前回はWebブラウザにデータを登録する処理について記述をしました。
今回は逆にWebブラウザよりデータを取得する処理について2点、紹介していきます。
テキスト情報の取得
さっそく、QiitaのWebページからデータを取得していきましょう。
例えば下記のページの要素から、「プログラミング知識を共有しよう」というデータが欲しかったとします。
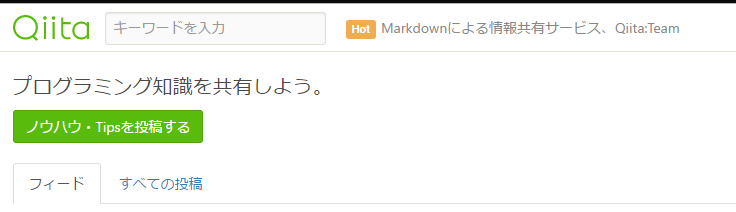
この場合、最も簡単な方法はRecordingよりCopy Textを使う事です。下記の項目を選択して、取得したい要素を指定。
Save & Editすると下記のシーケンスが自動で作成されます。
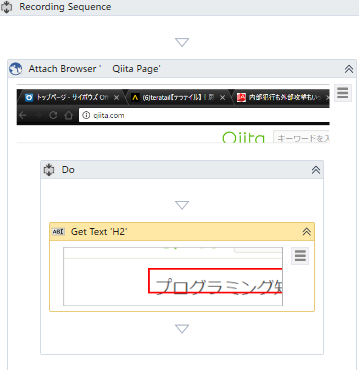
Attachは、開いているブラウザをActiveにするイメージとなります。次にGet Textという要素が出てきました。
これがWebから要素を取得する処理となります。
Recordingを使うと、Outputには自動で、Hという名前のOutputが出来ます。
Outputはgeneric型です。これは、UiPath特有の型で、String,Int,Date,Boolean等の様々な要素を受け取れる型となります。
この内容をMessage Boxを使って出力しましょう。generic型は、利用する時に型指定する必要があります。
今回はMessage Boxの出力として使うので、ToStringで文字列として扱いましょう。
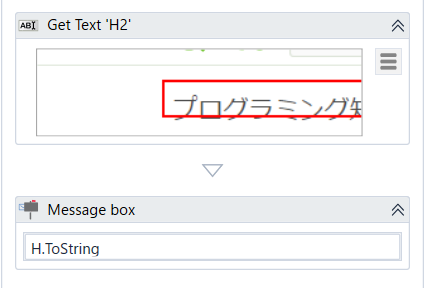
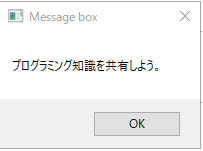
とても、簡単にできました。
ところで、今回の様にデータが出現する場所が固定であればさほど、難しくないのですが、欲しいデータの位置が可変となる場合、
Selectorという概念を理解する必要があります。
詳細はこちらの記事に書いているので、今回は割愛します。
下記の様なケースで、合計の数字を取ろうとすると、日によって、データが出現する位置が異なるので、
工夫する必要があるんです…
6/22時点のデータ(合計が3行目にある)
Left align Right align This 1 column 2 合計 3 6/23時点のデータ(合計が4行目にある)
Left align Right align This 4 column 5 is 6 合計 15
データスクレイピング
Webページのデータが規則的な場合、この機能を使う事が出来ます。(2)の記事でQiitaの記事一覧を作っていたのがこの技術です。
早速、使っていきましょう。
①Data Scrapingを選択する

②下記の画面が出るので、Nextを選択
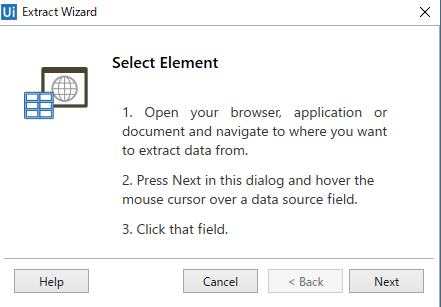
③最初の要素を選択して、Nextをクリック
④次の行の要素を選択して、Nextをクリック。すると、下記の画面が出てくるので、データに適当な名前を付けてNextをクリック
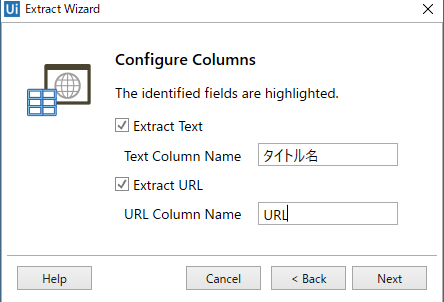
下記の順にクリックするイメージ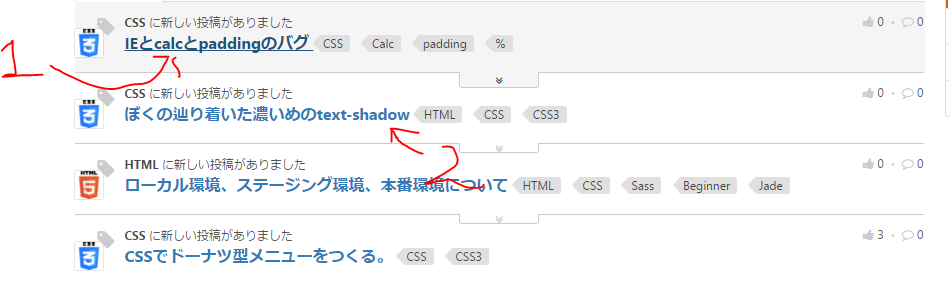
⑤下記の画面が出てくるので、内容を確認する。終わりたければ、「Finish」ボタンで良いが、さらに、「いいねの数」も欲しかったので、Extract Correlated Dataをクリック
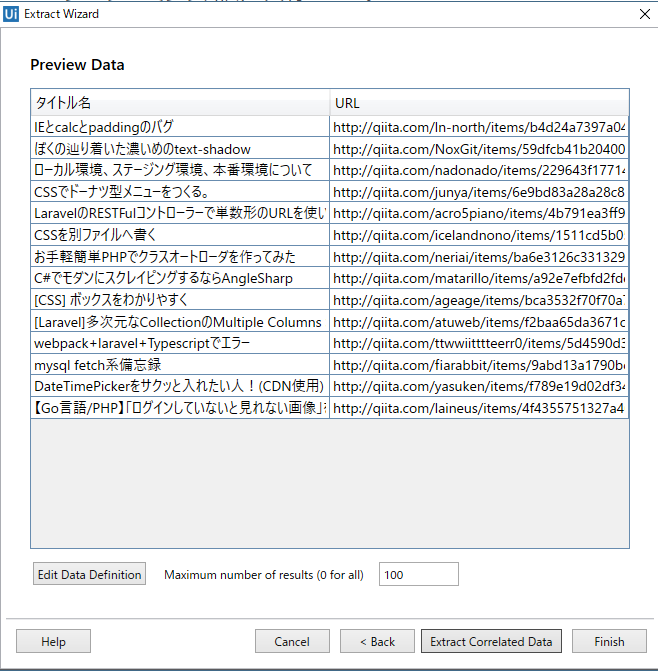
⑥いいねについても、上記の③~⑤の手順の容量で処理を行う。データの取得はここで終わりにするので、「Finish」をクリック。
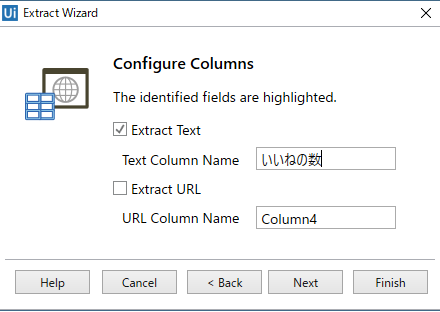
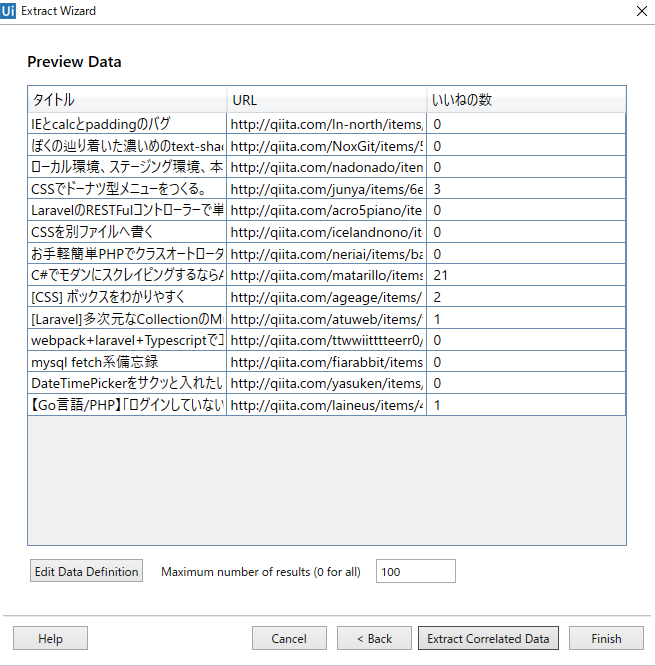
Maximum number of resultsは、最大でこのテーブルから何件のデータを取得するかを表す。
この場合、Defaultの100件にしています。
⑦次に、複数ページあるか聞いてきます。Qiitaの記事の一覧は「もっと見る」ボタンを押すと、より多くの記事が出ますね。というわけで、Yesを選択しましょう。
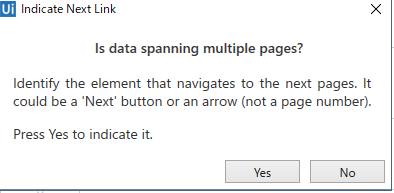
⑧次のページへ遷移するボタンを支持する必要があるので、「もっと見る」ボタンを指定してあげます。

これで完了です。作成されたシーケンスを見てみましょう。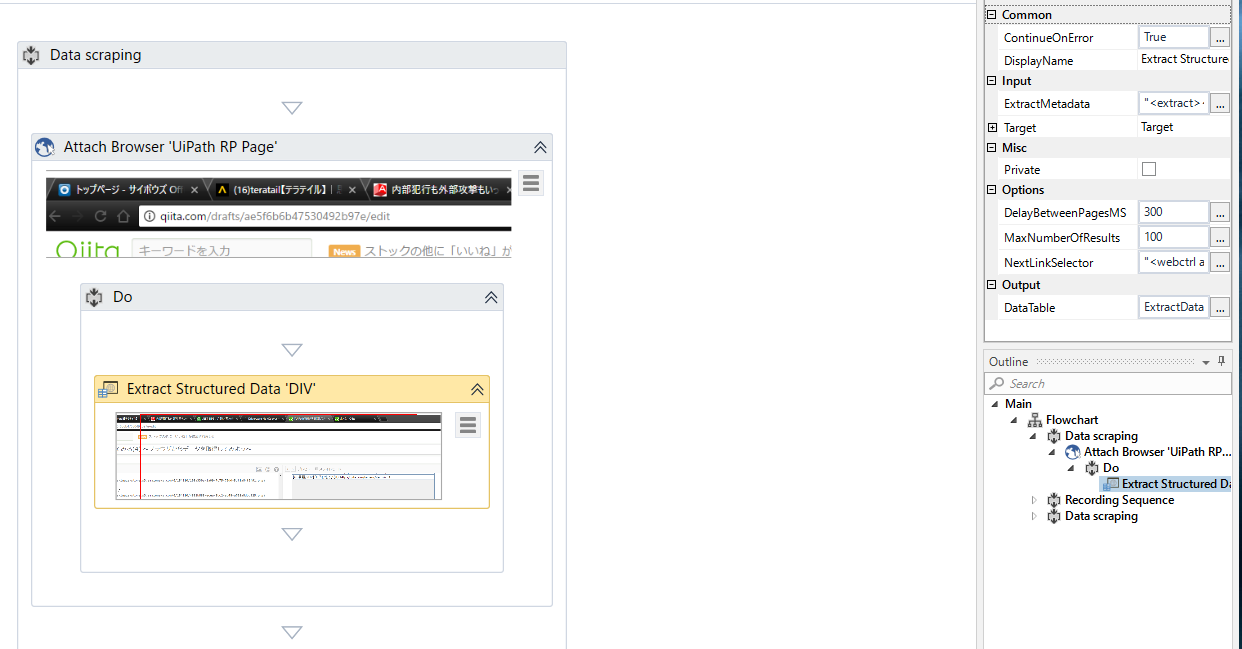
Outputはテキストの取得とは異なり、DataTable型となります。
なので、簡単にCSV形式に吐き出すことができます。
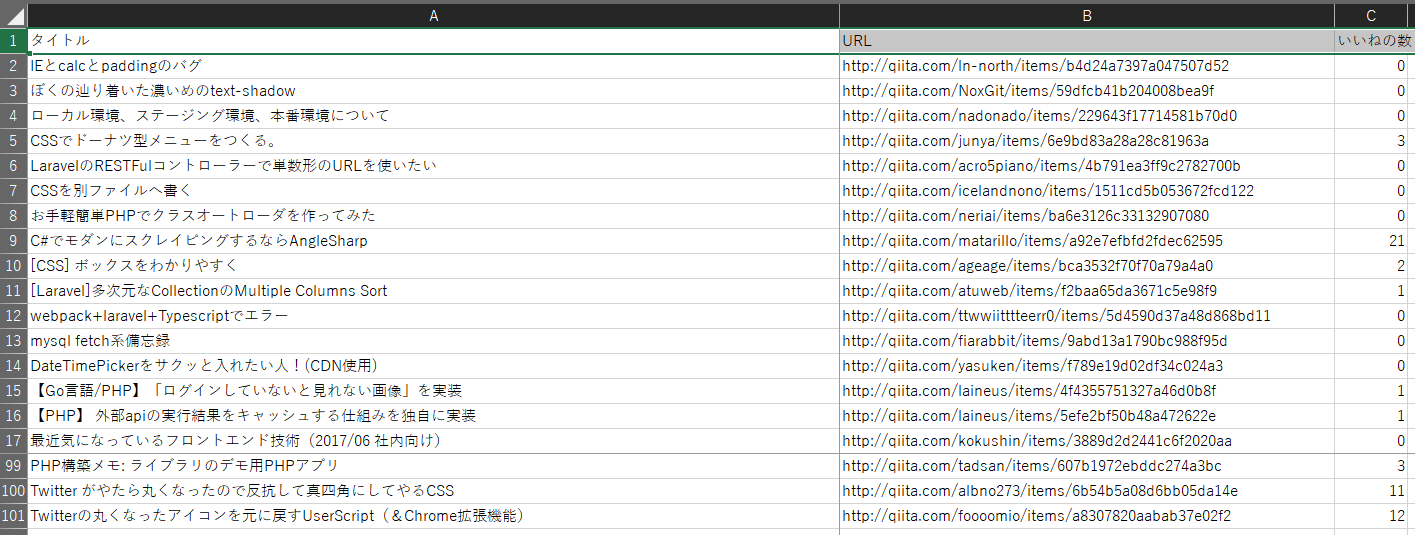
この様に、100件のデータが無事に取得されました。
とりあえず、よく使いそうな機能を書いたので、次は細かなテクニックを色々と書いてみたいと思います。