SIGNATE Questを利用した背景
業務の一環としてBI環境の構築(Talend、Snowflake、Quicksight)を行ってきた中で、機械学習は学びたいと思いながら中々手を付けることができなかった分野でした。
SIGNATEにて"Beginner限定コンペ"が開催されることを知りましたので、この機会にチャレンジしてみようと思いました。
どこから手を付けてよいかわからない状態でありましたが、"金融機関におけるテレマーケティングの効率化"の一部が無料で開放されておりましたので、こちらで学んだ内容を自分の学習メモとして記録しておく為に本記事を作成しております。
基礎
# pandasのインポート
import pandas as pd
# データの読み込み
df = pd.read_csv('data.csv', index_col='id')
#数値型データの基本統計量
print( df.describe() )
#文字列型データの基本統計量
print( df.describe(include=['O']) )
※ゼロではなく、大文字のオーです。
# 変数dfの型の表示
print( type(df) )
# カラムyの表示
print( df['y'] )
# カラムyのみを取り出したデータの型の表示
print( type(df['y']) )
# カラムage, job, yをこの順に取り出したデータの表示
print( df[['age', 'job', 'y']] )
# インデックス2,3 カラムage, job, yをこの順に取り出したデータの表示
print( df.loc[[2, 3], ['age', 'job', 'y']] )
# カラムyを取り除いたデータの表示
print( df.drop('y', axis=1) )
#単純集計
# カラムpoutcomeの要素の種類と出現数の表示
print( df['poutcome'].value_counts() )
# カラムyの要素の種類と出現数の表示
print( df['y'].value_counts() )
# value_counts関数を使うことで、そのカラムに存在する要素とその出現数を表示
print( df['poutcome'].value_counts() )
変数の相関
1.数値で確認
- 相関係数
2.可視化して確認
- 散布図
- 箱ひげ図
相関係数
Pandasライブラリの関数の1つであるcorr関数。数値データのクロス集計で相関を示す。
print(df.corr())

可視化
相関を表す方法として散布図と箱ひげ図が多用される。
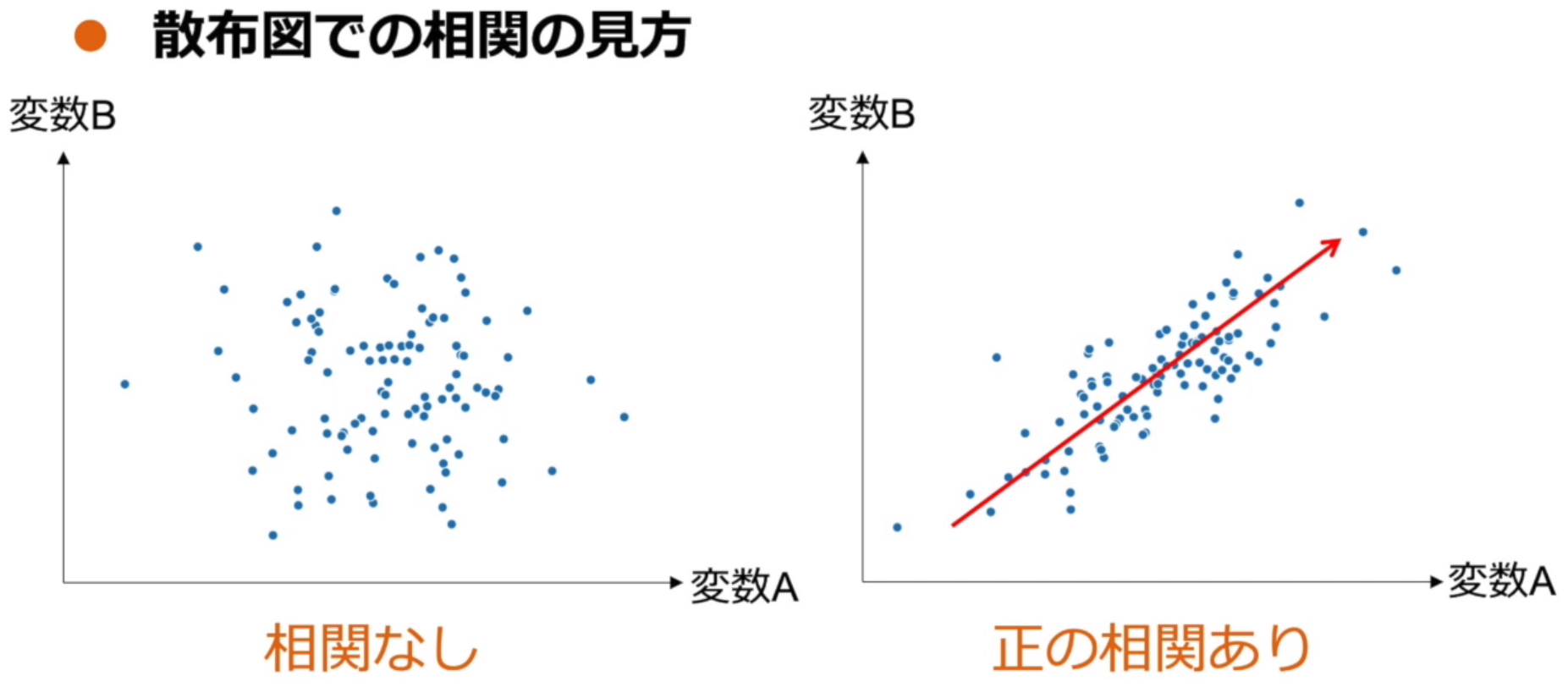
散布図
量的データ同士の相関を確認する際に使用する
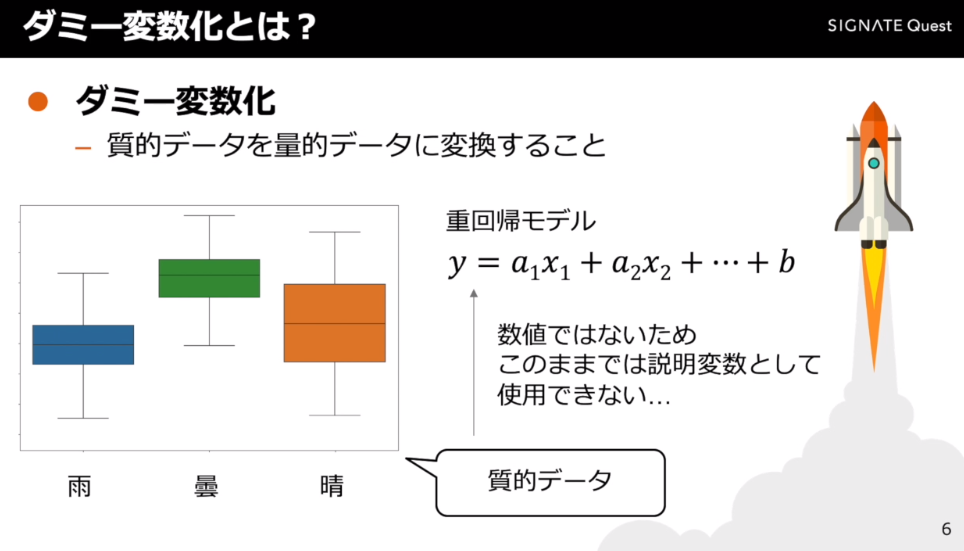
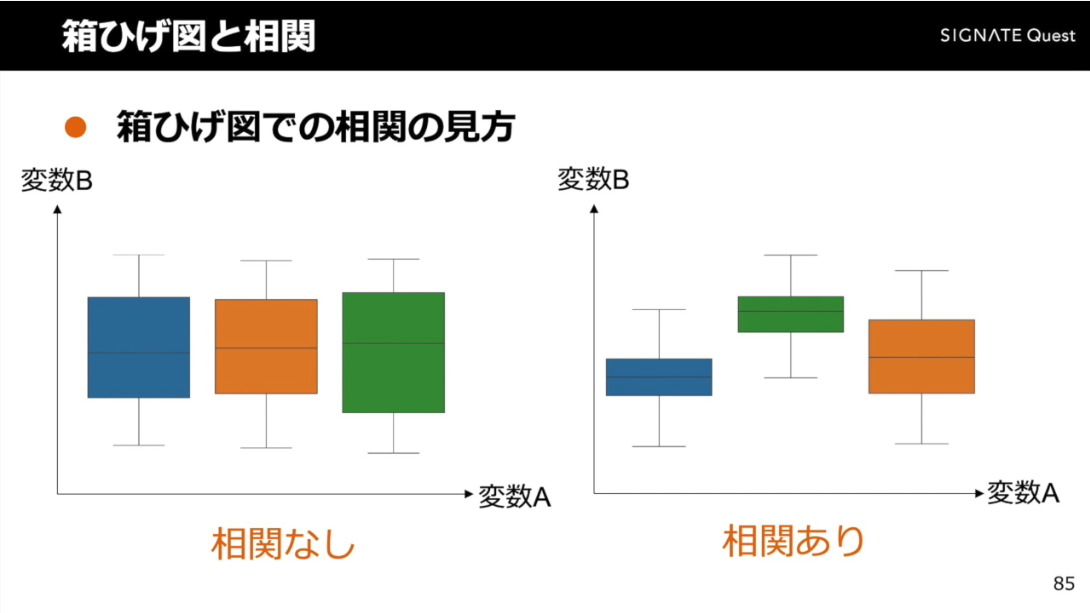
箱ひげ図
量的データと質的データの相関を確認する際に使用する
箱ひげ図の作り方
1.質的データと量的データの表を作成する
2.質的データごとにそれぞれの量的データをもとに箱ひげ図を作成する
(下記の例だとaの場合に最大値4、最小値1の箱ひげ図を作成する)


分析方法
定額預金申込有無には、どのような変数が影響を与えているか、基本統計量やグラフを見ながら仮説を立ててみましょう。闇雲にデータを見るのではなく、仮説を立てて検証していくことで、効率的に分析を進めることができます。例えば以下のようなものが考えられます。
仮説1. 前回キャンペーンで申し込みの実績がある人はリピートしやすいのではないか(満足できる商品だった場合に限るが)。
仮説2. 定期預金は自由に引き出しができない商品なので、まとまった余裕資金のある人が申し込みやすいのではないだろうか。
仮説3. 営業との接触時間が長かった人は、申し込みに気持ちが揺らぎやすいのではないだろうか(営業マンの手腕によるが)。
クロス集計
仮説1を実証する為に、(1)前回のOperationで作成したクロス集計結果を代入した変数crossを利用してカラムpoutcomeの要素毎の申込率を計算し、変数rateに代入しましょう。
# クロス集計の実行
import pandas as pd
df = pd.read_csv('data.csv', index_col='id')
cross = pd.crosstab(df['poutcome'], df['y'], margins=True)
# 申込率の計算
rate = cross[1] / cross["All"]
# クロス集計結果に申込率cvrを追加
cross["cvr"] = rate
print( cross )
# クロス集計表からインデックス'success', 'failure'、カラム'cvr'のみを取り出して表示
print( cross.loc[["success", "failure"], "cvr"])
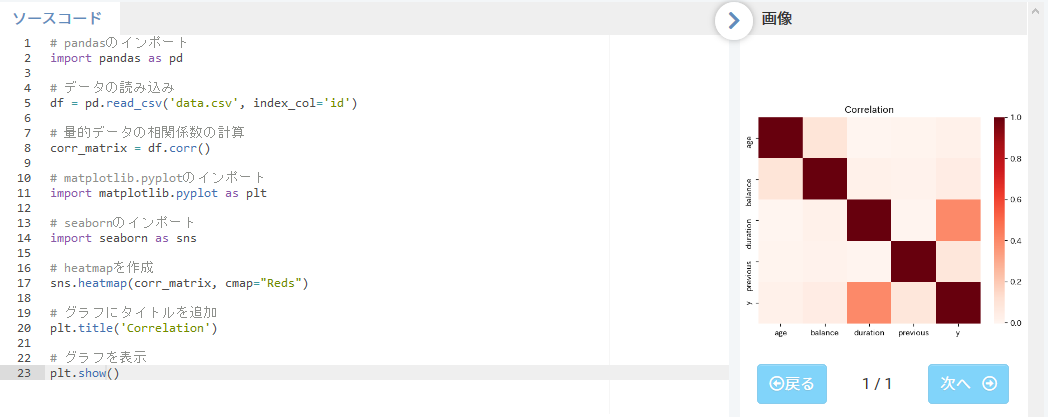
ヒートマップの表示
相関関係をマトリクスの表として作成しても、数値の羅列では何が相関が高いのか分かりにくいため、可視化して確認します。
# ライブラリのインポート
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# データの読み込み
df = pd.read_csv('data.csv', index_col='id')
# 量的データの相関係数の計算
corr_matrix = df.corr()
# heatmapを作成
sns.heatmap(corr_matrix, cmap="Reds")
# グラフにタイトルを追加
plt.title('Correlation')
# グラフを表示
plt.show()
データのフィルタリング
PandasではDataFrameを代入した変数[ 条件式 ]と記述することで、Excelのフィルタ機能と同様の処理ができます。条件式をDataFrameを代入した変数['カラム名']==値 と与えると、そのカラムがその値をもつ行のみを抽出できます。代表的な条件式は次のようなものがあります。
指定した値と等しいデータ : DataFrameを代入した変数['カラム名'] == 値
指定した値と異なるデータ : DataFrameを代入した変数['カラム名'] != 値
指定した値より大きいデータ : DataFrameを代入した変数['カラム名'] > 値
指定した値以上のデータ : DataFrameを代入した変数['カラム名'] >= 値
例えばDataFrameを代入した変数をXとしたとき、カラムAの値が0であるという条件でデータをフィルタリングするには次のように記述します。
X[X['カラムA'] == 0]
さらにフィルタリングしたデータの特定のカラムBのみ選択したい場合は、次のように記述します。
X[X['カラムA'] == 0]['カラムB']
この機能を使えば、カラムy(定期預金申込有無(1:有, 0:無))が'1'のときのカラムduration(最終接触時間)だけを抽出することができます。
# pandasのインポート
import pandas as pd
# データの読み込み
df = pd.read_csv('data.csv', index_col='id')
# yの値が1のデータを表示
print( df[df['y']==1] )
# yの値が1のデータのdurationを表示
print( df[df['y']==1]['duration'] )
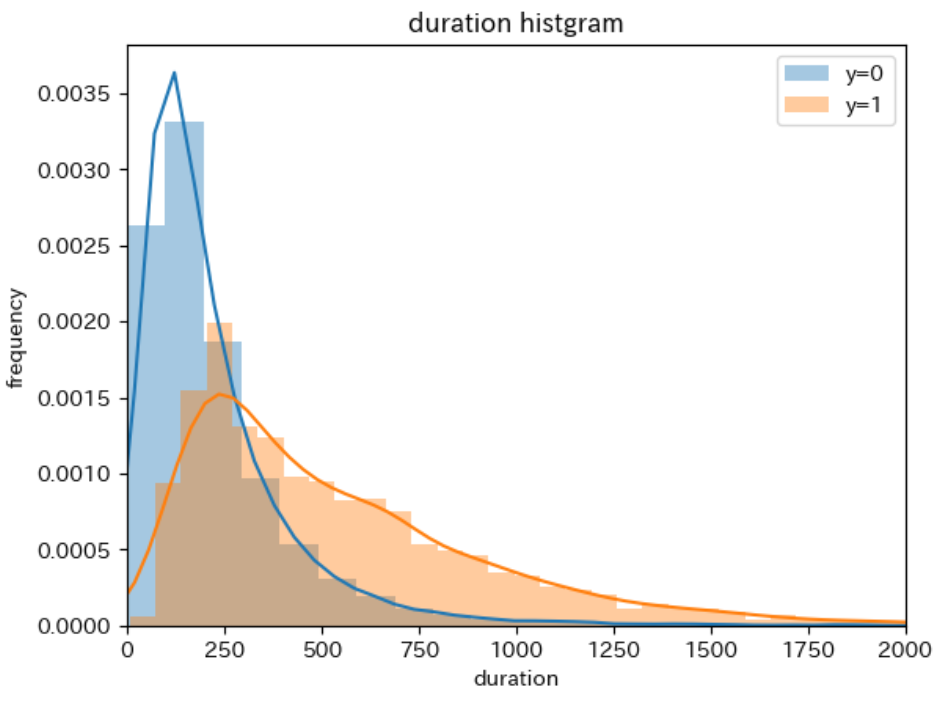
ヒストグラムの描画
数値データのデータ分布を確かめる可視化方法としてはヒストグラムがあります。ヒストグラムを用いることで、数値データの値域や、数値データの中で一番頻度が高い値域がどこであるかを確認することができます。
それでは、カラムduration(最終接触時間)について、カラムy(定期預金申込有無(1:有, 0:無))が0の場合と1の場合とで分けた2種類のヒストグラムを1つのグラフ上に描画し分布を比較してみましょう。ヒストグラムの作成には、seaborn の distplot 関数を使って次のように記述します。
seaborn.distplot(Seriesを代入した変数)
なお、2種類のデータを重ねるには、distplot関数を2回記述するだけで描画できます。
グラフに凡例をつける場合は、distplotのオプションでラベル名を指定しておき、その後matplotlibのlegend関数を記述します。
seaborn.distplot(Seriesを代入した変数, label="ラベル名")
matplotlib.pyplot.legend()
matplotlibには、グラフの見栄えを整えるために多くの関数が用意されています。例えば、x軸やy軸に名前をつけるには、xlabel関数、ylabel関数を使います。
matplotlib.pyplot.xlabel(x軸の名前)
matplotlib.pyplot.ylabel(y軸の名前)
また、x軸の表示範囲を指定するにはxlim関数を使います。(y軸もylim関数で同様に表示範囲を指定できます。)
matplotlib.pyplot.xlim(x軸の下限値, x軸の上限値)
# pandasのインポート
import pandas as pd
# データの読み込み
df = pd.read_csv('data.csv', index_col='id')
# matplotlib.pyplotのインポート
import matplotlib.pyplot as plt
# seabornのインポート
import seaborn as sns
# durationの抜き出し
duration_0 = df[df['y']==0]['duration']
duration_1 = df[df['y']==1]['duration']
# ヒストグラムの作成
sns.distplot(duration_0, label='y=0')
sns.distplot(duration_1, label='y=1')
# グラフにタイトルを追加
plt.title('duration histgram')
# グラフのx軸に名前を追加
plt.xlabel('duration')
# グラフのy軸に名前を追加
plt.ylabel('frequency')
# x軸の表示範囲の指定
plt.xlim(0, 2000)
# グラフに凡例を追加
plt.legend()
# グラフを表示
plt.show()
特徴量の生成と加工