はじめに
淫夢要素はありません。
Simple HTML DOM Parser や Goutte の使い方は至る所で説明されていますが、PHPネイティブのDOMに関しての記事がかなり少ないので書いてみることにします。
ちなみに…
-
Simple HTML DOM Parserは内部で何回も正規表現を使って全ての要素をパースするので、かなり遅いです。これ使うぐらいなら最初から自分で正規表現一本で書いたほうがマシ。自分で正規表現を使って必要部分だけを抜き出す方法は、全ての方法の中で最も高速なので、正規表現が得意な人だったらこれでもいいと思います。 -
Goutteは内部でPHPネイティブのDOMを使ってます。PHPネイティブのDOMはDOMとして読ませる方法の中では最も高速なので良い方法をチョイスしていることになるのですが、そもそもGoutteに頼らなくてもそれなりに十分やっていけます。何より依存ファイルが何も無いのがいいですね。
そもそもスクレイピングとは何か?
最近の多くのWebサービスでは REST API という形式で、外部のスクリプトから利用するためのリソースが提供されています。最も利用されているフォーマットはJSONです。
JSONで提供されているリソースに関しては json_decode 関数を用いて、容易にPHP内で利用することが出来ます。
$json = '{name:"John Smith",age:33}';
$obj = json_decode($json);
echo $obj->name; // John Smith
ところがAPIが提供されていないWebサービスではどうなるでしょうか?多くの場合は、Webブラウザで閲覧することを目的として作成されたHTMLをスクリプトで取得し、解析するしか手段は残されていないはずです。この、HTMLを解析して必要な部分だけ 切り取る(scrape) 手法を総称して、 スクレイピング(scraping) というのです。
基本的な流れ (導入編)
[http://qiita.com/mpyw] (http://qiita.com/mpyw) の最新記事を最大5件スクレイピングする例を示していきます。具体的な実装は後ほど示しますので、ここではスクレイピングするコードを書くときの考え方をまとめます。
目的とする結果
最初に、目的とする結果を var_dump 関数を用いて示します。
array(5) {
[0]=>
array(6) {
["title"]=>
string(64) "array_rand関数の結果を日付ごとに一意に固定する"
["url"]=>
string(48) "http://qiita.com/mpyw/items/ab6e2cf5f64b8a9f3344"
["tags"]=>
array(2) {
[0]=>
string(3) "PHP"
[1]=>
string(9) "小ネタ"
}
["date"]=>
string(10) "2014/10/29"
["stock"]=>
int(6)
["comment"]=>
int(0)
}
[1]=> (省略)
[2]=> (省略)
[3]=> (省略)
[4]=> (省略)
}
スクレイピングの基本的な考え方
1. ソースを表示する
まずは目的のURLを開きましょう。そして、以下に紹介するどちらかを用いてHTMLソースを表示させます。
ブラウザのデバッガを使って閲覧する
IE Firefox Chrome とも、以下のいずれかの方法でデバッガを起動できます。
-
F12キーを押す。 - 右クリックでコンテキストメニューから「要素の検査」「要素を調査」「要素を検証」を選択する。
整形されたソースが表示されます。折り畳みや要素の検索などもでき、非常に使い勝手がいいです。但し、JavaScriptが実行された結果での表示となるので、PHPで取得したものとDOMの構成が異なる場合があります。
ブラウザのソースビュワーを使って閲覧する
IE Firefox Chrome とも、以下のいずれかの方法でソースビュワーを起動できます。
-
Ctrl + Uキーを押す。(IEは対象外) - 右クリックでコンテキストメニューから「ソースの表示」「ページのソースを表示」を選択する。
こちらの方法では純粋なレスポンスボディそのものが表示されますが、インデント整形などはされないので、非常に見にくい場合があります。そういうときは「HTML」「Parser」「Online」等のキーワードでググると幾つかツールが見つかるので、こういったものを活用しましょう。
2. 自分の抜き出したい情報をソース中から見つける
Ctrl + Fで検索ツールを起動し、目的の情報がどこにあるかを調べましょう。今回の例であれば「最近の投稿」というキーワードで検索すると容易に見つかります。
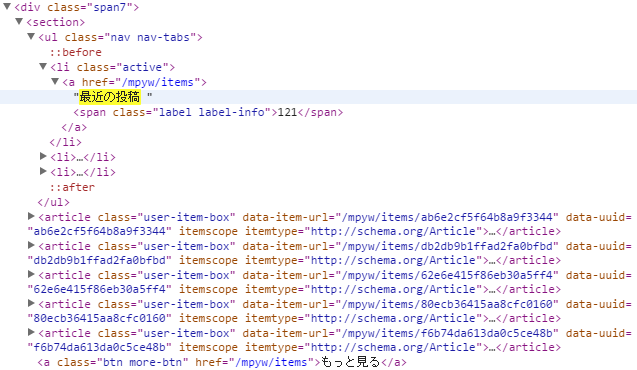
この下に表示されている<article>タグが目的の情報ですね。
3. どうすれば目的の情報だけを一意に抜き出せるかを考える
真っ先に思いつくのはこういう検索方法でしょう。
全体から <article> を検索
しかし、早合点してはいけません。ソース内を<articleで検索してみると、「最近の投稿」だけではなく「人気の投稿」もヒットしてしまいます。このままでは要らない情報も混じってしまうので、別の方法を考えなければなりません。
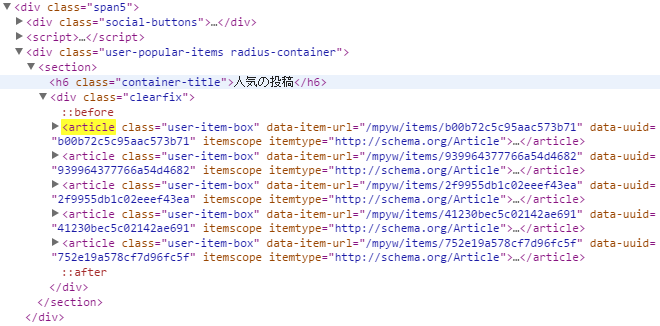
ここで上の方のノードに遡ると、「最近の投稿」「人気の投稿」がそれぞれ<div class="span7">``<div class="span5">に属していることが分かります。
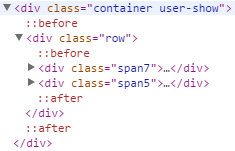
span7 というクラス名はここ以外では登場していないので、以下の検索条件によって望む結果が得られることが分かります。
全体から <div class="span7"> を検索し、その中にある <section> の中にある <article> を検索する
実際にこのような検索を行うには XPath式 の利用が欠かせませんので、次の章から説明していきます。
XPath式
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
</head>
<body>
<div id="yj">
<h1>野獣先輩の持つ異名</h1>
<ul>
<li>アンニュイ先輩</li>
<li>御満悦先輩</li>
<li>イ ン テ ル 長 友</li>
<li>鈴 木 福</li>
</ul>
</div>
<div id="mur">
<h1>大先輩の迷言</h1>
<img src="mur.png">
<ul>
<li>ポッチャマ…</li>
<li>ココアライオン</li>
<li>そうだよ(便乗)</li>
</ul>
</div>
</body>
</html>
文法
w3schools.com の XPath Tutorial に非常に分かりやすくまとめられています。ここでは更に内容を絞り込み、必要最小限のことについてだけまとめます。
階層の指定
日頃我々が利用しているファイルシステムと同じように、/ を区切り文字として扱う階層指定が行えます。
-
.は現在の階層を相対的に表します。一部の例外を除き、省略することが可能です。 -
..は上の階層を相対的に表します。 - 先頭の
/はルートノードの内側の階層を絶対的に表します。
<h1>野獣先輩の持つ異名</h1> と <h1>大先輩の迷言</h1> を取得する例
body/div/h1
./body/div/h1
./body/div/../div/../div/../div/h1
/body/div/h1
全ノードからの検索
-
//を先頭に書くと、ルートノードの内側にある全てのノードが対象になります。 - ノードの後ろに続けて記述すると、そのノードの内側にある全てのノードが対象になります。
<h1>野獣先輩の持つ異名</h1> と <h1>大先輩の迷言</h1> を取得する例
//div/h1
//h1
body//h1
属性
ノードとして要素だけを指定してきましたが、頭に @ をつけると属性もノードとして指定することが出来ます。
id="yj" と id="mur" を取得する例
//div/@id
//@id
内包するノード(子要素や属性)による絞り込み
ブラケット [] の中に、絞り込みに使う条件式を記述することが出来ます。ブラケット内部のコンテキストは、記述対象となるノードの内側です。
大先輩の迷言集を取得する例
//div[@id="mur"]/ul/li
//div[h1="大先輩の迷言"]/ul/li
//div[img]/ul/li
組み込み関数
w3schools.com の XPath Functions に非常に分かりやすくまとめられていますが、ここではその中でも頻繁に使うものを厳選して紹介します。
position() 関数
該当するノードの「番目」を返します。
- 【要注意】
position()関数の連番は1から始まります! - 省略形として
[position()=2]の代わりに[2]を利用できます。
<li>ココアライオン</li> を取得する例
//li[position()=6]
//ul[2]/li[2]
string() 関数
「ノード」から「文字列」に変換します。有用な使い方は後ほど記述します。
string(//li[6])
※ position()関数のようにブラケット内部にて引数なしで使う方法もあり、この際は絞り込みの対象となっているノード自身の文字列表現を返します。また、その際string()は単に.として簡略化出来ます。
substring() 関数
string()関数の亜種です。一部分のみを切り取ります。
- 第1引数でオフセットを指定します。
- 第2引数で長さを指定します。省略すると最後まで切り取ります。
- 【要注意】
substring()関数のオフセットは1から始まります!
substring(//li[6], 2, 3)
substring(//li[6], 5)
normalize-space() 関数
string()関数の亜種です。前後の空白をトリミングします。
クラスの概要
DOMNodeList クラス
複数の DOMNode のリストを保持しているクラスです。このクラスのインスタンスは DOMXPath::query() メソッドによって生成されます。説明の都合上、このクラスの紹介を頭の方に持ってきています。
DOMNodeList::length プロパティ
DOMNode の数が格納されています。
DOMNodeList::item() メソッド
指定した番目(インデックス)の DOMNode を返します。
- 【要注意】
DOMNodeList::item()メソッドの連番は0から始まります! - このクラスは
Traversableを実装しているため、foreach文で反復処理することが出来ます。以下の処理は等価です。
for ($i = 0; $i < $nodelist->length; ++$i) {
$node = $nodelist->item($i);
}
foreach ($nodelist as $node) { }
DOMNode クラス
DOMNode::nodeValue プロパティ
DOMNode::textContent プロパティ
DOMNode の内側に存在するテキスト部分のみが文字列として格納されています。これら2つはほとんどの場合において等価ですので、どちらを選択しても構いません。(例外)
- **【要注意】
DOMNodeList::item()メソッドで存在しないインデックスが指定されたとき、返り値はNULLになります!
**反復処理をしている場合を除き、プロパティを参照する際には返り値がNULLでないかどうか検証する必要があります。
$node = $node->item(114514);
$value = $node !== null ? $node->nodeValue : '';
DOMDocument クラス
スクレイピングを行うときは、このクラスのインスタンス生成から始まります。
DOMDocument::__construct() メソッド
新しく DOMDcoument のインスタンスを生成します。
$dom = new DOMDocument;
引数がありますが、省略しても問題ありません。
DOMDocument::loadHTML() メソッド
HTMLを読み込みます。
$dom->loadHTML($html);
Warningへの対応
この関数はHTMLとして正しくない箇所が一か所でもあると、処理上は問題無くてもWarningを発生します。これは無視しなければならないので、通常この部分には
@$dom->loadHTML($html);
のようにエラー抑制演算子を付加します。または、
libxml_use_internal_errors(true);
$dom->loadHTML($html);
libxml_clear_errors();
とすることでエラーを表示させないようにも出来ます。
文字化けへの対応
このメソッドは、HTML5形式の文字コード指定には対応していません。
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
<meta charset="utf-8">
非対応の宣言しか存在しないもしくは何も宣言されていない場合に、文字化けが発生したり、XPath式による検索がうまくいかなかったりすることがあります。これを解決するためには、一度マルチバイト文字列全てをHTMLエンティティ形式に変換する必要があります。
@$dom->loadHTML(mb_convert_encoding($html, 'HTML-ENTITIES', 'UTF-8'));
部分HTMLへの対応
デフォルトでは、<!DOCTYPE html ...>および<html><body>...</body></html>といった記述が見つからない場合、勝手に補正されてしまいます。このままでは部分的にHTMLを読み込む際に困りますね。第2引数にオプションを渡せば、この補正を無効化することが出来ます。
@$dom->loadHTML(
mb_convert_encoding($html, 'HTML-ENTITIES', 'UTF-8'),
LIBXML_HTML_NOIMPLIED | LIBXML_HTML_NODEFDTD
);
DOMDocument::loadHTMLFile() メソッド
HTMLファイルを読み込みます。
$dom->loadHTMLFile($url);
この記述は以下とほぼ等価です。
$dom->loadHTML(file_get_contents($url));
Warningへの対応
こちらの方法ではエラー抑制演算子を付けるのが理想です。HTTPリクエストに失敗したときのエラーは libxml_use_internal_errors 関数をコールしていても表示されてしまうからです。
@$dom->loadHTMLFile($url);
文字化けへの対応
こちらの方法では対応出来ません。
- 【要注意】HTTPレスポンスヘッダーで
Content-Type: text/html; charset=utf-8のように指定されていたとしても加味されません!
DOMDocument::saveHTML() メソッド
HTMLを文字列に書き出します。スクレイピングとはあまり関係ありませんが、読み込んだDOMに対して何らかの編集を加え、HTML文字列に戻したいときに使用します。
$html = $dom->saveHTML($node);
$html = $dom->saveHTML();
- 【要注意】
HTML-ENTITIESに変換して読み込んでいる場合、全体を保存する場合でもノード指定が必要になります!
$html = $dom->saveHTML($dom->documentElement);
DOMXPath クラス
DOMDocument::__construct() メソッド
DOMDocument オブジェクトに対して、XPath式を実行するためのインスタンスを生成します。
$xpath = new DOMXPath($dom);
- 【要注意】
DOMXPath生成後にDOMDocument::loadHTML()を実行すると意図した動作になりません!
$dom = new DOMDocument;
@$dom->loadHTML($html);
$xpath = new DOMXPath($dom);
$dom = new DOMDocument;
$xpath = new DOMXPath($dom);
@$dom->loadHTML($html);
DOMXPath::query() メソッド
XPath式にマッチする DOMNode を格納した DOMNodeList を返します。
$baz_list = $xpath->query('foo[1]/bar[2]/baz');
DOMNode オブジェクトによるコンテキストノードの指定
第2引数に DOMNode を指定すると、それをコンテキストノードとして利用することが出来ます。
$foo_1 = $xpath->query('foo[1]')->item(0);
$baz_list = $xpath->query('bar[2]/baz', $foo_1);
- 【要注意】コンテキストノード指定時、先頭の
//と.//は違う意味になります!
$foo_1 = $xpath->query('foo[1]')->item(0);
$baz_list = $xpath->query('//baz', $foo_1);
$foo_1 = $xpath->query('foo[1]')->item(0);
$baz_list = $xpath->query('.//baz', $foo_1);
XPath組み込み関数の利用
-
[]内での条件指定時に関数を利用することが出来ます。 - **結果として返されるノードを関数で加工することは出来ません。
**これが可能になるのは次に紹介するDOMXPath::evaluate()メソッドです。
DOMXPath::evaluate() メソッド
DOMXPath::query() メソッドと非常に似ていますが、こちらは結果として返されるノードに対して関数を使うことが出来ます。
DOMNode オブジェクトによるコンテキストノードの指定
DOMXPath::query() メソッドと同様です。
XPath組み込み関数の利用
-
[]内での条件指定時に関数を利用することが出来ます。 - **結果として返されるノードを関数で加工することが出来ます。**以下の2つは等価です。
$node = $xpath->query('/foo/bar/baz[1]')->item(0);
$value = $node !== null ? $node->value : '';
$value = $xpath->evaluate('string(/foo/bar/baz)');
- **【要注意】対象のノードが複数あるときは、最初の1つしか処理されません!**以下の2つは等価です。
$value = $xpath->evaluate('string(/foo[1]/bar[1]/baz[1])');
$value = $xpath->evaluate('string(/foo/bar/baz)');
基本的な流れ (実装編)
ここまで書いてきたことを踏まえて、最初のQiitaに対するスクレイピングを実装してみます。
$dom = new DOMDocument;
@$dom->loadHTMLFile('http://qiita.com/mpyw');
$xpath = new DOMXPath($dom);
$entries = [];
foreach ($xpath->query('//div[@class="span7"]/section/article/div') as $node) {
$tags = [];
foreach ($xpath->query('.//li[@class="tag-label"]/a', $node) as $tag_node) {
$tags[] = $tag_node->nodeValue;
}
$entries[] = [
'title' => $xpath->evaluate('string(h1/a)', $node),
'url' => $xpath->evaluate('concat("http://qiita.com",h1/a/@href)', $node),
'tags' => $tags,
'date' => $xpath->evaluate('string(.//li[@class="time"]/a)', $node),
'stock' => $xpath->evaluate('normalize-space(.//li[@class="stock"])', $node),
'comment' => $xpath->evaluate('normalize-space(.//li[@class="comment"])', $node),
];
}
var_dump($entries);
$dom = new DOMDocument;
@$dom->loadHTMLFile('http://qiita.com/mpyw');
$xpath = new DOMXPath($dom);
$entries = array_map(
function ($node) use ($xpath) {
return [
'title' => $xpath->evaluate('string(h1/a)', $node),
'url' => $xpath->evaluate('concat("http://qiita.com",h1/a/@href)', $node),
'tags' => array_map(
function ($node) {
return $node->nodeValue;
},
iterator_to_array($xpath->query('.//li[@class="tag-label"]/a', $node))
),
'date' => $xpath->evaluate('string(.//li[@class="time"]/a)', $node),
'stock' => $xpath->evaluate('normalize-space(.//li[@class="stock"])', $node),
'comment' => $xpath->evaluate('normalize-space(.//li[@class="comment"])', $node),
];
},
iterator_to_array($xpath->query('//div[@class="span7"]/section/article/div'))
);
var_dump($entries);
応用
ログインが必要なサイトに対するスクレイピング
認証処理にJavaScriptが使われていない場合
cURL関数群の出番です。以下のように CURLOPT_COOKIEJAR として空の値を指定すれば、メモリ上で自動的にCookieが管理されるようになります。
$ch = curl_init();
curl_setopt_array($ch, [
CURLOPT_RETURNTRANSFER => true,
CURLOPT_FOLLOWLOCATION => true,
CURLOPT_SSL_VERIFYPEER => false,
CURLOPT_COOKIEJAR => '', // こ↑こ↓
]);
あとはログイン処理を書くだけです…
認証処理にJavaScriptが使われている場合
Selenium-WebdriverのPHP向けの実装としてFacebookより php-webdriver というパッケージが提供されており、これを用いてブラウザの挙動をエミュレート出来ます。
- GitHub facebook/php-webdriver/example.php
- Selenium2.0でUIテスト(1) -まずはPHPでやってみる-
- Selenium-WebDriver API Commands and Operations
ドキュメントをみてみた感じ、XPath式もサポートされているようです。
相対パスを絶対URLに変換する
<a href="../baz.html">baz</a>
↓
<a href="http://www.example.com/foo/baz.html">baz</a>
このように直したいときは,最初に下処理を入れておきます。**base要素**に対応しています。
$url = 'http://www.example.com/foo/bar';
$base = preg_replace(
'@\Ahttps?://[^/]++(?:\K|(?:/++[^/]*+)*\K(?:/++[^/]*+))\z@i',
'',
$xpath->evaluate('string(//base/@href)') ?: $url
);
$nodes = $xpath->query('
//*[name()="base" or name()="html"][1]
/following::*
/@*[name()="src" or name()="href"]
[not(starts-with(name(), "http:"))]
[not(starts-with(name(), "https:"))]
[not(starts-with(name(), "data:"))]
');
foreach ($nodes as $node) {
$parts = [];
foreach (preg_split('@/++@', $node->nodeValue, -1, PREG_SPLIT_NO_EMPTY) as $v) {
if ($v === '..') {
array_pop($parts);
} elseif ($v !== '.') {
$parts[] = $v;
}
}
$node->nodeValue = implode('/', array_merge([$base], $parts));
}