はじめに
Meltdown と Spectre。2017 年末から噂が流れ始め、2018 年 1 月に GPZ によって公開された CPU の脆弱性です。
Project Zero: Reading privileged memory with a side-channel
https://googleprojectzero.blogspot.com/2018/01/reading-privileged-memory-with-side.html
この発表を受けて、Intel は Side channel vulnerability に関する新しい賞金プログラムを始めました。とりあえず 2018 年末まで。最高賞金は 25 万ドルです。一攫千金を狙う人は頑張ってください。
Expanding Intel’s Bug Bounty Program: New Side Channel Program, Increased Awards | Intel Newsroom
https://newsroom.intel.com/news/expanding-intels-bug-bounty-program/
本記事ではその Meltdown について解説しようと思います。というのも、ある日突然上司が「Meltdown と Spectre についてチームミーティングで何か話してよ。」とか無茶振りをしてきたからです。その上、「あ、でも、忙しいのわかってるから時間をかける必要はないよ。スライドとかも適当でいいから。」とか言い出すわけです。それは発表する側、聞く側の双方に失礼だろ、と。そのへんは新米上司だからしゃーないのですが、まあそれがきっかけとなって論文をまじめに読んで、PoC も一から自分で書いてみたら面白かったので記事にすることにしました。
完成した Meltdown の Windows 用 PoC がこれです。
msmania/microarchitectural-attack: Meltdown/Spectre PoC for Windows
https://github.com/msmania/microarchitectural-attack
本文中で、うまい日本語の単語が思い浮かばなかったものは英単語でそのまま書いています。ルー語みたくなっててキモいです。すみません。
まずはふわっと全体を理解
Micro-architectural attack
Meltdown と Spectre は、よくある Use-After-Free などのソフトウェアのバグとは全く異なり、CPU というハードウェアのバグを exploit する micro-architecture レベルの攻撃手法です。
Micro-architecture に対して、CPU における Architectural なレベルとは、プログラムやデバッガーから見えるレジスターなどのことです。Micro-architecture とはそれよりさらに下層の概念で、CPU キャッシュや、Spectre で出てくる BTB (= Branch Target Buffer) などが含まれます。これらの概念は原則として、プログラムからは見えないはずです。Meltdown 論文には、Micro-architecture の例として Intel Skylake の概要が掲載されています。以下の図がそれです。
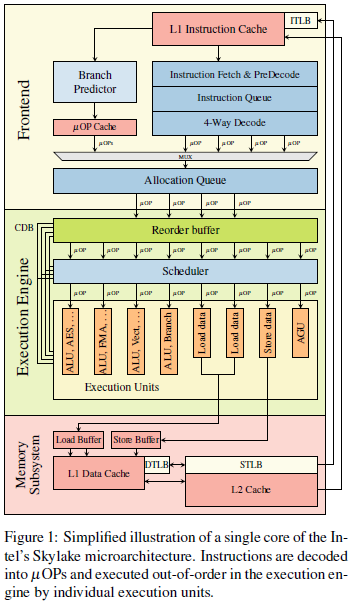
プログラムから見て CPU はブラックボックスであるはずですが、実は Meltdown/Spectre 以前から、Micro-architecture レベルの状態を Architecture レベルの状態に変換する抜け道 (= covert channel) が幾つか知られていました。例えばその一つが、Meltdown や Spectre で使われている Flush+Reload で、これについては後述します。
Micro-architecture が機密情報を持っている状態があり、その情報を攻撃者が何らかの方法で読みだして知ることができるのであれば、それは information disclosure の脆弱性であり、それを実現する攻撃手法が Micro-architectural attack です。
Meltdown/Spectre は共に、「Micro-architecture が機密情報を持っている状態」を CPU の投機的実行 (= Out-of-order Execution) を利用して意図的に作り出し、次にそれを Flush+Reload という従来から知られていた方法で盗み出す、という二つのステップで構成されています。Out-of-order execution と Speculative Execution の違いについては後述します。
Meltdown/Spectre でできること、できないこと
ここでは、以下の Meltdown/Spectre 論文を基にした情報について記述しています。上述した GPZ のブログには論文以上のことが書かれているような気がするのですが、ブログのほうはまだ完全に理解していないのでパスです。特に Hypervisor の仕組みに関しては全然知らないので苦手。
[1801.01207] Meltdown
https://arxiv.org/abs/1801.01207
[1801.01203] Spectre Attacks: Exploiting Speculative Execution
https://arxiv.org/abs/1801.01203
それぞれをテクニカル、かつ簡潔に説明すると、こうです。
- Meltdown: ユーザーモード プロセスから、権限昇格の必要性の有無に関わらず、同じプロセス コンテキストのページ テーブルに存在するアドレスのデータを任意に読みだせる
- Spectre: 権限昇格はできないが、同じプロセス内、もしくは別プロセス内の任意のアドレスを読みだせる
これはヤバいですね。ただし、あくまでも宣伝文句であって、実際には Meltdown/Spectre 双方に制限があります。
より具体的に考えてみます。
まず Meltdown ですが、同じコンテキストのページ テーブルにある、というのがポイントです。ページ テーブルにマップされていないデータは読めません。しかし、ここで Windows を Linux のカーネルのメモリ管理の違いが効いてきます。
今回初めて知ったのですが、Linux カーネルには Direct Physical Mapping という機能があり、64bit の仮想メモリ領域のうち、特定のカーネル領域は全ての物理メモリに常に直結するようになっているようです。ここにはカーネルだけでなく、全てのユーザー プロセスも含まれます。
linux-insides/Paging.md at master · 0xAX/linux-insides
https://github.com/0xAX/linux-insides/blob/master/Theory/Paging.md
さて Meltdown によって、ページ テーブル上にある全てのアドレスは読み出せるようになってしまいました。というわけで、Linux における Meltdown では、攻撃者は全ての物理メモリ、すなわち、ページアウトされていなければ別プロセスのデータでも読み出せることになりました。さらに、Direct Physical Map のある場所はある程度決まっていて、KASLR (= Kernel Address Space Layout Randomization) がなければ ffff880000000000 - ffffc7ffffffffff の 64TB 領域、KASLR があっても、ランダマイズのエントロピーは 40bit です。論文では、もし搭載物理メモリを 8GB と仮定するならば、最悪でも 128 テストすれば KASLR は bypass できると結論付けています。ここがどういう計算なのかはよく分からない・・。
一方の Windows ですが、Direct Physical Mapping のように、物理メモリに常に直結しているエリア、というのはありません。Non-paged pool と呼ばれる、ページアウトされずに物理メモリ上に存在し続けるメモリを確保することはできますが、どこに確保されるかは決まっていないはずです(若干自信がないですが・・)。したがって Windows で Meltdown する場合、どのアドレスをターゲットにするかを探す手間が発生します。また Windows では、別プロセスのデータを Meltdown によって読み出すことはできません。
一方の Spectre ですが、権限昇格はできません。カーネル データを読むのは Meltdown に任せておきましょう。代わりに何ができるかといえば、プロセスの壁を越えられます。これは Windows の Meltdown ではできませんでした。結局、Spectre があれば Windows もヤバい。どっちもヤバい。
同じプロセス内の任意のアドレスを読めて何が嬉しいのか、という話ですが、これはブラウザーや、Office 文書 への OLE 埋め込みが該当します。Spectre を使うコードは、C やアセンブリでなくとも、幾つかの条件を満たせば JavaScript などのスクリプト言語を使って書くことができます。つまり Spectre を使えば、危ないサイトを開いただけでブラウザー プロセス内の全部のメモリが読み出され放題になります。これもヤバいですね。ちなみに Google Chrome は、ドメインごとにプロセスを分ける Site Isolation という凄い機能が年末あたりにリリースされたのでちょっと安心です。
というわけで、分かりやすくまとめるとこうです。ただし、どの場合においても制約はあるので、本当に自由に読みたい放題、というわけではないです。
- Meltdown (Linux): ユーザー プロセスから、カーネルや別プロセスのデータが(物理メモリ上にあれば)全部盗める。
- Meltdown (Windows): カーネルのデータは盗める。別プロセスは無理。
- Spectre: 別プロセスのデータが盗める。スクリプトからブラウザーのデータが盗める。カーネルは無理。
Meltdown と Spectre の違い
ほとんど二次情報は見ていないのですが、記事を書くにあたって以下の記事は読みました。
MeltdownとSpectreの違いについて分かったこと - Qiita
https://qiita.com/hiuchida/items/2248b379197a5052029e
プロセッサの脆弱性。MeltdownとSpectre - Qiita
https://qiita.com/urakarin/items/c4f59c5bebd9a6080b6d
論文を読まないと Meltdown と Spectre の違いは分かりにくいのかもしれないですね。どちらの論文でも、他方との違いについては触れられていて、互いのことを orthogonal であると言っています。共通点は前述したように、speculative execution を利用して意図的に micro-architectural state を変えて、それを既知の方法でプログラムから見える状態に変えることだけです。
違いはけっこうたくさんあります。こんな感じ。
- Meltdown は、Intel CPU のバグを利用して権限昇格を bypass できることに意味がある
- Meltdown は out-of-order execution を利用するが、branch prediction は使わない
(厳密な意味で Meltdown は Speculative execution を使わない) - Spectre は権限昇格を目的としていない
- Spectre は Intel に限らない
- Spectre は branch mispredicion を意図的に誘発させる
- Spectre は他プロセスから情報をとれる
前提として、そもそも micro-architectural state を architectural state に変換する方法があること自体は新しい知見ではなく、それはバグとは見なしていません。
分かりやすいのは Meltdown です。Intel のチップが Out-of-order Execution のときに権限昇格をチェックしていないのが明らかなバグであり、それを利用して権限昇格が行える、というのが Meltdown です。根本的な解決は何かといえば、権限昇格できない新しいチップが開発されることですが、それまで何もせずに待っているわけにはいきません。そこで OS カーネル側で KPTI (= Kernel Page-Table Isolation; 名前からの単なる推測ですが、カーネル領域とユーザー領域のページテーブルを分けるような感じ・・?)のような機能が追加されたわけですが、あくまでもこれらは mitigation という扱いで、fix ではありません。
Spectre の方は、そもそも何がバグなのかが微妙で、何をどう直せばいいかという完ぺきな答えが得られていない状態です。例えば Branch prediction の動作自体は当初の思惑通りに動いているわけです。今まで信じてきたデザインが実は脆弱だった!ということが今になって分かってしまった、というのが現状です。例えばブラウザーでの対策として、高精度タイマーの精度を落とす、とか、SharedArrayBuffer を無効にする、といった変更がリリースされていますが、これは Flush+Reload を難しくするための方策であって、Spectre そのものに対する直接的な修正と考えるにはちょっと弱いです。
Out-of-order execution と Speculative execution の違い
Meltdown 論文では、Out-of-order execution と Speculative execution との違いを以下のように説明しています。
In this paper, we refer to speculative execution in a more restricted meaning, where it refers to an instruction sequence following a branch, and use the term out-of-order execution to refer to any way of getting an operation executed before the processor has committed the results of all prior instructions.
Speculative execution は Out-of-order execution の一種であるが、例外などによって全然別なところに飛ばされてしまう場合は Speculative execution とは呼ばないみたいです。一応本記事でもこれをなるべく踏襲するようにします。ただ、Meltdown/Spectre の違いの本質は Speculative execution vs Out-of-order execution ではありません。
Meltdown を理解する
ではここから、Meltdown のコードを理解していきましょう。論文の流れに沿っていきたいと思います。
Toy Example と Out-of-execution
実は Meltdown はとっても単純です。論文の Listing 1 にある 3 行のコードが Meltdown 第一方程式です。
raise_exception();
// the line below is never reached
access(probe_array[data * 4096]);
実装はよくわかりませんが、raise_exception は何らかの例外を投げるコードを実行するとしましょう。例えば、1 / 0 で divide-by-zero とか、*reinterpret_cast<int*>(0) = 1 で access-violation とかそんな感じです。
一行目を実行すると何が起こるでしょうか。プロセスがクラッシュするかもしれませんし、Linux で signal handler が定義されていればそっちに飛ぶでしょう。いずれにせよ、このコードで重要なのは 2 行目のコメントにもある通り、3 行目の access 関数は実行されない、ということです。 ただしそれは Architectural なレベルの話であって、Micro-architectural なレイヤーにおいては 3 行目が投機的に実行される可能性があります。
投機的実行の有無に関わらず、プロセスがクラッシュしてしまっては話は終わりです。そこで、Windows であれば __try{}__catch{}、Linux なら signal handler を使ってクラッシュは回避しましょう。その回避した先でうまいことやれば、Out-of-order execution による Microarchitectural state をゲットできます。それが Toy example の本質です。
Flush+Reload
Toy example の 3 行だけで本質は掴めますが、動きません。実際に動かすには、micro-architectural state を取り出すコードが必要で、その一例が Flush+Reload です。何度か触れていますが、Flush+Reload 自体は Meltdown の成果ではありません。
Flush+Reload とは、CPU キャッシュをフラッシュしてから試したいコード (例えば Meltdown の Toy example) を実行し、その後メモリ領域へのアクセスの応答時間を調べることで、その領域がキャッシュされていたかどうかを判別する方法です。私が書いたコードからのコピペになりますが、Windows だと例えばこんな感じです。
constexpr int probe_lines = 256;
uint64_t tat[probe_lines];
uint8_t probe[probe_lines * 4096];
for (int i = 0; i < probe_lines; ++i)
_mm_clflush(probe + i * 4096);
__try {
ooe(target_address, probe, &zero);
}
__except(EXCEPTION_EXECUTE_HANDLER) {}
for (int i = 0; i < probe_lines; ++i)
tat[i] = memory_access(probe + i * 4096);
真ん中の ooe は、toy example の関数だと考えてください。ooe を実行する前に clflush 命令を実行してキャッシュをフラッシュし、ooe を実行した後にクリアした領域から再度データをロードしています。
4096 を掛ける意味は、キャッシュは 1 バイト毎ではなく、ある程度まとめてキャッシュされるようになっているためです。例えばアドレス X のデータをキャッシュした場合、X+1 や X+2 のアドレスのデータも同じキャッシュ ラインに乗ってしまいます。盗みたいターゲット データの値に応じて、同じキャッシュ ラインに乗らない程度に離れた領域のデータを読み出すようにさせる工夫として 4096 を掛けています。ページ サイズが 4096 バイトだから、という理由だと思いますが、L1 キャッシュのキャッシュ ラインはもっと小さいはずなので、4096 である必要はないはずです。
memory_access 関数はアセンブリで以下のように実装しています。これは Windows における x64 の ABI に沿ったものです (パラメーターはレジスター渡しで、rcx, rdx, r8, r9 の順)。
memory_access:
mov r9, rcx
rdtscp
shl rdx, 20h
or rax, rdx
mov r8, rax
mov rax, [r9]
rdtscp
shl rdx, 20h
or rax, rdx
sub rax,r8
ret
やっていることは次の 3 ステップで、メモリアクセスの応答時間を調べているだけです。
- rdtscp でプロセッサーのタイムスタンプ カウンターを取得
- 引数として与えられたアドレスから 64bit 読む
- タイムスタンプ カウンターをもう一回取得し、前回との差を返す
ここで rdtsc ではなく rdtscp を使っているのは、rdtsc だと rdtsc 自体が投機的に実行される可能性があり、メモリアクセスが終わる前に 2 回目のカウンタが取得されてしまうことを防ぐためです。この動作は Intel の Software Developer’s Manual に以下のように書かれています。投機的実行まじ厄介・・・
The RDTSC instruction is not a serializing instruction. It does not necessarily wait until all previous instructions have been executed before reading the counter. Similarly, subsequent instructions may begin execution before the read operation is performed. If software requires RDTSC to be executed only after all previous instructions have completed locally, it can either use RDTSCP (if the processor supports that instruction) or execute the sequence LFENCE;RDTSC.
Toy Example を実行して確かめる
PoC の 01_meltdown_toy にあるコードは、divide-by-zero と Flush+Reload を組み合わせた方法で、ほぼ 100% 動作します。ぜひお試しを。
Meltdown
論文のセクション 5 です。Meltdown 第二方程式がこちら。3 行が 7 行に増えました。
; rcx = kernel address
; rbx = probe array
retry:
mov al, byte [rcx]
shl rax, 0xc
jz retry
mov rbx, qword [rbx + rax]
Toy example は「ここで例外 X が発生するとおくと・・」みたいな感じでしたが、このコードはより具体的に Intel CPU の権限昇格を exploit するためのコードに置き換えられています。といっても 4 行目の単なる mov で、「どこでもいいからとりあえずカーネルのアドレスからデータを持ってくると・・」程度の具体化です。Toy example と同じく、これが例外を発生させるのは明らかです。
retry とか jz は何なのよって話ですが、これは論文の 5.2 Optimizations and Limitations の最初の項目、The case of 0. で触れられています。コードの意味は、カーネルから読みだした値が 0 だったら retry に戻ってもう一回読み直す、というものです。これは CPU の動作として、後に消去される Out-of-execution の結果としての未来ではなく、現実において読めないはずの値を読もうとしているのが発覚した場合、例外を処理する前に安全のためそのレジスターを 0 でクリアするという動作が存在するためで、それとの競合を防ぐためです。表現が回りくどい・・・別の言葉で説明します。
Architectural レベルでは単なる mov ですが、CPU がアドレス X からデータを取ってくるとき、以下の作業が必要になるはずです。厳密には間違っているかもしれませんが、イメージです。
- アドレス X について調べる (GDT からデータを読み出す)
- 現在のコンテキストについて調べる (コントロール レジスターを見る)
- 現在のコンテキストがアドレス X にアクセスしていいかどうかを比べる
もしアクセスできない場合、続きはこうなります。
4. ロード先のレジスターを 0 クリア
5. IDT を調べて、適切なハンドラーに処理を投げる
これらのステップは、アドレス X のデータを知らなくても実行することができます。したがって、ステップ 1-3 の実行と並行してアドレス X のロードも開始しておいて、可能な限りその先のコードも実行しておけば、ステップ 3 の結果が出て初めてデータのロードを開始するよりも実行ユニットの稼働効率が良くなる、というのが Out-of-order Execution の意図です。
説明のため、投機的に実行されるはずの処理にアルファベットを振ります。
A. mov al, byte [rcx]
B. shl rax, 0xc
C. jz retry
D. rax が 0 なら mov al, byte [rcx]、0 以外なら mov rbx, qword [rbx + rax]
Meltdown では、ステップ 1 から始まる本流と、ステップ A から始まる Out-of-order Execution の傍流との間で競争が始まります。ここでもし retry を実装せずにいて、かつ、本当にカーネル内のデータが 0 だった場合、その 0 がステップ 4 による 0 なのか、ステップ A による 0 なのかを判断できません
Retry があることで、もし本当にカーネルのデータが 0 だった場合は傍流のほうが無限ループに陥る (Out-of-order Execution の話なので、プログラムがハングするわけではありません) ので、Out-of-order Execution による CPU キャッシュの変化は発生しない、すなわち Flush+Reload したときに、どのキャッシュ ラインも応答時間が同じぐらいになるはずです。逆に、キャッシュ ライン 0 の応答時間が速かった場合は、傍流でステップ A が終わる前に本流のステップ 3 が終わった、ということなので、Meltdown は失敗したということが分かります。細かいテクニックですが、実に巧妙です。
以上が Meltdown の本質で、ほとんど Toy Example と変わらないことが分かったと思います。
IAIK の Meltdown PoC について
論文のセクション 6 Evaluation に、GitHub 上にある Meltdown PoC へのリンクが書かれています。以下のリンクがそれで、全部 Linux 用の PoC です。
IAIK/meltdown: This repository contains several applications, demonstrating the Meltdown bug.
https://github.com/IAIK/meltdown
例えば Demo #4 は、secret というプロセスを起動しておいて、そのプロセス内にある情報を physical_reader という別のプロセスから、Direct Physical Map 領域を経由して読み出す、というものです。ここでポイントは、physical_reader を実行するときに taskset を使って、どのコア上で physical_reader プロセスを実行するかを指定していることです。taskset を使わない場合、高確率で失敗してデータは読めません。taskset を使っても、成功するコアもあれば失敗するコアも存在し、そのコアは変動します。理由はおそらく、IAIK 実装の Flush+Reload は CPU のコアごとに存在する L1 か L2 キャッシュしか判別できないためと考えられます。L3 キャッシュを利用して Meltdown できるかどうかは不明です。
手元にある複数の CPU で試しましたが、IAIK PoC のコードを全く変えない場合でも、半分以上のマシンで physical_reader によるデータの読み取りは成功しました。成功しないマシンでも、Windows を入れて Windows 上で PoC が動いた (正確には、もともと Windows が入っているマシンにおいて Ubuntu を USB ドライブから起動してテストしていた) ので、パラメーターを変えるか、後述するカーネル タイマーを使った処理と同様の処理を入れれば Linux 上でも動くはずです。
Windows で Meltdown する
Linux で動く IAIK 実装の PoC があるので、それを Windows で動かしたくなるのは自然な流れです。しかし、そのまま移植しただけでは動きません。Windows で Meltdown するときの追加要件について説明します。結論から言えば、要件を満たすために Meltdown 用のドライバーを作ってチートしました。
GitHub にある stormctf/Meltdown-PoC-Windows について
"windows meltdown poc" などのキーワードでググると、最初に来るのが以下のページです。
stormctf/Meltdown-PoC-Windows: Source from https://twitter.com/pwnallthethings. Compiled in VS 2013
https://github.com/stormctf/Meltdown-PoC-Windows
この中で対象アドレスの問題をどうやって解決しているかというと、NtQuerySystemInformation に 11 (= SystemModuleInformation) を渡して、返ってくる構造体の中にカーネル モジュールのベース アドレスが含まれているという情報を使い、その Imagebase + 0x1000 のところからデータを読み出そうとしています。なお、MSDN で NtQuerySystemInformation を見ても、SystemModuleInformation という値は書かれていません。有名な非公開情報なのでしょう。Windows カーネルの ASLR はまるで意味をなしていない・・・
しかし、この PoC は手元のどの環境でも上手くいきませんでした。
要件 1. CPU のアフィニティー
これは IAIK PoC 実行で taskset を使っていることと同等です。Windows には taskset のようなコマンドは無かったはずなので、存在する全てのコアの数だけにスレッドを作り、SetThreadAffinityMask を使ってアフィニティーを設定し、全コア上で同時に exploit するようにしました。
要件 2. Direct Physical Map の代わりとなるアドレス
少々強引ですが、ドライバーを書いて、Non-paged Pool にデータを確保するようにしました。要件 3. を考えれば、paged pool でもいいはずです。
要件 3. 読み出すカーネルのデータ自体もキャッシュされていないといけない、らしい
この条件を試行錯誤で見つけ出すのにけっこうかかりました。CPU のアフィニティーを設定して、決め打ちの Non-paged pool のアドレスを読み出そうと何度試しても Windows では全然うまくいきません。同じマシンの Linux では上手くいくことが分かっていたので、CPU 的には Meltdown できるはずです。ちなみにテストに使っていたのは Windows 10 1709 (RS3 とも言う) の RTM 版です。Windows で Meltdown は起きないのではないかと半ば諦めて Spectre の方に多くの時間を割いていたところ、偶々 Spectre 論文の記述をきっかけにして、ターゲットのデータもキャッシュにいれておけば、Out-of-order Execution の効率が上がるのでは、という発想が生まれ、試してみたらビンゴでした。
既に要件 2. のためにドライバーはできていたので、そこに、カーネル タイマーを利用して確保した領域を一定の間隔 (決め打ちで 10msec 間隔) で触り続ける、という動作を入れました。タイマーを止めると Meltdown は 100% 失敗しますが、タイマーを動かすと 100% というわけにはいきませんが高確率で上手くいきます。
要件からの考察
要件 3. から逆算しての仮説ですが、OS による例外トラップ処理 (CPU で例外が発生してからユーザー プロセスのハンドラーに制御が戻ってくるまでの一連の流れ) が、Linux の方が Windows よりも複雑なのかもしれません。
前のセクションで使ったリストですが、Meltdown では以下のシナリオが同時に発生します。
<通常実行>
- アドレス X について調べる (GDT からデータを読み出す)
- 現在のコンテキストについて調べる (コントロール レジスターを見る)
- 現在のコンテキストがアドレス X にアクセスしていいかどうかを比べる
<投機的実行>
A. mov al, byte [rcx]
B. shl rax, 0xc
C. jz retry
D. rax が 0 なら mov al, byte [rcx]、0 以外なら mov rbx, qword [rbx + rax]
Meltdown が成功するためには、ステップ A-D が ステップ 1-3 よりも先に完了している必要があります。そのときネックになるのは、ステップ A と D とで 2 回発生するメモリからのデータのロードです。ステップ D のメモリアクセスは、Flush+Reload で使う領域であり、ここがキャッシュされているかされていないかで結果を判断するので、ステップ D は投機的実行中に本当にメモリからデータをロードしないといけません。要件 3. で追加したカーネル タイマーは、ステップ A でアクセスされる領域を定期的に触ることによって、投機的実行中のステップ A が必ず cache hit するようにしています。要件 3. の有無による結果の違いは、Windows の例外トラップ処理がメモリ アクセス 2 回分より速いか、例外トラップ処理が消費するキャッシュによってターゲットの領域がキャッシュから evict されている場合にうまく説明されます。試していませんが、同様の工夫は、Linux の PoC の成功確率も向上させるはずです。
BlackHat 2018 での Meltdown セッション
BlackHat 2018 に会社の経費で参加できたので、Meltdown のセッションに参加してきました。
行く直前まで、Meltdown なんて 100% 理解できてるから今更、という感じだったのですが、スピーカーが Meltdown 論文の筆頭著者を含む オーストリアの Graz University of Technology のグループの方々だと分かったので参加してきました。
セッションの内容はユーモア多めで楽しいものでしたが、技術的にはこの記事で書かれている通りで大きな間違いや新発見はありませんでした。論文にも記載があったので驚くべきではないのでしょうが、ハードウェア割込を使わず、Intel TSX を使ったデモ動画が紹介され、そんな環境をどうやって入手したのかが気になりました。というか質問すればよかった。
興味深いのは、GPZ のグループと発見が重複したのはまったくの偶発的な出来事で、発見を報告してから Intel を経由して初めて GPZ の仕事を知ったそうです。先行研究があったとはいえ現実は面白いものです。なお、彼らは Spectre には気づかなったようです。
さて、セッションの内容からここで改めて紹介しておきたいのは以下の 3 点です。
- Intel だけでなく、AMD と ARM の一部の CPU にも Meltdown はあった
- Meltdown は Speculative Execution を利用するものではない
- Meltdown は Side-channel Attack ではない
まず一点目。これは本記事が少し間違っていました。Intel の CPU はほぼ全部ですが、AMD と ARM の一部 CPU でも Meltdown は有効だったようです。
二点目。これは論文から読み取れていましたが、理由が正しく理解できていませんでした。ポイントは Speculative という単語のニュアンスにあります。英語のネイティブ スピーカーだと明らかなのかもしれませんが、Speculate という単語には、何らかの外部要因に基づく思考のような行為が前提となるようです。例えば Spectre Variant 1 では条件分岐の過去の結果に基づいて将来の分岐先を予想して実行していました。しかし Meltdown では、単に依存関係のない後続の命令を手当たり次第に実行しているだけなので、Speculate と呼ばれるような行為は発生していません。したがって Meltdown で利用しているのは単なる Out-of-order Execution だという論理です。これはとても納得がいく説明でした。
最後三点目。これは定義に依存するのですが、彼らの主張は Side-channel を使ったからと言って必ずしも Side-channel Attack と呼ぶのが正しいとは限らない、というものです。Meltdown では、Out-of-order Execution が標的のアドレスの値を直接的に実行しているわけで、結局のところ標的を直接読み出しているのと同じだと考えることもできます。そして Side-channel attack とは、直接読み出せない情報を Side-channel 経由で読み取ろうとする行為に限定されるという考え方です。個人的にはこれは双方の主張もあり得ると思うのですが、だとすれば発見者の主張を尊重したいところです。これは深読みですが、彼らの主張の理由はおそらく、Meltdown はこれまでになかった全く新しい攻撃手法だと強調したいのだと思います。本記事で書いたように、Side-channel Attack 自体は以前からある攻撃手法なので。
BlackHat に基づく更新は以上の通りです。一緒に写真も撮らせてもらえるチャンスがあったのでここで自慢。
The presentation about Meltdown at #BlackHat2018 by @misc0110 @lavados @mlqxyz was really fun. Obviously it was a great Christmas gift or a nightmare for some vendors including me, but at the same time it motivates us to break our streotype. Thanks a lot! pic.twitter.com/QwdD8kndrS
— Toshi K. (@msmaniax) August 10, 2018
おわりに
Meltdown/Spectre の概要と、Windows で Meltdown を実行するための追加要件について説明しました。テストは Windows 1709 の 64bit RTM 版で行いました。最新の Windows Update を適用すれば PoC が動かないことも確認済です。
要件 3. には本当に苦労して、3 日ぐらい悩んでいました。完成した喜びの勢いのままこの記事を書いているので、読みにくい記事になっているかもしれません。不明点、記事に対する指摘などは歓迎です。
Spectre はいつやるの?
鋭意やっていますが、こちらはプロセスの壁を未だ破れず・・・Spectre 論文は記述の解釈がしづらいんですわ。今週末頑張ります。近日公開予定です。
書きました。
Windows で Spectre する - Qiita
https://qiita.com/msmania/items/eab61240f8b4f71b0177