はじめに
先日、南海トラフ巨大地震の30年以内での発生確率が「80%程度」に引き上げられたとのニュースが発表されました。
このニュースを見て、システム運用をしている身として改めて備えておく必要があると思い、DR対策についてまとめました。
DR対策とは
自然災害などが発生したときを想定して、システムの復旧における方法を検討しておくこと。
※BCP対策という言葉もありますが、DR対策は主にシステム復旧対策にあたり、BCP対策は事業の継続を含めた総合的な復旧対策をさします。
一般的な地震対策と同じく、システム面でも準備が大切です。
本記事はAWSでのケースを書いていますので、あらかじめご了承ください。
どんな準備をすればいいか?
まず、システム運用における災害対策では、目標復旧時間(RTO) と目標復旧時点(RPO) をしっかりと設定することが出発点になります。
目標復旧時間(RTO)とは
Recovery Time Objectiveの略で、システムの停止から復旧までに許容される最大の時間のことをさします。
例えば、RTOが4時間の場合、障害発生から4時間以内にシステムが完全に復旧することが求められます。
具体的な対策としては以下のような形になります。
- 自動化された復旧プロセスの構築(AWS Systems ManagerのRunbookを活用)
- 災害発生時の手順をすぐに実行可能な「復旧ドキュメント」の整備
- AWS Elastic Disaster Recoveryによる迅速なシステム切り替え
など。
目標復旧時点(RPO)とは
Recovery Point Objectiveの略で、災害が発生した時点からどれだけのデータを失うことが許容されるかを示す指標のことをさします。
例えば、RPOが1時間の場合、最悪でも1時間分のデータ損失が許容されるため、1時間ごとのバックアップが必要になります。
具体的には
- データレプリケーション:Amazon Aurora Global Databaseで異なるリージョン間の同期(レイテンシ1秒以下)
- 頻繁なバックアップ:AWS Backupを使用し、データベース、EBSボリューム、S3オブジェクトを定期的にバックアップ
などが挙げられます。
例えば、RTOを短縮しようとするとインフラのコストや運用負担が増加するといったように、RTOとRPOはトレードオフの関係にあります。
具体的な災害対策の選択肢
DR対策の大まかなパターンとしては、以下の4つがあります。
- バックアップ&リストア
- パイロットライト
- ウォームスタンバイ
- マルチサイト
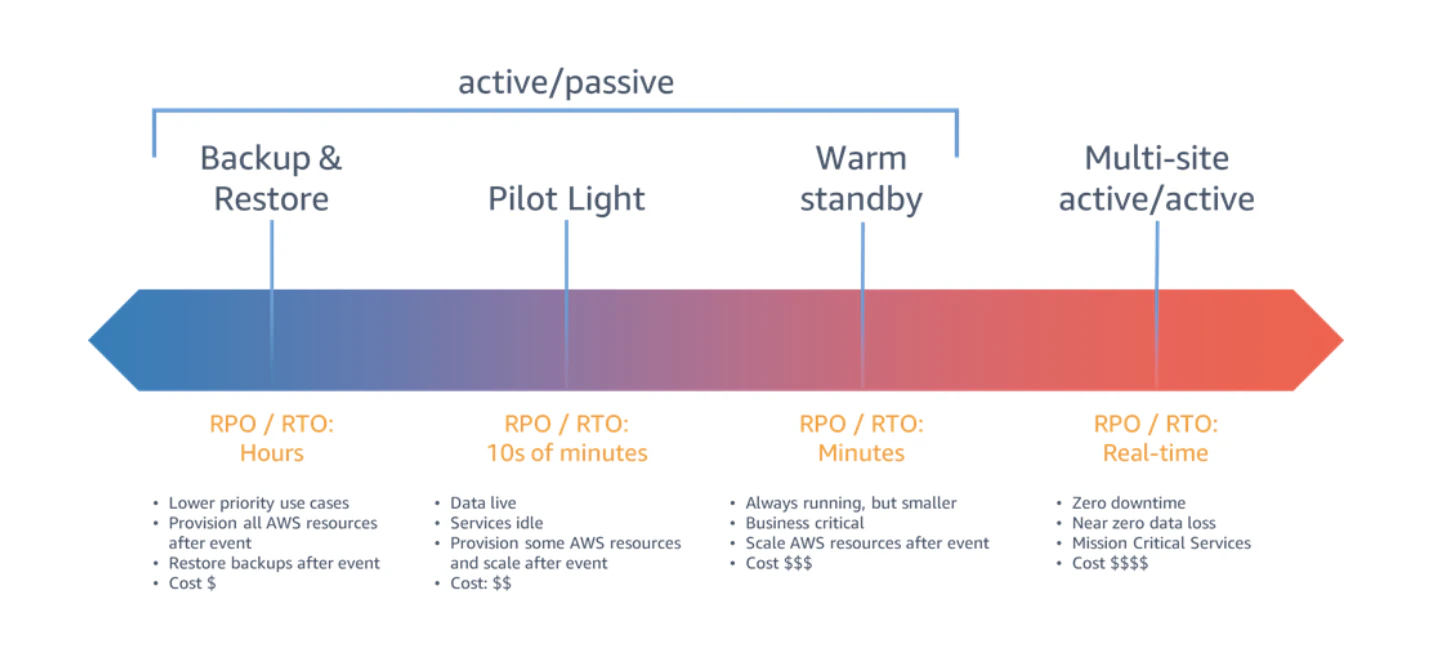
この図の右に行くほど、復旧までの時間は短いですが、コストは高くなります。
それぞれについて解説します。
1. バックアップ&リストア
データを定期的にバックアップして必要時にリストアする方法で、最小限のコストで始めることができます。
具体的な手順は以下の通りになります。
📌 準備
- Amazon RDSのバックアップを有効化します。
aws rds modify-db-instance \
--db-instance-identifier mydbinstance \
--backup-retention-period 7 \
--region ap-northeast-1
--apply-immediately
--backup-retention-period でバックアップの期間を7日間に設定しています。(必要に応じて変更してください)
また、--apply-immediately オプションを追加しないと、設定が次のメンテナンスウィンドウまで適用されない可能性があります。
2.EBSスナップショットの定期作成を実施します。
aws ec2 create-snapshot \
--volume-id vol-0123456789abcdef0 \
--description "Daily Backup" \
--region ap-northeast-1
3.アプリケーションデータをS3にバックアップします。
tar -czf backup_$(date +%Y%m%d%H%M%S).tar.gz /path/to/app/data
aws s3 cp backup_$(date +%Y%m%d%H%M%S).tar.gz s3://my-backup-bucket/app-backups/
定期的にバックアップからリストアしてデータの整合性を確認し、また、一連の手順を復旧ドキュメントとしてまとめておくといいでしょう。
🚨 災害発生時
1.最新のスナップショットからDBインスタンスを復元してRDSを復旧します。
aws rds restore-db-instance-from-db-snapshot \
--db-instance-identifier restored-db-instance \
--db-snapshot-identifier mydbsnapshot \
--region ap-northeast-1
2.最新スナップショットから新しいボリュームを作成してEBSの復旧します。
aws ec2 create-volume \
--snapshot-id snap-0123456789abcdef0 \
--availability-zone ap-northeast-1a
3.EC2インスタンスにアタッチします。
aws ec2 attach-volume \
--volume-id vol-0123456789abcdef0 \
--instance-id i-0123456789abcdef0 \
--device /dev/xvdf
![]() メリット
メリット
コスト:保存コスト以外はほぼ発生しないため、最も低コスト。
対応場面:データ消失や障害時の最終的な回復手段として利用可能。
コストが低い分、システムの復旧に数時間~1日かかることもあるので注意が必要です。また、定期的なバックアップが必須になります。
2. パイロットライト
最小限の本番環境を稼働させておき、災害時にフルスケールへ迅速に切り替える方法です。
具体的な手順は以下の通りになります。
📌 準備
1.最小限のDB・サーバーを常時稼働させる
aws rds create-db-cluster \
--db-cluster-identifier pilot-light-cluster \
--engine aurora-mysql \
--master-username admin \
--master-user-password password \
--region ap-northeast-1
2.Auto Scaling グループを設定する
aws autoscaling create-auto-scaling-group \
--auto-scaling-group-name pilot-light-asg \
--launch-configuration-name pilot-light-config \
--min-size 1 --max-size 10 --desired-capacity 1 \
--region ap-northeast-1
システムダウンを想定し、事前に実際にトラフィック切り替えとスケールアップを実施しておくとより安心です。
🚨 災害発生時
1.スケールアップ
AutoScalingのポリシーを変更してインスタンス数を増加する
aws autoscaling update-auto-scaling-group \
--auto-scaling-group-name pilot-light-asg \
--desired-capacity 8 \
--region ap-northeast-1
2.Route53でトラフィックを本番環境に向ける
aws route53 change-resource-record-sets \
--hosted-zone-id Z0123456789ABCDEF \
--change-batch file://traffic-switch.json
![]() メリット
メリット
- 復旧速度:RTOを1~2時間に短縮可能。
- コスト:必要最低限のリソースのみ常時稼働。
スケールアッププロセスの詳細な設計と管理が必要になります。
3. ウォームスタンバイ
本番環境とアーキテクチャは同じですが、インスタンス数やリソースを縮小して運用する(必要時に拡張する)方法です。
具体的な手順は以下の通りになります。
📌 準備
1 フルスケール環境と同じアーキテクチャで縮小版の環境を用意
※通常8台 → 2台の場合
aws ec2 run-instances \
--image-id ami-0123456789abcdef0 \
--count 2 \
--instance-type t3.medium \
--key-name my-key \
--security-group-ids sg-0123456789abcdef0 \
--subnet-id subnet-0123456789abcdef0
2.テンプレートを用意(CloudFormationの場合)
Resources:
WebServerGroup:
Type: AWS::AutoScaling::AutoScalingGroup
Properties:
MinSize: 2
MaxSize: 8
🚨 災害発生時
1.CloudFormationで追加リソースを作成して、フルスケールへ拡張します。
aws cloudformation update-stack \
--stack-name warm-standby-stack \
--template-body file://warm-standby-template.yaml
2.Route53でトラフィックを縮小版から本番環境に切り替えます。
aws route53 change-resource-record-sets \
--hosted-zone-id Z0123456789ABCDEF \
--change-batch file://traffic-switch.json
![]() メリット
メリット
- RTO:数十分~1時間以内で復旧可能。
- 安定性:常時縮小版が稼働しているため、トラフィック切り替えのみで対応できる。
縮小版とはいえ常時稼働が必要なため、運用コストが増加するので注意が必要です。
4. マルチサイト
別リージョンに同一システムを構築するため、最も可用性が高い方法になります。
具体的な手順は以下の通りになります。
※東京リージョン↔︎大阪リージョンの場合※
📌 準備
Auroraの場合
1.Aurora Global Databaseを作成して、別リージョンで環境を複製します。
aws rds create-global-cluster \
--global-cluster-identifier my-global-cluster \
--source-db-cluster-identifier arn:aws:rds:ap-northeast-1:123456789012:cluster:source-cluster
2.Route53で地理的ルーティングを設定します。
aws route53 create-geo-location-routing-policy \
--name example-policy \
--geo-location CountryCode=JP
RDSの場合
RDSにはグローバルデータベースの機能がないため、手動で別リージョンにレプリケーションを構築します。
1.本番環境のRDS(東京リージョン)を作成
aws rds create-db-instance \
--db-instance-identifier primary-rds \
--engine mysql \
--db-instance-class db.t3.medium \
--allocated-storage 20 \
--master-username admin \
--master-user-password mypassword \
--backup-retention-period 7 \
--region ap-northeast-1
primary-rds がメインのDB(東京リージョン)になります。
2.別リージョン(大阪)にリードレプリカを作成
aws rds create-db-instance-read-replica \
--db-instance-identifier replica-rds \
--source-db-instance-identifier primary-rds \
--region ap-northeast-3
replica-rds が大阪リージョンに配置され、東京リージョンのDBの変更がリアルタイムに反映されます。
また、フェイルオーバー時にプライマリへ昇格可能になります。
3.Route53でフェイルオーバールーティングを設定します。
※東京リージョンがダウンした場合に、自動的に大阪リージョンへトラフィックを振り分ける設定になります。
aws route53 change-resource-record-sets \
--hosted-zone-id Z0123456789ABCDEF \
--change-batch file://failover-routing.json
failover-routing.json の例
{
"Changes": [
{
"Action": "UPSERT",
"ResourceRecordSet": {
"Name": "db.example.com",
"Type": "CNAME",
"SetIdentifier": "Primary",
"Weight": 100,
"Failover": "PRIMARY",
"TTL": 60,
"ResourceRecords": [
{ "Value": "primary-rds.ap-northeast-1.rds.amazonaws.com" }
],
"HealthCheckId": "abcd1234-5678-90ef-ghij-klmnopqrstuv"
}
},
{
"Action": "UPSERT",
"ResourceRecordSet": {
"Name": "db.example.com",
"Type": "CNAME",
"SetIdentifier": "Secondary",
"Weight": 100,
"Failover": "SECONDARY",
"TTL": 60,
"ResourceRecords": [
{ "Value": "replica-rds.ap-northeast-3.rds.amazonaws.com" }
]
}
}
]
}
この設定によって、Route53のヘルスチェックが東京リージョンのRDSを監視します。
東京リージョンのRDSがダウンした場合、大阪リージョンのRDSへ自動的にトラフィックを切り替える形になります。
🚨 災害発生時
Auroraの場合
1.トラフィックを別リージョンに切り替えます。
aws route53 change-resource-record-sets \
--hosted-zone-id Z0123456789ABCDEF \
--change-batch file://geo-routing.json
2.Aurora Global Databaseのフェイルオーバーで、大阪リージョンをプライマリに昇格させます。
aws rds failover-global-cluster \
--global-cluster-identifier my-global-cluster \
--target-db-cluster-identifier arn:aws:rds:ap-northeast-3:123456789012:cluster:target-cluster
--allow-data-loss
--allow-data-loss を付けると強制的にフェイルオーバーしますが、データ同期が完全でない場合にデータ損失の可能性があるため、注意が必要です。
RDSの場合
1.フェイルオーバーして大阪リージョンのリードレプリカをプライマリに昇格させます。
aws rds promote-read-replica \
--db-instance-identifier replica-rds \
--region ap-northeast-3
これによりreplica-rdsがプライマリになるので、新しいデータも大阪リージョンで処理できるようになります。
RDSの場合はフェイルオーバー時に1~2秒のダウンタイムがある可能性があるため、許容できない場合に予めAuroraで構築しておくといいかもしれません。
![]() メリット
メリット
RTO:実質ゼロ
RPO:データ損失の可能性が(極めて)低い
複数のフルスケール環境が常時稼働するため、非常にコストが高い方法になります。
どれを選べばいいの?
あくまでも目安なので検討のご参考程度まで。。
バックアップ&リストア
- リソースが限られているスタートアップや中小規模のWebサービス
- システムのダウンタイムが数時間~1日許容される場合
→最もコスト効率がよいため、多少の停止は許容できるシステムに向いているかと思います。
パイロットライト
- ECサイトやSaaSアプリのDR対策
- 例:キャンペーンサイトなど季節やイベントに依存するトラフィックの変動があるサービス
- なるべく最小限のコストで早期復旧をしたい場合
ウォームスタンバイ
- 企業の業務システム
- 復旧に1時間以内が求められるが、マルチサイトほどのコストは避けたい場合
→早い復旧が必須な高い可用性が求められる業務アプリケーションなどで使われることが多い印象です。
マルチサイト
- 24時間365日での稼働が必須のシステム
- 例: 金融機関のトランザクションシステム、大規模ECサイト、グローバルSaaSサービス
- 障害が発生してもサービスを完全に継続しなければならない場合
最後に
DR対策は、RTOとRPOを軸に、ビジネス要件とコストのバランスが大切です。
南海トラフ地震のような大規模災害は避けられませんが、システムの準備次第でビジネスへの被害を最小限に抑えることは可能です。
時間があるうちに実行できる対策を始めて、いざという将来に備えたいものです。
参考にしたドキュメント