HadoopをVagrant上に構築して、株価の相関を求める
「Hadoopなんて、クラスタ環境を用意しないと使えない」と思っていたが、1PCでHadoopを動かせると知ったので、Vagrantの中で動かしてみた。
目次
- Hadoop環境構築
- Job作成
- 低スペックによる悲劇
Hadoop環境構築
Vagrant(CentOS6.5)を使用。
Hadoop のシングルノード作成方法を見ながら作成。
基本的に
JDK本体と、Hadoopをインストールして、SSHを使えるようにすれば完成。
この環境でコンパイルして、Hadoopコマンドで、実行できる。
Job作成
身近な題材として、株価の相関を求めることに決定。暴落と暴騰による阿鼻叫喚を引き起こした2014年10月の3週間(10/5~10/27)の変動で、似た動きの株があるかどうかを確かめてみる。
対象は、日本に上場している株式約4000と、SBI証券で公開されている投資信託約2000。
普段はpythonで一瞬相関を出しているが、今回はHadoopの分散を意識し、分散共分散行列から相関行列を自力で出している。詳細はGithub
基本的に日数のオーダーのデータ量は1リデュースで処理できると想定している。
フローとしては、ステップを分け、それぞれでMRを実行する。
(runjob.shが実行順序)
1.時系列データから行列を作成する
マップでは株をキーとして分割し、リデュースで日付と株価のMapを作成
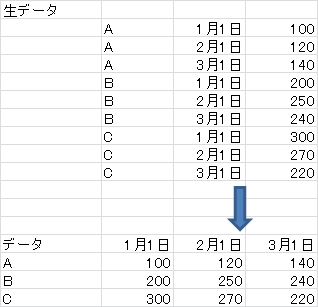
2.株価の行番号を求める(行列として計算したいが、株データがばらばらに来るせいで行番号がわからないため)
3.各株の平均から正規化する
マップでは、株をキーとして分割するだけ。
リデュースで平均をだし、各値を平均で引く。
4.分散共分散行列を出す
株Aと株Bのデータを求めるためには、両株のデータが全てがそろっている必要があるので、株数x株数にキーを分けてマップする。
リデュースでは共分散(分散)を求めるのに必要なデータがそろっているので計算する。
5.相関行列を出す。
分散共分散行列からそれぞれの相関を出すために必要なデータをキーに分けてマップする。(今回は対角をキーとしてマップしている。(2,1)のデータは(2,2)をキーとする)
リデュースで、各相関を計算する。
6.各相関は行列の番号になっているので、銘柄名に置き換える。
以上でコードが完成したので、実行する。
低スペックによる悲劇
実行したら、データが得られると思ったのだが、スペックが低すぎたため完全なデータが得られなかった。
1.ディスク容量不足
Hadoopでは、全マップ計算後にリデュースを行うためにマップで作成したデータを一時ファイルにする。その合計量がVagrantのデフォルト設定である40GBを超えて、クラッシュした。対象データから投資信託の一部を外して再開。
2.スワップによる遅延
データ量が多く、メモリに乗り切らず大量のスワップが発生。計算に4時間を要した。
実行完了
データ量を少なくして放置してやっと結果取得に成功。
結果としては、日経とTOPIXが最も相関が高いという、当たり前の結論等を得た。