目的
久しぶりの投稿となりました!!
現在、大学の研究室でDeeplearningを使ったClassificationをしていることもあるので基本的な機械学習も合わせて勉強していき、アウトプットしていきたいと思います。
*今回の記事は「PythonによるAI・機械学習・深層学習アプリのつくり方」という書籍を参考にしています。
手順
(1)データの取り込み
(2)前処理
(3)学習
(4)テスト
(1)データの取り込み
今回はgithubからデータを落とし込んできました。
以下のサイトからcsv形式でデータを保存します。
https://raw.githubusercontent.com/pandas-dev/pandas/master/pandas/tests/data/iris.csv
iris.py
# アヤメデータの読み込み
iris_data = pd.read_csv("iris.csv", encoding="utf-8")
実際に表示して見ると以下のようになります。
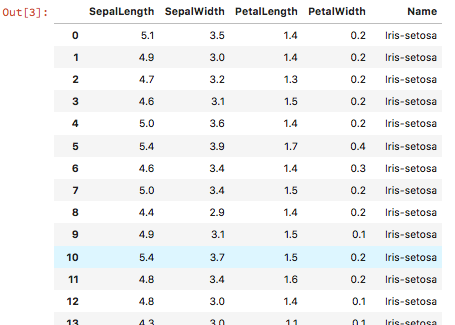
(2)前処理
次にこのデータを入力データとラベル(解)に分けましょう。
iris.py
# アヤメのデータをラベルと入力データに分離
y = iris_data.loc[:,"Name"]
x = iris_data.loc[:,["SepalLength","SepalLength","SepalWidth","PetalLength","PetalWidth"]]
(3)学習
それでは実際に学習させてみましょう!!
今回は学習モデルにSVC(SVM Classification)を用いました。
iris.py
# 学習
clf = SVC()
clf.fit(x_train, y_train)
これで学習することができました。
(4)テスト
最後に実際にtestデータを使って評価してみましょう。
iris.py
# テスト
y_pred = clf.predict(x_test)
print(accuracy_score(y_test, y_pred))
結果
約97%の成果が出ていますね!!
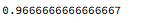
まとめ
以下の手順によってSVCモデルでアヤメのデータを分類することができました。
これからも様々な種類のモデルで遊びスキルをつけていきたいです!!