はじめに
自動運転を実現するアプローチの1つとして、センサーデータから自動運転車両の未来軌跡予測(生成)までをend-to-endで実装する手法が研究されています。本記事では、自動運転車両が他車両とのインタラクションのある環境下で自動運転を実現する技術について、Uber ATGのSergioさんが執筆した論文を紹介します。図番号と文献番号は論文内の記載のまま表記します。
Implicit Latent Variable Model for Scene-Consistent Motion Forecasting
ECCV 2020
Paper: https://www.ecva.net/papers/eccv_2020/papers_ECCV/papers/123680613.pdf
この論文をざっくり言うと、グラフニューラルネットワークを使い、自動運転車両と周辺車両の関係性を潜在空間にエンコードし、自動運転車両とその周辺車両の未来軌跡予測を生成する技術です。(論文の理解不足から誤った記述があるかもしれませんが,ご了承ください.)
論文のポイント
- Lidarのセンサーデータと地図情報を入力とし、他車両を認識し特徴量として出力させる。
- 自動運転車両と他車両の特徴量から提案手法のImplicit Latent Variable Model with Deterministic Decoder(ILVM)によって、自動運転車両と周辺車両の分布ではない(文中はdeterministicと記述)複数のの未来軌跡を生成(サンプリング)する。
- 生成されたサンプルからSOTAのモーションプラン手法[49]を適用し、安全性と快適性を評価するコスト関数によって最適なサンプルを選択する。(このコスト関数の説明は記述されていない)
手法の構成要素
Actor Feature Extraction
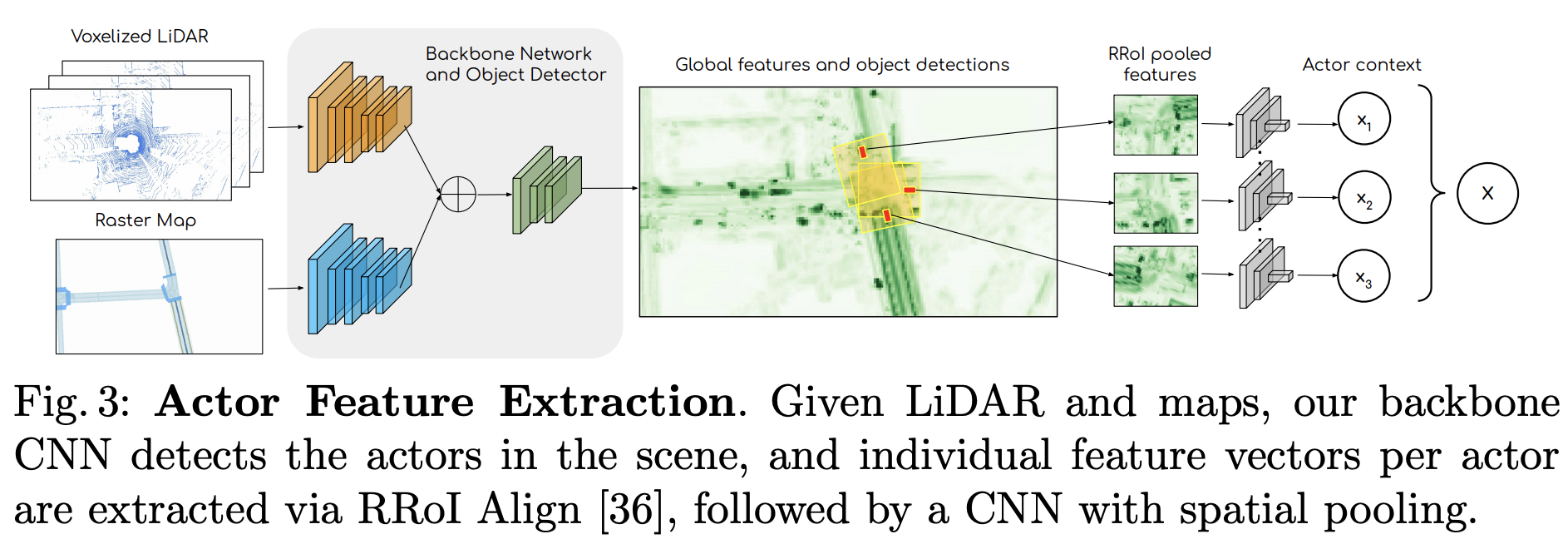
図3は過去の時系列センサーデータと高精度地図から車両ごとの特徴量を抽出する流れを説明しています。この部分で物体(車両)認識を行い、車両毎の特徴量を出力させている。モデルは[10][54]を参考にCNNベースのDNNを実装している。
Inplicit Latent Variable Model
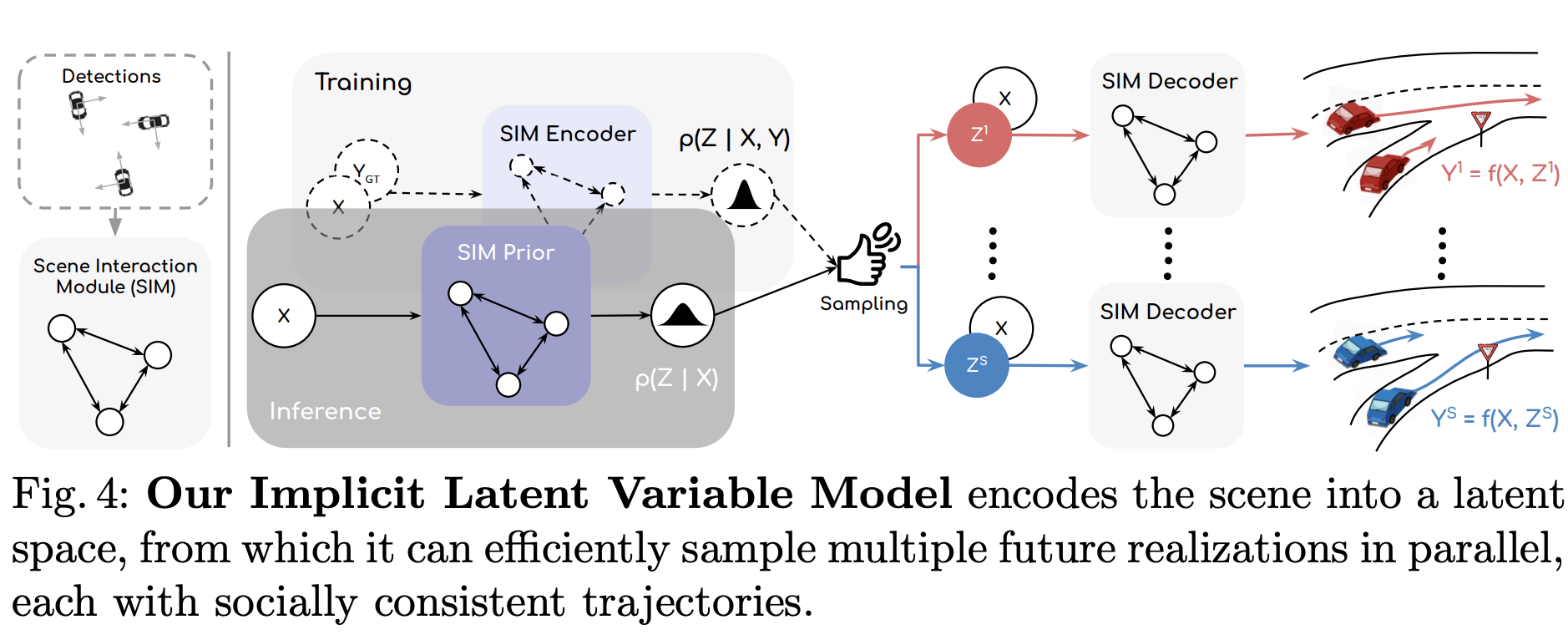
この部分が論文のContributionである。Fig.4によるとコアの部分はScene Interaction Module(SIM)であり、任意の車両と他の車両間の関連性をグラフで表現されている。この表現方法をエンコードおよびデコードに使い、SIMを複数サンプリングし全車両の複数の未来軌跡を出力している。
Motion Planner
自動運転車両を制御するために[49]の手法によって最適なサンプルを選択している。下記の式のcは安全性と快適性を評価するコスト関数であり、この関数の設計によって自動運転車両の性格(攻めた運転とか慎重な運転とか)を如何様にも持たせることができる。本論文の第4章実験評価ではその中身の説明はない。
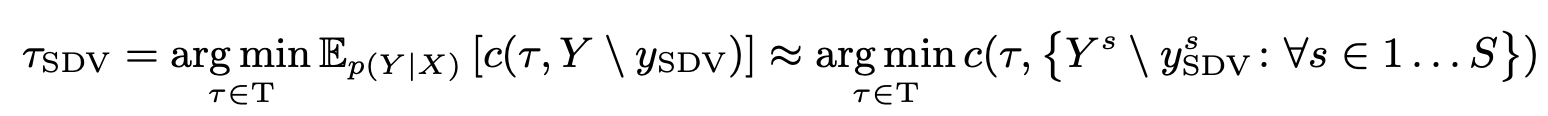
実験評価
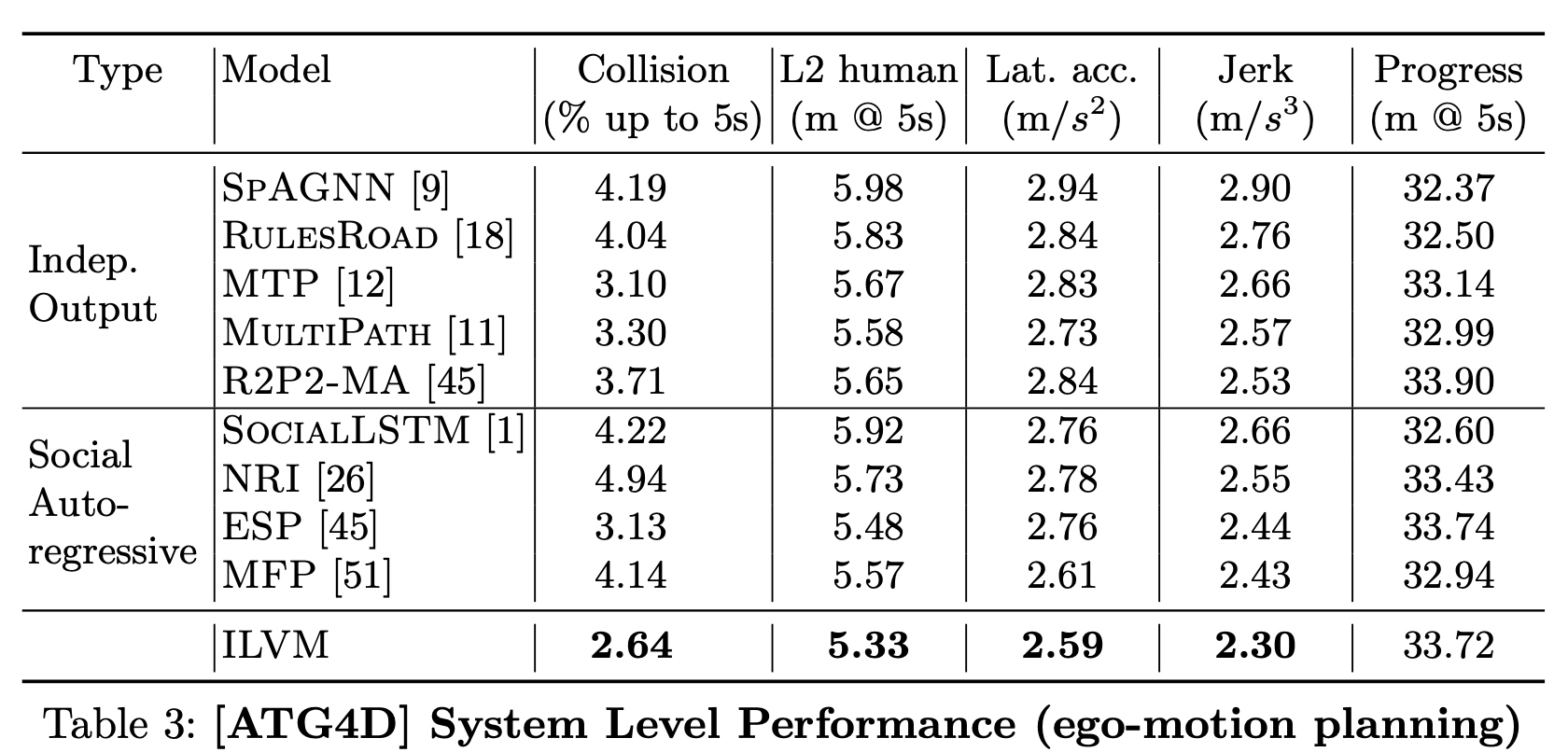
Collisionは5秒先までに発生する衝突率であり、L2 humanは5秒先までの自動運転車両と他車両との距離であり、他の項目は論文中に詳しく説明はないが、おそらく快適性を評価する指標と思われる。結論として、安全性と快適性ともにBaselineを上回っていると主張している。
おわりに
車両(エージェント)間の関係性をグラフニューラルネットを利用し、生成モデルとして学習させサンプル生成させるところまではend-to-endであるが、後処理において自動運転車両の未来軌跡を独立して選択できることが非常に面白いとおもいます。これによって、最終的な出力はend-to-endで決定されず、任意の手法で意思決定を実装することができます。このことは[39]で既に研究された方法とコンセプトは同じですが、その計算過程のexplicitnessのレベルが異なります。この差が車両運動のパフォーマンスへどれくらい影響するか検証されると良いと思います。
参考文献
論文記載の文献番号で記載しています。
[10]Casas, S., Luo, W., Urtasun, R.: Intentnet: Learning to predict intention from raw sensor data. In: Conference on Robot Learning (2018)
[39]Okamoto, M., Perona, P., Khiat, A.: DDT: Deep driving tree for proactive planning in interactive scenarios. In: 2018 21st International Conference on Intelligent Transportation Systems (ITSC). pp. 656–661. IEEE (2018)
[49]Sadat, A., Ren, M., Pokrovsky, A., Lin, Y.C., Yumer, E., Urtasun, R.: Jointly learnable behavior and trajectory planning for self-driving vehicles. arXiv preprint arXiv:1910.04586 (2019)
[54] Yang, B., Luo, W., Urtasun, R.: Pixor: Real-time 3d object detection from point clouds. In: Proceedings of the IEEE CVPR (2018)