はじめに
Chromium は、独自のヒープ管理機構を実装しており、OS が用意するヒープを使いません。その代わりに ParitionAlloc と Oilpan と呼ばれる 2 つのヒープ管理機構が存在し、確保するオブジェクトの種類によって使い分けられています。本記事では PartitionAlloc の詳細動作について紹介します。
PartitionAlloc 概要と特徴
Chromium プロジェクト公式の概要はこちらです。
PartitionAlloc Design
https://chromium.googlesource.com/chromium/src.git/+/master/base/allocator/partition_allocator/PartitionAlloc.md
デザイン上の特徴としては、メモリ領域をオブジェクトの種類と確保するサイズによって明確に分けていることです。オブジェクトの種類ごとに Partition とよばれる構造を作り、Partition の中で、決められたサイズの範囲のオブジェクトを Bucket と呼ばれる構造の中に確保します。
例えば現在の Chromium には、FastMalloc、LayoutObject、ArrayBuffer、Buffer という 4 つのパーティションが存在します。それぞれのパーティションが複数の Bucket を持っており、例えば 9~16 バイトの領域を確保する Bucket などが存在します。
オブジェクトの種類ごとに Partition を分けることによって、UAF に対して堅牢になります。例えば、Layout オブジェクトのダングリング ポインターが発生したとしても、その領域は次も Layout オブジェクトとして確保されることになるので、文字列バッファーなどを使ってオブジェクトを乗っ取ることが極めて難しくなります。
サイズごとに Bucket を分けることのメリットは、領域のサイズ情報を確保領域に保存せずに済むことです。これによって、確保領域を隙間なく敷き詰めることができます。Bucket や Partition 自身のメタ情報は当然必要ですが、これは確保領域とは離れたところに保存することができます。このような構造を採用することで、万が一バッファー オーバランが発生してもメタ情報が破壊されることがないため、セキュリティ上安全になります。
デメリットを挙げるとすれば、消費メモリが必要以上に増えることでしょうか。まあでも最近のパソコンは搭載メモリが潤沢なので、ブラウザーに関して言えば、多少消費メモリが多くても速くて安全な方がいいのは間違いないでしょう。
以下のブログの複数の記事で Chromium のメモリ管理について触れられています。
Root Cause by struct
http://struct.github.io/
このブログの Oilpan に関する記事の中で、Chromium のメモリ管理に関する簡単な歴史が紹介されていました。もともと WebKit では TCMalloc が使われていたが、WebKit をフォークして Blink プロジェクトが始まったあたりで、DOM オブジェクトについてはよりセキュアな PartitionAlloc を使うようになった、らしい。その後しばらくして、DOM と幾つかのオブジェクトはガベージ コレクションの機能を持つ Oilpan を使うようになったみたいです。Oilpan は次回やります。
本文中のデバッガー コマンドについて
以下、Windows 上でのデバッガー出力を掲載していますが、これは自作した下記の Chromium (というか Google Chrome) 用のエクステンションを使っています。未知のアプリケーションを理解するにはデバッガー エクステンションを作りながら調べるのが遠いようで近道です。
GitHub - msmania/chromium-debug: Debugger extension for Chromium
https://github.com/msmania/chromium-debug
PartitionAlloc の管理単位
Partition
PartitionAlloc の最上位構造は Partition で、現在の Chromium には 4 つの Partition があります。それらは全て WTF::Partitions クラスで static メンバーとして定義されています。WTF というのは Web Template Framework の略です。
0:027> !fast_malloc_allocator
Target Engine = 66.3359
WTF::Partitions::fast_malloc_allocator_ 00007ff9`2a6dd050 -> base::PartitionAllocatorGeneric 00007ff9`2a6dd090
extent(s): 0000197e`6a600000-0000197e`6b000000 (5)
0:027> !array_buffer_allocator
WTF::Partitions::array_buffer_allocator_ 00007ff9`2a6dd058 -> base::PartitionAllocatorGeneric 00007ff9`2a6df6e8
extent(s): 0000318a`8ee00000-0000318a`8f200000 (2)
0:027> !buffer_allocator
WTF::Partitions::buffer_allocator_ 00007ff9`2a6dd060 -> base::PartitionAllocatorGeneric 00007ff9`2a6e1d40
extent(s): 00007c17`cd400000-00007c17`cf000000 (14)
0:027> !layout_allocator
WTF::Partitions::layout_allocator_ 00007ff9`2a6dd068 -> base::SizeSpecificPartitionAllocator<1024> 00007ff9`2a6e4398
extent(s): 000029cc`c4e00000-000029cc`c5000000 (1)
例えば Layout tree オブジェクトについては、new 演算子が以下のようにオーバーロードされていて、Layout パーティションの Alloc 関数を呼ぶようになっています。シンプルで分かりやすいですね。
void* LayoutObject::operator new(size_t sz) {
DCHECK(IsMainThread());
return WTF::Partitions::LayoutPartition()->Alloc(
sz, WTF_HEAP_PROFILER_TYPE_NAME(LayoutObject));
}
Partition を表すクラスには PartitionAllocatorGeneric と SizeSpecificPartitionAllocator の 2 種類があります。Chromium に存在する 4 つの Partition のうち、Layout Partition が SizeSpecific で、他の 3 つは全て Generic です。
デザイン上、SizeSpecific Partition の方が速くなります。理由の一つは、後述するようにメモリ割り当て時の Bucket 選択が SizeSpecific Partition ではコンパイル時に完了しているためです。Generic Partition ではビット計算が必要です。また別の理由として、Generic Partition ではメモリの割当/解放時にスピンロックによるスレッド間の排他制御を行なうのに対し、SizeSpecific Partition では排他制御を行なわないという違いがあります。このため、スレッド間で共有されるオブジェクトを SizeSpecific Partition によって割り当てることはできません。Layout オブジェクトは、単一スレッドでしか使われないことが保証されているのだと思います。
Bucket, Slot
各 Partition は Bucket という構造を複数持っており、各 Bucket が、Slot という Bucket 毎に決められた固定長サイズの領域を単位として確保したメモリ領域を管理します。
例えば Slot サイズが 8 バイトである Bucketは、1 から 8 バイトまでのメモリ領域を管理することができます。仮に 7 バイトの領域が要求された場合でも、8 バイトの Slot を 1 つ用意し、末尾の 1 バイトは未使用のままにしておきます。無駄なスペースができることになりますが、そのおかげで各領域にメタ情報を埋め込まずに Slot を敷き詰めることができるという利点があります。
下記出力では、FastMalloc Partition には 0~135 (1 列目) の 136 Bucket があり、Bucket 0 の Slot サイズは 8 バイト (2 列目)、Bucket 135 は 0xf0000 バイトであることが分かります。この Bucket の分け方は全ての PartitionAllocatorGeneric に共通で、Buffer Partition や ArrayBuffer Partition も同様です。
0:027> !fast_malloc_allocator -buckets 00007ff9`2a6dd090
WTF::Partitions::fast_malloc_allocator_ 00007ff9`2a6dd050 -> base::PartitionAllocatorGeneric 00007ff9`2a6dd090
extent(s): 0000197e`6a600000-0000197e`6b000000 (5)
0 00007ff9`2a6de5e0 8 4 0000197e`6a601120 199!
8 00007ff9`2a6de6e0 10 4 0000197e`6ac013e0 1023
0000197e`6ac01220 996
0000197e`6ac013a0 831
0000197e`6ac01580 352
12 00007ff9`2a6de760 18 12 0000197e`6ac01080 2046
0000197e`6aa011e0 1985
0000197e`6ac015a0 453
...
134 00007ff9`2a6df6a0 e0000 224 g_sentinel_page
135 00007ff9`2a6df6c0 f0000 240 g_sentinel_page
一方 Layout Partition のデータ型は、SizeSpecificPartitionAllocator<1024> です。Bucket の数は 128 で、Slot サイズは単純に 8 バイト刻みになっています。
0:027> !layout_allocator -buckets 00007ff9`2a6e4398
WTF::Partitions::layout_allocator_ 00007ff9`2a6dd068 -> base::SizeSpecificPartitionAllocator<1024> 00007ff9`2a6e4398
extent(s): 000029cc`c4e00000-000029cc`c5000000 (1)
0 00007ff9`2a6e4488 8 4 g_sentinel_page
1 00007ff9`2a6e44a8 8 4 g_sentinel_page
2 00007ff9`2a6e44c8 10 4 g_sentinel_page
...
126 00007ff9`2a6e5448 3f0 16 g_sentinel_page
127 00007ff9`2a6e5468 3f8 4 g_sentinel_page
SuperPage, PartitionPage
PartitionAlloc は OS が提供するヒープを使いませんが、最終的なメモリの確保では当然 OS の助けが必要です。Windows では、VirtualAlloc を使ってメモリ ページを確保しています。
PartitionAlloc では、まず SuperPage という 2MB の連続した領域を VirtualAlloc で予約します。次に SuperPage を 16KB の PartitionPage という単位に区切ります。2MB / 16KB = 128 なので、SuperPage の中には 128 の PartitionPage ができます。ただし最初の PartitionPage 部分は、各 PartitionPage のメタ情報を保存するために使います。具体的には、16KB のうち、初めの 4K と 末尾の 8K は GuardPage としてページをコミットせずに MEM_RESERVE のままにしておき、残りの 4K をメタ情報の保存に使います。
PartitionPage のメタ情報は base::PartitionPage クラスで表現され、サイズは 0x20 バイトです。4K/0x20 = 128 となることから、4K の領域には 128 個分の 1 SuperPage 内全ての PartitionPage のメタ情報をぴったり収めることができます。以下の図は SuperPage のレイアウトを図示したものです。(雑な図やな・・・)

SlotSpan
前述の通り、PartitionAlloc は Bucket という単位において Slot という固定長のデータを敷き詰めて管理しています。同時に、OS から確保した SuperPage を PartitionPage という 16K の領域に切り分けて管理しています。これら 2 つの軸を結び付けるのが SlotSpan という単位です。
Slot サイズは 8 の倍数で、PartitionAllocatorGeneric の Partition では 8 から 0xf0000 まで様々な種類がありました。SlotSpan とは、幾つかの PartitionPage を並べた領域上で、なるべく無駄が出ないように Slot を敷き詰めたときの連続した PartitionPage の領域を意味します。例えば Slot サイズが 56 バイトの場合、Slot を 2 つの連続した PartitionPage に敷き詰めると、585 Slot を並べることができ、585 * 56 = 32760 = 16K * 2 - 8 となるため、8 バイトが未使用のまま余ります。別の例として、Slot が 704 バイトの場合は、64 Slot 並べると 704 * 64 = 4K * 11 となり、これを連続した 3 つの PartitionPage 上に敷き詰めるとちょうど 1 ページ分が余ります。このときの連続した PartitionPage のことを SlotSpan と呼びます。
PartitionAlloc は、確保した SuperPage を SlotSpan 単位で切り出して各 Bucket に割り振っていきます。具体的には、base::PartitionBucket クラスが ParitionPage のメタ情報へのポインター (base::PartitionPage クラス) をリンクトリストの形式で保持しています。
例えば以下の出力は、前述の FastMalloc Partition の Bucket 12 をダンプしたものです。Slot が 0x18 バイトで、SlotSpan が12 システム ページ、すなわち 3 PartitionPage になっています。SlotSpan には 2048 個の Slot を隙間なく敷き詰めることができます。Bucket には 3 つの PartitionPage が紐づけられていて、SuperPage 0000197e`6ac00000 における #4 と #45 番目の PartitionPage、SuperPage 0000197e`6aa00000 における #15 の PartitionPage がリストに存在しています。この例では、3 つの PartitionPage 全てに空き Slot が存在しています。
0:027> !bucket 00007ff9`2a6de760
slot_size (bytes): 0x18
num_system_pages_per_slot_span: 0n12
total slots per span: 0n2048
active pages / num_allocated_slots:
0000197e`6ac00000 #4 0000197e`6ac01080 2046
0000197e`6aa00000 #15 0000197e`6aa011e0 1985
0000197e`6ac00000 #45 0000197e`6ac015a0 453
メモリ確保処理
ここまで、Partition, Bucket, Slot, SuperPage, PartitionPage, SlotSpan という PartitionAlloc を構成する単位を見てきました。これらを活用してメモリを確保する手順を紹介します。コードとしては PartitionRootBase::AllocFromBucket に実装されています。
Fast path
特定の Partition に対してメモリ確保が要求されると、PartitionAlloc はまず、要求されたサイズを保持するのに十分は Slot サイズを持つ Bucket を選択します。前述の通り、Bucket は PartitionPage のリストを持っています。もし選択した Bucket が空き Slot を持つ PartitionPage をリストの先頭に持っている場合、そこからすぐに空き Slot を確保できます。前述の例では、先頭の 0000197e`6ac01080 に空き Slot があるため、この Fast path を実行することができます。PartitionPage のメタ情報をダンプすると、
0:027> !page 0000197e`6ac01080
bucket: 00007ff9`2a6de760 (total slots=2048)
num_allocated_slots: 2046
num_unprovisioned_slots: 0
free slots (2):
0000197e`6ac1a818 0000197e`6ac1a758
残っている空き Slot は 0000197e`6ac1a818 と 0000197e`6ac1a758 です。この Bucket に対して要求が来ると、先頭の 0000197e`6ac1a818 を要求元に返し、空き Slot リストの先頭を次の 0000197e`6ac1a758 に更新します。
この Fast path がうまくいく場合、空き Slot からの先頭要素の削除だけで領域が確保できるので、計算量は O(1) となります。
Slow path
Active Page の先頭に空き Slot がない場合、PartitionBucket::SlowPathAlloc に実装された Slow path を実行します。まず試みるのは、Active Page のリストを先頭から逐次検索し、空き Slot を持つ PartitionPage を探すことです。もし見つかれば、その PartitionPage をリストの先頭に更新し、空き Slot の先頭を返します。例えばこのような場合、
0:000> !bucket @rcx
slot_size (bytes): 0x80
num_system_pages_per_slot_span: 0n4
total slots per span: 0n128
active pages / num_allocated_slots:
00004a10`c3e00000 #62 00004a10`c3e017c0 128
00004a10`c4600000 #80 00004a10`c4601a00 113
0:000> !ppage 00004a10`c4601a00
bucket: 00007ffb`17143690 (total slots=128)
num_allocated_slots: 113
num_unprovisioned_slots: 0
free slots (15):
00004a10`c4743380 00004a10`c4743900 00004a10`c4743800 00004a10`c4743a00
00004a10`c4743a80 00004a10`c4743b00 00004a10`c4743b80 00004a10`c4743c00
00004a10`c4743c80 00004a10`c4743d00 00004a10`c4743d80 00004a10`c4743e00
00004a10`c4743e80 00004a10`c4743f00 00004a10`c4743f80
Slot は 0x80 バイトで、SlotSpan に詰め込める最大 Slot 数は 128 です。先頭の PartitionPage ではすでに 128 Slot を割り当て済みなので、空き Slot がありません。しかし次の 00004a10`c4601a00 では割り当て済みの Slot 数が 113 で、空き Slot が 15 残っています。したがって Slow path を実行すると、先頭の 00004a10`c4743380 を返し、00004a10`c4601a00 を Bucket の Active List の先頭にします。これで次回は Fast path が使えるようになります。
Active Page のリストに空き Slot が見つからなかった場合は、Active Page をどこからか入手してくる必要があります。これまで触れていませんでしたが、Bucket は Active Page の他に Empty Page と Decomitted Page という 2 つのリストを持っています。これらはその名の通り、何の Slot も割り当てられていない空の PartitionPage です。これらのリストが空でなければ、先頭の要素を取り出して空き Slot リストを作成し、Active Page のリストに加えることができます。名前から判断すると、Empty Page はコミット済みで、Decomitted Page は予約だけされているページとなりますが、PartitionBucket::SlowPathAlloc のコメントによると、Empty Page でもデコミットされている可能性があるようです。デコミットされたページを使う場合は、SlotSpan の範囲を全てコミットしてから使います。
Empty Page と Decomitted Page も空だった場合はいよいよ最終手段で、Bucket の上位にある Partition から PartitionPage を切り出してくる必要があります。Generic Partition と SizeSpecific Partition はともに base::PartitionRootBase を基底クラスとしており、PartitionBucket::SlowPathAlloc はその第一引数として PartitionRootBase へのポインターを受け取っています。PartitionRootBase は、現在使用中の SuperPage の情報、その SuperPage のどこまでをコミットしたか、そして次に確保すべき SuperPage の位置を保持しています。これらの情報を使って、次に使う SlotSpan 分の PartitionPage をコミットし、空き Slot リストを作ることができます。
最終手段である PartitionRootBase から PartitionPage を作る処理は、PartitionBucket::AllocNewSlotSpan に実装されています。ここで興味深いのは、新たに SuperPage を発行する必要があるときに、その SuperPage は現在使っている SuperPage と近接するように OS に要求している部分です。Windows であれば VirtualAlloc の第一引数です。理由がコメントとして書かれています。
// Need a new super page. We want to allocate super pages in a continguous
// address region as much as possible. This is important for not causing
// page table bloat and not fragmenting address spaces in 32 bit
// architectures.
これは自然な発想ではあるのですが、もし自分がこれを書く立場だったらこんな工夫には気付かない気がします。というか全体を通して、自然な工夫がいちいち当たり前に丁寧に実装されているのが Chromium の強みだと思います。いやー、Google 様凄いっす。
メモリ解放処理
解放は当然割り当て処理の逆で、基本的には、解放するアドレスを該当する PartitionPage の空き Slot リストの先頭に追加するだけです。ここでのトリックは、アドレスが与えられれば、そのアドレスが所属する PartitionPage や Bucket が簡単に分かるように PartitionAlloc がデザインされていることです。
まず、アドレスの下位 20 bit を 0 クリアすると、それがそのまま SuperPage の開始アドレスになります。SuperPage は、16K の PartitionPage が 128 個連続した領域なので、そのアドレスが何番目の PartitionPage にあるのかも単純なビット計算で分かります。そして、所属する PartitionPage のメタ情報は、SuperPage 内の (GuardPage を除いて) 先頭部分に 128 個並んでいるので、与えられたアドレスの PartitionPage のメタ情報も簡単に得られます。そのメタ情報に、Bucket や空き Slot のリストが含まれています。デバッガーでも辿れるようにしました。
0:017> g
Breakpoint 0 hit
chrome_child!WTF::Partitions::FastFree:
00007ffb`12baf4c2 55 push rbp
0:000> dv
p = 0x00004e05`2d4ede20
0:000> !slot 0x00004e05`2d4ede20
SuperPage 00004e05`2d400000 #59
base::PartitionPage 00004e05`2d401760
0:000> !page 00004e05`2d401760
bucket: 00007ffb`1713e6e0 (total slots=1024)
num_allocated_slots: 1024
num_unprovisioned_slots: 0
free slots (0):
メモリ確保の時の Slow path のように、解放にも Slow path があり、PartitionPage::FreeSlowPath に実装されています。詳細は端折りますが、基本的には Empty page や Decommitted page の管理を行なっています。例えば、Free したことで PartitionPage の使用 Slot が 0 になった場合は、その PartitionPage を Empty Page のリストに追加して、必要に応じてそのページを Decommit します。また、空き Slot が 0 であった PartitionPage に Slot が 1 つ戻された場合にも、その PartitionPage が full page ではなくなった、というフラグの管理が必要です。
Direct Map
Bucket の Slot サイズの上限は 0xf0000 なので、それより大きいデータに合致する Bucket は存在せず、Direct Map という別のロジックを使います。
もし要求されたサイズが 0xf0001 以上だった場合、PartitionGenericSizeToBucket 関数の結果として PartitionBucket::sentinel_bucket_ というダミーの Bucket が返されます。これは Partition のルックアップ テーブルである PartitionRootGeneric::bucket_lookups をそのように初期化しているためです。この sentinel_bucket_ に対して割り当て要求を出すと、chrome_child!base::PartitionDirectMap が呼ばれて Direct Map の処理が始まります。
端的に言えば Direct Map の処理とは、要求されたサイズに見合った領域を (Windows では VirtualAlloc を使って) 直接 OS から割り当ててもらうことです。管理を楽にするため、割り当てられた領域に対して見せかけの SuperPage、PartitionPage、PartitionBucket などの構造を組み立てます。割り当てられた領域は、Partition オブジェクトがリストとして保持します。具体的には base::PartitionRootBase::direct_map_list です。
デバッガーで見てみます。
0:027> !buffer_allocator 00007ff9`2a6e1d40
WTF::Partitions::buffer_allocator_ 00000000 -> base::PartitionAllocatorGeneric 00007ff9`2a6e1d40
extent(s): 00007c17`cd400000-00007c17`cf000000 (14)
0:027> dt chrome_child!base::PartitionRootBase 00007ff9`2a6e1d40 direct_map_list->*
+0x058 direct_map_list :
+0x000 next_extent : 0x000067e4`80201080 base::PartitionDirectMapExtent
+0x008 prev_extent : (null)
+0x010 bucket : 0x00004823`f9401060 base::PartitionBucket
+0x018 map_size : 0x26b000
0:027> !bucket 0x00004823`f9401060
slot_size (bytes): 0x25d000
num_system_pages_per_slot_span: 0n0
total slots per span: 0n0
active pages / num_allocated_slots:
00004823`f9400000 #1 00004823`f9401020 1
0:027> !page 00004823`f9401020
bucket: 00004823`f9401060 (total slots=0)
num_allocated_slots: 1
num_unprovisioned_slots: 0
free slots (0):
0x25d000 という Bucket としてはあり得ないサイズが Slot として見えています。この近傍の領域を !address で確認すると、+0x2000 から +0x4000 のところで GuardPage が入っています。なぜか先頭のページはコミットされたままです。
+ 4823`f9400000 4823`f9402000 0`00002000 MEM_PRIVATE MEM_COMMIT PAGE_READWRITE
4823`f9402000 4823`f9404000 0`00002000 MEM_PRIVATE MEM_RESERVE
4823`f9404000 4823`f9670000 0`0026c000 MEM_PRIVATE MEM_COMMIT PAGE_READWRITE
Direct Map では、ランダムなアドレスから領域を確保する工夫がなされており、VirtualAlloc の第一引数に GetRandomPageBase() で取得したランダムなアドレスを渡して Direct Map 領域を取得します。確証はありませんが、この理由は安全性の考慮であり、同じサイズの領域が同じ場所に確保されることを避けているのだと思います。ランダムなアドレスを生成するコードは、プラットフォーム (OS/Bitness/Architecture) 毎に #if を使って細かくロジックが用意されていて、相当作りこまれている印象を受けます。
補足
本筋では触れなかった細かい動作を 3 点ほど補足します。
PartitionAllocatorGeneric における Bucket の刻み方
PartitionAllocatorGeneric が保持する Bucket の数は 136 です。微妙に中途半端ですが、これはある程度広い範囲のサイズを対数的に均等にカバーできるように Bucket を配置した結果です。
確保する領域のサイズが X だとして、その最上位ビット (Most Significant Bit) の右端を 1 とした位置を Order と呼ぶことにします。例えば X が 8 から 15 までなら最上位ビットは 8 なので 4 です。数学的には $\lfloor \log_2 x \rfloor + 1$ でしょうかね。
ここで、各 Order 毎に 8 つの Bucket を均等に用意するように決めます。例えば、Order 4 に属するのは $64 \le x \lt 128$ ですが、これを Slot サイズが 64, 72, 80, 88, 96, 104, 112, 120 である 8 つの Bucket でカバーすることにします。ただし Slot の granularity は 8 バイトと決め、8 バイト境界に合わない Slot サイズの Bucket は無効化します。例えば Order 5 では 16, 18,..., 30 バイトを Slot とする Bucket を用意することになりますが、8 バイト境界に合うのは 16 バイトと 24 バイトを Slot とする Bucket の 2 つだけです。また、Order の下限を 4、上限を 20 に決めます。
上記を分かりやすく表にしたものが以下の図です。4 から 20 までの Order 毎に 8 つの Bucket を用意し、各セルは Slot のサイズを表しています。無効な Bucket (グレー表示) も含めると、(20 - 4 + 1) * 8 = 136 の Bucket があり、これが PartitionAllocatorGeneric::buckets_ の要素数が 136 になっている理由です。
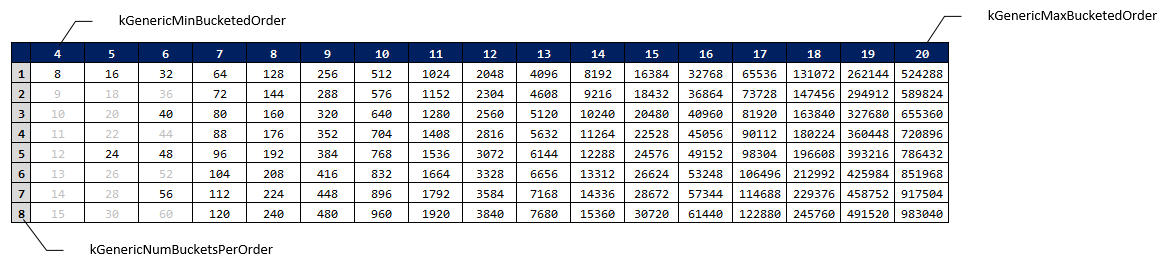
こうして決めると、最後の Bucket 135 の Slot サイズが 983040 (= 0xf0000) バイトとなるため、983041 バイト以上のメモリに対して Direct Map を使うことになります。
PartitionAllocatorGeneric は、サイズの予想がつかない汎用なデータをなるべく効率よく確保できるように Bucket を設計しています。しかしその汎用性のため、サイズが大きければ大きいほど Slot サイズと確保サイズの差が大きくなり、メモリの無駄が大きくなります。
一方 Layout Partition では、base::SizeSpecificPartitionAllocator を使って、Slot の上限サイズを 0x3f8 (= 1016) に抑える代わりに、8 バイト刻みの Slot をすべて用意することで、メモリの無駄を減らすことができます。これは 1024 バイト以上の Layout オブジェクトが存在しないか、存在する可能性が著しく低いからだと考えられます。
Layout Partition における Bucket 選択に対するコンパイラー最適化
Layout Partition における Bucket 選択では、コンパイラーによる最適化によってとても美しいコードが生成されています。
Layout オブジェクトの作成は、 blink::LayoutObject::CreateObject で行われ、style.Display() の値によってどのオブジェクトを new するかを決める switch 文があります。この switch 文は当然ジャンプテーブルに変換されています。アセンブリは以下の通りです。
chrome_child!blink::LayoutObject::CreateObject+0x6b [C:\b\c\b\win64_clang\src\third_party\WebKit\Source\core\layout\LayoutObject.cpp @ 234]:
234 00007ff9`264dc71b 83e01f and eax,1Fh
234 00007ff9`264dc71e 488d0d3f090000 lea rcx,[chrome_child!blink::LayoutObject::CreateObject+0x9b4 (00007ff9`264dd064)]
234 00007ff9`264dc725 48630481 movsxd rax,dword ptr [rcx+rax*4]
234 00007ff9`264dc729 4801c8 add rax,rcx
234 00007ff9`264dc72c ffe0 jmp rax
case ブロックの数は 25 なので、ジャンプテーブルのエントリも 25 個あります。上記アセンブリから、それぞれのエントリがジャンプテーブル 00007ff9`264dd064 の先頭からのオフセットになっていることが分かります。
0:027> dd 00007ff9`264dd064
00007ff9`264dd064 fffffa33 fffff6ca fffffa7d fffff6ca
00007ff9`264dd074 fffff7c7 fffff7c7 fffff733 fffff733
00007ff9`264dd084 fffff733 fffffae6 fffff811 fffff811
00007ff9`264dd094 fffffb30 fffffb99 fffff85b fffff85b
00007ff9`264dd0a4 fffff8a5 fffff8a5 fffff8ef fffff8ef
00007ff9`264dd0b4 fffffcc2 fffff6ca fffffcc2 fffff939
00007ff9`264dd0c4 fffff939 cccccccc cccccccc 2442428a
それぞれのジャンプ先をダンプします。
0:027> .for (r $t1=0; @$t1 < 19; r $t1=@$t1+1) {? (dwo(00007ff9`264dd064 + @$t1 * 4) + ffffffff`00000000 + 00007ff9`264dd064)}
Evaluate expression: 140708066216599 = 00007ff9`264dca97
Evaluate expression: 140708066215726 = 00007ff9`264dc72e
Evaluate expression: 140708066216673 = 00007ff9`264dcae1
Evaluate expression: 140708066215726 = 00007ff9`264dc72e
Evaluate expression: 140708066215979 = 00007ff9`264dc82b
Evaluate expression: 140708066215979 = 00007ff9`264dc82b
Evaluate expression: 140708066215831 = 00007ff9`264dc797
Evaluate expression: 140708066215831 = 00007ff9`264dc797
Evaluate expression: 140708066215831 = 00007ff9`264dc797
Evaluate expression: 140708066216778 = 00007ff9`264dcb4a
Evaluate expression: 140708066216053 = 00007ff9`264dc875
Evaluate expression: 140708066216053 = 00007ff9`264dc875
Evaluate expression: 140708066216852 = 00007ff9`264dcb94
Evaluate expression: 140708066216957 = 00007ff9`264dcbfd
Evaluate expression: 140708066216127 = 00007ff9`264dc8bf
Evaluate expression: 140708066216127 = 00007ff9`264dc8bf
Evaluate expression: 140708066216201 = 00007ff9`264dc909
Evaluate expression: 140708066216201 = 00007ff9`264dc909
Evaluate expression: 140708066216275 = 00007ff9`264dc953
Evaluate expression: 140708066216275 = 00007ff9`264dc953
Evaluate expression: 140708066217254 = 00007ff9`264dcd26
Evaluate expression: 140708066215726 = 00007ff9`264dc72e
Evaluate expression: 140708066217254 = 00007ff9`264dcd26
Evaluate expression: 140708066216349 = 00007ff9`264dc99d
Evaluate expression: 140708066216349 = 00007ff9`264dc99d
全部出力すると長いので、2 つほど適当に抜粋して case ブロックのアセンブリの先頭を見てみます。
chrome_child!WTF::Partitions::LayoutPartition [C:\b\c\b\win64_clang\src\third_party\WebKit\Source\core\layout\LayoutObject.cpp @ 239] [inlined in chrome_child!blink::LayoutObject::CreateObject+0x3e7 [C:\b\c\b\win64_clang\src\third_party\WebKit\Source\core\layout\LayoutObject.cpp @ 239]]:
00007ff9`264dca97 488b15ca052004 mov rdx,qword ptr [chrome_child!layout_allocator_ (00007ff9`2a6dd068)]
00007ff9`264dca9e 488bb230030000 mov rsi,qword ptr [rdx+330h]
00007ff9`264dcaa5 488b3e mov rdi,qword ptr [rsi]
00007ff9`264dcaa8 4885ff test rdi,rdi
chrome_child!WTF::Partitions::LayoutPartition [C:\b\c\b\win64_clang\src\third_party\WebKit\Source\core\layout\LayoutObject.cpp @ 252] [inlined in chrome_child!blink::LayoutObject::CreateObject+0x17b [C:\b\c\b\win64_clang\src\third_party\WebKit\Source\core\layout\LayoutObject.cpp @ 252]]:
00007ff9`264dc82b 488b1536082004 mov rdx,qword ptr [chrome_child!layout_allocator_ (00007ff9`2a6dd068)]
00007ff9`264dc832 488bb2b0060000 mov rsi,qword ptr [rdx+6B0h]
00007ff9`264dc839 488b3e mov rdi,qword ptr [rsi]
00007ff9`264dc83c 4885ff test rdi,rdi
2 つ目の mov 命令で、rdx レジスターに加えるオフセットが異なっています。結論から言うと、ここが Bucket 選択のコードであり、コンパイル時に Bucket 選択が完了していることを意味します。
最初の例である 00007ff9`264dca97 から始まる case 文は、ジャンプ テーブルの最初のエントリなので case EDisplay::kInline に相当し、new するのは blink::LayoutInline クラスです。Partition の構造を見ると、
0:027> dt chrome_child!layout_allocator_
0x00007ff9`2a6e4398
+0x000 partition_root_ : base::PartitionRoot
+0x0f0 actual_buckets_ : [128] base::PartitionBucket
0:027> ?? sizeof(base::PartitionBucket)
unsigned int64 0x20
Bucket の配列 actual_buckets_ のオフセットは +f0 であり、各要素のサイズは 0x20 です。アセンブリの出力から、参照しているのは +330 です。(0x330 - 0xf0) / 0x20 = 0x12 なので、18 番目の Bucket を選択しているらしいことが分かります。そこで Bucket の一覧を出力すると
0:027> !layout_allocator -buckets 00007ff9`2a6e4398
WTF::Partitions::layout_allocator_ 00000000 -> base::SizeSpecificPartitionAllocator<1024> 00007ff9`2a6e4398
extent(s): 000029cc`c4e00000-000029cc`c5000000 (1)
0 00007ff9`2a6e4488 8 4 00007ff9`2a5b85d0 0
1 00007ff9`2a6e44a8 8 4 00007ff9`2a5b85d0 0
...
18 00007ff9`2a6e46c8 90 16 000029cc`c4e01180 68!
...
127 00007ff9`2a6e5468 3f8 4 00007ff9`2a5b85d0 0
Bucket 18 の Slot サイズは 0x90 となっていて、case EDisplay::kInline で確保する blink::LayoutInline のサイズと一致していることが確認できます。
0:027> ?? sizeof(blink::LayoutInline)
unsigned int64 0x90
SlotSpan のサイズの決め方
SlotSpan のサイズは、なるべく無駄が出ないように Slot を敷き詰められる程度の PartitionPage の数を決めています。この部分の計算は、地味に Bucket を初期化するときにちまちまとやっています。コードで言うと PartitionBucket::get_system_pages_per_slot_span で、Slot をシステム ページ i 個分の領域に並べたときに、実際にどれだけの未使用領域が出るのかを for 文でループしながら計算し、未使用領域が最小で済むページ数で SlotSpan のサイズを確定しています。コードを見るだけだと理解が難しかったので、Excel で表を作って計算してみました。下図は、Slot が 1152 バイトだった時の表で、採用されるのは i = 9 のときです。これはすなわちシステム ページを 9 個分、PartitionPage が 16K なので PartitionPage を 3 つ並べると、使われないシステム ページが 3 つ余るものの、Slot は完全に敷き詰められるので他と比べて無駄が最小になるためです。
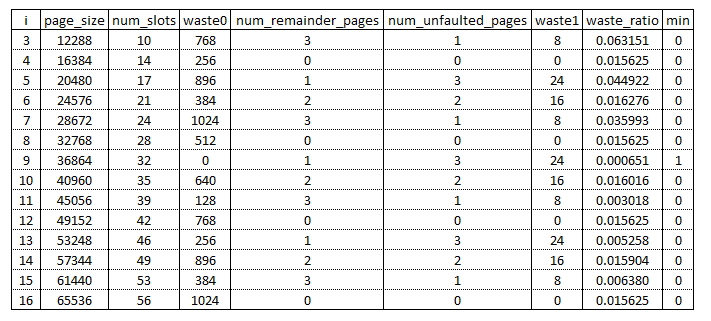
ただし、現在の PartitionBucket::get_system_pages_per_slot_span の実装にはコメントによって疑問が残されています。改善の余地がありそうです。Contribute チャンス・・?
おわりに
以上、Chromium の PartitionAlloc 実装の紹介でした。ある日なんとなく、Chromium における動的メモリ確保の実装と、UAF 攻撃に対する防御策 (IE/Edge における MemGC みたいな) はどうなっているのかと思い立って調べ始めました。そしてあまりの実装の美しさに感動しました。というか、自然な工夫を当たり前のように全部実装してあるのが凄い。いやほんと Google 凄いっすわ。
なお、将来的には以下の計画があるみたいです (partition_alloc.h のコメントより抜粋)。サイズ毎の Bucket は不要になってしまうのか・・・。
// The following security properties could be investigated in the future:
// - Per-object bucketing (instead of per-size) is mostly available at the API,
// but not used yet.
// - No randomness of freelist entries or bucket position.
// - Better checking for wild pointers in free().
// - Better freelist masking function to guarantee fault on 32-bit.
コードを読み解くことで、placement new 演算子や Bloom Filter、LIKELY/UNLIKELY などを今まで知らず、自分が無知であることを改めて実感しました。やはり優秀な人が書いた生きたコードを読むのは本を読むよりも勉強になりますね。
メモリ管理のもう一つの機能、Oilpan については次回やります。Oilpan 用デバッガー エクステンションも絶賛開発中です。