画像生成モデルの10年についてまとめたものです。更新日時:2022/11/22
以下の元資料にエポックメイキングな論文については、簡単な解説を付与しています。
有名どころについては随時解説を追加していく予定。
元資料
https://zentralwerkstatt.org/blog/ten-years-of-image-synthesis
1. 始まり (2012-2015)
2012年12月
現在の「AIの夏」の始まり。
深層畳み込みニューラル ネットワーク (CNN)、GPU、および非常に大規模なインターネット ソース データセット ( ImageNet ) を初めて統合する、深層畳み込みニューラル ネットワークを使用した ImageNet 分類の公開。
https://www.image-net.org/
2014年12月
Ian Goodfellow ほか 敵対的生成ネットワークを公開。
GAN は、分析ではなく画像合成に特化した最初の最新 (つまり 2012 年以降) のニューラル ネットワーク アーキテクチャ。
ゲーム理論に基づいた独自の学習アプローチを導入し、「ジェネレータ」と「ディスクリミネータ」という 2 つのサブネットワークが競合し、最終的には、「ジェネレータ」だけがシステムから除外され、画像合成に使用される。
https://proceedings.neurips.cc/paper/2014/file/5ca3e9b122f61f8f06494c97b1afccf3-Paper.pdf
GANのネットワーク 図1-1
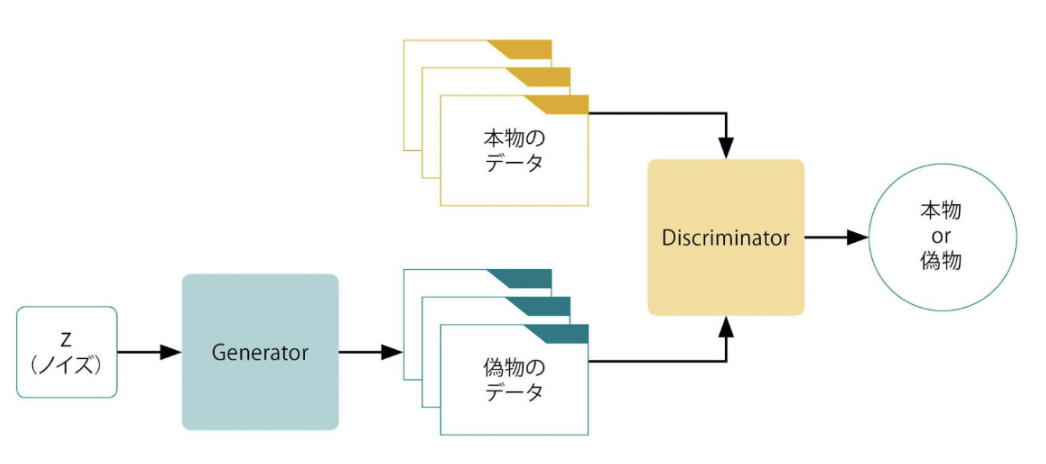
1つはGeneratorであり、その名のとおりデータを生成する。
Generatorは、生成データの特徴の種に相当するランダムノイズ(図表1では z )を入力することで、このノイズを所望のデータに近づけるようにマッピングする。
もう1つはDiscriminatorであり、Generatorが生成した偽物のデータと本物のデータが与えられ、その真偽を判定する。
Loss関数
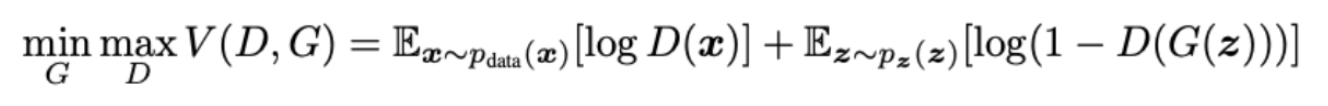
2015年11月
教師なし表現学習と深層畳み込み敵対的生成ネットワークの公開。
DCGAN (Deep Convolutional GAN)はICLR 2016で発表された論文
Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
オリジナルのGANでは生成画像がぼやけていたが、DCGANではより自然な画像の生成が可能になっている。
この論文はまた、潜在空間操作の問題を初めて提起。
https://arxiv.org/pdf/1511.06434.pdf
図1-2
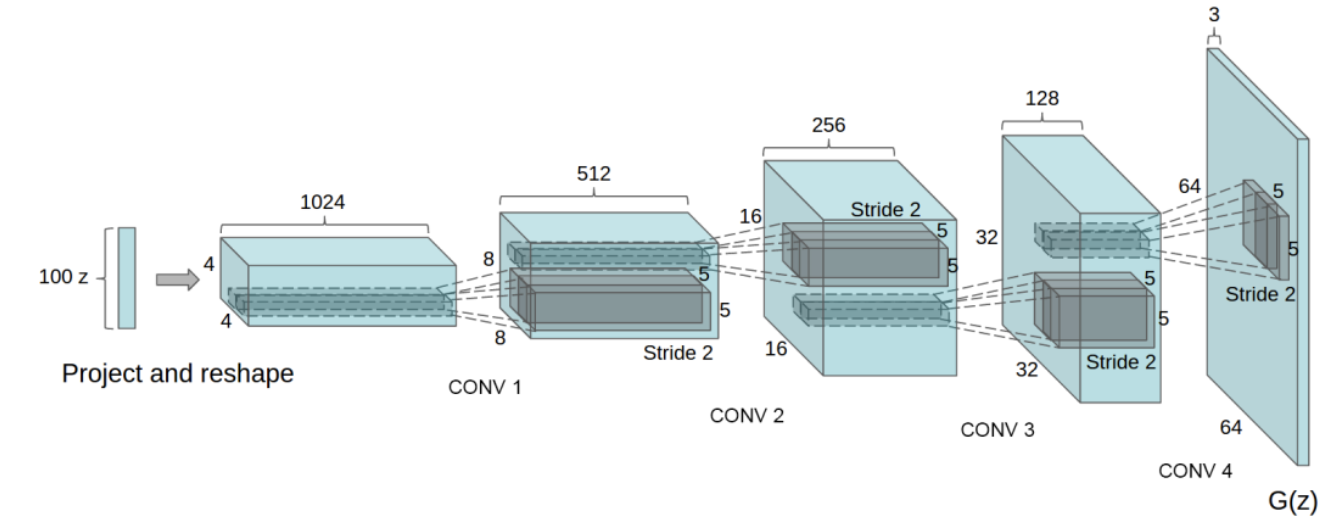
オリジナルのGANとの大きな違い
GeneratorとDiscriminatorそれぞれのネットワークに全結合層ではなく、畳み込み層(と転置畳み込み層)を使用している点。
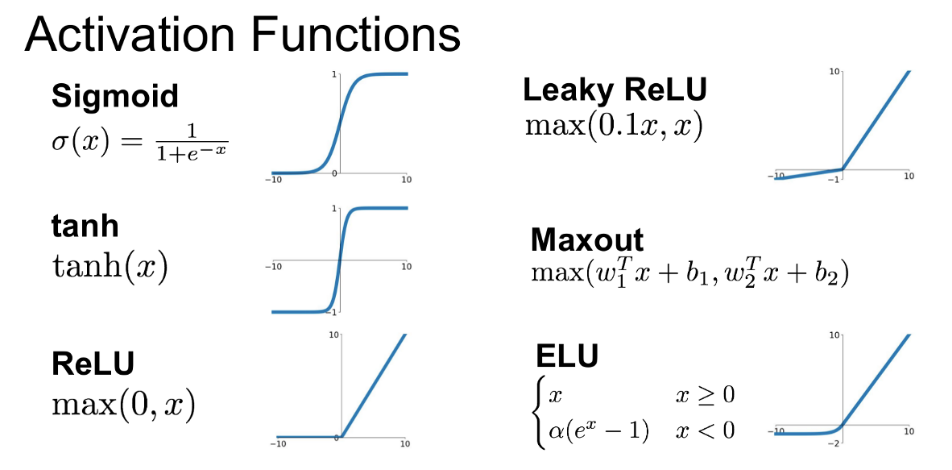
そして、GANの学習が安定しない問題に対しては、Batch Normalization (バッチ正規化)の導入や、活性化関数にReLUだけでなくtanh, Leaky ReLUを使用。
Generatorのネットワークでは以下の図のように、入力となる100次元のノイズベクトルZから転置畳み込みによって徐々に64×64サイズの画像へとアップサンプリングしていく。
全結合層やpooling層は使用しない。
この図では省略されているけど、それぞれの転置畳み込み層の後にBatch Normalizationと活性化関数が入る。活性化関数には基本的にReLUを使用し、最終層だけtanhを使用している。
転置畳み込み (transposed convolution)
fractional-strieded convolutionsは基本的にはこの図のような処理で、strideが2でpaddingが0の処理
図1-3
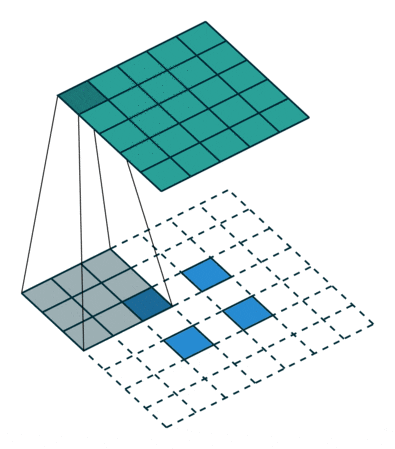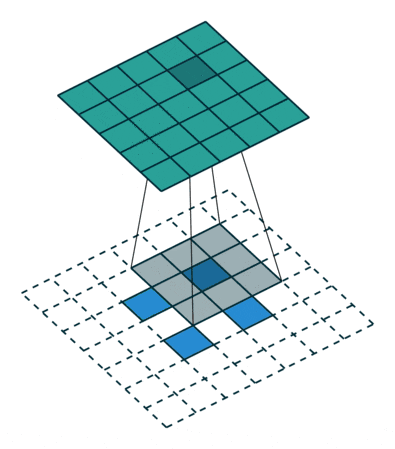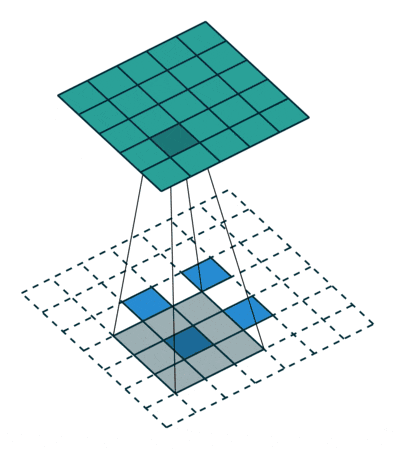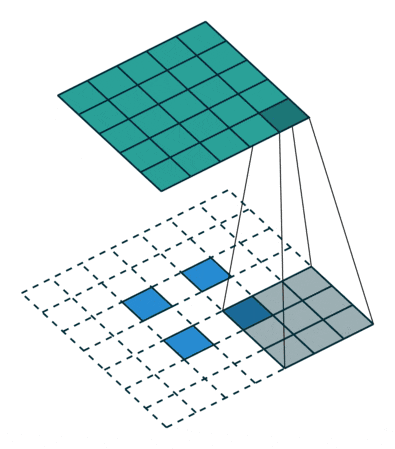
図1-4
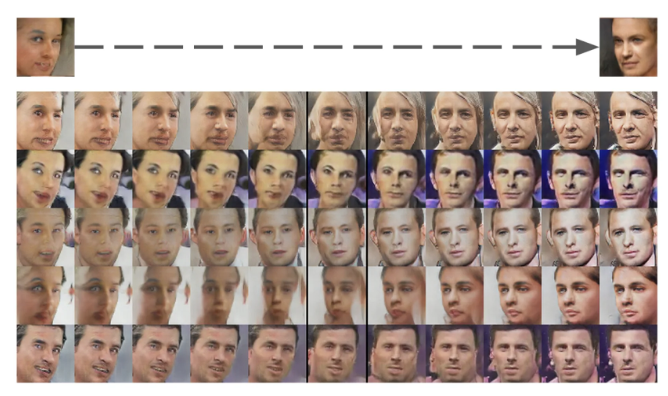
入力ベクトルを変化させることで顔を別の向きへと滑らかに補間できる
図1-5
2. GAN の 5 年間 (2015-2020)
GAN は、スタイル転送、修復、ノイズ除去、超解像など、さまざまな画像操作タスクに適用された。
https://github.com/nightrome/really-awesome-gan
同時に、GAN を使った芸術的な実験が始まり、
https://www.theverge.com/2018/10/23/18013190/ai-art-portrait-auction-christies-belamy-obvious-robbie-barrat-gans
Mike Tyka、Mario Klingenmann、Anna Ridler、Helena Sarin などによる最初の作品が登場。最初の「AI アート」スキャンダルは 2018 年登場。同時に、Transformer アーキテクチャは NLP に革命をもたらし、近い将来の画像合成に大きな影響を与えた。
2017年6月
Attention の公開 「Attention Is All You Need」
https://arxiv.org/pdf/1706.03762.pdf
Transformer アーキテクチャ (BERT などの事前トレーニング済みモデルの形式) は、自然言語処理 (NLP) の分野に革命をもたらした。
図2-1

2018年7月
概念的なキャプションの公開: 自動画像キャプション用のクリーンでハイパーニム化された画像代替テキスト データセット。
Conceptual Captions: A Cleaned, Hypernymed, Image Alt-text Dataset For Automatic Image Captioning
https://aclanthology.org/P18-1238.pdf
マルチモーダル データセットは、CLIP や DALL-E などのモデルにとって非常に重要。
2018年~2020年
NVIDIA の研究者による GAN アーキテクチャの一連の抜本的な改善 (StyleGAN、最新: StyleGAN2-ada、Training Generative Adversarial Networks with limited dataで紹介)。
https://arxiv.org/pdf/2006.06676.pdf
図2-2
少なくともFlickr-Faces-HQ (FFHQ) のような高度に最適化されたデータセットでは、GAN で生成された画像が初めて自然画像と見分けがつかなくなった。
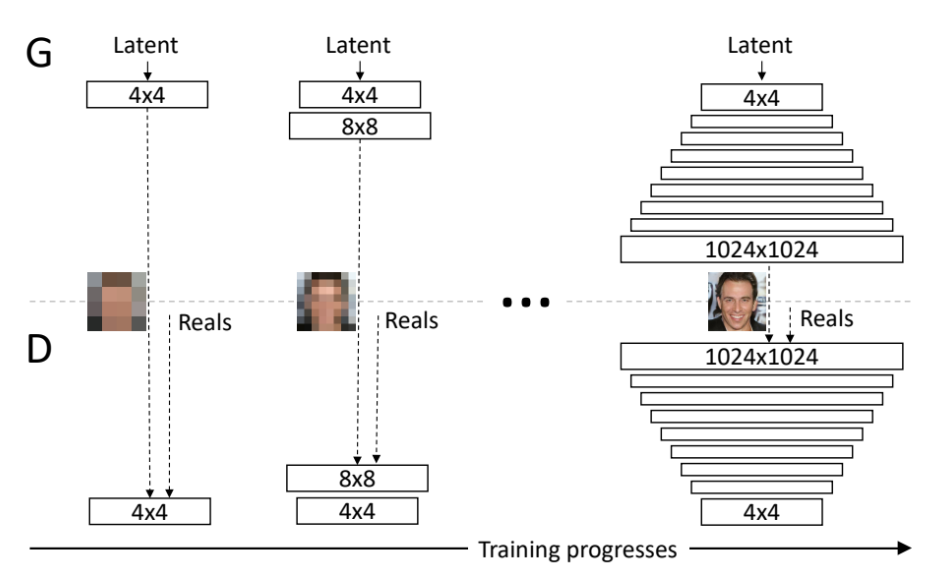
progressive growing
GANの学習過程において、低解像度の学習から始めて、モデルに徐々に高い解像度に対応した層を
加えながら学習を進めることで高解像度画像の生成を可能にするというもの。
初めに4×4の学習から始め、次に8×8の層を追加というように学習を進めていくことで
最終的に1024×1024の画像を生成している。
図2-3
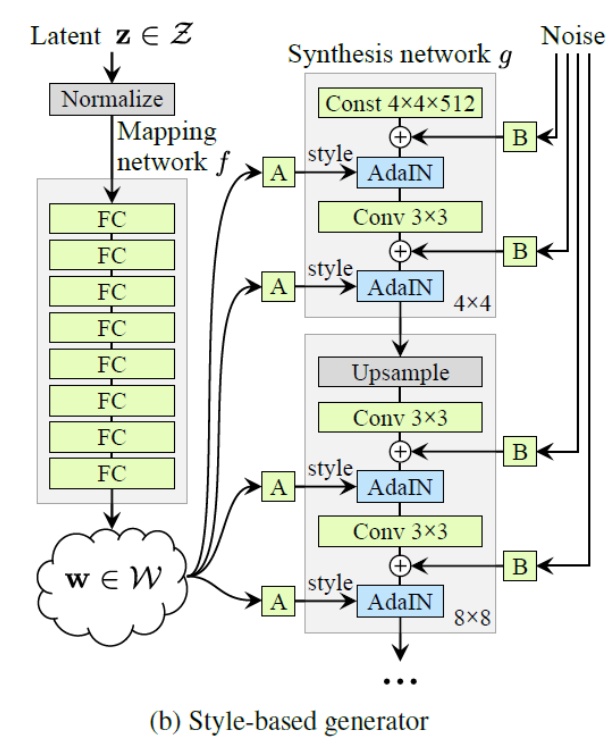
Adaptive Instance Normalization(AdaIN)
StyleGANで採用された正規化手法。
ベクトルwがAdaINを通して各層に適用されている。wは潜在表現と呼ばれるスタイルの決定要素zを非線形変換したもの。AdaINの処理によって生成画像のスタイル変換が行われる。
図2-4:2つの画像ソースによる画像生成

図2-4では2つのベクトルwを使用した結果を示している。
上段は生成に使用するwの値を低解像度の段階 画像Aを生成するようなw(以下w_a)から画像Bを生成するようなw(以下w_b)に切り替えた場合の生成画像。
同様に中段は中解像度の生成段階でw_aからw_bに切り替えた際の生成画像、
下段は高解像度の生成段階でw_aからw_bに切り替えた際の生成画像。
2020年5月
言語モデルの公開は few-shot learning。
OpenAI の LLM Generative Pre-trained Transformer 3 (GPT-3) は、Transformer アーキテクチャの能力を示している。
https://arxiv.org/pdf/2005.14165.pdf
GPTはTransformerという学習モデルをベースにして、しっかりと事前学習を行い文章生成を行うようにカスタマイズされた言語モデル。
図2-5
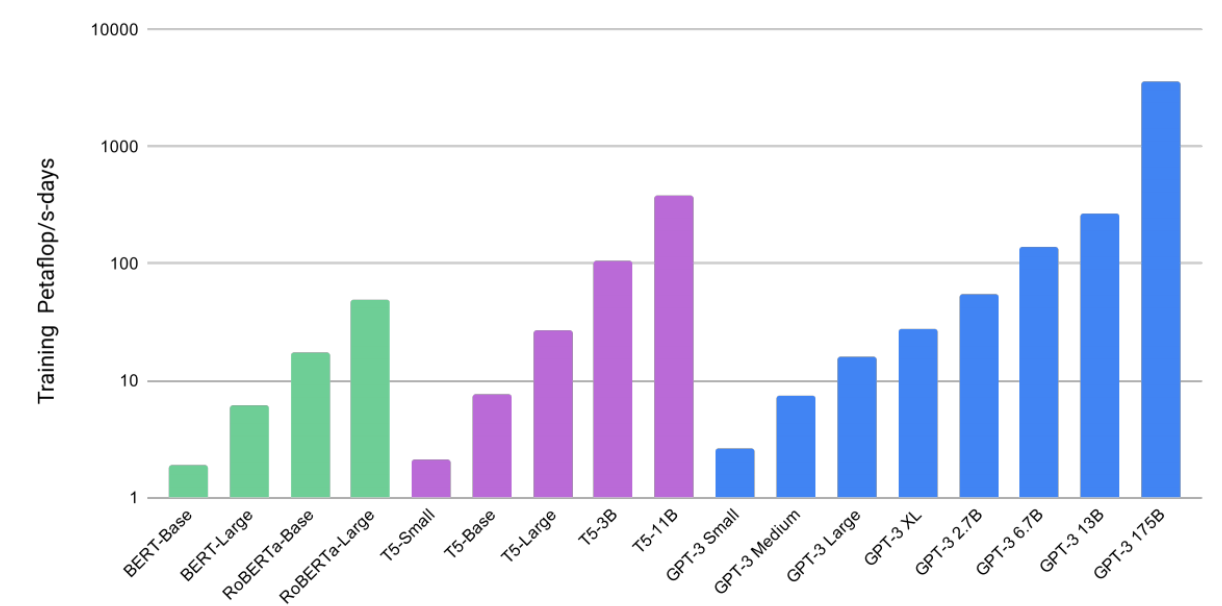
図2-6
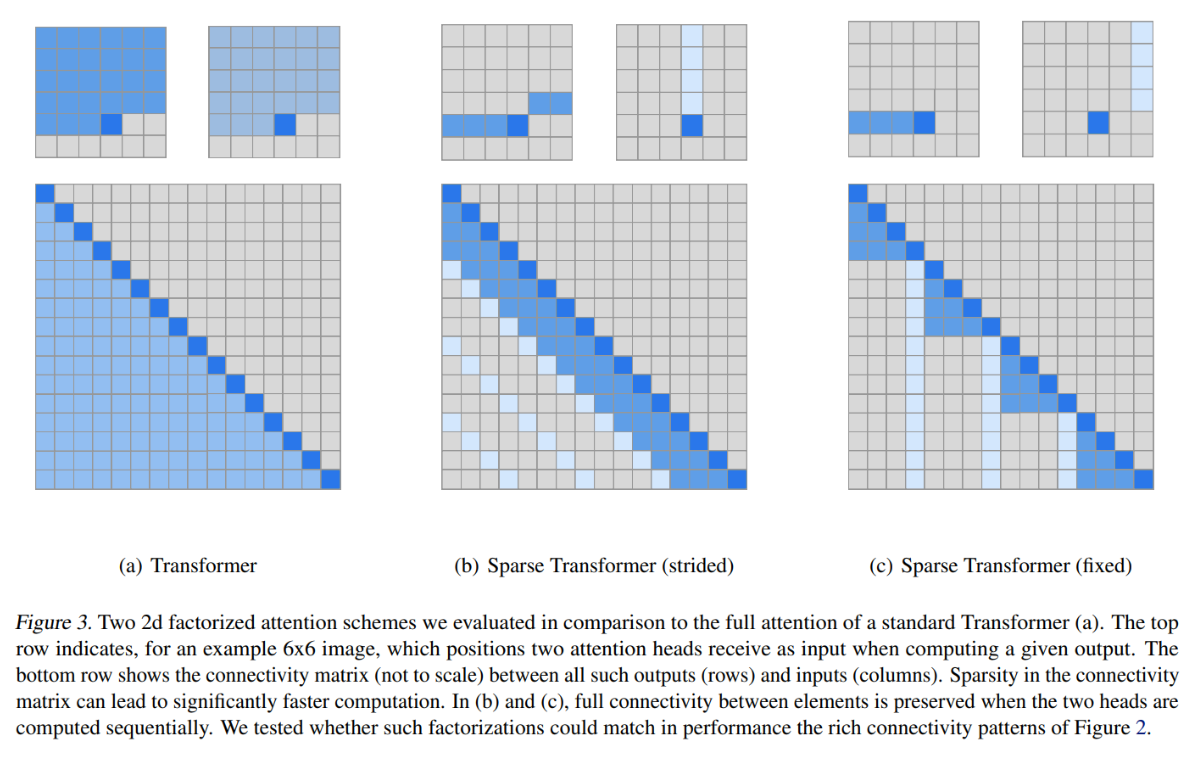
Strided Sparse Transformer
相対的な位置情報をスキップ
画像や音楽など周期的な傾向のあるデータに関して有効
Fixed Sparse Transformer
特定位置情報をスキップ
文章などのテキスト情報に有効
インプットの長さ n に対してattentionを向ける先の数をに近い値にする
↓
メモリの使用量が𝑂(𝑛^2) → 𝑂(𝑛√n )に削減
図2-7
図2-8
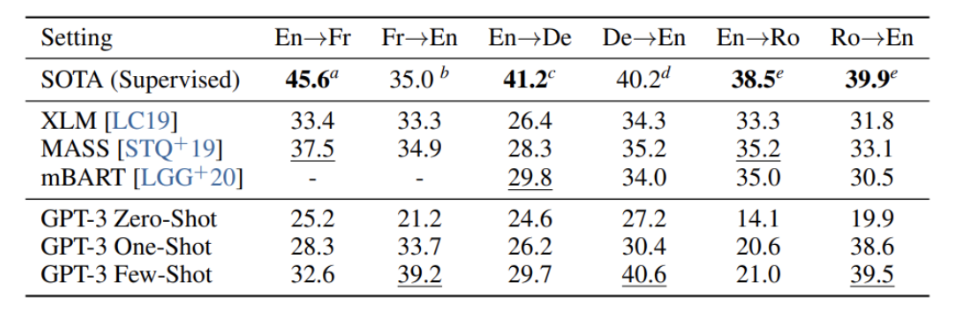
翻訳自体の勉強をすることなく、たくさんネットの文章を読んだだけで翻訳をしようというタスクをこなす
応用事例
-
文章の生成
-
デザインの生成
-
プログラミングコードの生成
-
データ解析
-
クリエイティブ作成
-
教育
-
ゲーム
-
論文作成
https://www.fortescience.com/news/296-editorial-snapshot-how-ai-might-change-the-future-of-academic-writing-and-publishing.html
GPT-3自体に関する学術論文が書かれ、投稿、更に査読まで受けていた。
筆頭著者としてGPT-3の名前
2020年12月
高解像度画像合成のための Taming Transformers の公開 (プロジェクト Web サイトも参照)。ビジョン トランスフォーマー (ViT) は、トランスフォーマー アーキテクチャを画像に使用できることを示しています。この論文で紹介されているアプローチ VQGAN は、ベンチマークで SOTA の結果を生成。
https://compvis.github.io/taming-transformers/
3. トランスフォーマーの時代 (2020-2022)
Transformer アーキテクチャは画像合成に革命をもたらし、GAN からの移行を開始。
「マルチモーダル」ディープ ラーニングは、NLP とコンピューター ビジョンの手法を統合し、「プロンプト エンジニアリング」は、画像合成への芸術的なアプローチとして、モデルのトレーニングとチューニングに取って代わる。
図3-1
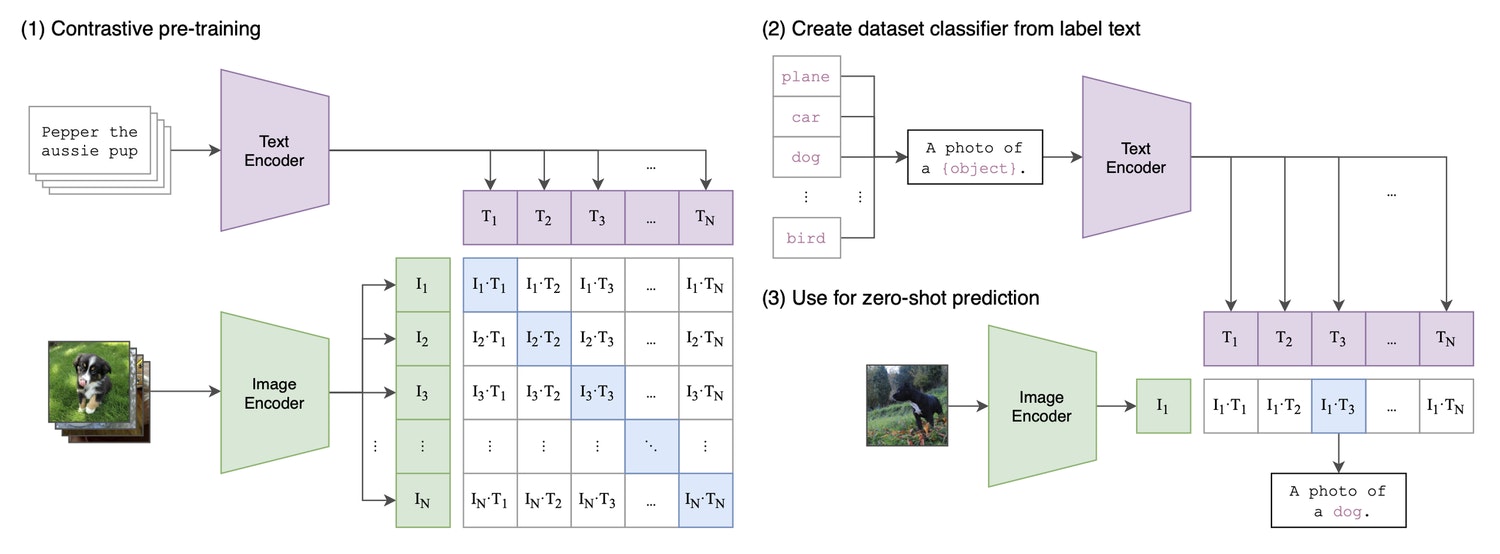
自然言語の監督からの伝達可能な視覚モデルの学習からのCLIPアーキテクチャ。おそらく、
現在の画像合成ブームは、CLIP で最初に導入されたマルチモーダル機能によって促進されている。
https://arxiv.org/pdf/2103.00020.pdf
2021年1月
DALL-E の最初のバージョンを紹介するZero-shot text-to-image generation ( OpenAI のブログ投稿も参照) の公開。このバージョンは、単一のデータ ストリームでテキストと画像 (VAE によって「トークン」に圧縮) を組み合わせることで機能する。モデルは単に「文」を「続ける」だけ。
データ (2 億 5000 万枚の画像) には、Wikipedia のテキストと画像のペア、Conceptual Captions、およびYFCM100Mのフィルター処理されたサブセットが含まれる。
CLIP は、画像合成への「マルチモーダル」アプローチの基礎を築く。
https://arxiv.org/pdf/2102.12092.pdf
https://aclanthology.org/P18-1238.pdf
http://projects.dfki.uni-kl.de/yfcc100m/
2021年1月
ビジョン トランスフォーマーと通常のトランスフォーマーの組み合わせであるマルチモーダル モデルである CLIP
CLIP は画像とキャプションの「共有潜在空間」を学習するため、画像にラベルを付けることができる。
論文の付録 A.1 に記載されている多数のデータセットでトレーニングされている。
https://arxiv.org/pdf/2103.00020.pdf
図3-2
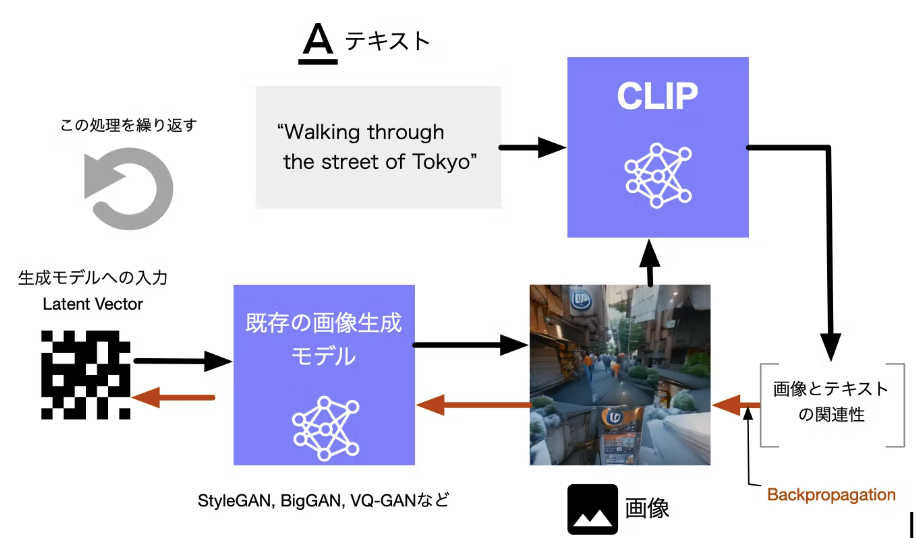
画像とテキストをつなげる (どのくらいマッチしているかを判定する)モデル、OpenAI CLIPと、既存の画像生成モデル(BigGAN, StyleGANなど) をつなげることで、テキストからそれにあった画像を生成する。
CLIPが算出する生成画像と入力テキストとの距離を最小化するように、生成モデルへの入力のベクトル(latent vector)をBackpropagationで最適化していく。
2021年6月
画像合成で GAN に勝る拡散モデルの公開。拡散モデルは、GAN アプローチとは異なる画像合成へのアプローチを導入。人工的に追加されたノイズから画像を再構成することで学習。
https://arxiv.org/abs/2105.05233
https://benanne.github.io/2022/01/31/diffusion.html
Diffusion Model(拡散モデル)
元データにノイズが徐々に付加されていき、最終的にガウシアンノイズとなるという前提を置き、その逆のプロセスをモデル化することでデータを生成する。
GANや変分オートエンコーダー (VAE)よりも高品質の画像を生成することに成功
図3-3

拡散モデルはガウスノイズだけではなく動物化ノイズ(animorphosis:ランダムな動物の顔をノイズとして顔に加える処理)でも問題なく動作する。これは、従来の拡散モデルに関する理論に反している。
拡散モデルは強力な画像生成ツールですが、ガウス ノイズを追加して画像を劣化させる関数と、このノイズを除去するための単純な画像復元ネットワークという 2 つの単純な部品から構築されている。
図3-4

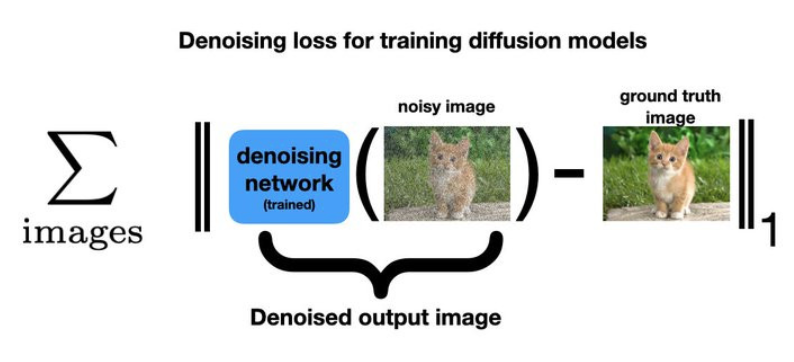
元の画像とノイズ除去された出力の間の L1 差を測定する損失を最小化することによってトレーニングする。
図3-5
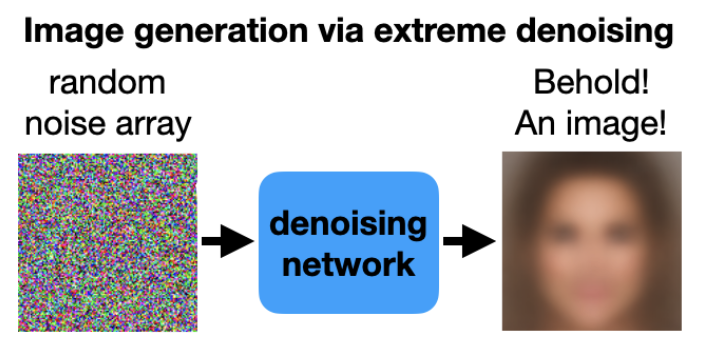
これらのノイズ除去ネットワークは非常に強力で、一連の単なる純粋なノイズ画像を渡しても、それを画像に復元する。異なるノイズの並びを渡すたびに、異なる画像が返される。
図3-6
ノイズ除去モデルは純粋なノイズをぼやけた画像に変換し、次に、この画像にノイズを追加し、より低いノイズ レベルでトレーニングされたノイズ除去モデルに入力として与える。
これにより、ぼやけの少ない画像が作成される。ノイズを元に戻し、ノイズを除去する。そして何度もこれを繰り返す。
図3-7

ノイズがゼロになるまで、ノイズレベルを徐々に下げてこのプロセスを繰り返す。
これで、シャープな先端部と特徴を備えた洗練された出力画像が得られる。
この反復プロセスは、モデルがトレーニングされた Lp-norm損失の制限を回避する。
図3-8

2021年7月
DALL-E の複製であるDALL-E miniがリリース(より小さく、アーキテクチャとデータの調整がほとんどない。
データには、Conceptual 12M、Conceptual Captions 、およびOpenAI が元の DALL-E モデルに使用するYFCM100Mの同じフィルター処理されたサブセットが含まれている。コンテンツフィルターやAPIの制限がないため、クリエイティブな探求ができる大きな可能性があり、Twitter上では「奇妙なダルイー」の画像が爆発的に拡散された。
https://huggingface.co/spaces/dalle-mini/dalle-mini
https://wandb.ai/dalle-mini/dalle-mini/reports/DALL-E-Mini-Explained-with-Demo--Vmlldzo4NjIxODA
https://arxiv.org/pdf/2102.08981.pdf
https://aclanthology.org/P18-1238.pdf
http://projects.dfki.uni-kl.de/yfcc100m/
https://twitter.com/weirddalle
2021年~2022年
Katherine CrowsonがCLIPを使った生成モデルの作成方法を探るCoLabノートブックを公開。
例:512x512 CLIPガイド拡散とVQGAN-CLIP (自然言語誘導によるオープンドメインの画像生成・編集、2022年にプレプリントとして公開されただけだが、VQGANが公開されると同時に公開実験が登場)。
初期のGANのように、アーティストやハッカーが、既存のアーキテクチャを大幅に改良し、非常に限られた人数で開発が行われた。
そしてそれが企業によって効率化され、wombo.aiのような「スタートアップ」によって商業化。
https://colab.research.google.com/drive/1V66mUeJbXrTuQITvJunvnWVn96FEbSI3
https://colab.research.google.com/github/justinjohn0306/VQGAN-CLIP/blob/main/VQGAN%2BCLIP(Updated).ipynb
https://arxiv.org/pdf/2204.08583.pdf
2021年4月
CLIP latentsを用いた階層的テキスト条件付き画像生成の発表。
この論文では、その数週間前にリリースされたGLIDE(GLIDE: テキストガイド付き拡散モデルによるフォトリアリスティックな画像生成・編集)をベースとしたDALL-E 2を紹介している。
同時に、DALL-E 2へのアクセスが制限され、意図的に制限されたため、DALL-E miniへの関心が再び高まった。
「一般に公開されているソースと当社がライセンス供与したソースの組み合わせ」で構成されたデータは、モデルカードによるものと、論文によるCLIPとDALL-E のフルデータセットで構成されている。
https://arxiv.org/pdf/2204.06125.pdf
https://arxiv.org/pdf/2112.10741.pdf
https://github.com/openai/dalle-2-preview/blob/main/system-card.md
2021年5月/6月
DALL-E 2に対するGoogleからの回答であるImagegenとParti。
コンテンツが豊富なText-to-Image生成のための言語理解の深いフォトリアリスティックなText-to-Image拡散モデルが公開された。
https://arxiv.org/pdf/2206.10789.pdf
4.Photoshop としての AI (2022 年~現在)
DALL-E 2 は画像モデルの新しい標準を築いたが、すぐに商品化され、多くの制限があったため、
クリエイティブな使用は最初から制限されていた。
そのため、DALL-E 2が発売されても、ユーザはDALL-E miniのような小型のモデルで実験を続けていた。Stable Diffusion のリリースにより、このすべてが一変し、画像合成の「Photoshop 時代」の幕開けとなった。
2022年8月
Stability.aiは、 DALL -E 2 と同等のフォトリアリズムを可能にするモデルであるStable Diffusion (潜在拡散モデルを使用した高解像度画像合成) をリリース。
DALL-E 2以外のモデルは、ほぼ即座に公開され、CoLab内やHuggingfaceプラットフォーム上で実行することが可能。
https://stability.ai/blog/stable-diffusion-public-release
https://openaccess.thecvf.com/content/CVPR2022/papers/Rombach_High-Resolution_Image_Synthesis_With_Latent_Diffusion_Models_CVPR_2022_paper.pdf
https://en.wikipedia.org/wiki/Stable_Diffusion
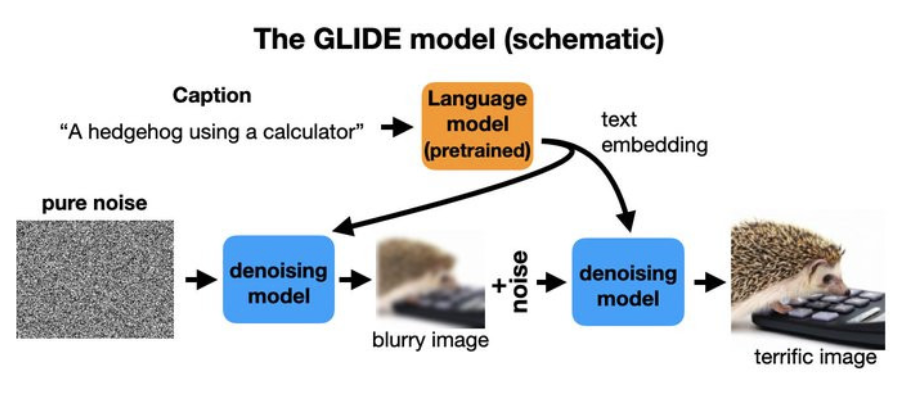
DALL-E や GLIDE、Stable Diffusion など、テキストの説明から画像を作成する創造的なモデルではノイズ除去モデルを使用するが、2 つの入力がある。
トレーニング時に、通常どおり、クリーンなイメージを劣化させ、トレーニングのためにノイズ除去モデルに渡される。
同時に、画像を説明する説明文が言語モデルを介して押し込まれ、embedded特徴に変換される。
これらは、ノイズ除去器への追加入力として提供される。トレーニングと生成は以前と同じように進行し、ヒントを提供するテキスト入力がある。
図4-1
2022年8月
Google’s DreamBooth では、拡散モデルをより細かく制御することができる。
しかし、このような技術的な介入を行わなくてもPhotoshopのようなジェネレーティブモデルを使い、ラフスケッチから始めて、レイヤーごとに生成された修正を加えていくことが可能に。
https://arxiv.org/pdf/2208.12242.pdf
https://andys.page/posts/how-to-draw/
2022年10月
ストックフォト最大手のシャッターストックは、Stable Diffusionのようなジェネレーティブモデルがストックフォトの市場に大きな影響を与えることを見越して、OpenAIとの協業による生成画像の
提供/ライセンス提供を発表。
https://www.shutterstock.com/press/20435