リアルタイムランキングの最適化の話
リアルタイムランキングを普通のデータベースでやると、それなりに大変だ。ユーザが数万人くらいだったとしても、結構大変。今なら、Redisのソート済リストなんかで管理する手もあるね。でも、ランキングを管理するのって、地味にいろんなコストがかかる。Redisなら、パフォーマンスは出そうだけど、例えば、10万人×10指標で100万件のデータがオンメモリになってたら、嬉しいかな? 望ましくは、もっと本質的なロジックの部分でリソースを使いたいよね。そこで、順位の近似値でリアルタイムランキングをし、きりのいいところで(イベント終了時とかね)バッチで順位を提供する、というのも、有力な戦略になる。
ここで紹介するやり方は、1件当たりのスコア更新の計算量が償却定数、必要メモリが定数となる。精度を犠牲にして計算量とメモリ使用量を抑える、極めてゲーム業界的なアルゴリズムだ。
順位の近似値の要件
さて、順位の近似値ってどうやるか。近似値とは言っても譲れない条件はある。
- トップ1000位くらいは、正確なリアルタイムランキングじゃないと、ゲームなんかでは求道者の皆さんに失礼。
- a.score >= b.score ならば、a.rank >= b.rank
- a.score == b.score ならば、a.rank == b.rank
- たとえば「ストック数」みたいに、1点単位のスコアなら、0~300点くらいの人の順位も正確に出しておきたい。(総参加人数を明らかにしている場合、ユーザにとっても推計しやすいデータなので、ここが不正確だと近似値だとばれやすい)
ここで、手抜くポイントは、
- a.score != b.score ならば、a.rank != b.rankという条件は捨てる
という割り切りだ。(というか、上の条件にこの条件を足すと、近似値じゃなく、精確な順位を出すことになる)
正直、ランキング真ん中へんは、ユーザが自分のリアルタイムランキングを見ていても、73462位->72196位->73221位みたいにころころ変わるから、競ってる仲間との相対的な位置関係が保たれていれば、ある程度の誤差はまずわかんないのだ。
さあ、もうだいたい判った? よね?
ここまで言えば、だいたいやり口は見えたんじゃないかな? 中間層はスコア濃度分布だけを管理し、順位がクエリーされたらナノ秒単位でちゃちゃっと積分して返し、上位の全てと下位のスコア別人数だけ正確にカウントするような「オンメモリいかさま順位データベース」があればいいのだね。ただ、全体の得点域が拡大していくことを前提にすると、濃度分布の管理の仕方には、一定の工夫が必要になる。(縮小もする場合、下手すると誤差が大きくなってしまうのだが、点差そのものは開いていくので、中間層の順位の誤差は気にしなくていいのだ)
このアルゴリズムの実装は、C++かJavaで Reader-Writer lock を噛ましてオンメモリで行うのがオススメだが(それなら、指標を相当数抱えても大丈夫だ)、今日び、Node.jsでやりたい向きもあるだろう。そこで、サンプルソースはJavascript(CoffeeScript)で新たに書き起こすことにしたい。Javascriptでも実用的な速度で使えるはずだ。
麻雀の待ち牌の話・麻雀の理牌の話以来のちょっとゲーム寄りのお話。どうかな。アルゴリズムというタグを付けた割に、ずるい、実装上の工夫的な話なのだが……。
詳細に入っていくよ
まず、トップ1000位以内は、UserIDとScoreとRankを生で持つ。ここは配列操作で問題無い。挿入場所はバイナリサーチだが、母数が常に1000件なので、計算コストも比較10回、常に一定だ。下位の、score別人数で管理されている人びとも、score n点の時、((総対象人数)-(0点~n点までの人数の累計)+1)位なので問題無い。これらは全て、精確な順位だ。問題は、中間層だ。中間層は、一定間隔のスコア階層ごとの人数、つまり、ヒストグラムで管理する。既に述べたトップグループと下位グループの間を128~256分割したヒストグラムに保管するのだ。最初期はヒストグラムの各階層の値の幅は1点とし、差が開いて256分割に達するか超えたら、ヒストグラムの隣り合う2階層ずつを足してヒストグラム全体の長さを半分にする。以後同様に繰り返しだ。点数が増加する一方の場合には、これだけで良い。点数が増減する場合でも、基本的に点差は開く一方だと考えられるので、その場合下位グループなしで、トップグループと中間層だけを扱うようにすればいい。ただ、値のブレで、上位陣のデータに欠損が生じる可能性があるので、その際はDBアクセスするか、そのための特殊処理を加えるかはサービスによるだろう。(点数が増加する一方でも、上位陣に垢BANが発生した時には1000位以内のデータに欠損が生じる)
では、そのヒストグラムから個々の順位をどのように推計するか、そこが問題だ。正規分布などを歪めてフィッティングしたり、ベジェで近似したりしても、そこまで精度が上がるわけではないし、(正直、全く精度は上がらないよ!)何より、計算量が大きくなっては元も子もない。なので、濃度分布を折れ線で近似する。各区間の人数を値の幅で割った値を Cn とする。区間の境目の値をそれぞれ (Cn-1+Cn)/2, (Cn+Cn+1)/2 とすると、区間の中央の値を (6*Cn-Cn-1-Cn+1)/4 とすると、この折れ線より下の面積は、Cn より下の面積と等しくなる。つまり、この折れ線を積分すれば、この中での順位が分かるのだ。積分とは言っても、台形の面積の高々2つの和だ。C++なら無視できるような時間で計算できる。
わかりやすい例で図示すると、下記の通りだ。ただし、この単純なやり方では、ピークが尖ってしまう、という弱点があるのだが、そういうのをあまり丁寧に避けていると地味に地味に性能が悪化して行く。どこかで手を打つ必要があるので、そこは慎重になって欲しい。ピークとなる区間は、台形では無くヒストグラムの長方形のまま扱う、という程度にしておくのが良いだろう。それにしてもバグの原因になりそうな条件分岐を伴うので、あまりオススメはできない。ただ、ピークのあたりは尖らせない方が精度が高いのは確かだ。
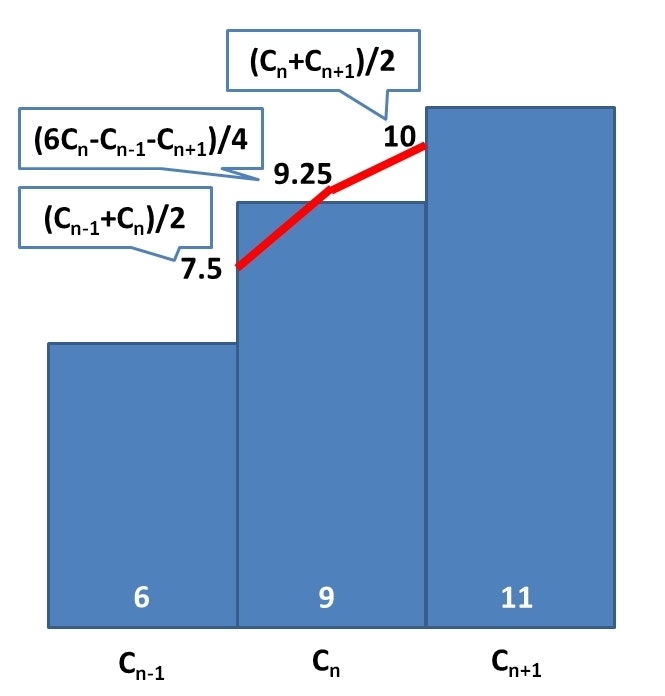
もちろん、端っこの階層は、「両側」を参照して決めるわけにはいかない。ヒストグラムの内側の端点は同じように隣り合う濃度の算術平均を使うとして、区間の中央と、外側の端点は、 (3*Cn-Cm)/2 を用いれば良い。
では、この後に、コード例と共に、もう少し実装上の工夫について触れよう。例えば、トップ1000人目と同着の人びとの扱いとかね。実装にはまだまだ考えるべきことがある。(あとで)
複数サーバにスケールアップする時
どうせ1指標あたり30kb不変なので、全ゲームサーバがそれぞれ上記のランキング管理クラスを持っていて、自分以外のサーバーは、負荷調整や再起動のためのユーザのリダイレクトとかを管理するサーバみたいな、全ゲームサーバと全2重通信を張っているようなサーバーが、他のサーバで起きた指標の更新を、まとめて数秒おきに配信すればいいでござるよ。
ただ、上位陣はそういうわけにもいかない。人生を半ば賭けちゃってるので、上位陣のデータだけは優先的に配信する、みたいな処理は必要だと思うよ。それ以外は、そこそこトロくても良い。
基本的に、UserID,指標種別,更新前Score,更新後Scoreというデータがあれば良くって、ネットワーク経由で聞いた情報も、サーバ内での指標更新と同じように扱えば良い。「同じUserIDかつ同じ指標」の更新が複数溜まることがあったら(そして、ゲームなんかの場合は、たいていそういう風に更新されるもんだよね)、更新後Scoreだけ書き換えて複数の更新データを統合できるので、全体的にサーバ群が重い時には、配信間隔を長めに取れば、矛盾なくサボれる。
DBの更新も、どうせ複数の列を更新するんだったらまとめた方が全体最適なので、今だったらRedisみたいに永続化の効くキャッシュに溜めといて、遅延更新させれば良かろう。ただし、DBをまたいだ処理はアトミックにはなり得ないので、遅延更新中に墜ちた時は「運営からのお詫び」発動だけどね。DBも内部ネットワークも超強力になってるんだったら、クエリ垂れ流しでも良いんだけどさ。でもね、毎回UPDATEしても、たまにUPDATEしても、最終結果は変わらないのに総I/O・総メモリ・総CPUコストが激減する状態だと、間欠的に更新する誘惑には勝てないと思うな。クリティカルなビジネス用途ではそういうのやっちゃ駄目だけどさ。
あと、もいっこ注意は、集計中にサーバを起動する際、他サーバの手抜きランキングクラスを丸ごとコピーする機能が無いと、えらく起動に時間がかかることになっちゃうってことかな。DBから全員分のヒストグラムを構築できる集計を、ロックを獲得した上でゲットするなんて、「サーバを追加しなきゃいけない状況」では殊更ムリゲーだよね。ranking_clone、必要、ゼッタイ。でも、ここでも1指標30kbというのが活きる。ちょっとしたCSSファイルくらいの重さなのだ。内部ネットワークでの通信なら一瞬だよね。タイミング調整だけちょっと注意、と言ったところかな。
おわりに
このアイディア、1指標あたり30kbくらいでむっちゃくちゃ高速なリアルタイムランキングが実現できるので、実用性はあると思うんだ。麻雀の話みたいに、後で少しずつ加筆していくスタイルで書くつもりだよ。スケーリングの話もあぶね、って感じだし、誤差もおっかね、って感じなので、ゲーム以外の応用があるのかどうかは分からない。でもそういう用途があるなら、コメントで教えてもらえると、勉強になるので嬉しいよ。