はじめに
本日12時より、MLB開幕戦のチケットの一般発売が開始されました。
私も大谷選手を一目見たいなと申込サイトにアクセスしましたが、案の定混雑ページが表示されてしまいました。
順番待ちを見ると・・・人数はなんと40万人超え・・・!
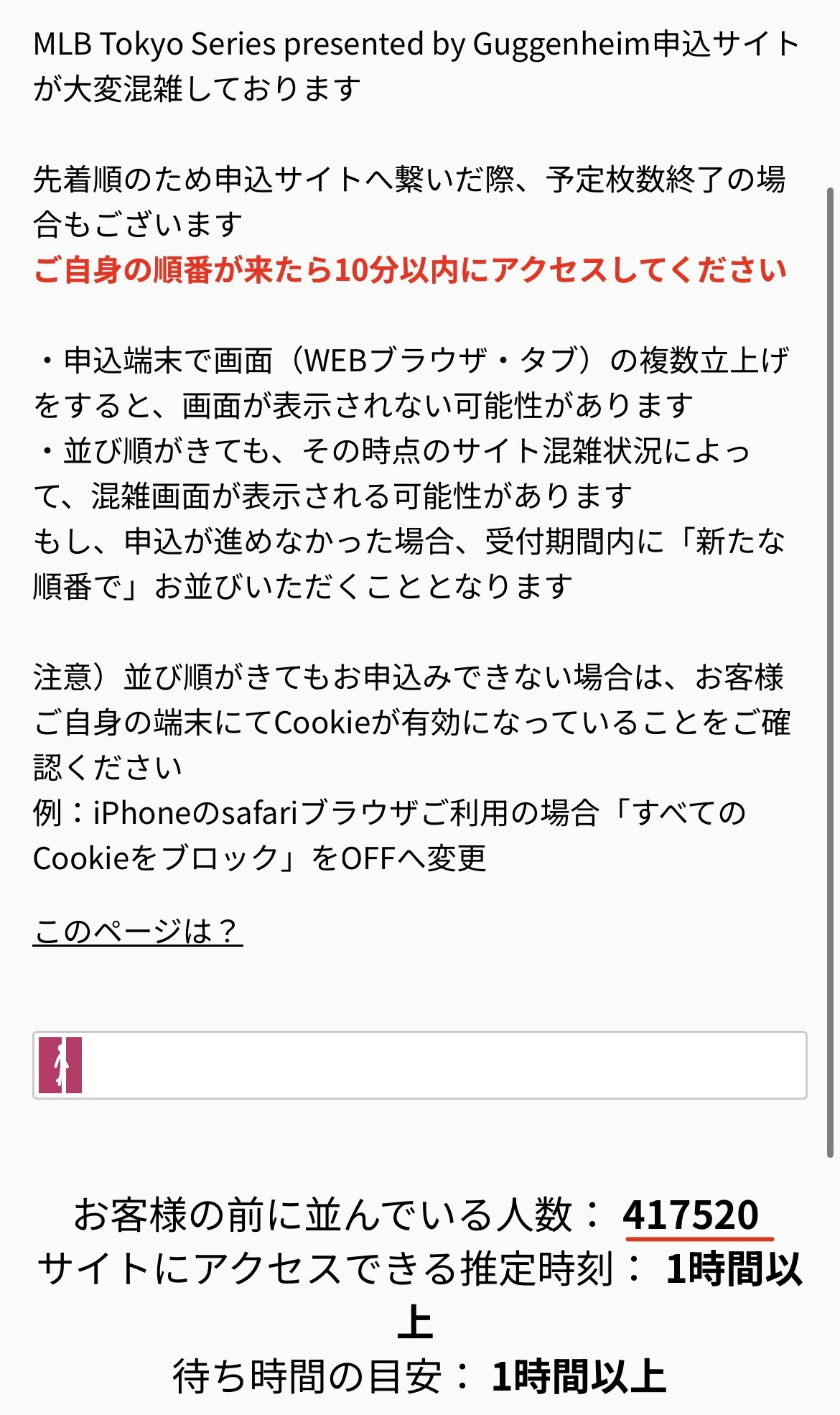
これは買うとは無理だなと思いつつ、それよりも、エンジニアの性なのか40万のアクセスに耐えている(少なくとも混雑ページを出せる)インフラ構成の方が気になってしまいました。
そこで今回は (40万程度の)高スパイクに耐えるインフラ構成 について、実際の事例や技術的な選択肢を交えて考察してみようと思います。
「スパイク」とは、短時間でアクセス数が急激に増加する現象を指します。
本記事では、AWSを利用することを想定していますので、あらかじめご了承ください。
1. 40万のスパイクとは具体的にどんな負荷か?
「40万のスパイクに耐える」と言っても、具体的にどのような負荷なのかを明確にしておかないと、適切なアーキテクチャ設計はできません。
(1) 負荷の定義
まず、想定する負荷の条件を整理しておきます。
-
40万リクエストが同時に発生する
- これは「40万ユーザーが1秒以内に同時アクセスする」ことを想定する。
- 例えば、チケット販売開始直後の「リロード爆撃」などが該当。
-
リクエストの種類は?
- 静的コンテンツ(画像、CSS、JS)
- 動的ページ(ログイン、購入処理など)
-
耐えるべき時間は?
- 数秒〜数分(スパイクのピーク)
(2) 一般的なWebシステムのボトルネック
40万のスパイクに耐えるには、まずボトルネックになりやすい部分を理解する必要があります。
| ボトルネック | 説明 | 対策の方向性 |
|---|---|---|
| Webサーバー | 同時接続数・リクエスト処理能力の限界 | 負荷分散(ロードバランサー・スケールアウト) |
| データベース | 高トラフィック時のクエリ競合・ロック | キャッシュ・レプリケーション・スケーリング |
| セッション管理 | セッションストアのスケール限界 | ステートレス化 or 高可用セッションストレージ |
| 外部API | 外部システムがボトルネックになる | レートリミット・バックオフ戦略 |
2. 高スパイクに耐えうるインフラ設計
ここからは 落ちない構成 を考えます。
(1) アーキテクチャ全体像
高負荷に耐えられるアーキテクチャをシンプルに整理すると、以下のような構成になります。
[ユーザー] → [CDN] → [ロードバランサー] → [Webサーバー群] → [データベース]
↓ [キャッシュ]
↓ [キュー]
主要コンポーネントの説明
| コンポーネント | 役割 | 適用技術(例) |
|---|---|---|
| CDN(Content Delivery Network) | 静的コンテンツのキャッシュ・リクエスト削減 | CloudFront, Fastly, Akamai |
| ロードバランサー | Webサーバーへの負荷分散 | AWS ALB/NLB, GCP Load Balancer |
| Webサーバー群(スケールアウト) | 動的ページ処理 | EC2, ECS, Kubernetes(EKS/GKE) |
| キャッシュ | DB負荷軽減・応答速度向上 | Redis, Memcached |
| キュー(非同期処理) | 重い処理を分散 | SQS, RabbitMQ, Kafka |
| データベース | 永続データ管理 | Aurora, PostgreSQL, MySQL(リードレプリカ) |
(2) 具体的な対策
① CDNの活用(リクエスト数を減らす)
CDNを使えば 約70%のリクエストを削減可能 です(Akamaiのレポートより)。
チケットサイトのようなアクセス集中型のサービスでは、 可能な限りCDNにキャッシュを寄せるのが鉄則 です。
例:AWS CloudFrontのキャッシュ戦略
- 静的ファイルは長期間キャッシュ (
Cache-Control: max-age=31536000) - HTMLは短時間キャッシュ (
max-age=60)
② ロードバランサーによる負荷分散
ALBやNLBを使い、トラフィックを複数のWebサーバーに分散します。
リクエストが偏らないようにする のがポイント。
-
ALB(Application Load Balancer)
- L7(HTTP/S)負荷分散が可能
- Cookieベースのセッション管理OK
-
NLB(Network Load Balancer)
- L4(TCP)負荷分散
- 超高スループット(ALBより耐久性高)
ベストプラクティス
- 静的コンテンツはCDNにオフロード(ALB/NLBに流さない)
- Webサーバーのオートスケールを有効化(EC2 Auto Scaling, Kubernetes HPA)
③ キャッシュを適切に使う(データベースを守る)
RDBに負荷をかけたら負けです。
RedisやMemcachedを活用して、DBアクセスを削減します。
キャッシュの使いどころ
- セッション管理(例:DynamoDB + TTL)
- よく読まれるデータ(例:Redisにランキング情報をキャッシュ)
- 外部APIの結果(例:天気情報APIのレスポンスをキャッシュ)
④ キューを導入して非同期処理に分散
チケット購入のような トランザクション処理 は 同期的に処理しない のが鉄則です。
キュー(SQS, Kafka, RabbitMQ)を使い、バックグラウンドで処理します。
例:チケット購入の流れ
- ユーザーが「購入」ボタンを押す
- Webサーバーは即座にレスポンスを返し、購入リクエストをキューに送る
- ワーカーが非同期で処理し、DBを更新
⑤データベースの負荷分散
DB自体もリードレプリカを利用するどして負荷を分散することが大切です。
特定のデータはレプリカ参照、他はマスター参照するなど。
3. まとめ
40万のスパイクに耐えるには、以下のポイントを押さえることが重要です。
✅ CDNを活用してリクエストを削減
✅ ロードバランサーで適切にトラフィック分散
✅ キャッシュを最大限活用し、DB負荷を軽減
✅ 重い処理はキューで非同期化
この構成であれば、 「落ちない」だけでなく、スムーズなユーザー体験も提供 できます。
この記事が大規模スパイクに強いインフラの設計する際の参考になれば幸いです。