Googleスプレットシート便利ですよね。便利すぎて幸福度爆上がりです。
入れ子(ネスト)なしJSONを書き出すのは難しくないのですが、入れ子(ネスト)ありのJSONを書き出す必要があるので死ぬ気で調べました![]()
あまりにもヒットしなさすぎて死ぬかと思った![]()
スプレットシートからJSONを書き出したい
400点以上あるデザインアイテムを管理しているのですが、その結果が列A〜AYの51列、495行ものスプレットシート。
今後も追加していくので、間違いなく成長しますw(MacBook Pro16インチで見るのは大変キビシイ![]() )
)
近々メンテをする予定なのですが、実際のスプレットシートを大公開するわけにもいかず、同じようなサンプルデーターが落ちてないかな?と考えていると。
あったんですよ。
『青空文庫』の作家一覧データベースが。
今回はこれを例に記事を書こうと思います。
スプレットシートにやって欲しいこと
次の事をスプレットシートにはお願いしたい。
- 情報を一元化したい
- 一元化されたデーターから作家別に書籍情報を抽出してスプレットシートを作りたい
- 書籍情報は入れ子(ネスト)ありのJSONで書き出したい
- 複数の作家別シートをひとつにまとめてJSONに書き出したい
『1』に関しては『青空文庫|公開中 作家リスト:全て』からCSVをダウンロードして、スプレットシートにインポートします。
ExcelでCSVを開くとファイル形式やら何やら尋ねられますが、GoogleドライブにCSVを放り込むと簡単にインポートしてくれます。
サブメニューを出し、アプリで開く > Google スプレットシート
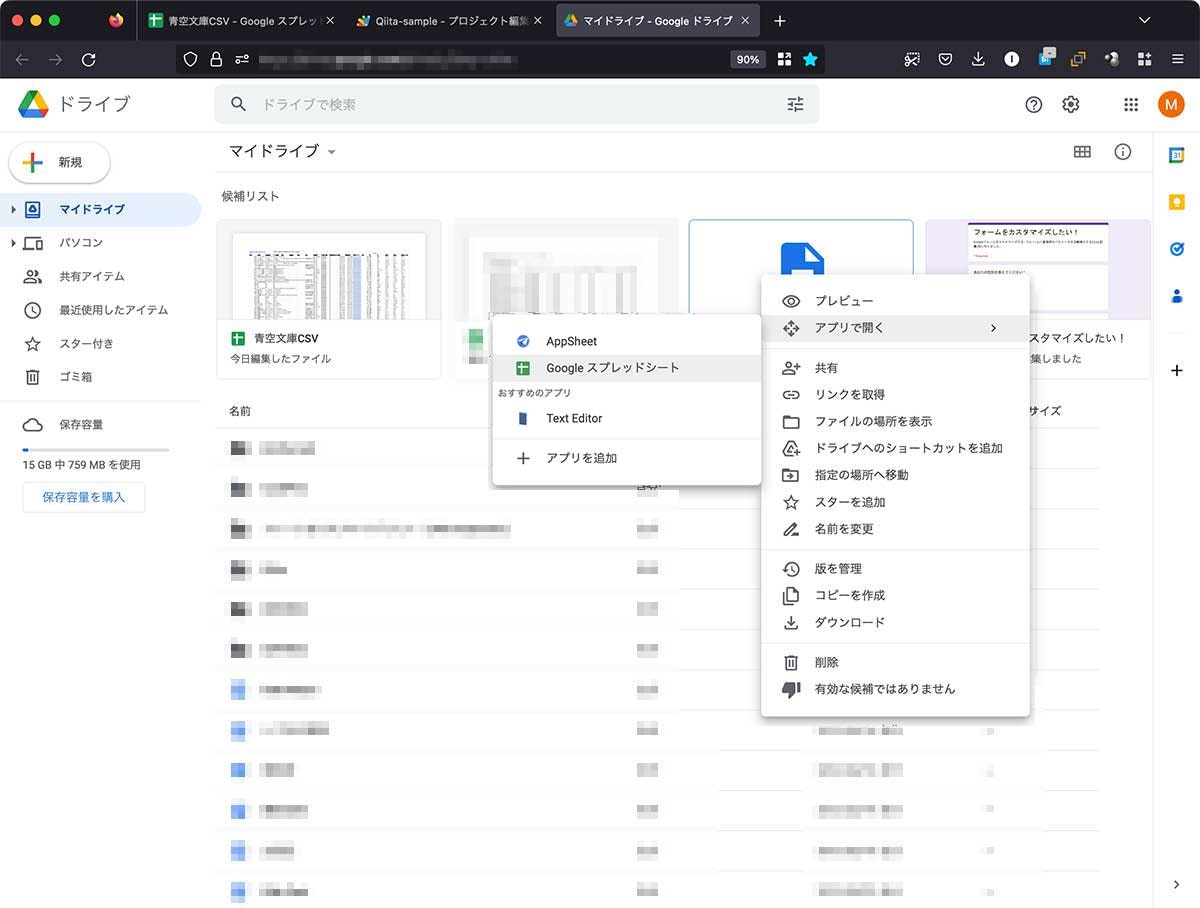
なんて便利な!![]()
すでに整理されているデーターなので、今回用にメチャクチャになるようにソートしましたw
このCSVをDLした時点で17798作品あるらしく、すごい量のデーターを見ることができますw
たまにスプレットシートが処理を停止するぐらいに重いw
書き出して欲しいJSON形式
書籍名・発行元・発行日・著者・収録作品ID・収録作品タイトル・図書カードURLをこんな感じにできるとうれしい。
[
{
"originalText": "現代日本文學全集 第三〇篇 芥川龍之介集",
"publisher": "改造社",
"issueDate": "1928(昭和3)年1月9日",
"author": {
"lastName": "芥川",
"firstName": "竜之介"
},
"titles": [
{
"id": 24453,
"title": "蜜柑",
"url": "https://www.aozora.gr.jp/cards/000879/card24453.html"
},
{
"id": 24454,
"title": "藪の中",
"url": "https://www.aozora.gr.jp/cards/000879/card24454.html"
}
]
}
]
Query関数を使って別シートに内容を抽出する
全作品が入っている ![]() 青空文庫CSV から、直接JSONを取り出すとめちゃくちゃ時間かかりそうだし、今回は特定の作家以外の作品は排除したい。
青空文庫CSV から、直接JSONを取り出すとめちゃくちゃ時間かかりそうだし、今回は特定の作家以外の作品は排除したい。
![]() 青空文庫CSVにソートをかけてもいけど、原本には手を入れたくない。
青空文庫CSVにソートをかけてもいけど、原本には手を入れたくない。
なので、作家別のシートを作ろうと思います。
基本、抽出する時はこんな感じ。
= QUERY('スプレットシート名'!参照範囲,"クエリ(検索項目)",[見出し行数])
このままだと ![]() 青空文庫CSVと同じ内容になるので、select句を使ってJSONに書き出したい内容の列を指定します。
青空文庫CSVと同じ内容になるので、select句を使ってJSONに書き出したい内容の列を指定します。
= QUERY('青空文庫CSV'!A3:BD,"select A, B, N, P, Q, Z, AB, AC, AD",1)
芥川龍介の著作一覧を作りたい
「芥川」の著作だけを抜き出したいので、where句で条件抽出します。
= QUERY('青空文庫CSV'!A3:BD,"select A, B, N, P, Q, Z, AB, AC, AD where P = '芥川'",1)
![]() 芥川一覧ではB2にクエリを書いて、B5の関数は
芥川一覧ではB2にクエリを書いて、B5の関数は=QUERY('青空文庫CSV'!A4:BD,B2,1)としています。
「竜之介じゃない人」フィルタで確認すると、紗織さん・多加志さんも一緒に抽出している事がわかります。
通常のフィルタを使った場合、共同編集者の表示にもフィルタがかかるので、利用者によってはとても迷惑です。
しかし、名前をつけたフィルタを使用した場合、共同編集者の表示に影響しないので非常に便利です。

今回は竜之介さんの著作一覧を作りたいので複数条件にします。
- = QUERY('青空文庫CSV'!A3:BD,"select A, B, N, P, Q, Z, AB, AC, AD where P = '芥川'",1)
+ = QUERY('青空文庫CSV'!A3:BD,"select A, B, N, P, Q, Z, AB, AC, AD where P = '芥川' and Q = '竜之介'",1)
また、![]() 青空文庫CSV は作品IDからリストが始まっていますが、今回は書籍ごとにまとめる予定なので、列の表示順も変更します。
青空文庫CSV は作品IDからリストが始まっていますが、今回は書籍ごとにまとめる予定なので、列の表示順も変更します。
さらに、出版年ごとにソートしたいのですが、Query関数で抽出した一覧では「フィルタ」によるソートができません。
クエリにソートを追加します。
今回は底本初版発行年1と底本名1で昇順にします。
- = QUERY('青空文庫CSV'!A3:BD,"select A, B, N, P, Q, Z, AB, AC, AD where P = '芥川' and Q = '竜之介'",1)
+ = QUERY('青空文庫CSV'!A3:BD,"select AB, AC, A, B, AD, N, P, Q where P = '芥川' and Q = '竜之介' order by AD asc, AB asc",1)
で、ここで気づいたのですが、『青空文庫』では「芥川龍之介」を 「芥川竜之介」と表記しています。
誤植じゃないの?ってTwitterで呟いている人を見かけたのですが、どうやら誤植ではない様子。
引用:「竜」と「龍」はどちらが正しいの? | 生徒の広場 | 浜島書店
2002年から使用する歴史の教科書では,次のようになっていますよ。
坂本竜馬…東京書籍,教育出版,日本書籍,帝国書院,清水書院
坂本龍馬…大阪書籍
芥川竜之介…東京書籍
芥川龍之介…大阪書籍,帝国書院
「竜」は「龍」を簡単にした漢字で、前者は常用漢字です。また、「龍」は人名用漢字ではありません。
そのため、国語審議会の方針に従うパターンと本人が使っていた漢字を優先するパターンで表記が異なるようです。
『青空文庫』は「芥川竜之介」パターンを採用しているため、この記事内も「竜之介」表記で行こうと思います。
この関数を使用した ![]() 芥川竜之介一覧|翻訳作品ありを確認してみると、昇順にした関係で、底本初版発行年1と底本名1が空欄の作品が一番最初に表示されます。
芥川竜之介一覧|翻訳作品ありを確認してみると、昇順にした関係で、底本初版発行年1と底本名1が空欄の作品が一番最初に表示されます。
詳細を調べてみたところ、「後世」という作品の英訳版が『青空文庫』に登録されていることがわかりました。
「後世」自体は著作権が失効してパブリックドメインになっていますが、翻訳者の著作権が発生し「クリエイティブ・コモン4.0」による公開がなされています。
今回のJSONには翻訳者の項目を設けなかったので、英訳版「後世」はJSONに追加しない事にしました。
そこで、この項目を取り除くため、「底本名1」が空欄だった場合、その項目は抽出しない事にします。
- = QUERY('青空文庫CSV'!A3:BD,"select AB, AC, A, B, AD, N, P, Q where P = '芥川' and Q = '竜之介' order by AD asc, AB asc",1)
+ = QUERY('青空文庫CSV'!A3:BD,"select AB, AC, A, B, AD, N, P, Q where AB is not null and P = '芥川' and Q = '竜之介' order by AD asc, AB asc",1)
やっと「芥川竜之介」のパブリックドメイン作品のみを抽出できました。→ ![]() 芥川竜之介一覧
芥川竜之介一覧
正しく抽出されているかは、![]() 青空文庫CSV シートの「芥川竜之介」フィルタを使うと確認できます。
青空文庫CSV シートの「芥川竜之介」フィルタを使うと確認できます。
JSONを書き出すためのGASを追加する
JSONを書き出すために、Apps Scriptに3つのファイルを追加します。
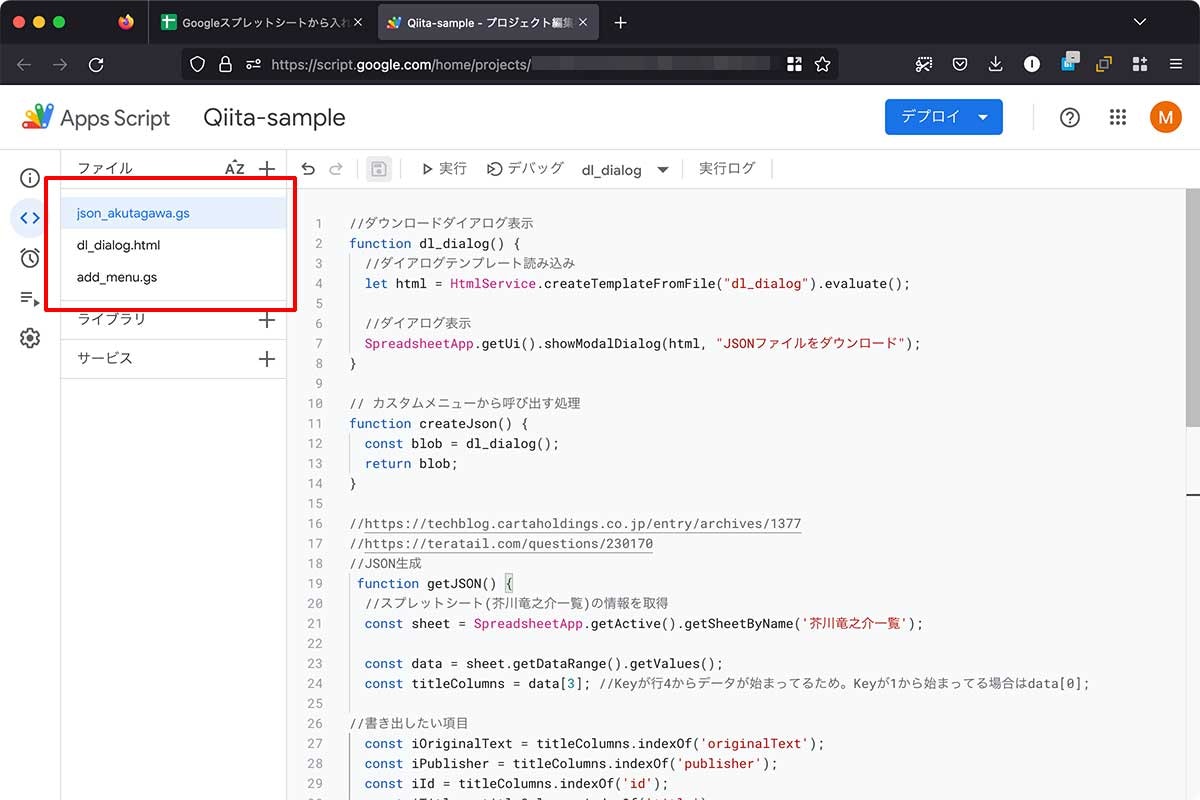
これ、つらかった…めっちゃ辛いし、めっちゃ切り貼りした!![]()
ファイル名や関数名とかは不問で!不問でお願いします!
プログラムに弱いデザイナーには辛すぎる苦行…そうして出来た切り貼りGASがこちらです![]()
JSONを作るGAS
//JSON生成
function getJSON() {
//スプレットシート(芥川竜之介一覧)の情報を取得
const sheet = SpreadsheetApp.getActive().getSheetByName('芥川竜之介一覧');
const data = sheet.getDataRange().getValues();
const titleColumns = data[3]; //Keyが行4からデータが始まってるため。Keyが1から始まってる場合はdata[0];
//書き出したい項目
const iOriginalText = titleColumns.indexOf('originalText');
const iPublisher = titleColumns.indexOf('publisher');
const iId = titleColumns.indexOf('id');
const iTitle = titleColumns.indexOf('title');
const iIssueDate = titleColumns.indexOf('issueDate');
const iUrl = titleColumns.indexOf('url');
const iLastName = titleColumns.indexOf('lastName');
const iFirstName = titleColumns.indexOf('firstName');
//JSON形式配列
let dataArray = [];
let dataDic = {};
for(let i = 5; i < data.length; i++) { //行6からデータが始まってるため。本来はvar i = 1
let rowData = data[i];
let key = rowData[iOriginalText]+ '|' + rowData[iPublisher]+ '|' + rowData[iIssueDate];
if (dataDic[key] !== undefined) {
dataArray[dataDic[key]]['titles'].push(
{
"id":rowData[iId],
"title":rowData[iTitle],
"url":rowData[iUrl]
}
);
} else {
dataDic[key] = dataArray.push(
{
"originalText":rowData[iOriginalText],
"publisher":rowData[iPublisher],
"issueDate":rowData[iIssueDate],
"author": {
"lastName":rowData[iLastName],
"firstName":rowData[iFirstName]
},
"titles": [
{
"id":rowData[iId],
"title":rowData[iTitle],
"url":rowData[iUrl]
}
]
}
) - 1;
}
}
//JSON整形なし
//return JSON.stringify(dataArray);
//JSON整形あり
return JSON.stringify(dataArray, null, '\t')
}
JSONをダウンロードするGAS
生成されたJSONのダウンロードを実行するために、カスタムメニューに「芥川竜之介JSON」を追加します。
また、ダウンロード用のダイアログを出すのですが、いちいちクリックするのが面倒なので、「芥川竜之介JSON」を選んだら勝手にダウンロードしてダイアログを閉じるようにします。
json_akutagawa.gsの冒頭にカスタムメニューを呼び出す処理とダウンロードダイアログ表示を追加
// カスタムメニューから呼び出す処理
function createJson() {
const blob = dl_dialog();
return blob;
}
//ダウンロードダイアログ表示
function dl_dialog() {
//ダイアログテンプレート読み込み
let html = HtmlService.createTemplateFromFile("dl_dialog").evaluate();
//ダイアログ表示
SpreadsheetApp.getUi().showModalDialog(html, "JSONファイルをダウンロード");
}
===== ここから下は「JSONを作るGAS」と同じ =====
//JSON生成
function getJSON() {
//アクティブなスプレットシート内の「芥川竜之介一覧」タブを取得
const sheet = SpreadsheetApp.getActive().getSheetByName('芥川竜之介一覧');
⁝
ダウンロードする時に呼び出すテンプレートHTMLを追加
<!DOCTYPE html>
<html>
<head>
<base target="_top">
<script type='text/javascript'>
window.onload = function(){
handleDownload();
}
//ダウンロード実行
function handleDownload() {
//JSONデータの取得
const content = <?= getJSON(); ?>;
//コンテンツタイプ
const contentType = 'text/plain';
//保存名
const fileName = 'akutagawa.json'
//blob生成
const blob = new Blob([ content ], { "type" : contentType});
// aタグを生成
const link = document.createElement('a');
// ダウンロード
link.download = fileName;
link.href = window.URL.createObjectURL(blob);
link.click();
// ダイアログを閉じる
google.script.host.close();
}
</script>
</head>
<body>
</body>
</html>
</html>
カスタムメニューに「芥川竜之介JSON」を追加するスクリプト
function onOpen() {
var ui = SpreadsheetApp.getUi()
//メニュー名を決定
var menu = ui.createMenu("JSON書き出し");
//メニューに実行ボタン名と関数を割り当て
menu.addItem("芥川竜之介JSON", "createJson");
//menu.addSeparator(); 区切り線を追加
//スプレッドシートに反映
menu.addToUi();
}
こんな感じになります。

複数のシートをひとつにまとめて一覧を作りたい
複数作家の一覧を合体するのはあまりなさそうですが、「カテゴリー」ならあり得そう。
芥川竜之介を激推ししていた事で有名な太宰治と一緒にしてみます。
=QUERY({'芥川竜之介一覧'!B5:I;'太宰治一覧'!B6:I},"where Col1 is not null order by Col5 asc")
![]() 芥川竜之介&太宰治一覧
芥川竜之介&太宰治一覧
シートの名前と抽出する範囲を;で繋げると幾つでも合体させることができます。「太宰治一覧」がB6から始まっているのは、項目タイトルを除外したためです(除外しないと行の一番下に表示されます)。
今までと違い列の名前ではなく抽出する範囲から何番目のセルという指定になります。
わかりやすいように「底本初版発行年1」の昇順にしてみました。
ちょっと便利な関数
年月日付の年だけ取り出したい
『青空文庫』に掲載されている作品の元になった書籍を「底本」と呼ぶのですが、違う版を参考にした作品もあるせいか、次のような表示もあります。
1968(昭和43)年11月15日、1984(昭和59)年12月25日38刷改版
これを年だけ表記にできないかなあ…と考えたわけです。
サンプルで作っているものなので、本来なら記載されたすべての西暦を抜き出すところですが、冒頭の「年」だけ抜き出す事にします。
REGEXEXTRACT関数を使って、正規表現で抜き出せればいいんだけどなあ。
J6に次の関数追加します。
=IFERROR(ArrayFormula(REGEXEXTRACT($F6:F, "(\d+)")),)
年月日をセルで分割するなら、こんな感じになるはず。
=IFERROR(ArrayFormula(REGEXEXTRACT($F6:F, "(\d+)((.+)).(\d+)月(\d+)日")),)
…どちらも全然うまくいってないw
ひとつのセルに2つ以上の年月日が入っている作品もあるし、年のみ記載しているものもあったりします。
書き方が一定ではないので、本格的にやるならもう少し捻りが必要。
もう疲れたので、今回は諦めたw
どちらかというと ArrayFormula関数が便利だよという方が大きかったりします。
1行づつ同じ関数を入れなくてもJ6に記載するだけで、指定した範囲に適用してくれます。
関数のコピペミスも防げて、超幸せになれるはず![]()
正規表現云々よりも、これが便利だったから中途半端な状態で書いただけですw
もう少しやりたかったこと
毎度おなじみ時間切れです![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
今回はスプレットシートもJSONのファイル名も指定して書き出しをしていますが、選択しているスプレットシート(タブ)を取得して、タブの名前をJSONファイルの名前として取得すれば、ひとつのGASで処理できると思います。
スクリプトにベタ書きすると横展開が面倒になるので、時間がある時にでもやりたいなあ。
…年末はめちゃくちゃ忙しいし、今日はクリスマス![]() なのに、なんでこんな事してるんだろう
なのに、なんでこんな事してるんだろう![]()
参考リンク
- JSON整形&構文チェック:jsonデータ、jsonファイルをフォーマットする | ラッコツールズ🔧
- スプレッドシートをJSON形式に出力する方法 - CARTA TECH BLOG
- GASでJSONを任意の出力形式にしたい