最適解で何を求めたいか?
みんな大好きBostonの家の価格のデータセットがありますよね。このデータセットを使って、最適解を求めたいと思いました。
|カラム| 説明|
|------|------------------------------------------------------|
|CRIM |犯罪率|
|ZN| 住宅の密集度|
|INDUS| 非小売業の割合
|CHAS |チャーリーズ川ダミー変数(川の周辺1、それ以外0)|
|NOX |酸化窒素濃度|
|RM |1住戸あたりの平均部屋数|
|AGE |1940年以前に建設された物件割合|
|DIS |5つのボストンの雇用センターまでの距離|
|RAD |大きな道路へのアクセス距離|
|TAX |10,000ドルあたりの税率|
|PTRATIO| 教師あたりの生徒数|
|B |町における黒人の割合|
|LSTAT |人口当たり給料の低い率|
|MEDV |住宅の中央値|
例えば、家の価格(MEDV)が安くて、部屋の数(RM)が多いところに住みたいよね。部屋数が多くて価格が安いのが皆さんうれしいですよね。この最適解モデルができれば、SUUMOとかホームメイトとか、賃貸業者に売れるかもしれません。
とりあえずボストンのデータセットをもとに、遺伝的アルゴリズムでパレート最適解を求めてみよう。
特徴量と目的変数、データの可視化
目的変数が、(MEDV,RM)で、それ以外を特徴量にしました。
その特徴量で、それぞれ目的変数として、サポートベクター回帰を使いMEDVとRMの学習モデルを作りました。
モデル1として、家の価格(MEDV)の予測モデルを作ります。
|特徴量| 目的変数|
|------|------------------------------------------------------|
|CRIM,ZN,INDUS,CHAS,,NOX,AGE,DIS,RAD,TAX,PTRATIO,B,LSTAT|MEDV|
モデル2として部屋の数(RM)の予測モデルを作ります。
|特徴量| 目的変数|
|------|------------------------------------------------------|
|CRIM,ZN,INDUS,CHAS,NOX,AGE,DIS,RAD,TAX,PTRATIO,B,LSTAT|,RM|
まず家の価格と部屋の数は結構相関があるんですよね。だから、これをお互いのモデルを作るときに、特徴量からはずすと、精度があがらないような気がします。
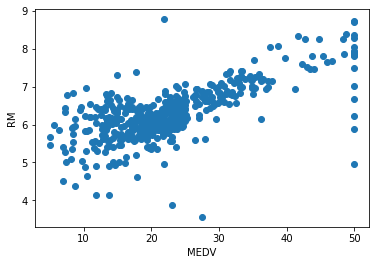
後、見てわかるように、家の価格の50のところにグラフの上ではデータが縦に並んでいます。そこで、家の価格50以上は除きました。
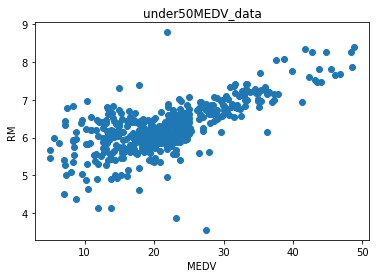
SVRでの予測で価格と部屋の数の予測結果
まずSVRで学習モデルを作りましたが。。。
ここのアルゴリズムは何でもよくて、サポートベクターでもランダムフォレストでもお好きなもので。
サポートベクターのハイパーパラメーターは、optunaで決定しました。
学習モデル1は、optimised_svr_MEDVに、学習モデル2は、optimised_svr_RMに入れました。
予測結果はこういう感じです。
MEDVの学習精度:0.873
MEDVのテスト精度:0.748
RMの精度:0.628
RMの精度:0.439
確かに家の価格は、部屋数がなくても、他の要因で説明できそうです。
でも、部屋の数は、犯罪率や大きな道路へのアクセスとか、関係あるとは思えません。予想通り、精度はあがりませんでした。
まぁ仕方がないので、このまま遺伝的アルゴリズム(GA)にかけようと思います。
NSGAⅡでの価格と部屋のパレート最適解
ここまできて、ふと思った。部屋の数とか整数のはずなのに、dtypesで型を見てみるとfloat型になっている。
とりあえず今回は全部float型で計算をした。
アルゴリズムはNSGAⅡで、遺伝子は1000個、10000回繰り返して計算した。
# ライブラリーのインポート
from platypus import NSGAII, Problem, Real
# 遺伝子による変数の設定と学習モデル(目的関数)による予測結果
def objective(vars):
crim = vars[0]
zn = vars[1]
indus = vars[2]
chas = vars[3]
nox = vars[4]
age = vars[5]
dis = vars[6]
rad = vars[7]
tax = vars[8]
ptratio = vars[9]
bb = vars[10]
lstat = vars[11]
ga_data = [[crim,zn,indus,chas,nox,age,dis,rad,tax,ptratio,bb,lstat]]
#遺伝子を標準化
ga_data_std = scaler.transform(ga_data)
#学習モデルによる予測
ga_MEDV_np = optimised_svr_MEDV.predict(ga_data_std)
ga_RM_np = optimised_svr_RM.predict(ga_data_std)
ga_MEDV = ga_MEDV_np[0]
ga_RM = ga_RM_np[0]
return [ga_MEDV,ga_RM]
# Platypus遺伝的アルゴリズムの設定
# 変数が12個、目的関数が2個
problem = Problem(12, 2)
# 変数の設定。すべて実数Realとした。また、最大値最小値は、元データの最大値と最小値にした。
problem.types[:] = [Real(0.006, 88.976),Real(0.00, 100.00),Real(0.740, 27.740),Real(0.00,1.00),Real(0.385, 0.871),Real(2.9000, 100.00),
Real(1.137, 12.126),Real(1.00, 24.00),Real(187.00, 711.00),Real(12.60, 22.00),Real(0.32, 396.90),
Real(1.980, 37.90)]
problem.function = objective
# 価格を最小に、部屋数を最大にする。
problem.directions[:] = [Problem.MINIMIZE, Problem.MAXIMIZE]
algorithm = NSGAII(problem,population_size=1000)
algorithm.run(10000)
計算結果は、後で処理しやすいようにpandasで保存します。空のデータフレームを作って、そこにalgorithm.resultのvariablesの中に変数(遺伝子)が、objectivesに結果が入っていますので、それを空のpandasに取り込んでから、保存しました。
ga_result = pd.DataFrame(columns=['CRIM','ZN','INDUS','CHAS','NOX','AGE','DIS','RAD','TAX','PTRATIO','B','LSTAT','MEDV','RM'])
for i in range(len(algorithm.result)):
ga_result.loc[i] = algorithm.result[i].variables[:] + algorithm.result[i].objectives[:]
ga_result.to_csv("ga_result.csv")
部屋の数と家の価格のパレート最適解は
青いプロットが元のデータ。赤のプロットが遺伝的アルゴリズムが計算した結果です。
これを見るとほかの条件を気にしなければ、部屋数が6で価格が10くらいの家が、部屋が多くて家族が多くなっても暮らしやすくて価格が安いということになりますね。
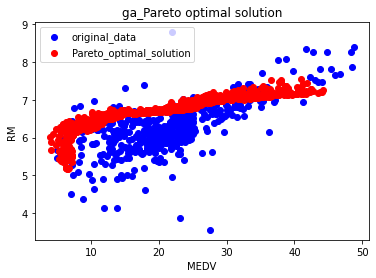
元のデータだと、単純な相関のように見えるけど、遺伝的アルゴリズム的には、変曲点が見えているようです。
草薙素子チックにつぶやくと。。。
「そうささやくのよ、わたしの遺伝子が。。。」
3カ月くらいplatypusいじってます。マニュアルがあっさり書いてあるので、初心者の私にはだいぶ難しいのですが、とりあえずここまでできました。