まえがき
今回も始まりました。やってみよう分析!シリーズ
前章ではExcelとMySQLの連携手順を紹介しました。本章では前章で構築したExcelとMySQLの環境下で、
- MySQLの基本コマンド(SHOW, USE, CREATE, DROP)
- データ入力・出力(LOAD DATA / INTO OUTFILE)
- Excel pivotと連携
を紹介していきます。上記以外にもMySQLのコマンドはたくさん存在しますが、本章ではMySQLとExcelを連携させてpivotするのに必要と思われる最小限のコマンドを紹介します(コマンドの詳細はMySQLの教科書を参照してください)。本章の読者対象は前章と同じ
- エンジニア以外で大きめの容量を持つcsvのExcel pivot集計を実施したい方
です。では、今回も早速始めましょう。
MySQLの基本コマンド
前章の手順に従ってMySQLにログインしておきます。
SHOW, USE
基本的にはMySQLはDatabaseを選択し、テーブルからSQL文でデータを抽出します。まず、MySQLのDatabaseを確認してみましょう。どんなDatabaseがあるか確認するため下記のコマンドを実行していみましょう。
SHOW DATABASES;
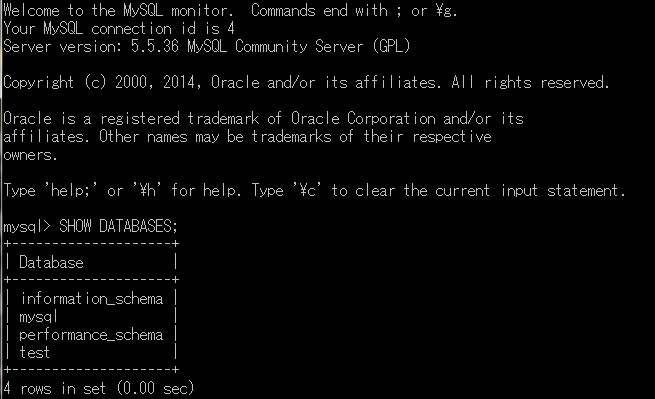
Databaseが複数表示されるはずです。ではDatabaseを選んで使ってみます。例えばmysqlを使うコマンドは
USE mysql;
です。Database mysqlは複数のtableを持っています。どんなtableがあるか確認するコマンドは
SHOW TABLES;
です。mysql databaseに含まれるtableが表示されたはずです。

CREATE
csvを新たにMySQLへ格納するためには、それを入れるためのdatabaseとtableが必要になります。databaseとtableを生成するためにはCREATE文を使います。ここではdatabaseとして mysql_test, tableとして __test_table__を作ってみます。まずdatabaseを作るCREATE文は
CREATE DATABASE mysql_test;
です。コマンドが成功していれば上記のSHOW DATABASES;で確認した時にmysql_testが現れます。

次はmysql_testの中にtest_tableを作ってみます。USE mysql_test;で新しく作ったデータベースを指定しておきます。tableを作るときは最低限の設定として table名、 __カラム名__と __カラムの型__を指定します。例えば次のようにtest_tableを生成してみましょう。
CREATE TABLE test_table(id int NOT NULL AUTO_INCREMENT, name CHAR(30) NOT NULL, PRIMARY KEY (id));
このCREATE文では整数型のid, 文字型のnameをカラムとして生成しています。さらにidはプライマリーキー(主キーとも呼ばれ、簡単に表すとtabel内で重複のない番号のことです)という条件を最後に付与しています。 idに付けられているAUTO_INCREMENTは、idはデータ(レコード)がインサートされるたびに1が加算されることを条件付けています。NOT NULLはNULLを格納することを許可しない条件です。
CREATE TABLEするとき、インクリメントや主キーが必要なければ NOT NULL, AUTO_INCREMENT, PRIMARY KEY (id)を省略することができます。
それではtest_tableが生成されているか確認してみましょう。確認するためには次のコマンドを実行します。
SHOW TABLES;
うまくtableが生成されていればtest_tableが現れるはずです。

DROP
せっかく作ったdatabaseとtableですが、今度はこれらを削除してみましょう。tableをまるごと削除するコマンドは次のようになります。
DROP TABLE test_table;
このコマンドを実行した後にSHOW TABLES;を実行するとmysql_testの中が空になっていると返ってきます。続いてdatabaseを削除します。コマンドは次のようになります。
DROP DATABASE mysql_test;
SHOW DATABASES;で確認するとmysql_testが削除されているはずです。
データ入力・出力
データの準備
今度はdatabaseとtableを作成してcsvを格納する操作を実行してみましょう。ここで使うcsvは住所.jp様の全国住所データを利用させていただきます。住所.jp様のトップページのcsvを選択します。
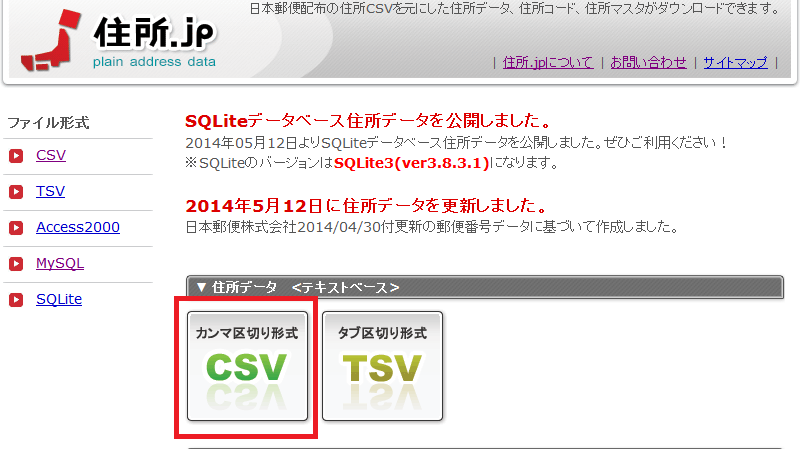
全国の __csv_zenkoku.zip__をダウンロードします。
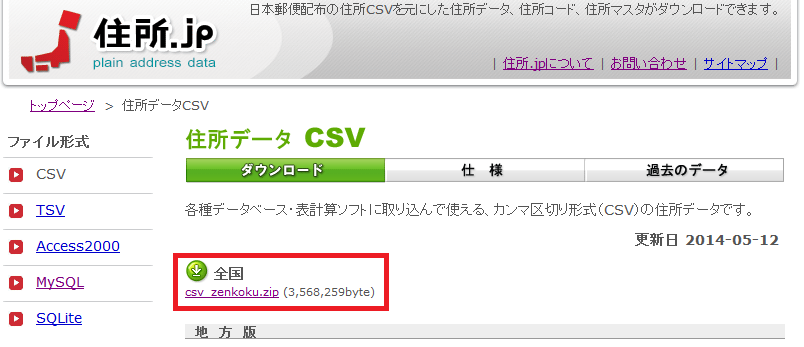
ダウンロードしたら解凍してCドライブ直下に __zenkoku.csv__置きます。本章では後の解説のためにCドライブ直下にファイルを置くこととします(Cドライブの代わりに別の格納場所を指定しても問題ないので、適時読み替えてください)。
ダウンロードしたcsvファイルを開くと1行目はラベル、それ以下がデータという形式になってます。zenkoku databaseとjusyo tableを新規作成してcsvデータをテーブルに格納したいと思います。
データの入力
まずzenkoku databaseを作りましょう。前に説明した通りの手順で作成します。
CREATE DATABASE zenkoku;
USE DATABASE zenkoku;でzenkokuを指定します。この状態でjusyo tableを作成します。次のCREAT文でjusyo tableを作成します。カラム名はcsvのラベルの名前をローマ字化しました。また、文字列の型は全てTEXT型にしました。
CREATE TABLE jusyo (
jusyo_CD INT,
todoufuken_CD INT,
shichouson_CD INT,
chouiki_CD INT,
yuubinbangou TEXT,
jigyousyoflag TEXT,
haishiflag TEXT,
todoufuken TEXT,
todoufukenkana TEXT,
shichouson TEXT,
shichousonkana TEXT,
chouiki TEXT,
chouikikana TEXT,
chouikihosoku TEXT,
kyotodouri TEXT,
azachoume TEXT,
azachoumekana TEXT,
hosoku TEXT,
jigyousyomei TEXT,
jigyousyomeikana TEXT,
jigyousyojusyo TEXT,
shinjusyo_CD TEXT
);
このtableに先ほどダウンロードしたCドライブ直下に置いたcsvを格納しましょう。csvを読み込むのは __LOAD DATA INFILE__構文を使います。Cドライブ直下のzenkoku.csvをjusyoに読み込むクエリは下記のようになります。
LOAD DATA INFILE 'C:/zenkoku.csv'
INTO TABLE jusyo
FIELDS
TERMINATED BY ','
ENCLOSED BY '"'
LINES
TERMINATED BY '\r\n'
IGNORE 1 LINES;
このクエリが伝えていることは下記のことです。
- 1-2行目:C:/zenkoku.csv をjusyoに格納。
- 3-5行目:データはカンマ区切り。ダブルクォーテーションで囲まれている。
- 6-7行目:データには改行がある。
- 8行目:C:/zenkoku.csvの1行目は無視する(csvの1行目はラベルのため)。
インポートするcsvにラベルが存在しない場合にはIGNORE 1 LINESを省略します。
データの出力
本章ではcsvをtableにインポートして、Excelからそれにアクセスしてpivotすることが目的です。必ずしもデータのcsv出力が必要にはなりませんが、csvの入力と似た操作なのでここで紹介します。
先ほど格納したデータの全てのカラムを20行だけCドライブ直下にcsvとして出力することを考えます。クエリは下記のとおりです。今までに紹介していないコマンドも含まれていますが、ここではこんなものだと思って先に進みましょう。
SELECT * FROM jusyo LIMIT 20
INTO OUTFILE 'C:/zenkoku_out.csv'
FIELDS
TERMINATED BY ','
ENCLOSED BY '"';
このクエリが伝えていることは下記のことです。
- 1行目:jusyoから全てのカラム(*)を20行(LIMIT 20)選択(SELECT)。
- 2行目:選択したデータをC:/zenkoku_out.csvへ出力。
- 3-5行目:出力データはカンマ区切り、ダブルクォーテーションで囲まれている。
実行が成功すればCドライブ直下にzenkoku_out.csvが生成されます。
Excel pivotとの連携
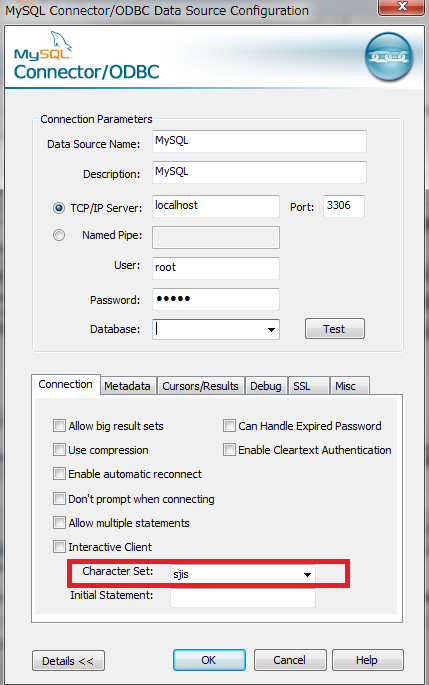
jusyoテーブルにアクセスしてpivotしてみましょう。sjisのデータからpivotを活用するために、ODBCに少し設定が必要になります。プログラムとファイルの検索からodbcad32.exeを実行します。ユーザDSNのMySQLを選択して構成ボタンを押します。
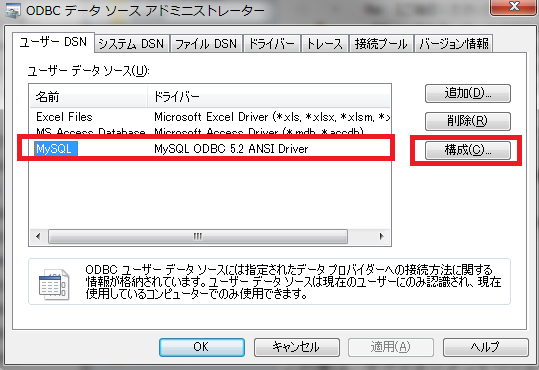
MySQL Connector/ODBC Data Source Configurationが立ち上がったら、Detailsボタンを押します。ConnectionタブのCharacter Setでsjisを選択しOKボタンを押します。
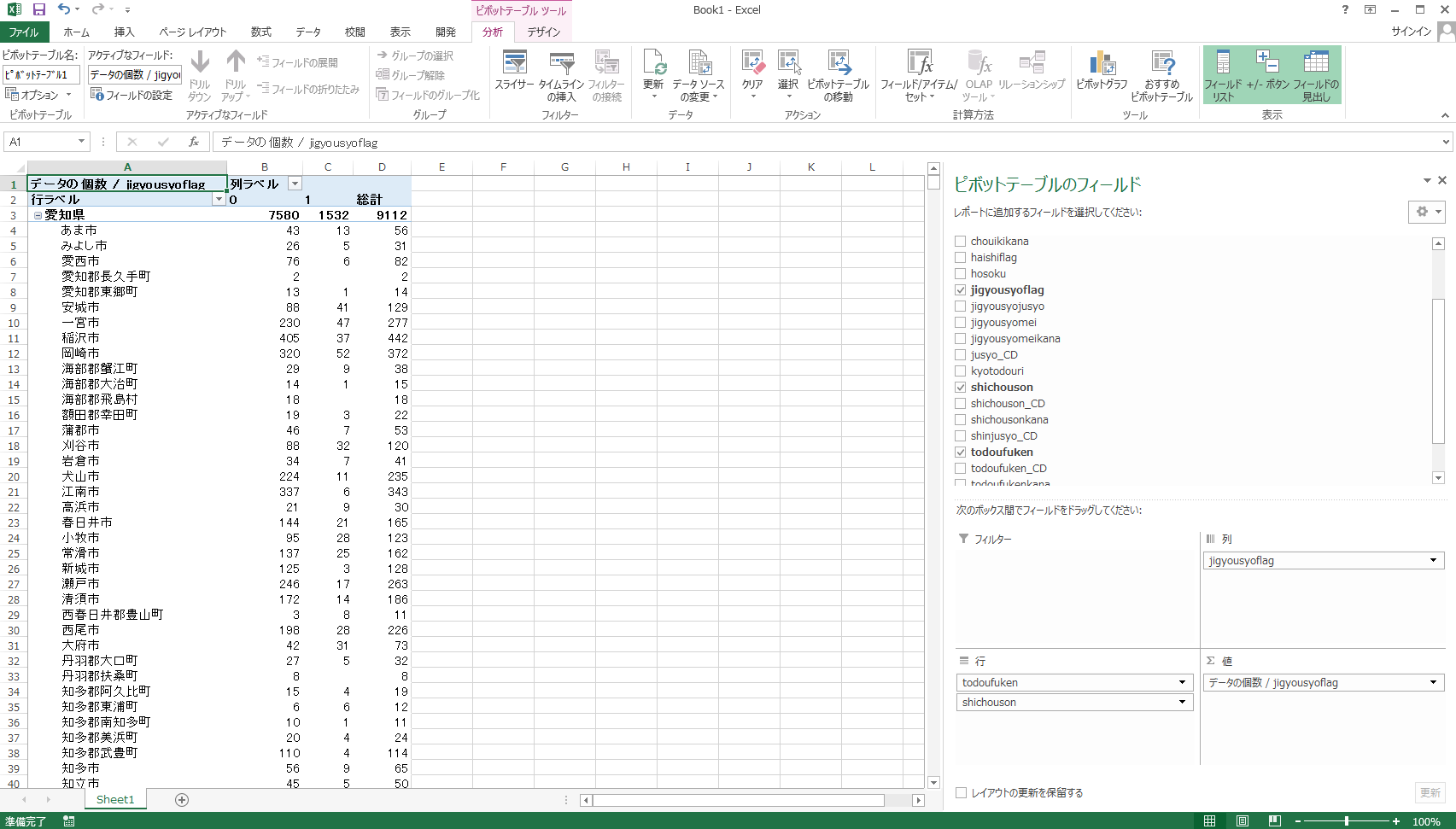
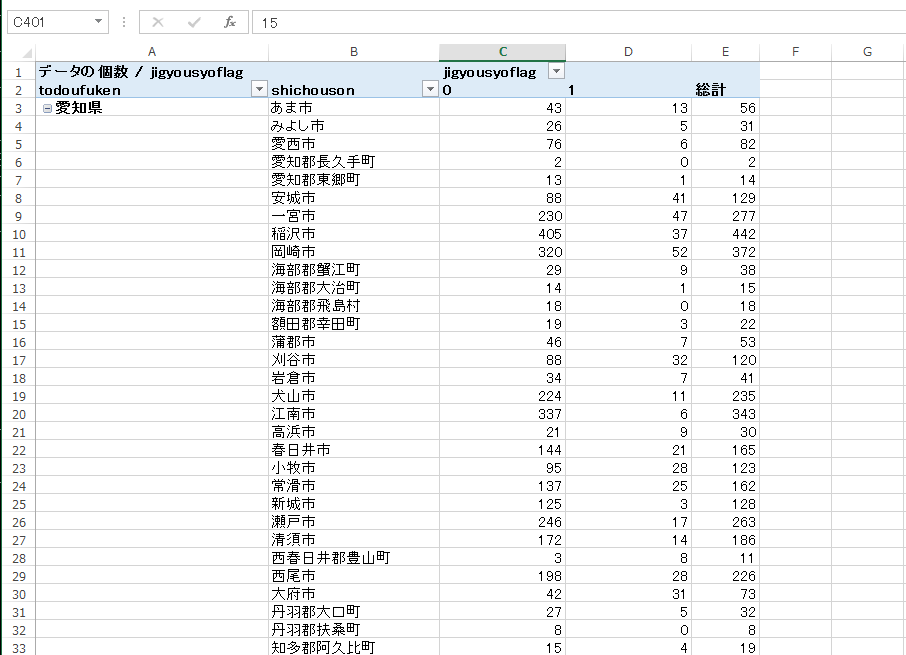
第3章の手順でzenkoku databaseのjusyoテーブルに接続します。行にtodoufuken, shichousonを順に挿入します。列と∑値にjigyousyoflagを挿入します。∑値の中はデータの個数になっていることを確認します。
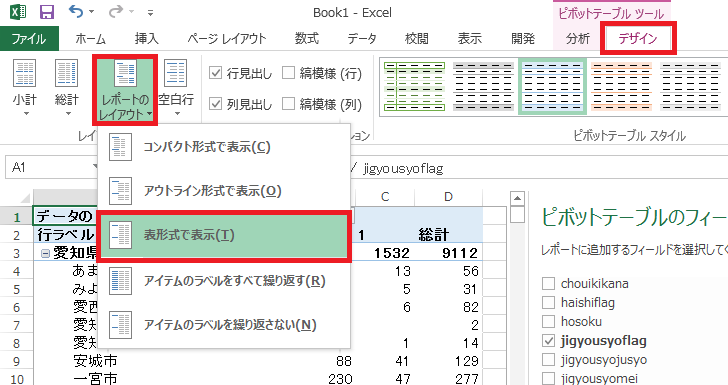
次にテーブルを整理しましょう。ピボットテーブルツールのデザインからレポートのレイアウト、表形式で表示を指定します。
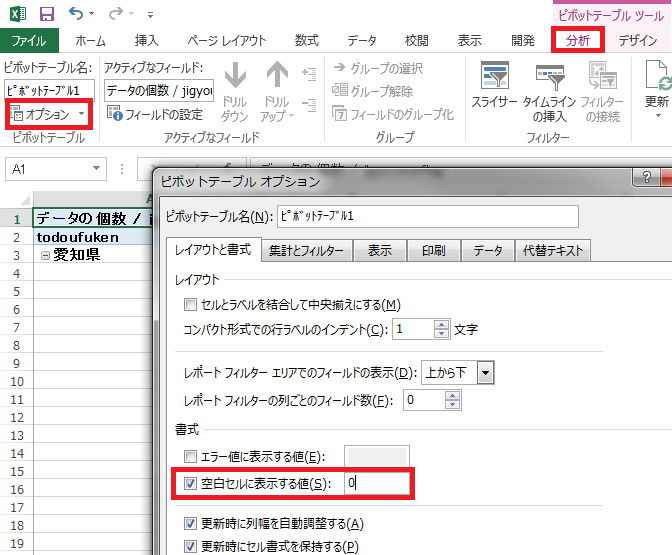
さらに空白セルを0で埋めるため、ピボットテーブルツールのオプションを開き、空白セルに表示する値に0を挿入して
OKします。
操作が完了すると次のように都道府県、市町村ごとに事業所(flag 1)・非事業所(flag 0)数を表した表が出力されます。
まとめ
本章では実際にMySQLにcsvデータを取り込んでピボットする方法を紹介してきました。紹介してきた内容はExcelで開けないような少々容量が大きめのcsvに対し、クロス集計でデータをさっと可視化したい場合とても便利です(64bit版Excel2013使用)。
本章ではMySQLへcsvを入出力する方法を紹介しました。これを知っていればMySQL単体でのcsv集計も実施することができます。複数のテーブルが存在する場合には、本章で紹介しなかったMySQLのJoin構文(MySQLの書籍をご参照ください)を活用することでEcxelのVLOOKUPのようなテーブル結合を行うことも可能です。予め結合したテーブルを用意しpivotに読み込ませることで、より複雑なテーブルに対してクロス集計が可能になります。
次回からはExcelに備わっている分析ツールやソルバーの導入方法について紹介したいと思います。
===========================================