はじめに
PHPで以前、ローレベルなソケット通信処理をガリガリ書いていたときに、gzip圧縮されたストリームの扱いに大変苦しんだ覚えがあります。今になってようやく解決策を得たので、ここにまとめさせていただきます。
gzipだとかzlibだとか全然詳しくありません。憶測で書いてる部分も多いです。詳しい方、間違っているところを発見したら是非コメント欄にて指摘お願いします。
検証に協力して頂いた @nullkal さんと @_wata1221 さん、ありがとうございました!ずっと悩んでいたことがスッキリして嬉しい限りです!
gzipのおさらい
deflate, gzip, zlib の違いって何?
| 名称 | 説明 |
|---|---|
| deflate | 圧縮アルゴリズム。ペイロードのみを生成する。 |
| gzip | deflateを利用してデータを圧縮するコマンドラインツールの名称、またはそれが採用している圧縮データフォーマットの名称。メタデータを付加する。 |
| zlib | deflateを利用してデータを圧縮するC言語で作成されたライブラリの名称、またはそれが採用している圧縮データフォーマットの名称。メタデータを付加する。 |
- gzipとzlibでメタデータの内容は異なる。
- zlibはgzipの圧縮データフォーマットもサポートしている。
- PHPはエクステンションとしてzlibを利用している。
- HTTP通信で最も多く利用されているものはgzip圧縮データフォーマットである。
gzdeflate, gzencode, gzcompress の挙動を実際に確かめてみる
ここでは a という1バイトの文字を圧縮してみます。サイズが肥大化してるとか突っ込まれたら負けだけど気にしない。
$funcs = ['gzdeflate', 'gzencode', 'gzcompress'];
print_r(array_map(
function ($func) { return bin2hex($func('a')); },
array_combine($funcs, $funcs)
));
Array
(
[gzdeflate] => 4b0400
[gzencode] => 1f8b080000000000000b4b040043beb7e801000000
[gzcompress] => 789c4b040000620062
)
| 関数名 | 実行結果(16進数) |
|---|---|
| gzdeflate | 4b0400 |
| gzencode |
1f8b 08 00 00000000 00 0b 4b0400 43beb7e8 01000000
|
| gzcompress |
78 9c 4b0400 00620062
|
gzipのデータフォーマット
RFC 1952 GZIP file format specification version 4.3 日本語訳 を参考にしています。
| 名称 | データ(16進数) | 説明 |
|---|---|---|
| ID | 1f8b | gzipのデータフォーマットであることを示す固定値。 |
| CM | 08 |
08 はdeflateを利用していることを表すが、これもほぼ固定値と考えていい。 |
| FLG | 00 |
00 はFTEXT、つまりASCIIテキストであることを示す。 |
| MTIME | 00000000 | 圧縮元ファイルの最終更新時刻を示すが、今回は使用されていない。 |
| XFL | 00 | 圧縮レベルを表すが、今回は使用されていない。 |
| OS | 0b | OSを表す。0b はWindowsであることを示す。 |
| … | … | … |
| CRC32 | 43beb7e8 | 破損や改竄を検出するためのチェックサム。 |
| ISIZE | 01000000 |
元のデータ長 % 2^32 の値。リトルエンディアンなので1を意味する。 |
zlibのデータフォーマット
RFC 1950 ZLIB Compressed Data Format Specification version 3.3 日本語訳 を参考にしています。
| 名称 | データ(16進数) | 説明 |
|---|---|---|
| CMF | 78 | 2進数でみてCINFO 0111 とCM 1000 に分割される。 |
| FLG | 9c | 2進数でみてFLEVEL 10 とFDICT 0 とFCHECK 11100 に分割される。 |
| … | … | … |
| ADLER32 | 00620062 | 破損や改竄を検出するためのチェックサム。 |
| 名称 | データ(16進数) | 説明 |
|---|---|---|
| CM | 08 |
08 はdeflateを利用していることを表すが、これもほぼ固定値と考えていい。 |
| CINFO | 07 | ウィンドウサイズを表す。 07 の場合、32Kとなる。 |
| FCHECK | 1c | フラグ部分用のチェックサム。 |
| FDICT | 00 | このフラグが有効な場合辞書が使用されるが、今回は無関係である。 |
| FLEVEL | 02 | 圧縮レベルを表す。 02 はデフォルトレベルを示している。 |
有限長の文字列から展開する
gzinflate, gzdecode, gzuncompress
文字列に格納されたデータを、圧縮時の方式にあったもので展開します。HTTP通信の内容を展開する場合、ほぼ確実に gzdecode 関数を使うことになるでしょう。
$fp = fsockopen('ssl://qiita.com', 443);
fwrite($fp, implode("\r\n", [
'GET / HTTP/1.0',
'Host: qiita.com',
'Connection: close',
'Accept-Encoding: gzip',
'',
'',
]));
$html = gzdecode(explode("\r\n\r\n", stream_get_contents($fp))[1]);
$context = stream_context_create([
'http' => ['header' => 'Accept-Encoding: gzip'],
]);
$fp = fopen('https://qiita.com/', 'rb', false, $context);
$html = gzdecode(stream_get_contents($fp));
$context = stream_context_create([
'http' => ['header' => 'Accept-Encoding: gzip'],
]);
$html = gzdecode(file_get_contents('https://qiita.com/', false, $context));
zlib_decode
この関数はわざわざ使い分けしなくても3種類のフォーマットを自動判別してくれるみたいですね!便利です。
ストリームから自動展開する
有限長のデータではなく、ストリームを逐次展開していきたい場合はこの方法を用います。こちらで用いられている圧縮データフォーマットがよく理解できなかったので、解説は控えてとりあえず解決策だけ掲載しておきます。詳しい方がおられましたらコメント欄で教えてください。
gzopen
fopen の代わりのような関数です。読み出しには専用関数 gzgets, gzread, gzpassthru などが用意されています。但し、ストリームコンテキストを指定することが出来ません。
$data = '';
$fp = gzopen('data.gz', 'rb');
while (false !== $line .= gzgets($fp)) {
$data .= $line;
}
実は専用関数ではない fgets, fread, fpassthru も全く同じように使用することが出来ます。何のための専用関数なんでしょうか。
$data = '';
$fp = gzopen('data.gz', 'rb');
while (false !== $line .= fgets($fp)) {
$data .= $line;
}
どうせならもう stream_get_contents が一番いいよね。
$data = stream_get_contents(gzopen('data.gz', 'rb'));
readgzfile
readfile の代わりのような関数です。但し、ストリームコンテキストを指定することが出来ません。
ob_start();
readgzfile('data.gz');
$data = ob_get_clean();
gzfile_get_contents とかあって欲しい。
compress.zlib://
ストリームラッパーなので使い勝手がいいです。ストリームコンテキストを絡めることが出来ます。
$context = stream_context_create([
'http' => ['header' => 'Accept-Encoding: gzip'],
]);
$fp = fopen('compress.zlib://https://qiita.com/', 'rb', false, $context);
$html = stream_get_contents($fp);
$context = stream_context_create([
'http' => ['header' => 'Accept-Encoding: gzip'],
]);
$html = file_get_contents(
'compress.zlib://https://qiita.com/',
false,
$context
);
ところが、これを fsockopen からは実現できないのです。これでは、以下の全てを求める要件を満たすことが出来ません。
-
Transfer-Encoding: chunkedである -
Content-Encoding: gzipである - 双方向ストリームとしてローレベルな処理を行いたい
さて、どうしましょう…?
ストリームに流れる一部の文字列から展開する
リクエストの組み立て ~ ヘッダーの読み出し
chunkedなgzipのストリームは、以下のような構造になっています。
※ 通常のchunkedなストリームは理解している前提です

要点を挙げると…
- 第2チャンク以降の中身には、(gzip圧縮における)ペイロードしか含まれない。
- どのペイロードも、展開するには第1チャンクに含まれる gzipヘッダ の情報を必要とする。
- 「有限長の文字列から展開する」で紹介した関数群で取り扱うことは出来ない。
(…って考えたけどこれだと gzinflate で展開に失敗する理由が説明できないから多分説明間違ってる…)
TwitterのストリーミングAPIでの例を示します。細部は手抜きですがスルーしてください。
/* 署名の生成 */
$oauth_params = [
'oauth_consumer_key' => 'コンシューマーキー',
'oauth_signature_method' => 'HMAC-SHA1',
'oauth_timestamp' => time(),
'oauth_version' => '1.0',
'oauth_nonce' => md5(mt_rand()),
'oauth_token' => 'アクセストークン',
];
$additional_params = ['track' => 'twitter'];
$base = $oauth_params + $additional_params;
$key = ['コンシューマーシークレット', 'アクセストークンシークレット'];
uksort($base, 'strnatcmp');
$oauth_params['oauth_signature'] = base64_encode(hash_hmac(
'sha1',
implode('&', array_map('rawurlencode', [
'GET',
'https://stream.twitter.com/1.1/statuses/filter.json',
http_build_query($base, '', '&', PHP_QUERY_RFC3986)
])),
implode('&', array_map('rawurlencode', $key)),
true
));
foreach ($oauth_params as $name => $value) {
$items[] = sprintf('%s="%s"', urlencode($name), urlencode($value));
}
$authorization = 'OAuth ' . implode(', ', $items);
/* 接続してリクエストヘッダを送信 */
$fp = fsockopen('ssl://stream.twitter.com', 443);
fwrite($fp, implode("\r\n", [
'GET /1.1/statuses/filter.json?track=twitter HTTP/1.1',
'Host: stream.twitter.com',
"Authorization: $authorization",
'Accept-Encoding: gzip',
'',
'',
]));
/* レスポンスヘッダの読み飛ばし */
while (fgets($fp) !== "\r\n");
ここまでは下準備です。
レスポンスボディの読み出し
/**
* gzipヘッダの読み取り
*/
// チャンクサイズ分だけ読み取る
// (サイズ文字列の末尾に改行コードが付随するが数値キャストすれば無視されるので問題ない)
$header = fread($fp, base_convert(fgets($fp), 16, 10));
// データ末尾の改行コードを読み飛ばす
fgets($fp);
/**
* ペイロードの読み出し
*/
while ($size = base_convert(fgets($fp), 16, 10)) {
// 圧縮を展開して表示する
readgzfile(
'data://text/plain;base64,' .
base64_encode($header . fread($fp, $size)) /* ここでヘッダを結合する! */
);
// データ末尾の改行コードを読み飛ばす
fgets($fp);
}
こうすると無事、展開に成功します!JSONがターミナル上にダーッっと流れ込んでくるのが分かると思います。もしJSONをデコードしてツイート本文だけを流したい場合は以下のようにしてください。
/**
* ペイロードの読み出し
*/
$buffer = '';
while ($size = base_convert(fgets($fp), 16, 10)) {
// 圧縮を展開してバッファに追加する
$buffer .= stream_get_contents(gzopen(
'data://text/plain;base64,' .
base64_encode($header . fread($fp, $size)), /* ここでヘッダを結合する! */
'rb'
));
// データ末尾の改行コードを読み飛ばす
fgets($fp);
// 末尾が改行であればJSONデコードを試みる
if (preg_match("/\r\n\z/", $buffer)) {
// 遅いストリームではタイムアウト防止のためにTwitterが
// 空行を返してくるので、空行でないかの確認が必要
if ($buffer !== "\r\n") {
$status = json_decode($buffer);
// イベントなどは無視してツイートだけを取り扱う
if (isset($status->text)) {
var_dump(htmlspecialchars_decode($status->text, ENT_NOQUOTES));
}
}
// バッファをリセットする
$buffer = '';
}
}
こんな感じになるはずです↓
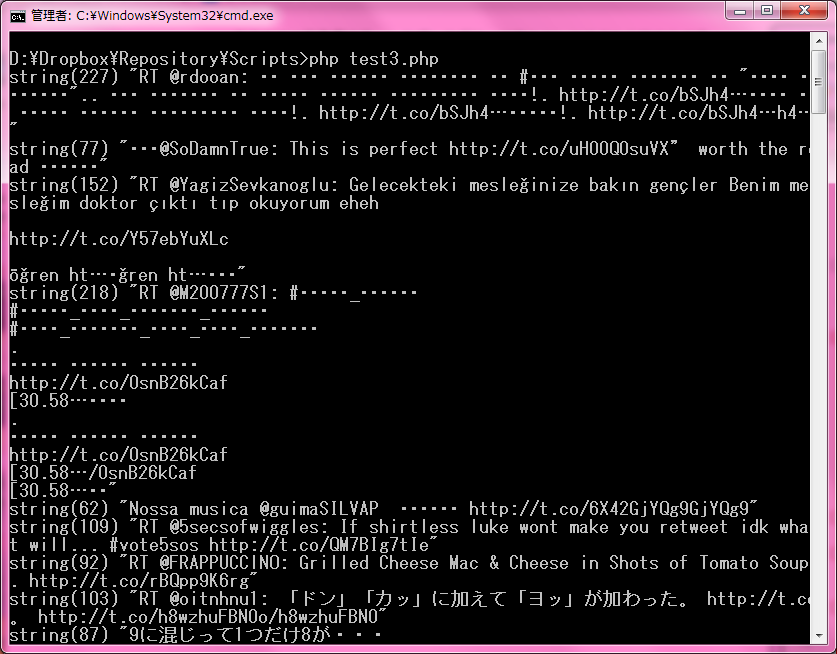
おわりに
解決策は分かったけど全然中身理解してないので誰か詳しい人教えてください(切実)