はじめに
本記事では、2021年のアップデートで追加されたAmazon BraketのHybrid Jobsという機能と2022年のアップデートで追加されたEmbedded SimulatorsであるPennyLane Lightningというシミュレータについて調べたことをまとめました。
また、私自身が量子コンピュータの学習歴が短い素人のため、間違っている点やよろしくない表現がありましたら、ご指摘をよろしくお願いいたします。
対象者
・Amazon Braketに興味がある方。
・Amazon BraketでHybrid JobsやEmbedded Simulators、PennyLane Lightningについて興味がある方。
・量子コンピューティングSDKを用いて、量子機械学習や量子化学計算を行いたいと考えている方
Hybrid Jobs
Hybrid Jobsとは古典・量子ハイブリットアルゴリズムを効率的に実行するフルマネージドサービスです。(ハイブリットアルゴリズムについては後述します。)
特徴として、
- ジョブ単位における量子プロセッサ(Quantum Processing Unit: QPU)への優先的なアクセス
- ジョブインスタンス・ジョブコンテナの生成
が挙げられます。以下に概念図を示します。
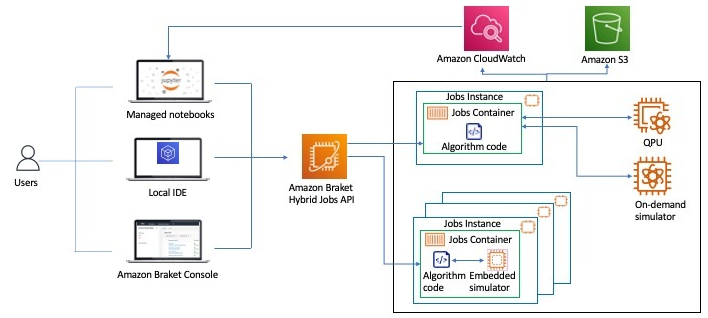
参考:「Accelerate hybrid quantum-classical algorithms on Amazon Braket using embedded simulators from Xanadu’s PennyLane featuring NVIDIA cuQuantum」
いきなり全体図を見ても少しわからないかもしれませんね。
(少なくとも素人の私にとってはわかりませんでした。。。)
そのため、一旦先に各特徴を見ていきましょう。
1. QPUへの優先的なアクセス
Braketにおいて、QPUへのアクセスはQPUタスクごとに行われています。
つまり、以下のコードのdevice.runが実行されるたびにQPUへアクセスします。
from braket.aws import AwsDevice
device = AwsDevice(量子デバイスのARN)
task = device.run(bell_circuit, shots=ショット数)
QPUの実行待ち行列
QPUにタスクが投げられると、タスクはQPUの実行待ち行列に並びます。QPUは他ユーザと共有されているため、待ち行列には他ユーザのQPUタスクも含まれています。そのため、QPUへのアクセスの混雑度合いがQPUのタスク処理待ち時間、ひいてはQPUタスクの実行時間に大きな影響を与えています。
特に、ハイブリットアルゴリズムは、古典コンピュータのCPUで処理するCPUタスクとQPUタスクを何度も往復するアルゴリズムであるため、QPUタスクの待ち行列に何度も並ぶ必要があり、これが実行時間が低下する要因となっていました。
Hybrid Jobsにおける優先待ち行列
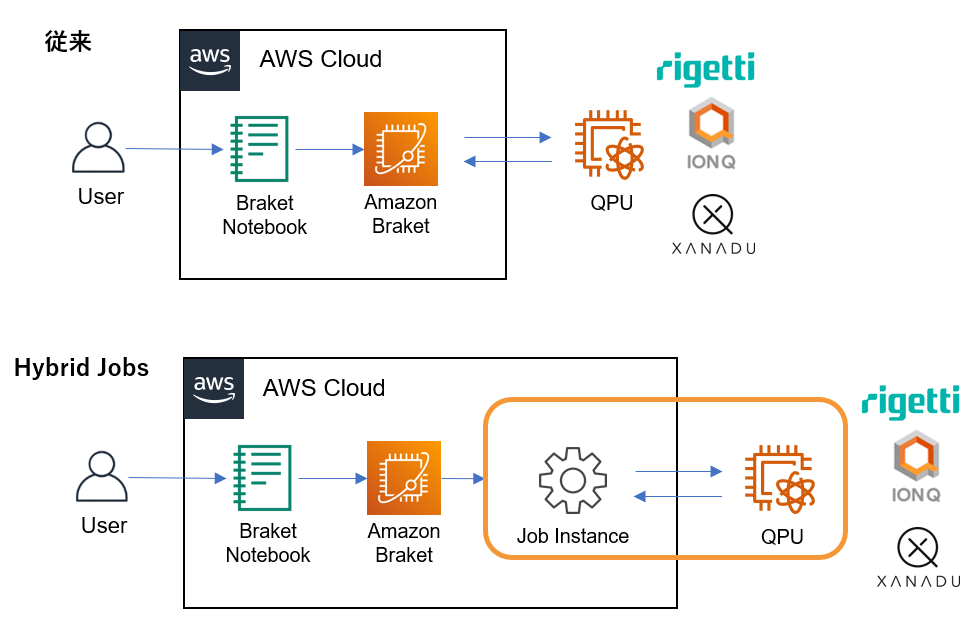
しかし、Hybrid Jobsではアルゴリズム全体を一つのジョブとして一括管理し、QPUに同一ジョブ内のQPUタスクを優先的に処理させることで、タスク処理待ち時間を短縮することが可能になりました。
まず、計算したいアルゴリズムをアルゴリズムスクリプト、ジョブの実行や結果の出力操作をジョブスクリプトに分けて記述します。次に、ユーザがジョブスクリプトを実行すると、アルゴリズムスクリプト内で発生する全タスクは一つのジョブとして管理されます。そして、各タスクはQPUにおいて、ジョブというフラグで区別されることによって、QPUの優先待ち行列に並ぶことができるようになりました。その結果、タスク処理待ち時間の短縮が可能になりました。
ざっくりいうと遊園地のアトラクションに並ぶ際にファストパスを使えるようになったイメージですね笑
従来とHybrid Jobsを比較したイメージ図を以下に示します。
2. インスタンス・コンテナの生成
Hybrid Jobsでは、従来のようにBraket NotebookからQPUやシミュレータにタスクを直接投げるのではなく、インスタンスとコンテナを起動し、コンテナ内からタスクを投げます。
そのため、インスタンスであるEC2およびコンテナのイメージファイルを指定する必要があります。
ジョブインスタンスの指定
ジョブインスタンスを指定する上で、新たにEmbedded Simulatorsが指定可能になりました。
Embedded Simulatorsは、ジョブインスタンス上で量子回路をシミュレートする組み込みシミュレータです。
Embedded SimulatorsにはPennyLane社の高性能シミュレータである、
・lightning.qubi (CPUベースのシミュレータ)
・lightning.gpu (GPUベースのシミュレータ)
があります。
特に、GPUベースのlightning.gpuを使用するには、以下のGPUインスタンスを選択する必要があります。
・p3.2xlarge
・p3.8xlarge
・p3.16xlarge
ジョブコンテナのイメージファイルの指定
ジョブコンテナを指定する上で、新たにcuQuantumが使用可能になりました。
cuQuantumは、NVIDIA社の量子回路シミュレーションを加速させるライブラリ群です。
cuQunantumを使用するには、PyTorchとTensorFlowのイメージファイルを選択する必要があります。
従来手法との比較
Hybrid Jobsと従来手法の比較を以下の表に示します。
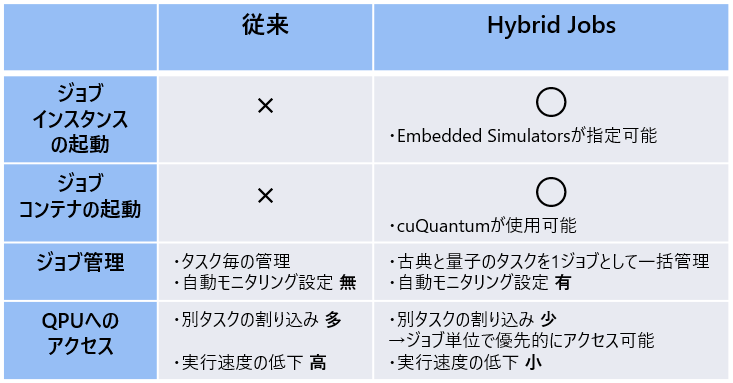
Hybrid Jobsの特徴およびメリットをまとめると、

となります。
古典・量子ハイブリッドアルゴリズム
古典・量子ハイブリッドアルゴリズムとは、アルゴリズムの一部を量子コンピュータで計算し、得られた出力を古典コンピュータによって逐次調整することで、所望の動作を実行するアルゴリズムです。量子回路の形を固定したまま、コスト関数が最小化となるように変分パラメータとよばれるパラメータを古典コンピュータで調整する点が最大の特徴です。量子コンピュータの使用範囲を限定的にすることで、量子ビット数と量子ゲート数を削減し、ノイズの影響を抑えることができます。
ハイブリットアルゴリズムの必要性
現在の量子コンピュータは、量子誤り訂正を行うことができないNISQデバイスであるため、計算途中で発生するノイズの影響を大きく受けてしまいます。そこで、ノイズの影響を抑えるために、少数の量子ビット数かつ少数の量子ゲート数で実行可能なアルゴリズムとして、ハイブリッドアルゴリズムに注目が集まっているのです。
ハイブリットアルゴリズムの応用分野
主な応用分野は、
・量子化学計算
・量子機械学習
となります。
特に量子計算化学では、ハイブリットアルゴリズム中でも変分量子固有値ソルバー(Variational Quantum Eigensolver: VQE)を用いた応用が検討されています。VQEを用いた問題は、IBM Quantum ChallengeやQHackなど、様々なハッカソンで出題されています。
IBM Quantum Challengeで取り扱われたVQE応用例をまとめる
PennyLane Lightning
PennyLane Lightningとは、Xanadu社が提供するEmbedded Simulatorsです。
様々な機能が搭載されており、ハイブリットアルゴリズムの高速化が可能となっています。
下記の発表を読むと、
・ハイブリットアルゴリズムの収束までに必要な回路の実行回数を約90%削減し、実行時間を大幅に短縮した
ということがわかります。実行回数を90%も削減したのはすごいですね。。。
Today, we are excited to announce that Amazon Braket Hybrid Jobs now supports five high-performance embedded circuit simulators, which are available in the same container as your application code. As part of this launch, we support the high-performance lightning.qubit and lightning.gpu simulators from PennyLane, the latter of which is powered by the NVIDIA cuQuantum SDK, which comes with state-of-the-art features such as native GPU support for adjoint differentiation. These methods have significantly lower memory usage and can reduce the number of circuit executions required for your variational algorithm to converge by as much as 90%. Fewer circuit executions mean fewer round-trips between your algorithm code and the simulator, hence faster runtimes.
Braketで提供される量子シミュレータ
ここで、Braketで提供されるシミュレータを整理してみました。

特に、lightning.gpuでは、cuQuantumライブラリが使用可能です。cuQuantumを併用することで、従来のシミュレーションと比較して劇的な高速化が可能になりました。
PennyLane Lightning.gpuとcuQuantumの併用
lightning.gpuはcuQuantum SDKとの併用によって、量子化学計算・量子機械学習などの計算量の多いシミュレーションを、CPUシミュレーションと比較して桁違いに高速化することができます。
具体的には、以下の特徴があります。
・cuQuantum SDKのcuStateVecライブラリ
・GPU上の量子回路の状態ベクトルシミュレータの高速化
・深い量子回路や高度に絡み合った量子回路の柔軟なシミュレーションが可能
・量子ビット数の増加
・大規模回路のシミュレーションの高速化により、シミュレーション可能な量子ビット数が増加
・変分パラメータの最適化
・勾配計算手法であるAdjoint法では、従来のパラメータシフト法と比較して、勾配評価を大幅に高速化
これらの特徴は、波動関数の中間状態に対する状態取得に依存しており、Ondemand SimulatorsやQPUでは未対応となっています。
このように、lightning.gpuをcuQuantumと併用することで、計算の高速化と計算費用の削減が可能になります。
以下に、量子シミュレータとしてCPUとGPUを用いた際の比較図を示します。
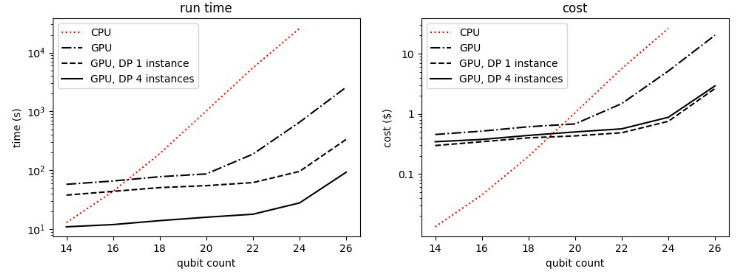
参考:「Accelerate hybrid quantum-classical algorithms on Amazon Braket using embedded simulators from Xanadu’s PennyLane featuring NVIDIA cuQuantum」
左図の縦軸は時間のlogスケールとなっているため、GPUでは大幅に高速化されていることが分かります。特に、量子ビット数が増加するほど、高速化の影響が大きく出ています。さらに、GPUを並列化することでさらなる高速化を実現しています。
右図では、GPUの計算の高速化に伴い、計算費用が抑えられていることが分かります。ただし、GPUでは初期コストが高く、一定以上の量子ビット数でないとコスト削減効果がないようです。
上記の図から、CPUシミュレータは小規模回路、GPUシミュレータは大規模回路に適しているということが分かります。
ちなみに、CPUを並列化してもGPUのほうが速いことを示す図も確認されました。
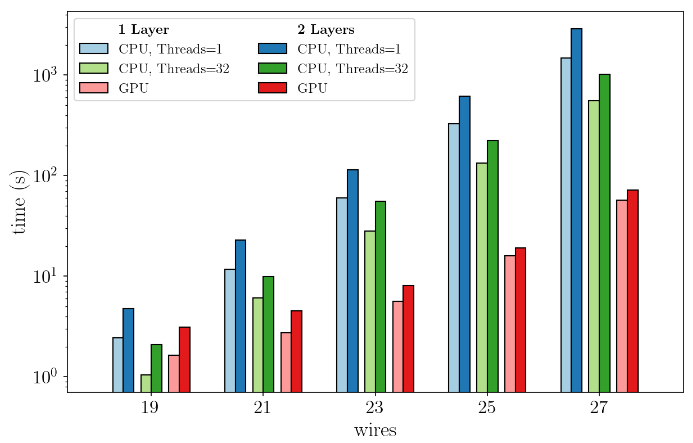
参考:「Lightning-fast simulations with PennyLane and the NVIDIA cuQuantum SDK」
他SDKとの比較
BraketのHybrid Jobsと同様の機能は他社のSDKにも実装されているのでしょうか。
気になったため調べてみました。
PennyLane SDK
Xanadu社のSDKであるPennyLaneでは、Quantum node(QNode)という概念に相当します。
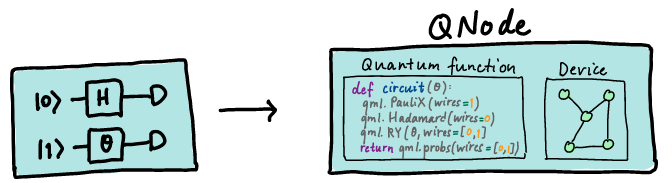
参考:「Quantum Node」
PennyLaneは量子機械学習に特化したSDKのため、古典コンピュータとの連携が前提となるアルゴリズムの実装が初期段階から想定されていたようです。そのため、初期段階からQNodeという概念を導入していた模様。また、PennyLaneは機能が豊富であり、Qiskit SDKとの連携によってQiskitのグラフィカルな回路図の描画も可能であるため、PennyLaneを推す方も多いようです。(私もQHackでお世話になりました。)
Braket notebookにもプリインストールされているため、
「PennyLaneが書ければそれでいい」(引用元:量子プログラミング用SDK PennyLane を推す)
ということかもしれませんね笑
Qiskit SDK
IBM社のSDKであるQiskitでは、Oiskit Runtime Sessionという概念に相当します。
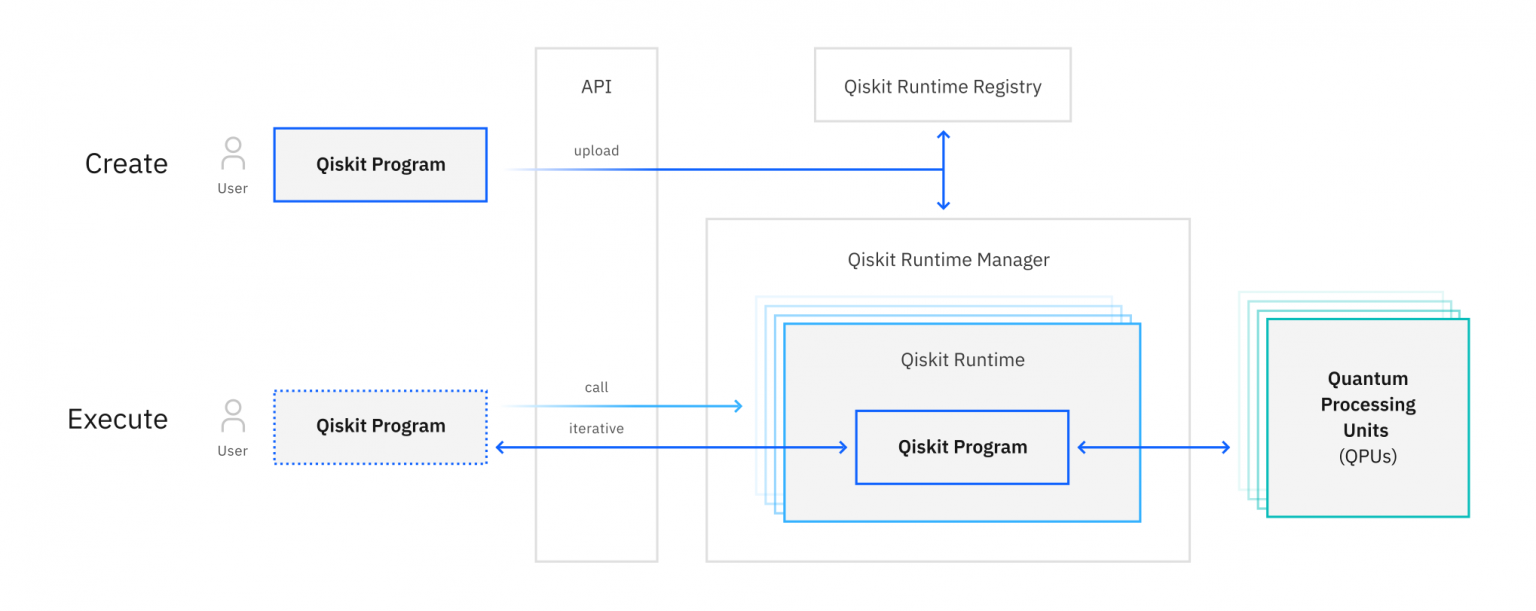
参考:「量子システム開発の新たな展開、IBMがQiskit Runtimeを発表 ~古典コンピュータとのI/O回数を削減し、処理時間を短縮」

このようにNISQ時代では、ハイブリットアルゴリズムのようなノイズを考慮したアルゴリズムの効率的な計算手法が求められており、各社のSDKでも実装されていることがわかりました。
最後に
ご質問やご指摘等ありましたら、コメントまでお願いいたします。
参考
・Accelerate hybrid quantum-classical algorithms on Amazon Braket using embedded simulators from Xanadu’s PennyLane featuring NVIDIA cuQuantum
・Amazon Braket Hybrid Jobs のご紹介 – 量子/古典ハイブリッドアルゴリズムのワークロードを設定およびモニタリングし、効率的に実行する
・変分量子アルゴリズムと量子機械学習
・IBM Quantum Challengeで取り扱われたVQE応用例をまとめる
・Lightning-fast simulations with PennyLane and the NVIDIA cuQuantum SDK
・Quantum Node
・量子プログラミング用SDK PennyLane を推す)
・量子システム開発の新たな展開、IBMがQiskit Runtimeを発表 ~古典コンピュータとのI/O回数を削減し、処理時間を短縮
・Estimator primitive 入門