BLIP-2の論文を読んだので内容を整理します。
ざっくりとした内容
事前学習済みの視覚モデルは高品質な視覚表現を作成し、LLMは高い言語生成能力とゼロショットでの変換能力を持ちます。
できれば事前学習済みモデルをうまく使い、視覚と言語のギャップを埋めることで、計算コストを抑えたいです。また、事前学習時に獲得した知識の忘却を防ぐという目的でもパラメータを凍結する方が好ましいです。
そこで本論文では、視覚と言語のアライメントに焦点を当て、二つのモダリティのギャップを埋めることのできるQuerying Transformer(Q-Former)を提案しています。
ここまでの内容と提案手法の概要を簡単にまとめると、
- 事前学習済み画像モデルとLLMを組み合わせる
- 画像とテキストという異なるモダリティの橋渡しにはQ-Formerを使用する
- 既存手法よりも圧倒的に少ない学習パラメータにもかかわらず、様々なVision&LanguageタスクでSOTAを達成した
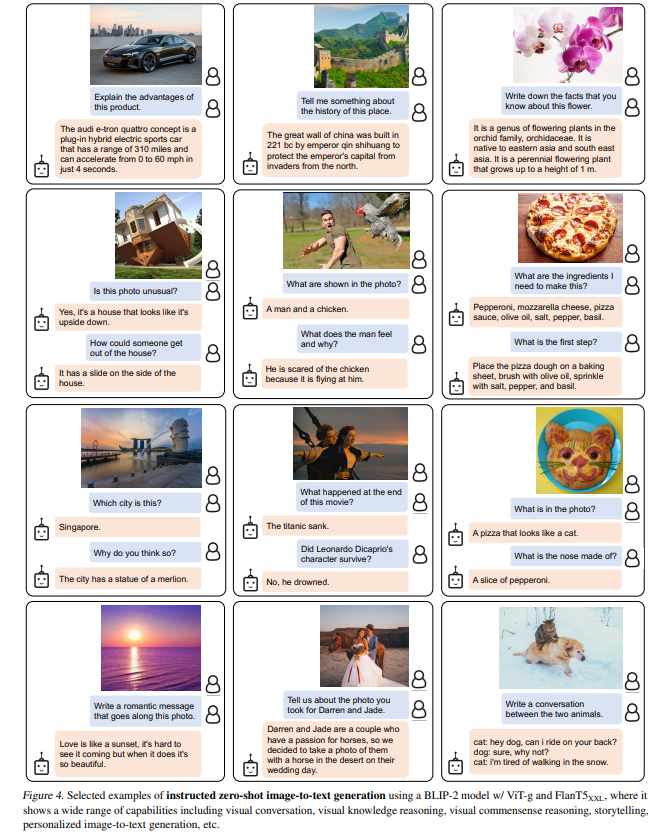
提案手法により以下のように画像からテキストを生成することができます。
Q-Formerの構造
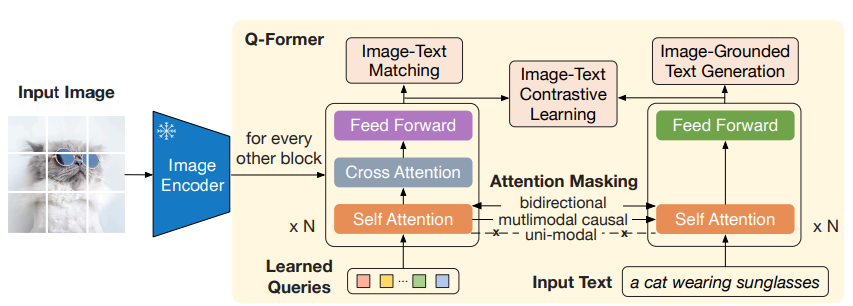
Q-Formerは、以下の二つのサブモジュールで構成されています。
- 画像エンコーダと相互作用して視覚特徴を抽出する画像変換モジュール(左)
- テキストエンコーダとテキストデコーダの両方として機能するテキスト変換モジュール(右)
ただし、Self Attention層はこれらのサブモジュール間で共有されています。
Q-Formerは事前学習済みのbert-baseの重みで初期化され、合計で188Mのパラメータを持っています。
また、画像変換モジュールのために、学習可能なクエリ埋め込みを作成しています。クエリはSelf Attention層で互いに作用した後、Cross Attention層にて画像エンコーダの特徴と作用します。
実験では32のクエリを使用していて、各クエリの次元は768(Q-Formerの隠れ層の次元と同じ)です。Cross Attention層については、ランダムな値で初期化されます。
BLIP-2の事前学習
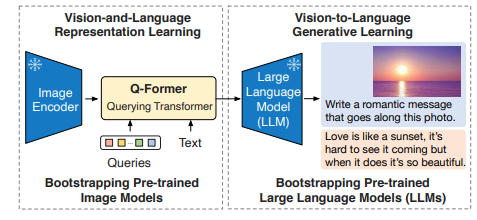
BLIP2では、モダリティ間のギャップを埋めるためにQ-Formerに対して二段階の事前学習戦略を採用しています。
一段階目のVison-and-Language Representation Learningでは、クエリがテキストの情報をよく抽出できるような画像表現を学習するようにQ-Formerを訓練します。具体的には、Q-Fomrerをパラメータ凍結した画像エンコーダに接続し、画像とテキストのペアを用いて事前学習します。
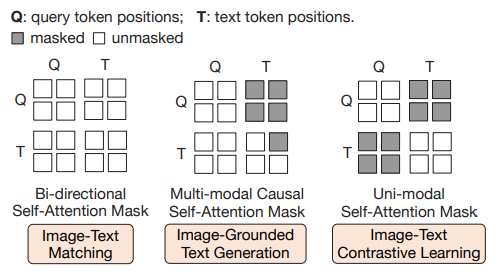
以下の3つの事前学習を共同で最適化します。また、それぞれで異なるSelf Attention Maskingを用います。
Image-Text Contrastive Learning (ITC)
対照学習により、画像表現とテキスト表現の相互情報が最大になるように、画像表現とテキスト表現をアライメントさせる学習を行います。
画像変換モジュールからの出力クエリ表現を$Z$、テキスト変換モジュールからのテキスト表現を$t$とします。$Z$は、複数のクエリ表現を持っていて、それぞれとtの類似度を計算し、最も類似度の高いペアを画像-類似度テキストとして選択します。
また、情報のリークを避けるためにクエリとテキストが互いに見えないようなSelf-Attention Maskを使用します。
Image-grounded Text Generation (ITG)
入力画像から、Q-Formerにテキストを生成するよう学習させます。これにより、クエリは画像特徴量からテキスト生成に必要な情報を抽出するようになります。
クエリとテキストの相互作用をコントロールするために、UniLMで使用されているMulti-modal Causal Self-Attention Maskを使用します。
Image-Text Matching (ITM)
画像とテキスト表現間のきめ細かな整合を学習することを目的とする、画像とテキストのペアが正(一致)か負(非一致)かを予測するタスクです。
Vison-and-Language Representation Learning
二段階目のVision-to-Language Generative Learningでは、Q-Formerの出力をパラメータ凍結したLLMに渡して視覚から言語への生成学習を行い、Q-Formerの出力がLLMに解釈されるようにトレーニングします。
クエリとテキストが互いにAttentionされるため、出力されるクエリ埋め込み$Z$は、マルチモーダルな情報を捉えることができます。
Vision-to-Language Generative Learning
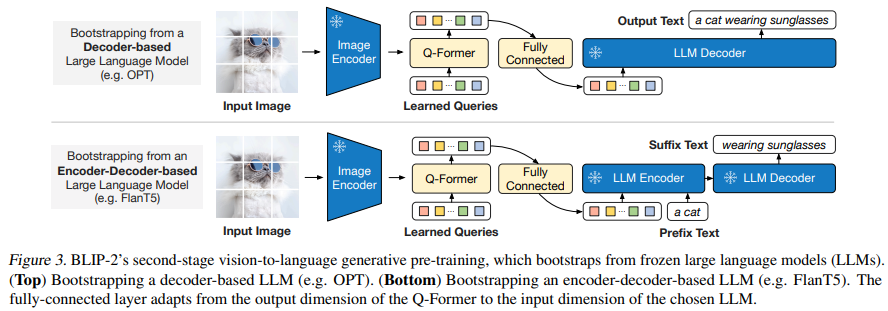
図3に示すように、全結合層を使って、出力クエリ埋め込みZをLLMのテキスト埋め込みと同じ次元に線形射影します。Encoder-DecoderベースのLLM(FlanT5など)を用いる場合、線形射影されたこの埋め込みは、テキストの前部分の埋め込みと共にLLMに入力されます。Decoderベース(OPTなど)の場合、Q-Formerからの視覚表現からテキストを生成しっます。
事前学習のデータセットと実験設定
COCO 、Visual Genome 、CC3M 、CC12M 、SBU 、LAION400Mデータセットの115M画像を含む、合計129M画像のBLIPと同じ事前学習データセットを使用します。
| 学習段階 | モデル | バッチサイズ(ViT-L/ViT-g) | バッチサイズ(OPT/FlanT5) | 学習ステップ数 |
|---|---|---|---|---|
| 一段階目 | ViT-L/ViT-g | 2320 / 1680 | - | 25万ステップ |
| 二段階目 | OPT/FlanT5 | - | 1920 / 1520 | 8万ステップ |
また、最大サイズのモデル(ViT-gとFlanT5-XXL)計算時間は、16-A100(40G)のマシンを1台使用した場合、第一段階で6日未満、第二段階で3日未満でした。
ハイパーパラメータについては、すべてのモデルで同じ値です。AdamW をβ1 = 0.9、β1 = 0.98、weight_decay=0.05を使用します。ピーク学習率を1e-4、Cosine Decayを用い線形ウォームアップを2kステップ行います。第2段階での最小学習率は5e-5である。224×224サイズの画像を用い、ランダムなリサイズと水平反転でAugmentします。
実験
表1に、様々なゼロショット視覚言語タスクにおけるBLIP-2の性能を示します。

これまでの最先端モデルと比較して、BLIP-2は、事前学習時に必要な学習可能なパラメータ数を大幅に減らしながら、性能の向上を達成することができています。
ゼロショットVQA
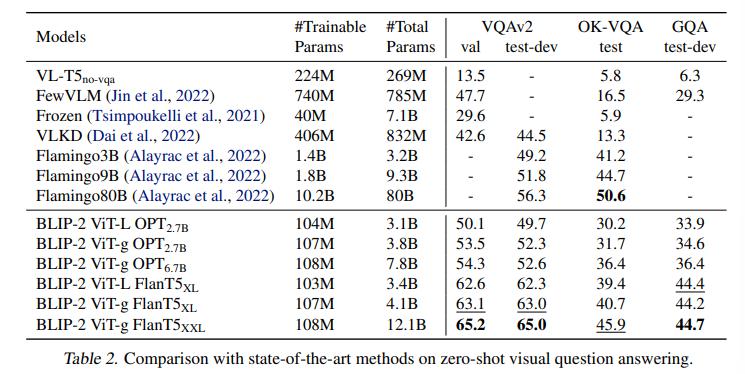
BLIP-2はVQAv2 とGQAデータセットで他のモデルを上回っています。
Vision-Language Representation Learningの効果
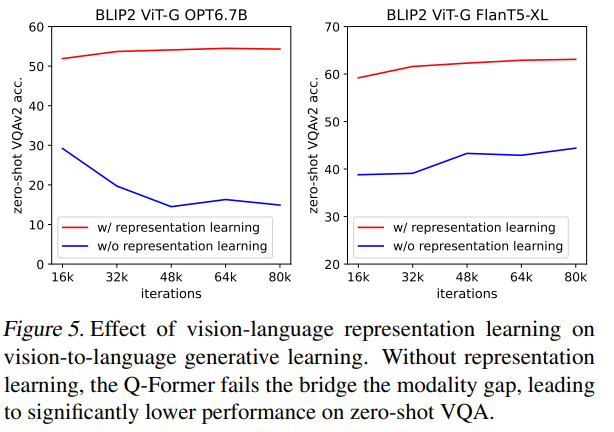
第一段階目のVision-Language Representation Learningなしでは、ゼロショットVQAでのモデルの性能が大きく悪化することがわかります。特に、一段階目なしでOPTを使う場合、二段階目の学習は、学習が進むにつれて性能が急激に悪化することも読み取れます。
Image Captioning
BLIP-2モデルを画像キャプション生成タスクでファインチューニングした結果は以下の通りです。
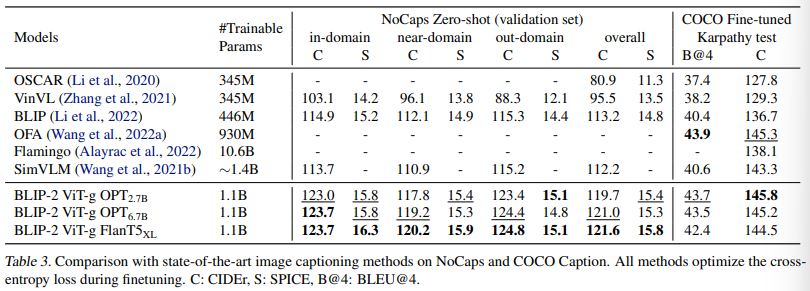
BLIP-2は、NoCaps上で既存の手法よりも大幅に上回る結果を達成しています。
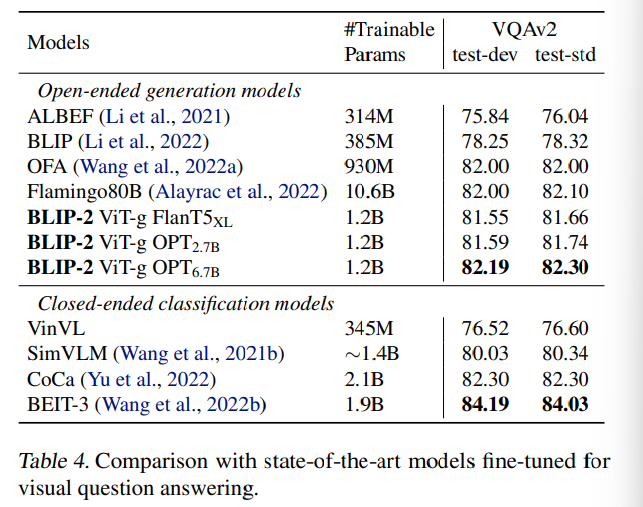
VQA
アノテーション付きのVQAタスクでは、LLMのパラメータを凍結させたまま、Q-Formerと画像エンコーダのパラメータをファインチューニングさせています。
画像テキスト検索
画像テキスト検索は言語生成を伴わないため、LLMを無しで第一段階の訓練済みモデルを直接ファインチューニングします。具体的には、ITC、ITM、ITGを用いて、COCO上でQ-Formerと共に画像エンコーダをファインチューニングします。そして、COCOとFlickr30Kデータセットを用いて、画像からテキストへの検索とテキストから画像への検索の両方でモデルを評価します。推論時は、まず画像テキスト特徴の類似度に基づいてk = 128の候補を選択し、次にペアごとのITMスコアに基づいて順位を決定します。その結果を以下の表5に示します。
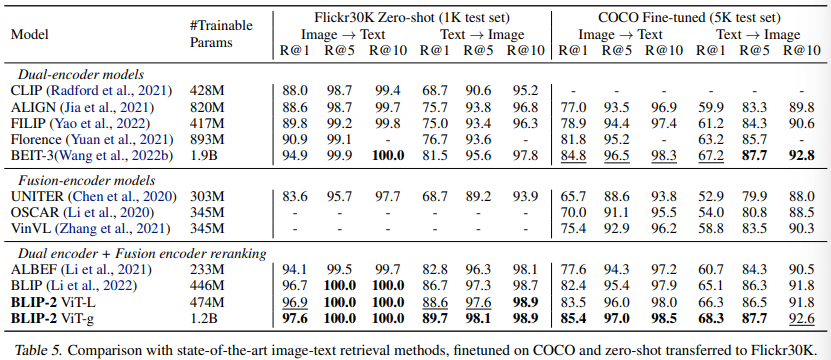
BLIP-2は、ゼロショットの画像テキスト検索において、既存の手法を大幅に上回る結果を出しています。
ITCとITMは画像とテキストの類似性を直接学習するため、画像テキスト検索には不可欠であることはわかりますが、ITG(image-grounded text generation)についてはどうでしょうか。表6をみると、ITGについても画像テキスト検索において、性能向上に寄与していることがわかります。
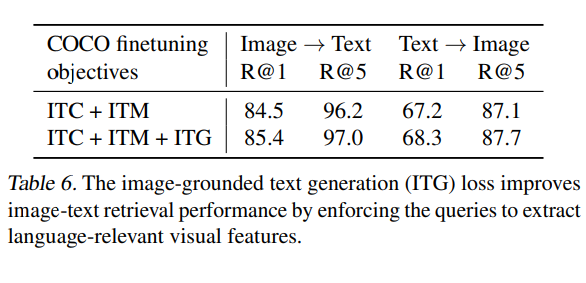
ITGは、テキストに最も関連する視覚的特徴を抽出するようにクエリを強制することができるため、視覚と言語間のアライメントの向上に貢献することができます。
まとめ
BLIP-2では、画像エンコーダとLLMの間にQ-Formerを挟み、二段階の事前学習を行うことで、計算コストを抑えつつ視覚と言語のギャップを埋めることが可能となっています。
一方で、In-Context Learningができないという課題があり、これは事前学習データセットが1つの画像とテキストのペアしかないことが原因だと考察されています。また、LLMの社会的なバイアスや不適切な発言の生成といったリスクを継承しているという課題も指摘しています。