はじめに
きれいに画像を拡大できない?
何気ない質問から、ググってみるとwaif2xというアプリがなかなか良いとの評判
調べてみると、今はやりのDeeplearningを使った拡大アプリのようです
Kerasを使い始めていたので試してみよう!ってことで簡単なモデルを試してみました
データセット
簡単な画像データセットとして頭に浮かんだのがMNIST
28x28ピクセルのグレーデータ(1ch)でkerasのデータセットとして用意されています
通常の数字認識と異なるので使用するのは手書き画像のみ
今回は、縦横2倍、4倍で学習してみます
元々の画像を拡大後と比較するため、縮小画像を入力画像として準備
waif2xも入力画像を拡大してからCNNにかけているようなので
縮小後にnearest neighborで拡大した画像を入力画像とします
input=[]
input2=[]
for i in range(60000):
sample=x_train[i].copy()
sample=cv2.resize(sample, dsize=(14,14))
sample=cv2.resize(sample, dsize=(28,28), interpolation=cv2.INTER_NEAREST)
input.append(sample)
sample2=x_train[i].copy()
sample2=cv2.resize(sample2, dsize=(7,7))
sample2=cv2.resize(sample2, dsize=(28,28), interpolation=cv2.INTER_NEAREST)
input2.append(sample2)
input = np.array(input)
input2 = np.array(input2)
input = input.reshape(60000,28,28,1)
input2 = input2.reshape(60000,28,28,1)
入力画像を確認
50%画像は、なんとなく認識できるものの25%まで縮小するとかなり厳しい感じです
果たしてうまくいくか?
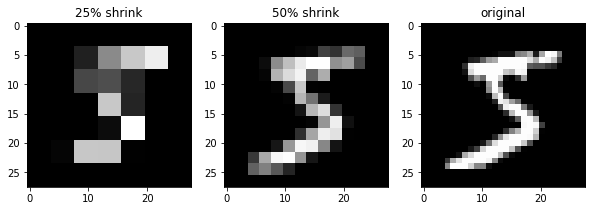
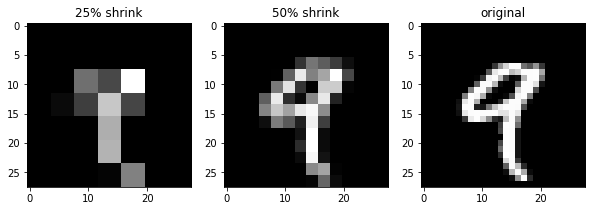
モデル
waif2xが参考にしたというSRCNNにならって単純な4層のCNNでモデルを作成
modelx2 = models.Sequential()
modelx2.add(layers.Conv2D(16, (3, 3), activation='relu', padding='same', input_shape=(28,28,1)))
modelx2.add(layers.Conv2D(32, (3, 3), activation='relu', padding='same'))
modelx2.add(layers.Conv2D(64, (3, 3), activation='relu', padding='same'))
modelx2.add(layers.Conv2D(1, (3, 3), activation='relu', padding='same'))
modelx2.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_33 (Conv2D) (None, 28, 28, 16) 160
_________________________________________________________________
conv2d_34 (Conv2D) (None, 28, 28, 32) 4640
_________________________________________________________________
conv2d_35 (Conv2D) (None, 28, 28, 64) 18496
_________________________________________________________________
conv2d_36 (Conv2D) (None, 28, 28, 1) 577
=================================================================
Total params: 23,873
Trainable params: 23,873
Non-trainable params: 0
_________________________________________________________________
学習演算
損失関数は、2乗和誤差
最適化関数は、rmsprop
と基本的なものを使用
modelx2.compile(optimizer='rmsprop', loss='mse', metrics=['accuracy'])
modelx2.fit(input, x_train, epochs=5, batch_size=64)
結果
50%画像で学習したモデルで拡大した結果
そこそこoriginal画像に近づいています
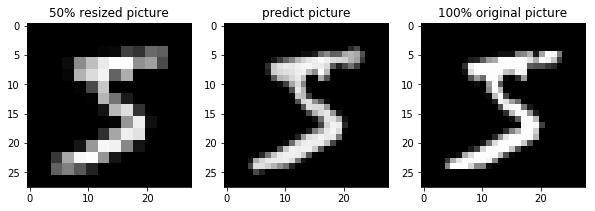
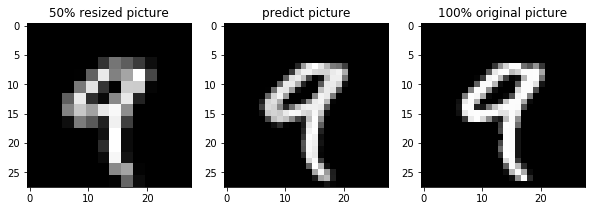
50%画像で学習したモデルで25%画像を拡大した結果
この結果はいまいちです、とくに9は数字として認識できません
学習時と条件がことなるとうまくいかないようです
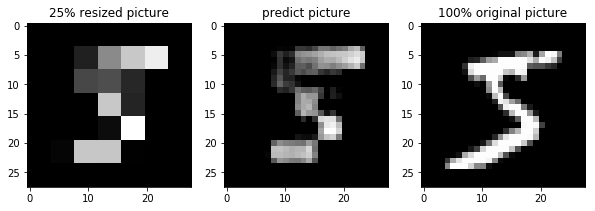
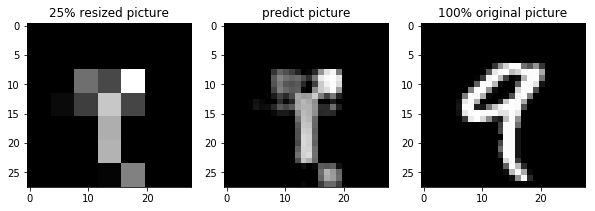
再学習した結果
25%画像で再学習を行ってみます
モデルとしては50%と同じで入力画像のみ変更した結果
9も何とか視認できそうなくらいの再現性です
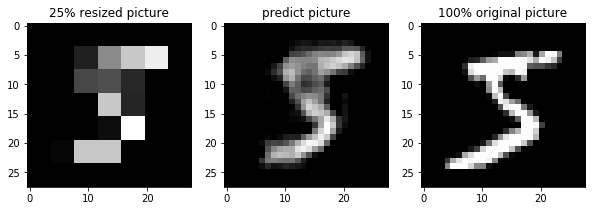
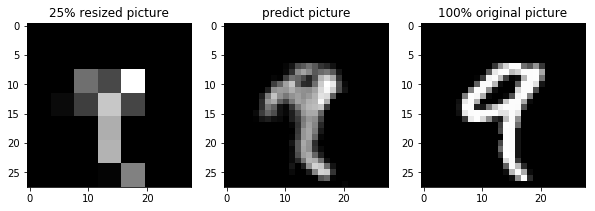
まとめ
CNNの4層だけでここまでの超解像ができてしまうことにびっくりしました
今回は手短に、手書き文字でのトライでしたが、写真画像を探してトライしてみたいと思います