背景
Snowflakeに限った話ではないが,テーブルを作成する際,事前にそのテーブル定義を行っていないといけなかったり,またはselectした情報をテーブルに格納する際にはテーブル定義と合致させる必要がある(テーブル定義と異なる情報を格納しようとするとエラーがでる).テーブル定義の項目が多いと,それなりに手間がかかるため,この過程を少しでも省力化することが目的である.
やりたいこと
テーブル1の情報を集計してテーブル2を作成することを考える.このとき,通常のやり方だと,テーブル1とテーブル2の定義を事前に行い,テーブル1にデータをロードし(または,別テーブルからSecure Data SharingなりViewを行う),テーブル1の情報を集計してテーブル2を作成する.
テーブル1
| 都道府県 | 氏名 | 男女 |
|---|---|---|
| 北海道 | AAAA | 男 |
| 北海道 | BBBB | 女 |
| 青森 | CCCC | 女 |
| ⋮ | ⋮ | ⋮ |
| 沖縄 | XXXX | 男 |
テーブル2
| 都道府県 | 男 | 女 |
|---|---|---|
| 北海道 | 49 | 45 |
| 青森 | 33 | 50 |
| ⋮ | ⋮ | ⋮ |
| 沖縄 | 32 | 46 |
通常のやりかた
create or replace table TABLE_NAME1 (PREF_NAME VARCHAR(4), NAME VARCHAR(10), GEND VARCHAR(1));
create stage TABLE1;
put "C:\xxxxx\table1.csv" @TABLE1;
create or replace table TABLE_NAME2 (PREF_NAME VARCHAR(4), MAN_NUM NUMBER(38,0), WOMAN_NUM NUMBER(38,0)) as select PREF_NAME, count(case when GEND="男" then 1 end) as MAN_NUM, count(case when GEND="女" then 1 end) as WOMAN_NUM from table1 group by PREF_NAME;
このときの問題点
- TABLE1の仕様が変更されたとき(e.g. 新しくカラムが追加される等),TALBE1のテーブル定義をやり直す必要があり,テーブル定義を行わなければ,csv取り込み時にエラーとなる
- TALBE2の集計の仕様が変更されたとき(e.g. 無記名やNULLが追加される等),正しい集計結果を出力するためにTALBE2のテーブル定義をやり直す必要がある
テーブルの型の宣言を省略し,Snowflakeでテーブルを作成する方法
Pythonを用いてSnowflakeのテーブルを新規作成または上書きすることで,テーブルの型の宣言を省略することができる.例えば,TABLE1を作成するときは,
import snowflake.snowpark as snowpark
from snowflake.snowpark.functions import col
import pandas as pd
import json
with open('creds.json') as f:
data = json.load(f)
USERNAME = data['user']
PASSWORD = data['password']
PASSCODE = data['passcode']
ACCOUNT = data['account']
ROLE = data['role']
connection_parameters = {
"account": ACCOUNT,
"user": USERNAME,
"password": PASSWORD,
"passcode": PASSCODE,
"role": ROLE,
"database": "XXXX",
"schema": "XXXX",
"warehouse": "XXXX"
}
session = Session.builder.configs(connection_parameters).create()
csv_file_path = 'C:\xxxxx\table1.csv'
table1_pd_df = pd.read_csv(csv_file_path)
table1_snowflake_df = session.create_dataframe(table1_pd_df)
table1_snowflake_df.write.save_as_table("TABLE_NAME1") #上書きの場合はtable1_snowflake_df.write.save_as_table("TABLE_NAME1", mode="overwrite")
TALBE2を作成するときは,
import snowflake.snowpark as snowpark
from snowflake.snowpark.functions import col
import pandas as pd
import json
with open('creds.json') as f:
data = json.load(f)
USERNAME = data['user']
PASSWORD = data['password']
PASSCODE = data['passcode']
ACCOUNT = data['account']
ROLE = data['role']
connection_parameters = {
"account": ACCOUNT,
"user": USERNAME,
"password": PASSWORD,
"passcode": PASSCODE,
"role": ROLE,
"database": "XXXX",
"schema": "XXXX",
"warehouse": "XXXX"
}
session = Session.builder.configs(connection_parameters).create()
table2_snowflake_df = session.sql("select PREF_NAME, count(case when GEND="男" then 1 end) as MAN_NUM, count(case when GEND="女" then 1 end) as WOMAN_NUM from table1 group by PREF_NAME")
table2_snowflake_df.write.save_as_table("TABLE_NAME2") #上書きの場合はtable2_snowflake_df.write.save_as_table("TABLE_NAME2", mode="overwrite")
Secure Data Sharing やView を用いてる場合も同様にテーブルの型の宣言を省略することができる.特に,Secure Data SharingやViewの場合,参照元のテーブル仕様が変更することで参照先テーブルの型も変更する必要があるため,便利である.
おまけ
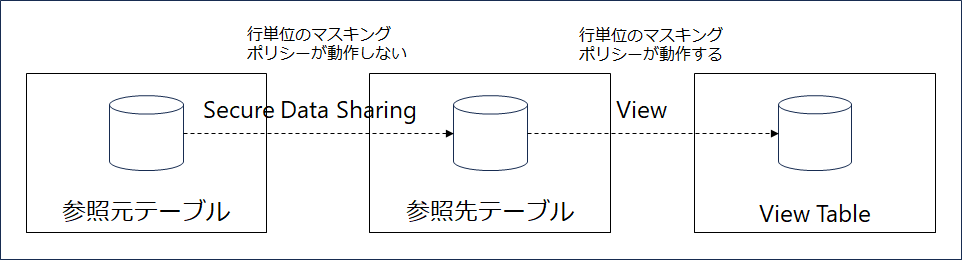
Secure Data Sharing を用いた場合,行単位のマスキングポリシーが動作しないため,以下のようにView を利用するアーキテクチャにすることで,行単位のマスキングポリシーを適用できる.このとき,参照元テーブルのテーブル仕様が変更されたとき(e.g. 新しくカラムが追加される等),View Table側の型が参照元(または参照先)テーブルの型が不整合となり,エラーが発生する.そのため,Pythonを用いた処理をタスク化することで,このような事態を避けることができる(マスキングポリシー部分の処理を追加する必要がある).