導入
htmlspecialchars 関数や htmlentities 関数で使用可能なフラグとして以下のものがありますが、詳しい違いを考慮したことが無かったので、ここで検証してみることにします。
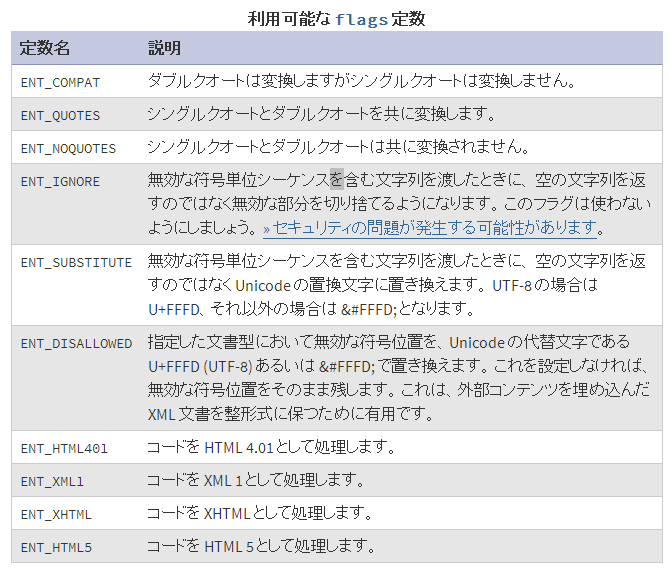
検証
定数を2進数表示してみる
$types = [
'ENT_COMPAT', 'ENT_QUOTES', 'ENT_NOQUOTES',
'ENT_IGNORE', 'ENT_SUBSTITUTE', 'ENT_DISALLOWED',
'ENT_HTML401', 'ENT_XML1', 'ENT_XHTML', 'ENT_HTML5',
];
foreach ($types as $type) {
printf('% 14s: %08b' . PHP_EOL, $type, constant($type));
}
ENT_COMPAT: 00000010
ENT_QUOTES: 00000011
ENT_NOQUOTES: 00000000
ENT_IGNORE: 00000100
ENT_SUBSTITUTE: 00001000
ENT_DISALLOWED: 10000000
ENT_HTML401: 00000000
ENT_XML1: 00010000
ENT_XHTML: 00100000
ENT_HTML5: 00110000
この結果から各桁に関して以下のことが推測できます。マニュアルの分かりにくい部分は読み替えています。
- 処理対象に
'を含める - 処理対象に
"を含める (デフォルトで有効) - 指定 文字コード として無効なシーケンスを削除する
- 指定 文字コード として無効なシーケンスを同じバイト長の
�で構成される文字列に置換する - 文書タイプ指定 下位ビット
- 文書タイプ指定 上位ビット
- 未実装
- 指定 文書タイプ として無効なシーケンスを同じバイト長の
�で構成される文字列に置換する
文書タイプ指定
| 2進数値 | 文書タイプ |
|---|---|
00(デフォルト) |
HTML |
01 |
XML |
10 |
XHTML |
11 |
HTML5 |
' " の扱いに関して
基本動作は ENT_COMPAT ENT_QUOTES ENT_NOQUOTES に関連するマニュアルの記載通りに自明です。
function test($string, $type) {
return htmlspecialchars($string, ENT_HTML401 | constant($type), 'UTF-8');
}
foreach (['ENT_COMPAT', 'ENT_QUOTES', 'ENT_NOQUOTES'] as $type) {
printf('% 12s: %s' . PHP_EOL, $type, test('"\'', $type));
}
ENT_COMPAT: "'
ENT_QUOTES: "'
ENT_NOQUOTES: "'
関連する関数のデフォルトのフラグは ENT_COMPAT | ENT_HTML401 となっていますが、ビット演算の性質上、文書タイプのみを指定したときには ENT_NOQUOTES が適用されてしまうことに注意してください。
echo htmlspecialchars('"\'', ENT_HTML401, 'UTF-8');
"'
もう1点気になるのは、 ' のみを対象とするフラグが存在しないことです。なので、実際に2進数 01 を直接渡したときにどのような結果になるのかを検証してみました。
echo htmlspecialchars('"\'', 1, 'UTF-8');
"'
定数としては定義されていませんが、期待した通りの結果が得られました。
文書タイプに関して
get_html_translation_table 関数の返り値を比較することで検証を試みましたが、出力結果が長すぎるので要点だけ記載します。文字コードによって結果が異なるようなので、ここでは UTF-8 だけを対象に考えます。
共通
< > & " はそれぞれ < > & " と対応する
htmlspecialchars 関数 / htmlspecialchars_decode 関数
ENT_XML1 |
ENT_HTML401ENT_XHTML
|
ENT_HTML5 |
|
|---|---|---|---|
' との対応 |
' |
' |
' |
| ギリシャ文字など | × | × | × |
| タブ・改行など | × | × | × |
htmlentities 関数 / html_entity_decode 関数
ENT_XML1 |
ENT_HTML401ENT_XHTML
|
ENT_HTML5 |
|
|---|---|---|---|
' との対応 |
' |
' |
' |
| ギリシャ文字など | × | ○ | ○ |
| タブ・改行など | × | × | ○ |
XHTMLはHTMLともXMLとも考えられますが、互換性を考慮してHTML寄りの実装になっていると思われます。しかし
header('Content-Type: application/xhtml+xml; charset=utf-8');
としてヘッダーを直接送出する場合、そもそも互換性の無いブラウザは正常にページを表示することが出来ないので、XMLとして扱わせておく方が妥当な気はします。
【追記】
'をデコードしたいときは,ENT_HTML401以外の文書タイプをENT_QUOTESとともに使う必要がある.
文字コードとして無効なシーケンスの扱い
ENT_IGNORE と ENT_SUBSTITUTE は互いに排反的な機能に対応するフラグですが、 php_escape_html_entities_ex 関数の実装によれば両方のフラグを設定した場合は ENT_IGNORE の方が優先されるようです。
ENT_IGNORE 指定
無効なシーケンスは 削除 されます。しかし、以下のようなコードを書いてしまうとかえってXSS脆弱性を作り込む要因となってしまいます。
そもそも 「XSSの攻撃手法いろいろ」 を見ても分かる通り、このフィルタリング処理自体が不適切なのは否めませんが…リスクを少しでも減らそうという観点から見れば、このフラグは使用すべきではないと言えるでしょう。
$_POST['url'] = "java\xffscript:alert('XSS')"; // リクエストが来たと仮定
if (stripos($_POST['url'], 'javascript:') !== 0) {
$url = htmlspecialchars($_POST['url'], ENT_HTML401 | ENT_IGNORE, 'UTF-8');
echo '<a href="' . $url . '">URL</a>';
}
<a href="javascript:alert('XSS')">URL</a>
ENT_SUBSTITUTE 指定
無効なシーケンスは同じバイト長の � で構成される文字列に置換 されます。 ENT_IGNORE のようなリスクが発生したりすることはありません。
$_POST['url'] = "java\xffscript:alert('XSS')"; // リクエストが来たと仮定
if (stripos($_POST['url'], 'javascript:') !== 0) {
$url = htmlspecialchars($_POST['url'], ENT_HTML401 | ENT_SUBSTITUTE, 'UTF-8');
echo '<a href="' . $url . '">URL</a>';
}
<a href="java�script:alert('XSS')">URL</a>
無指定
無効なシーケンスが検知された時点で返り値は 空文字列 になります。 ENT_IGNORE のようなリスクが発生したりすることはありません。
$_POST['url'] = "java\xffscript:alert('XSS')"; // リクエストが来たと仮定
if (stripos($_POST['url'], 'javascript:') !== 0) {
$url = htmlspecialchars($_POST['url'], ENT_HTML401, 'UTF-8');
echo '<a href="' . $url . '">URL</a>';
}
<a href="">URL</a>
文書タイプとして無効なシーケンスの扱い
セキュリティを考慮するのだけが目的であれば、あまりこの処理は重要ではないかもしれません。
ENT_DISALLOWED 指定
無効なシーケンスは同じ長さの � で構成される文字列に置換 されます。ENT_IGNORE のようなリスクが発生したりすることはありません。
文書タイプとして有効かどうかは unicode_cp_is_allowed 関数の実装に従って判定されます。文書タイプによって差がある一例として、 非文字 と呼ばれる を用いた際の結果を示します。HTML5では非文字の使用は許可されていません。
function test($string, $type) {
return htmlspecialchars($string, ENT_DISALLOWED | constant($type), 'UTF-8');
}
foreach (['ENT_HTML401', 'ENT_HTML5'] as $type) {
printf('% 11s: %s' . PHP_EOL, $type, test("\xef\xb7\x90", $type));
}
ENT_HTML401:
ENT_HTML5: �
無指定
何も影響を受けません。
function test($string, $type) {
return htmlspecialchars($string, constant($type), 'UTF-8');
}
foreach (['ENT_HTML401', 'ENT_HTML5'] as $type) {
printf('% 11s: %s' . PHP_EOL, $type, test("\xef\xb7\x90", $type));
}
ENT_HTML401:
ENT_HTML5:
まとめ
htmlspecialchars 関数のラッパー関数の実装例を紹介します。
function h($str) {
return htmlspecialchars($str, ENT_QUOTES, 'UTF-8');
}
function h($str) {
return htmlspecialchars($str, ENT_QUOTES | ENT_SUBSTITUTE, 'UTF-8');
}
function h($str) {
return htmlspecialchars($str, ENT_QUOTES | ENT_XML1 | ENT_DISALLOWED, 'UTF-8');
}
「不正なリクエスト」としているものに関しては…意図的に不正な文字コードが第三者によって渡される場合に限らず、不意に期待していない文字コードが渡されてしまうことも含まれます。例えば、Windows環境ではOSによって渡されるエラーメッセージが全て SJIS-win です。 PDO クラスによって自動的にスローされる例外や fsockopen 関数で発生するエラーのメッセージをキャプチャしたものがこれに該当する可能性があります。そういったときに 何も表示しない のではなく 文字化けしていることを知らせてくれる ようになる、という意味では有用な処理でしょう。