こんにちは。
独学ですが、pythonと統計数学を勉強しています。
今回の記事はJupyter Notebookを使って、
統計検定2級の勉強目的をこめて、
出題範囲であるローレンツ曲線で、
都道府県別の人口の偏りを調査しました。
都道府県別の人口については、
以下のサイトを参考にCSVのデータを作成しました。
2018年10月時点のものです。
環境
Windows 7
anaconda 2018.12
python 3.7.1
調査結果
調査結果です。
Jupyter Notebookから画面出力したキャプチャを少し加工しています。
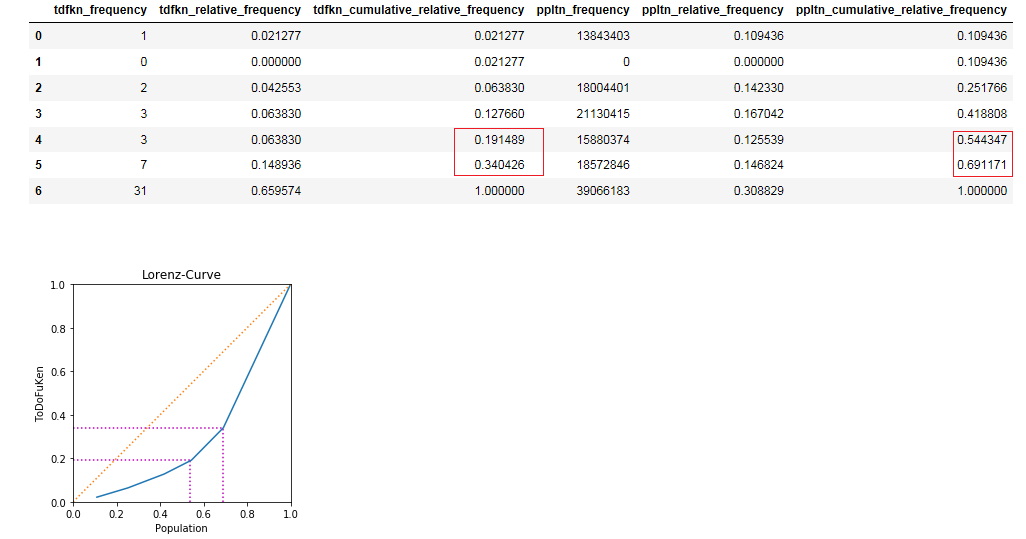
細かい数字がたくさん並んでいますね。
注目するべき点は、
都道府県別の累積相対度数(tdfkn_cumulative_relative_frequency)
人口の累積相対度数(ppltn_cumulative_relative_frequency)
の部分です。
都道府県別の累積相対度数: 0.19...
人口の累積相対度数: 0.54...
また、
都道府県別の累積相対度数: 0.34...
人口の累積相対度数: 0.69...
となっています。
これはどういうことかというと、
約2割の都道府県に日本全体の人口の5割強が住んでいて、
約3割の都道府県に日本全体の人口の約7割が住んでいる。
ということを示しています。
また、ローレンツ曲線は
全く偏りがなく完全に均等配分されている場合には、
y = xのグラフ(完全平等線)を描きます。
グラフでは完全平等線に対して、下方へのズレが見られます。
これらのことから、
都市部へ人口が大きく偏っていることが分かりますね。
調査方法
①まず、スタージェスの公式を使って階級の数を求めました。
階級の数 = 1 + \log_2 n \\
(n=データ数)
n=47(都道府県の数)としたとき、
計算結果は6.55...となります。
今回は
階級の数:7
階級幅 :2,000,000
としています。
②次に、各階級ごとの都道府県数、人口の度数を集計。
そこから、それぞれの相対度数、累積相対度数を算出します。
③そして、
X軸: 人口の累積相対度数
Y軸: 都道府県数の累積相対度数
にとったグラフがローレンツ曲線になります。
ソースコード
以下は、今回調査用に使った全ソースコードになります。
%matplotlib inline
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import math
#定数
LF = '\n'
CSV_FILE = 'PopulationByToDoGFuKen.csv'
ENCODING_METHOD = 'cp932'
def read_csv():
"""
csvの読込
"""
output = pd.read_csv(CSV_FILE, encoding=ENCODING_METHOD)
#出力
print('★加工元CSVファイル★')
print(str(output) + LF + LF)
return output
def format_df(df):
"""
DataFrameの加工
"""
#度数の集計用のbool DataFrame
df_1400 = df.query('12000000 <= population')
df_1200 = df.query('10000000 <= population < 12000000')
df_1000 = df.query('8000000 <= population < 10000000')
df_0800 = df.query('6000000 <= population < 8000000')
df_0600 = df.query('4000000 <= population < 6000000')
df_0400 = df.query('2000000 <= population < 4000000')
df_0200 = df.query('population < 2000000')
#都道府県の度数のSeries
tdfkn_frequency = pd.Series([
len(df_1400.index)
, len(df_1200.index)
, len(df_1000.index)
, len(df_0800.index)
, len(df_0600.index)
, len(df_0400.index)
, len(df_0200.index)])
#人口の度数のSeries
ppltn_frequency = pd.Series([
df_1400['population'].sum()
, df_1200['population'].sum()
, df_1000['population'].sum()
, df_0800['population'].sum()
, df_0600['population'].sum()
, df_0400['population'].sum()
, df_0200['population'].sum()])
#相対度数のSeries
tdfkn_relative_frequency = tdfkn_frequency / tdfkn_frequency.sum()
ppltn_relative_frequency = ppltn_frequency / df['population'].sum()
#float型へ変換
tdfkn_relative_frequency = tdfkn_relative_frequency.astype(np.float64)
ppltn_relative_frequency = ppltn_relative_frequency.astype(np.float64)
#累積相対度数のSeries作成
tdfkn_cumulative_relative_frequency = cumulative(tdfkn_relative_frequency)
ppltn_cumulative_relative_frequency = cumulative(ppltn_relative_frequency)
#DataFrame生成
new_df = pd.DataFrame({
'tdfkn_frequency': tdfkn_frequency
, 'tdfkn_relative_frequency': tdfkn_relative_frequency
, 'tdfkn_cumulative_relative_frequency': tdfkn_cumulative_relative_frequency
, 'ppltn_frequency': ppltn_frequency
, 'ppltn_relative_frequency': ppltn_relative_frequency
, 'ppltn_cumulative_relative_frequency': ppltn_cumulative_relative_frequency
})
#出力
print('★加工後DataFrame★')
display(new_df)
print(LF)
return new_df
def cumulative(srs_relative_frequency):
"""
累積相対度数Seriesの生成
"""
crf = 0
#累積相対度数 列用のSeries
srs_cumulative_relative_frequency = pd.Series([0, 0, 0, 0, 0, 0, 0]).astype(np.float64)
#累積相対度数の集計
for cnt, row in srs_relative_frequency.iteritems():
crf += srs_relative_frequency[cnt]
srs_cumulative_relative_frequency[cnt] = crf
return srs_cumulative_relative_frequency
def sturges(input):
"""
スタージェスの公式
"""
output = 1 + math.log2(input)
#出力
print('★階級幅の算出★' )
print(str(output) + LF)
return output
def show_lorenz(df):
"""
ローレンツ曲線の表示
"""
fig = plt.figure()
ax1 = fig.add_subplot(1,1,1)
#X軸: 人口の累積相対度数
#Y軸: 都道府県数の累積相対度数
ax1.plot(df['ppltn_cumulative_relative_frequency']
, df['tdfkn_cumulative_relative_frequency'])
#完全平等線
x = np.linspace(0, 1, 10)
y = x
ax1.plot(x, y, linestyle=":")
#垂直、平行線
plt.hlines(0.19, 0, 0.54, "m", linestyle=":")
plt.vlines(0.54, 0, 0.19, "m", linestyle=":")
plt.hlines(0.34, 0, 0.69, "m", linestyle=":")
plt.vlines(0.69, 0, 0.34, "m", linestyle=":")
#グラフの範囲 設定
ax1.set_xlim(0, 1)
ax1.set_ylim(0, 1)
#縦横比 1:1
plt.axes().set_aspect('equal')
plt.title("Lorenz-Curve")
plt.xlabel("Population")
plt.ylabel("ToDoFuKen")
plt.show()
plt.savefig('PopulationByToDoFuKen.png')
def main():
"""
メイン関数
"""
#csv読み込み
df = read_csv()
#階級幅をスタージェスの公式より算出
class_width = sturges(len(df.index))
#DataFrame加工
formated_df = format_df(df)
#ローレンツ曲線の表示
show_lorenz(formated_df)
return
#エントリポイント
main()