RoBERTaとDeBERTaはKaggleのNLPコンペで良くお世話になっているものの、違いを聞かれてうまく答えられなかったので整理してみました。ついでにBERTも。
(とは言いつつ、実際によく使うのはDeBERTa V3の方ですが、、、)
結論
結論から書くと違いは以下の通りです。
BERT -> RoBERTa
- より大きいバッチサイズ、データかつ多くの回数で事前学習した
- Next Sentence Predictionをなくした
- Maskのパターンを動的に変えた
BERT/RoBERTa -> DeBERTa
- Disentangled Attention Mechanismを導入し、単語(content)と相対位置(Position)を分離して扱う
- Enhanced Mask Decoderにより、MLM時の相対位置を用いることの不都合を解消
※ファインチューニングの際にモデルの汎化性能を高めるScale-invariant-Fine-Tuning (SiFT)も提案されています。SiFTはSuperGLUEタスクのDeBERTa1.5Bにのみ適用されており、包括的な研究はfuture workと述べられています(この記事では詳細は省きます)。
以降でBERT、RoBERTa、DeBERTaを順に掘り下げます。特に明記していない場合、それぞれの論文から引用しています。
BERTの概要
まずは派生元のBERTについて簡単にまとめます。
BERT(Bidirectional Encoder Representations from Transormers)はTransformerベースの深層学習モデルです。モデル構造としては、TransformerのEncoderを積み重ねた形になっています。
BERTへ入力される文章は、まずサブワードによるトークン化が適用されます。サブワードとは、単語よりも細かい単位で分割されたもので、例えば「running」をサブワードに分割すると、「run」と「##ning」に分割されます(詳細は、文字単位・単語単位での分割との比較がわかりやすいです)。
TransformerのEncoderへの入力は以下の図のような形式となります。
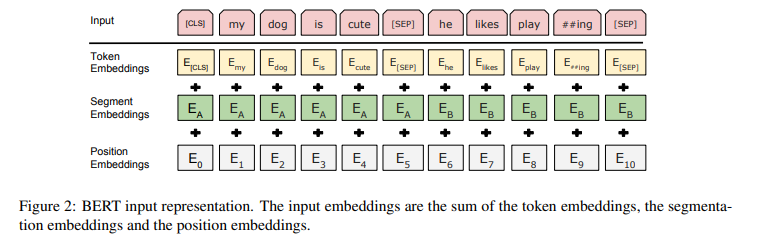
ここで、Segment Embdeddingsは文章同士の区別をつけるために用いられています(my dog ...とhe likes ...は文単位で異なる)。
Position Embeddingsは単語の位置を表現するEmbdeddingです。TransformerのEncoder部分では、トークンが順番に処理されるのではなく同時に処理されるため、トークンの位置情報を考慮することができません。そのため、入力トークンの位置情報を把握するために導入されています。
そして、Token Embeddings、Segment Embdeddings、Position Embeddingsの三つを足し合わせたものをTransformerのEncoderに入力させます。
また、BERTは以下の二つの手法により事前学習が行われています。
- MLM(Masked Language Model)
- NSP(Next Sentence Prediction)
MLMでは、入力をランダムにマスクしその単語を予測することで、前後の文脈を考慮しながら単語の埋め込み表現を獲得することを行っています。また、NSPでは、二つの文が与えられたときに文同士が意味的・論理的に連続しているかを判定するタスクを解いています。これにより、文同士の関係性の理解に繋がります。
RoBERTaの概要
RoBERTa(A Robustly Optimized BERT Pretraining Approach)のモデル構造はBERTと変わりませんが、以下の点で異なります。
- より大きいバッチサイズ、データかつ多くの回数で事前学習する
- Next Sentence Predictionによる事前学習をなくす
- 事前学習時のMaskのパターンを動的に変える
より大きいバッチサイズ、データかつ多くの回数で事前学習する
BERTではバッチサイズ256で100万ステップ学習されていますが、RoBERTaが提案された論文によると、バッチサイズ2000で12万5000ステップ学習するのが最も性能が高いと報告されています。
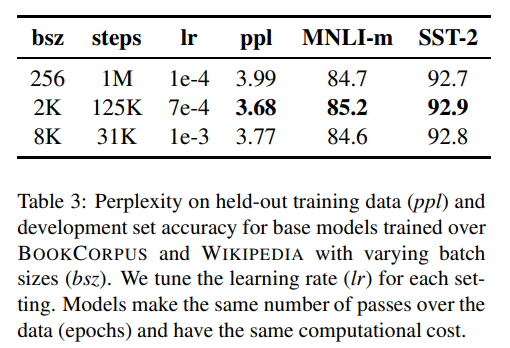
また、160GBを超えるデータセットを使用して学習されていて、長い文章の入力(Raceデータセット)に対しても有効であることも確認されています。
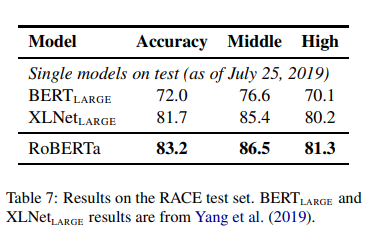
Next Sentence Predictionによる事前学習をなくす
BERTでは、二つの文章ペが連続しているかを解くタスクであるNext Sentence Prediction(NSP)がモデルの訓練で重要な要素だと主張されていた一方で、直近の研究ではNSPの必要性に疑問を呈するものがあったようです。
RoBERTaの論文では、以下の4つのパターンによる実験を通してNSP損失を取り除くことで性能の向上が確認できたと報告されています。
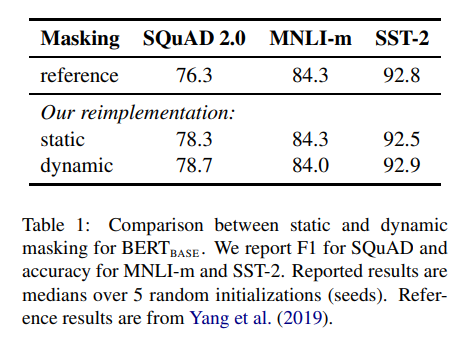
事前学習時のMaskのパターンを動的に変える
BERTではトークンのマスク処理は学習のはじめに生成したものを学習中も継続して使用しています(static)。
一方で、RoBERTaでは動的にマスクを行うDynamic Maskingを用いていて、入力シーケンスをモデルに与えるたびにマスクパターンを生成しています。Dynamic Maskingにより、BERTとほぼ同等または上回る性能を発揮しています。
DeBERTaの概要
一方で、DeBERTa (Decoding-enhanced BERT with disentangled tention) ではBERT/RoBERTのモデルの構造を変更することで、NLPタスクのパフォーマンスを向上させています。
大きな変更点は以下の2つです。
- Disentangled Attention Mechanism
- Enhanced Mask Decoder
Disentangled Attention Mechanism
disentangled attention mechanismは単語ペアのAttentionの重みがその内容だけでなく相対的な位置にも依存するのではという発想のもと考案されました。
例えば、「deep」という単語と「learning」という単語の依存関係は、異なる文で現れるよりも隣り合って現れる方がはるかに強くなると考えられます。
また、BERT(RoBERTa)では、入力層の各単語は、単語(content)の埋め込みと位置(position)の埋め込みの和をとったベクトルで表されていました。
一方で、DeBERTaの論文中では、単語埋め込みと位置埋め込みを一緒に追加することは、位置が単語の信号と混合しすぎるためパフォーマンスの低下につながるのではと主張されています。
そこで、disentangled attention mechanismでは、contentとpositionの二つの別々のベクトルを用いて、もつれのない(disentangled)Attention機構を提案しています。
トークン$i$から見たときのトークン$j$に対するAttentionの重みA_{i,j}は以下のように求めます。
\begin{align}
A_{i,j} &= {\lbrace H_i, P_{i | j} \rbrace }\times{\lbrace H_j, P_{j| i} \rbrace^T}\\
&= H_i H_j^T + H_i P_{j | i}^T + P_{i|j}H_j^T + P_{i|j}P_{j|i}^T
\end{align}
ただし、$\lbrace H_i\rbrace$は位置$i$のcontentを表すベクトルであり、$\lbrace P_{i|j} \rbrace$は位置$i$と$j$の相対位置を表すベクトルです。
2行目の式を見ると、$A_{i, j}$は4つの項で表されていることがわかります。BERTやRoBERTaでは、$H_i H_j^T $の項一つでAttentionの重みを計算していたため、disentangled attention mechanismではより多くの情報を捉えることが可能になっています。
ここで、4つの項は順に、
- Content-to-Content
- Content-to-Position
- Position-to-Content
- Position-to-Position
となります。
Content-to-Contentの項は、スタンダードなSelf Attentionに類似しており、各単語は入力テキスト内のすべての単語を見て、依存関係を求めようとしています。
Content-to-Positionの項は、$token_i$がどの位置を見るのが重要で、どの位置が他の位置よりも多くの情報を要求できる位置かを探ろうとしていると解釈できます。例えば、「I」は「am」の前に来るべきだとモデルが理解しているとした場合、「am」という単語は自身の直前の位置を見てもあまり役に立たないと考え、自身よりも後ろの位置を見たいと判断することができます。
Position-to-Contentの項は、位置$i$にある$token_i$が入力文のどの単語を見ればマスクされたトークンを予測しやすくなるかに役立つと解釈することができます。
Position-to-Positionの項は、あまり有用な追加情報を提供しないため、DeBERTaの実装では使われていないようです。
このようなアイディアでdisentangled attention mechanismは提案されています。ここで、single-headのAttentionを例にAttentionの計算をさらに詳しく追っていきます。
まずは、スタンダードなSelf-Attentionをおさらいします。入力の埋め込みベクトル$H \in \mathbb{R}^{N \times d}$、射影行列$W_q,W_k, W_v\in \mathbb{R}^{d \times d}$を用いて、Attention行列$A\in \mathbb{R}^{N \times N}$は、
\begin{align}
Q_c = HW_q, K = HW_k, V=HW_v, A = \frac{QK^T}{\sqrt{d}}
\end{align}
で求まります。ここで、$N$は入力の長さ、$d$は埋め込みベクトルの次元数です。また、Self Attentionの出力$H_o\in \mathbb{R}^{N \times d}$は
\begin{align}
H_o = softmax(A)V
\end{align}
と計算されます。
disentangled attention mechanismでは、contentとpositionを別々に用意します。$H, P$を用いて$Q, K, V$を表すと、
\begin{gather}
Q_c = HW_{q, c}, K_c = HW_{k, c}, V_c=HW_{v, c}, \\ Q_r=PW_{q, r}, K_r=PW_{k, r}
\end{gather}
となります。ここで$c$はcontentの、$r$はrelative positionの頭文字です。そして、Attention行列$\tilde{A}$の各要素$\tilde{A_{i, j}}$は。
\begin{gather}
\tilde{A_{i, j}} = Q^{c}_{i}{K^{c}_{j}}^T + Q^{c}_{i}{K^{r}_{\delta(i,j)}}^T + K^{c}_{j}{Q^{r}_{\delta(i,j)}}^T
\end{gather}
となります。ここで、最大相対距離$k$を用いて、トークン$i$からトークン$j$までの相対距離$\delta (i, j) \in [0, 2k)$を以下のように定義します。
\begin{align}
\delta(i,j) = \begin{cases}
0 & \text{if } i-j \leq -k \\
2k-1 & \text{if } i-j \geq k \\
i-j+k & \text{if } others. \\
\end{cases}
\end{align}
これは、$j$が$i + k$より後方にある時は0を、$j$が$i - k$より前方にある場合には$2k - 1$を、$i$と$j$の距離が$k$以下の場合は$i - j + k$を返す関数です。
例えば、$Q^{r}_{\delta(i,j)}$は$Q_r$の$\delta(i,j)$行目を表します。
Self Attentionの出力$H_o$は、
\begin{align}
H_o = softmax(\frac{\tilde{A}}{\sqrt{3d}})V_c
\end{align}
となり、$\tilde{A}$に$\frac{1}{\sqrt{3d}}$倍するスケーリングを適用することに注意します。このスケーリングは、大規模言語モデルの安定的な訓練を行う上で重要な処理となっています。
Enhanced Mask Decoder
DeBERTaはBERTやRoBERTaと同様にMLMによる事前学習を行います。このとき、周囲の文脈からマスクされた単語の予測するタスクを解くことになりますが、DeBERTaが絶対位置ではなく相対位置を採用していることで問題が起こります。
例えば、「a new store opened beside the new mall」という文の「store」と「mall」がマスクされている場合を考えます。この場合、どちらも「new」との相対位置は同じであるためモデルが「store」と「mall」を区別することが難しくなります。
この問題に対処するため、絶対位置も考慮する必要があります。BERTでは入力層で絶対位置が組み込まれていますが、DeBERTaでは絶対位置は、マスクされたトークン予測のためのソフトマックス層の直前の変換層の直後に追加されます。
以下はEMDを表す図です。EMDが二層のTransformer Layerからなる場合、一層目へ入力する$Q$の代わりとして、$H$と絶対位置の情報を持つ$I$との和となります。そして、二層目へ入力する$Q$としてEMDの一層目の出力とします。
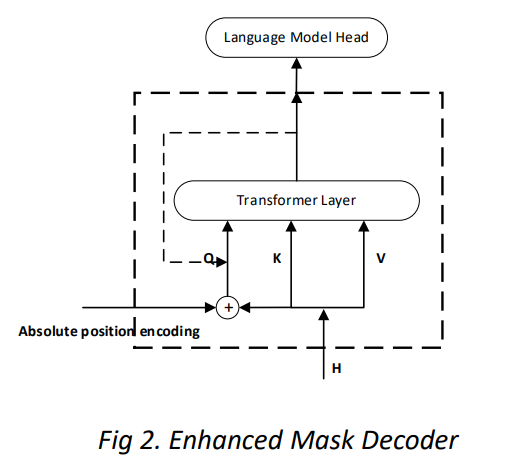
著者のスライドから引用
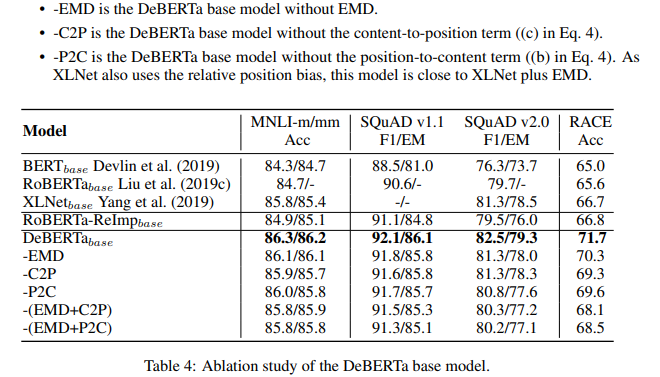
Ablationを見ると確かに提案手法が性能向上に寄与していることがわかります。
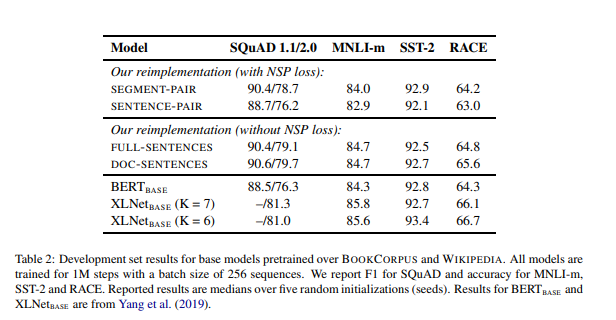
その他モデルとの比較は以下の通りです。
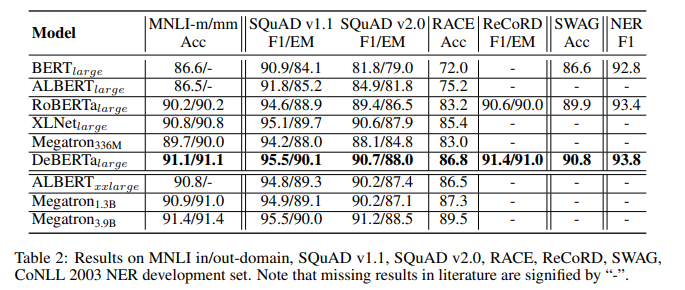
なお、RoBERTa、XLNet、ELECTRAは160Gの訓練データで事前訓練されているのに対し、DeBERTaは78Gの訓練データで事前訓練されています。
まとめ
BERTからRoBERTaは事前学習の仕方に違いがあり、BERT/RoBERTaからDeBERTaはモデル構造に手を加えていることが大きな違いであることがわかりました。
今後も機械(深層)学習手法の知識整理をしていこうと思います。