DeepLearningで出てくるグラフは
今、この本を勉強しています。
動かしながら学ぶPyTorchプログラミング入門
いつもDeepLearningでサンプルとして出てくるグラフはこんなグラフです。
ミニバッチでの計算で、Epochの回数とLossのデータで、予測がうまくいっているかどうかを見るグラフが出てきます。これはこれで良いのだけど、・・・・。
最初のところに回帰のサンプルプログラムがついているのですが、ここでも、上のグラフしか出てきません。
scikit-learnの機械学習からやり始めた私は、ディープラーニングでは、実測値と予測値のこういうグラフをなぜ書かないんだろうといつも疑問に思っています。
同じグラフで描かないと、機械学習とディープラーニングの回帰の比較の可視化ができません。
そう思ったので、ディープラーニングのPyTorchの勉強しながら、グラフを描いてみました。
参考にしたプログラムは
動かしながら学ぶ PyTorchプログラミング入門の中の第3章「糖尿病の予後予測」のプログラムをベースに、データをボストンの家の価格のデータセットに変更して使用しました。
元のプログラムは、
https://www.ohmsha.co.jp/book/9784274226403/
の Section3-3.ipynb です。
変更点のみ、以下にプログラムを書いていきます。
ボストンの家の価格のデータセットをディープラーニングで回帰する
「動かしながら学ぶ PyTorchプログラミング入門」の第三章の糖尿病のデータセットのディープラーニング回帰からボストンのデータセットに変更する変更点は以下のところのみです。
基本は、diabetes → boston に変更することで、データセットを変更します。
# 元のサンプルプログラムの次の部分を変更
# サンプルプログラム
# データセットの読み込み
from sklearn.datasets import load_diabetes
diabetes = load_diabetes()
# データフレームに変換
df = pd.DataFrame(diabetes.data, columns=diabetes.feature_names)
# 1年後の進行度の追加
df['target'] = diabetes.target
# データセットの可視化
sns.pairplot(df, x_vars=diabetes.feature_names, y_vars='target')
plt.show()
# データセットの読み込み
diabetes = load_diabetes()
data = diabetes.data # 特徴量
label = diabetes.target.reshape(-1, 1) # 一年後の糖尿病の進行度
# ハイパーパラメータの定義
D_in = 10 # 入力次元: 10
# 上の部分を下記のように変更
# 基本的にdiabetes → boston に変更する
# ボストンの家のデータセットへ変更
# データセットの読み込み
from sklearn.datasets import load_boston
boston= load_boston()
# データフレームに変換
df = pd.DataFrame(boston.data, columns=boston.feature_names)
# 1年後の進行度の追加
df['target'] = boston.target
# データセットの読み込み
boston = load_boston()
data = boston.data # 特徴量
label = boston.target.reshape(-1, 1) # ボストンの家の価格
# ハイパーパラメータの定義
D_in = 13 # 入力次元: 13
注意点は、入力の特徴量が、糖尿病のデータセットが10に対し、ボストンの家の価格のデータセットが13であるので、ディープラーニングの入力の次元も変更する必要があるところである。
これで、ボストンのデータセットで回帰計算ができます。
計算はGPU(cuda)で計算しています。
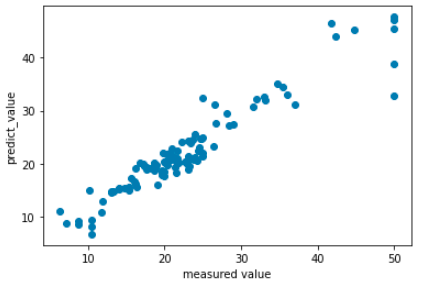
結果は次のとおりです。
精度がいまいちですけど、グラフを描きたいだけなので、このまま次にいきます。
ボストンの家のデータセットでランダムフォレスト回帰
これは簡単です。
scikit-learnの計算はとっても簡単だと思います。
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import r2_score
import matplotlib.pyplot as plt
rg = RandomForestRegressor(n_jobs=-1, random_state=0)
rg.fit(train_data,train_label)
test_predict = rg.predict(test_data)
rg_scorer = r2_score(test_label, test_predict)
print('ランダムフォレストのR2:{:.3g}'.format(rg_scorer))
plt.scatter(test_label, test_predict)
plt.xlabel("measured_value")
plt.ylabel("predict_value")
plt.show()
# ランダムフォレストのR2:0.724
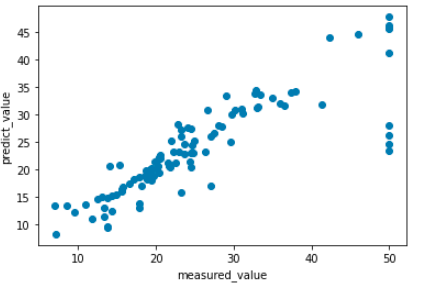
見慣れたグラフを描きました。
Pytorchのディープラーニングでグラフを描くためには
ポイントは、予測結果は、gpu(cuda)で扱うためのtensor形式になっているため、それをcpuで扱える形式に戻して、さらにnumpyにする必要があります。.to('cpu').detach().numpy().copy() この部分です。
# 予測結果のグラフ
import numpy as np
# ディープラーニングを評価モードに設定
net.eval()
# tesonr形式になっているtestデータセットの特徴量データをdevice(gpu:cuda)に送る。
data = test_x.to(device)
# gpuに送ったデータを評価モードのDLで予測する
y_pred = net(data)
# ここでy_predは、gpu(cuda)で計算するtensor形式なので、これをcpuで扱うnumpyに戻す必要がある。
# .to('cpu')で、gpuからcpuモードに戻す
# .detach().numpy().copy()で、tensor形式からnumpy形式に戻して、コピーする
y_pred_cpu = y_pred.to('cpu').detach().numpy().copy()
from sklearn.metrics import r2_score
dl_scorer = r2_score(test_label, y_pred_cpu)
print('ディープラーニングのR2:{:.3g}'.format(dl_scorer))
# ディープラーニングのR2:0.718
PyTrochで使うデータは、numpyからtensor形式へ変更し、CPUで計算するか、GPUで計算するかで異なってきます。予測結果をmatplotlibでグラフで書くためには、'tensor'形式からnumpyへ、GPUからCPUへ戻す必要があります。
これは1行で書けます。
y_pred_cpu = y_pred.to('cpu').detach().numpy().copy()
to('cpu')で、gpuからcpuモードに戻す
detach().numpy()で、numpy形式に戻す。
numpyに戻れば、後は、ランダムフォレストの結果とディープラーニングの結果を合わせてグラフにするだけです。
DeepLearningとRandomForestの結果の比較
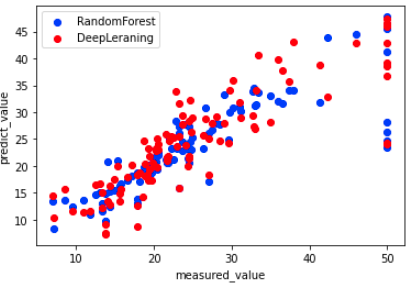
Pytorchのディープラーニングの設定が適当なので、あまり精度はよくありませんが、これでランダムフォレストとディープラーニングの比較の可視化ができました。