概要
Snowflake 内にあるテーブルに対して,テーブルのメタ情報を作成する処理(semantic-model-generator)と,その情報を用いてテーブルを自然言語で問い合わせを行う処理(cortex-analyst)を構築する.構築方法は,Streamlit in Snowflake(SiS)を用いるやり方とローカルのPythoを用いてStreamlitを用いるやり方があるが,今回は前者のやり方について解説する.
前提条件
- Streamlit in Snowflake(SiS)で処理が完結
- ACCOUNTADMINの権限があること
- SnowflakeからGitリポジトリにアクセスできること,できなければ別の手段でGitリポジトリにあるファイルをSnowflakeの内部ステージにアップロードできること
大まかな流れ
- テーブルのメタ情報を作成する処理(semantic-model-generator)の実装
- テーブルを自然言語で問い合わせを行う処理(cortex-analyst)の実装

1. テーブルのメタ情報を作成する処理の実装
- semantic-model-generator にアクセス
-
sissetup_snowsightgit.sql を実行
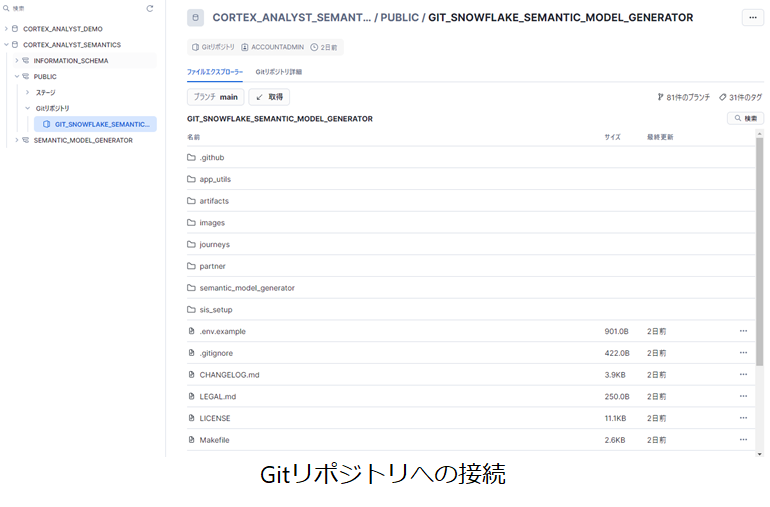
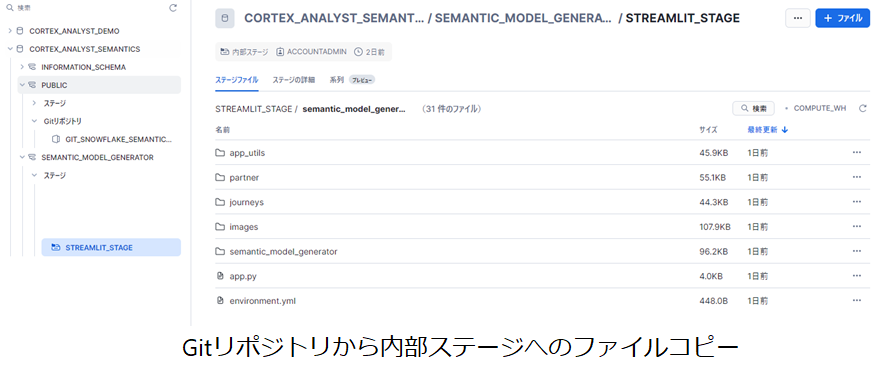
Gitリポジトリにアクセスするための外部APIの作成,Gitリポジトリへの接続,内部ステージの作成,Gitリポジトリから内部ステージへのファイルコピー,Streamlitアプリの作成を実施

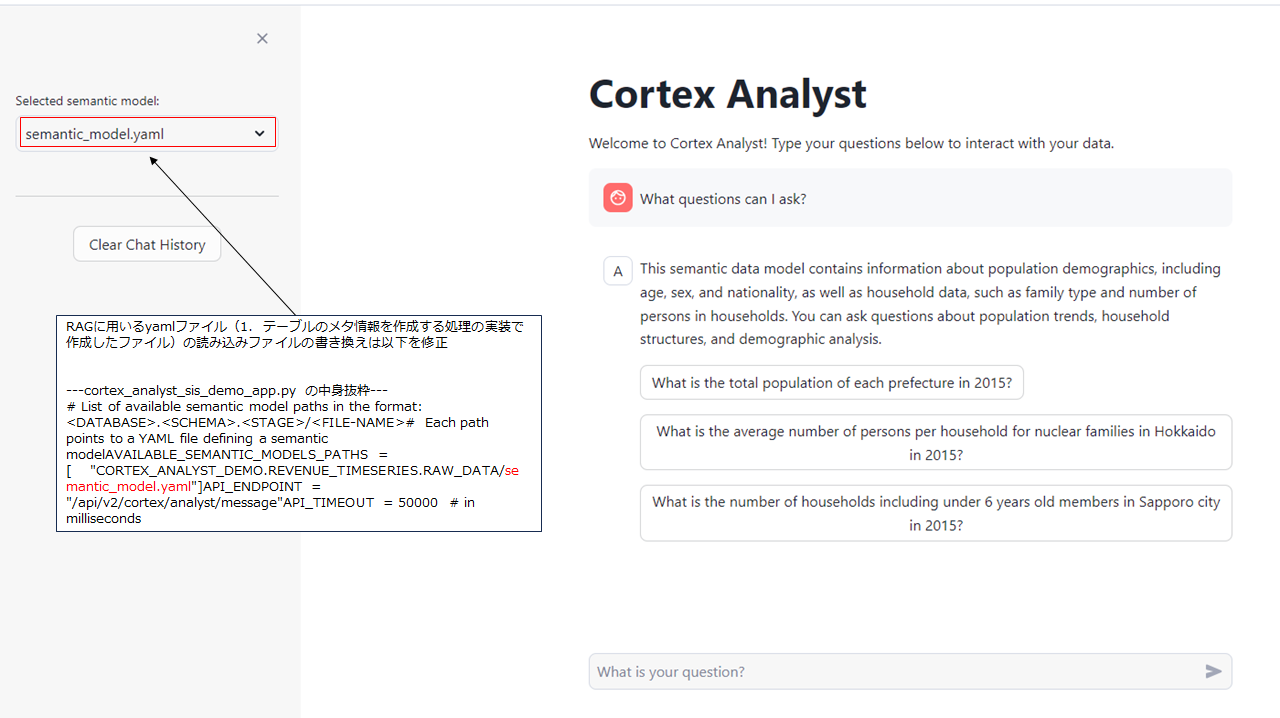
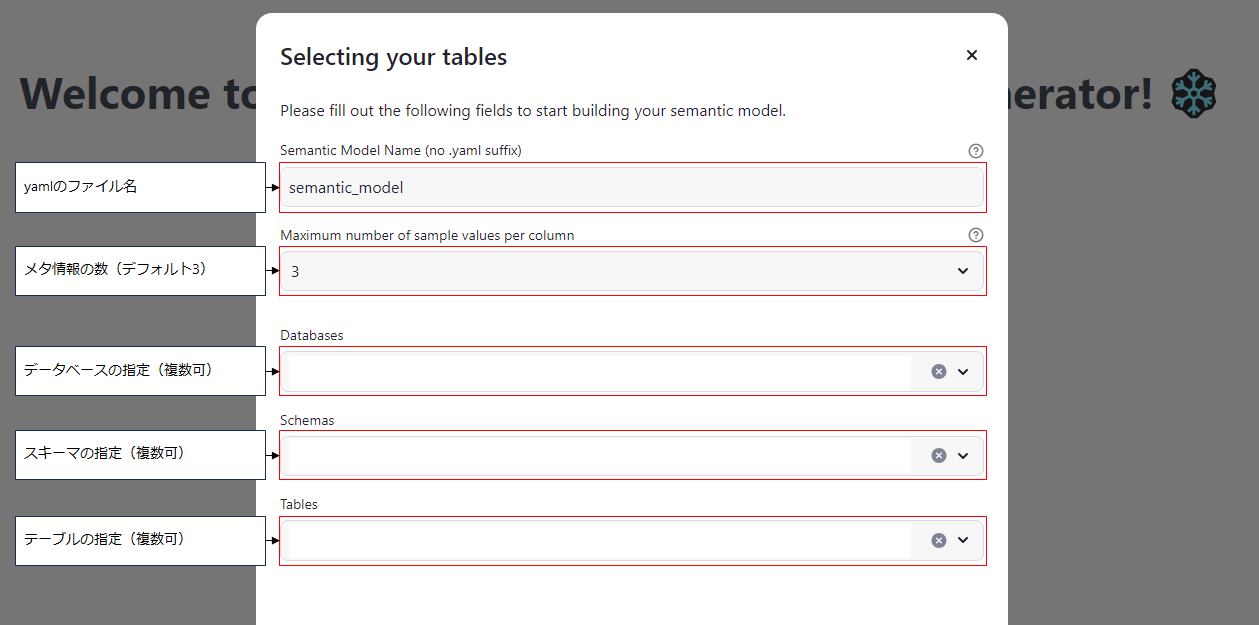
- Streamlitアプリを実行し,テーブルのメタ情報となるyamlファイルを作成する

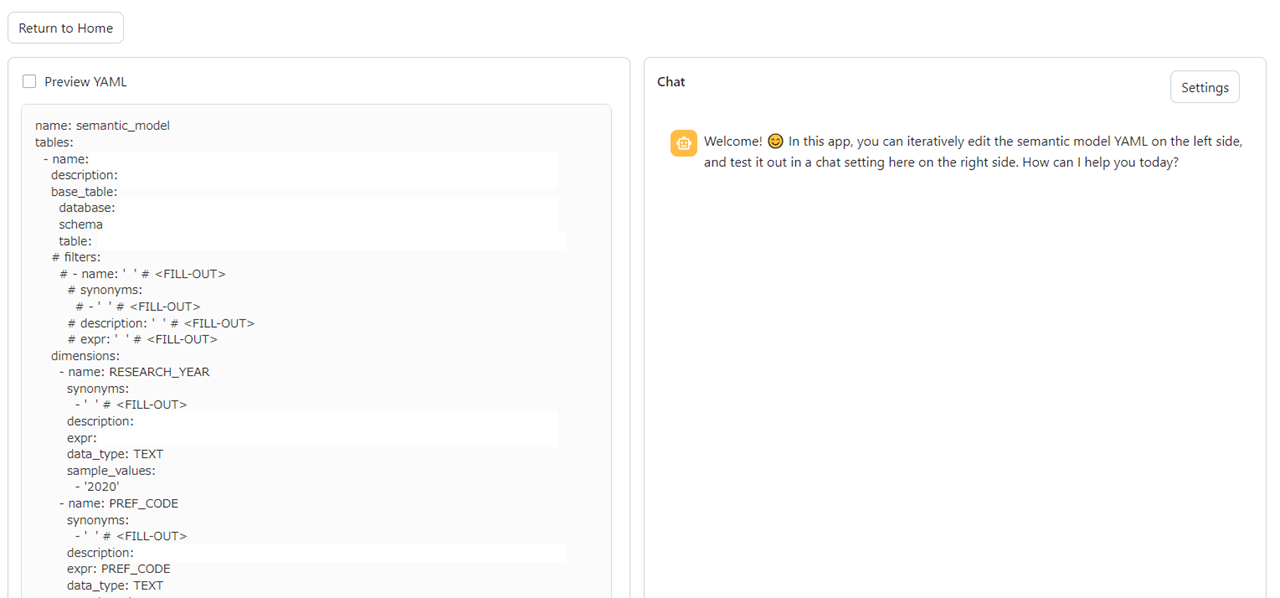

2. テーブルを自然言語で問い合わせを行う処理の実装
-
cortex-analyst にアクセス
-
create_snowflake_objects.sql を実行
cortex-analyst のアプリを動作させるためのデータベースやスキーマ,ステージ,テストテーブルを作成- ROLE の切り替えが発生するため,すべて選択して実行はできない.そのため,基本的には1行ごとに実行する.
- SECURITYADMIN やSYSADMIN 等必要な権限に切り替えながら実行する.必要に応じてロールは変更して実行すること.cortex_user_role についても,別のロールに置き換えても良い.
- 部分は権限を付与したいアカウント名を指定して書き換えること.
- テストテーブル(daily_revenue,product_dim,region_dim)は本番環境では不要.不要の場合,次および次々の手順はスキップしても良い.
-
daily_revenue.csv,product.csv,region.csv,revenue_timeseries.yaml(3つのテーブルのメタデータ) のファイルを内部ステージにアップロード(スキップ可)

-
cortex_search_create.sql を実行(スキップ可)
テストテーブルにdaily_revenue.csv,product.csv,region.csv をロード -
Streamlit in Snowflake(SiS) でcortex_analyst_sis_demo_app.py を実行