はじめに
Capsule Network(CapsNet) は、ディープラーニング界のゴッドファーザーの一人、Geoffrey Hinton を中心に提案された新しいニューラルネットワークです。
この記事では、CapsNet の概要を説明するとともに、その PyTorch 実装と手書き数字の分類(MNIST)におけるテスト結果を紹介します。
実装はこちら → GitHub
Capsule Network (CapsNet)
CapsNet のモチベーション
近年、画像解析の中心技術といえばやはり畳み込みニューラルネットワーク(CNN)でしょう。CNN は、画像分類、物体検出、セマンティック・セグメンテーションなど、ビジョン系のタスクで新たな state-of-the-art を次々と打ち立ててきています。
CNN は、特徴マップの畳み込みを行う畳み込み層と、特徴マップの縮小を行うプーリング層の繰り返しです。CNN はプーリング層によって translation-invariance を獲得していますが、その代償として異なる特徴間の相対的な位置関係などを学習することが難しくなっています。CapsNet は CNN が抱えるこうした問題を解消するものとして提唱されました。
従来のニューラルネットワークとの違い
従来のニューラルネットワークにおいては、ネットワークの各ノード(ニューロン)は一つ下のレイヤに属するすべてのニューロンの出力を受け取り、それらに重みパラメータをかけて合計したものを出力します。つまり、各ニューロンの出力はスカラです。
それに対して、CapsNet においてはニューロンが ”Capsule” に置き換えられます。 Capsule も一つ下のレイヤに属する すべての Capsule の出力を受け取るという点では同じですが、それぞれの Capsule の出力はベクトルであるという点で、従来のニューロンとは異なっています。
下の図では、従来のニューロンと Capsule の違いをまとめています(画像は GitHub:CapsNet-Tensorflow より引用)。
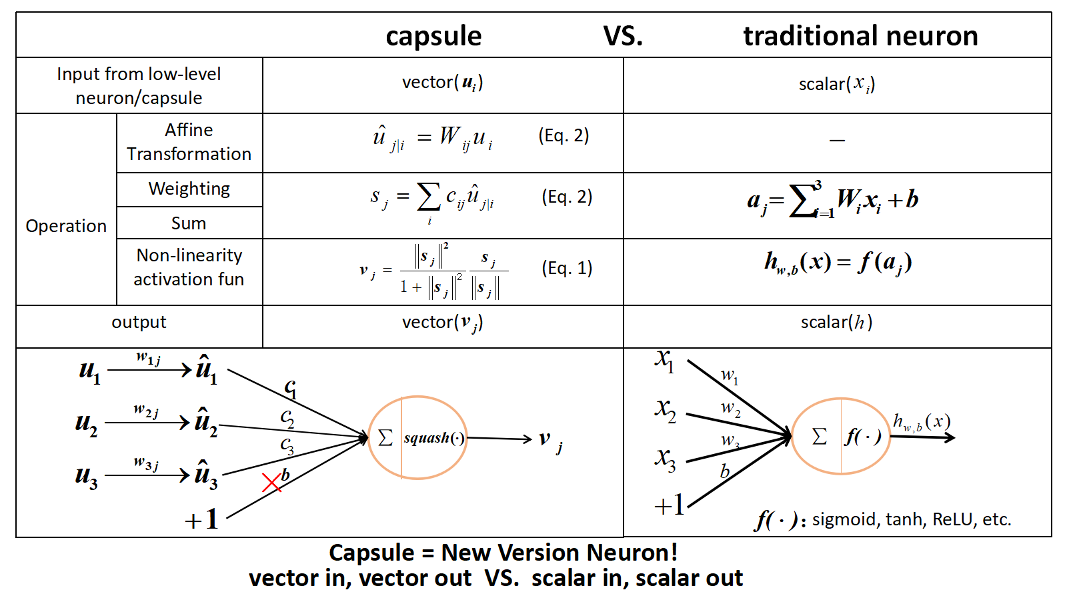
Capsule が表現するもの
Capsule が出力するベクトルは、その大きさが「特徴」の存在確率を表し、その方向が「特徴」のプロパティを表しています。表現する特徴は Capsule ごとに異なります。例えば、人の顔を認識する CapsNet があるとすれば、ある Capsule は「目」という特徴を表現し、別の Capsule は「鼻」という特徴を表現するという具合です。
特徴のプロパティは、例えば、その特徴(物体)の方向やスケール、照明条件など、特徴の状態のことを言います。スカラを保持するニューロンからベクトルを保持する Capsule へと移行することによって、特徴の存在だけではなく、その特徴がどのような状態にあるのかを表現することができるようになります。
上でも述べたとおり、Capsule は一つ下のレイヤに属するすべての Capsule の出力を受け取るという点で従来のニューラルネットワークと共通しますが、CapsNet においては各特徴の状態を(出力ベクトルの方向として)明示的に表現した上で、より高次のレイヤの Capsule に伝達しています。これによって、低次の異なる特徴間の相対的な位置関係なども含めて、高次の特徴をより正確に学習することができると考えられます。
例えば、同じレイヤに属する異なる3つの 低次の Capsule は、それぞれ「鼻」、「口」、「目」の特徴を表現し、一つ上のレイヤに属する高次の Capsule は「顔」の特徴を表現するものとするとしましょう。低次のそれぞれの Capsule は「鼻」、「口」、「目」の方向やスケールをベクトルの方向として表現します。それらのベクトルを受け取った「顔」という特徴を表現する高次の Capsule は、それらの顔のパーツの相対的な位置関係などを手掛かりに、「顔」という物体の特徴を学習することができるという具合です(鼻はだいたい顔の真ん中、口は顔の下の方、目は顔の上の方に左右一つずつある、など)。
CapsNet をより詳しく
CapsNet では、このような**異なる特徴間の階層構造(ヒエラルキー)**を学習するために様々な工夫が施されています。論文以外にも、Mediumへのポストなどでも非常にわかりやすく解説がされています(ので、ここでは書きません)。
CapsNet の PyTorch 実装
コードは GitHub で公開しています。
timomernickさんによる実装からフォークさせていただきました。コードの大枠はそのままですが、squashの実装に誤りと思われる箇所があったので issue を出すとともに私のレポジトリで修正をしておきました。また、学習結果とテスト結果を TensorBoard で見られるようにしたり、学習パラメータをコマンドラインから指定できるようにしたり、クラス構造を(私なりに)理解しやすいように分割・統合したりと若干の修正を加えました。
手書き数字分類(MNIST)のテスト結果
以下、私の PyTorch 実装でのテスト結果です。論文でもベンチマークとして使われている手書き文字の分類データセット(MNIST)で CapsNet の学習とテストを行いました。
AWS の GPU ノードでとりあえず50エポックほど学習させてみました。最適化には論文どおりに Adam を使用しましたが、いろいろ試行錯誤した結果、この実装では学習率は0.01(論文では0.001)で精度が最も高くなりました。
分類結果
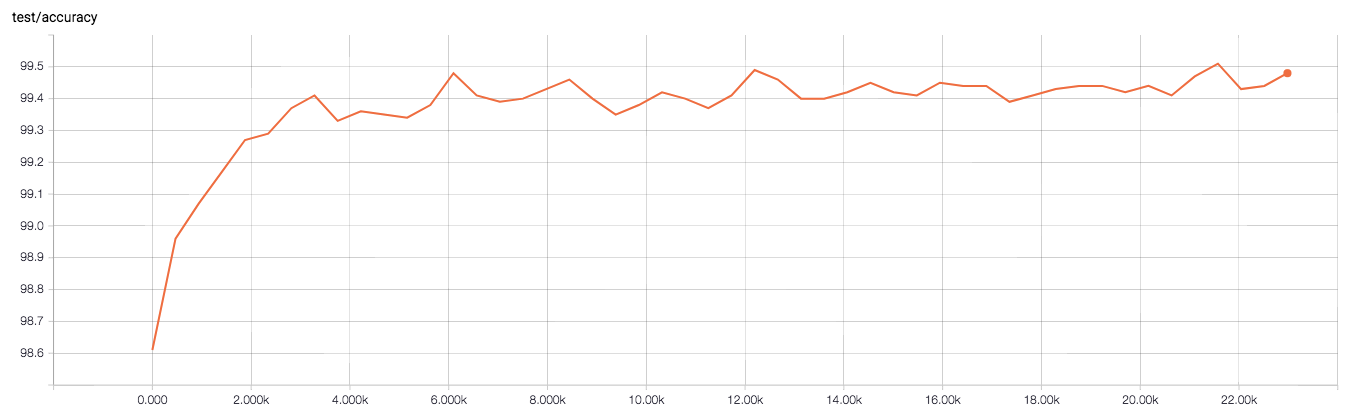
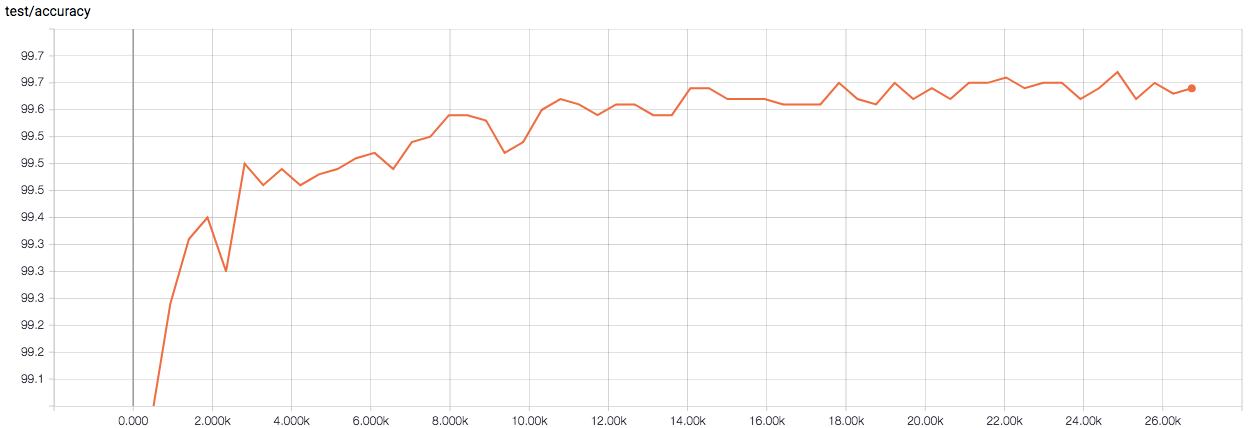
下図はテストデータにおける分類精度の推移です(横軸はイタレーション)。現状、最高精度で99.51%と、論文での精度(99.75%)には及びませんでした…。
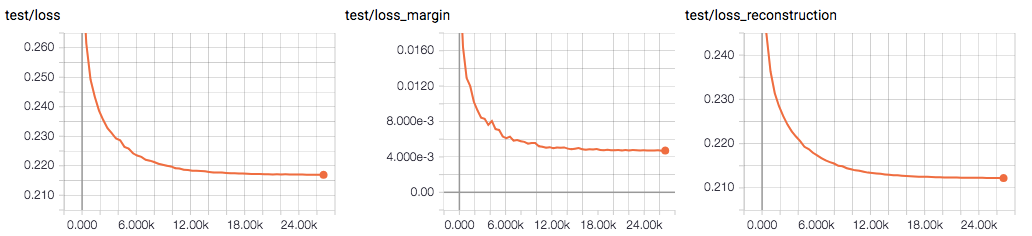
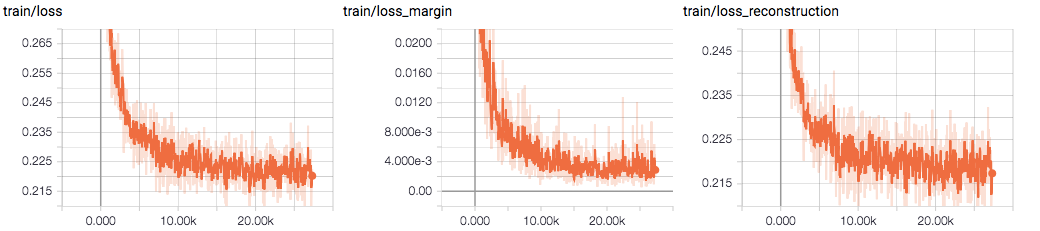
下図は訓練データに対する損失の推移です(横軸は同じくイタレーション)。CapsNet には数字の分類を行うのとは別に、オートエンコーダーのように入力画像を復元するパスがあります。分類タスクと復元タスクそれぞれで損失を計算しており、その和が CapsNet 全体の損失となります。
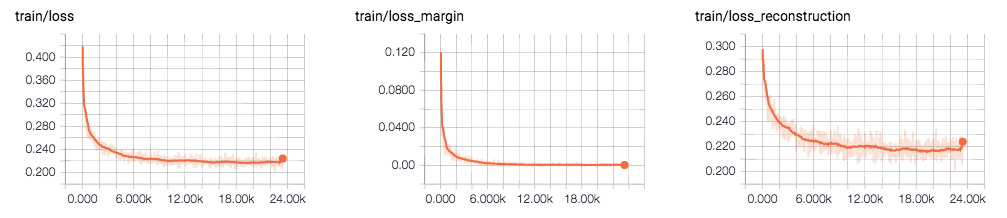
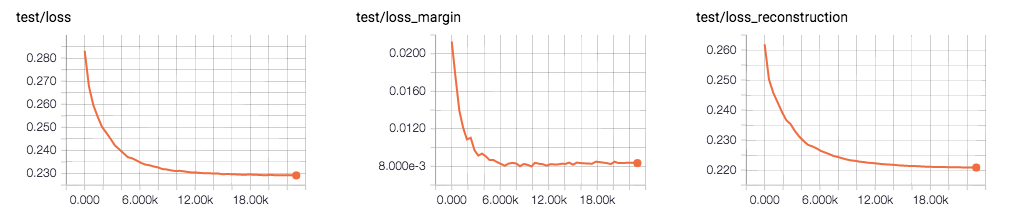
図において、左が CapsNet の全体の損失、中央が分類タスクに対する損失、右が復元タスクに対する損失です。また、下の図はテストデータに対する損失の推移です。分類タスクに対する損失(中央)がやや過学習気味に見えます。
入力の復元結果
CapsNet による入力画像の復元結果も紹介します。ランダムに選んだテスト画像128枚に対して復元を行いました。学習が進むにつれて数字の特徴を捉えた復元ができている様子がわかります。

所感
論文ほどの精度はまだ再現できていないものの、CapsNet (と思しきもの)を実際に動かすことができました。コードと論文に違いがないかをもう一度確認し、論文の精度に近づけていきたいと思います。
CapsNet は、現状 MNIST のような比較的単純な画像での実証にとどまっており、物体検出やセマンティックセグメンテーションのようなより複雑なタスクに適用するためにはまだ工夫が必要になりそうです。しかし、CapsNet は従来のニューラルネットワークに代わるかもしれない新たなコンセプトを打ち出しており、今後、ビジョン系のタスクに膨大な応用や改善を生み出し得るものだと思います。Capsule 関連の新しい論文等、今後も注意して追って行きたいと思います。
追記
CapsNet の論文と実装が食い違っていたところを修正し、再度学習と評価を行った結果、テストデータに体する分類精度が99.67%まで向上しました。
変更点は以下の2つです。
- 論文に記載の方法に従って、トレーニングデータに対して data augmentation を行った
- Routing において Capsule 間の結合重み係数 $c_{ij}$ の正規化処理を正しく修正した
- 2つ目の変更にともなって、学習係数を0.001まで小さくした
- 2つ目の変更にともなって、重み $W$ の初期化を一様分布からのサンプリングによって行うようにした
1つめ以外の変更点は、spikefairwayさんにGitHub上でご指摘いただきました。Routing プロセスは CapsNet の肝なのですが、ここが間違っていたことで大きく精度が低下していたようです。
分類タスクに対する損失がやや過学習気味だったのも改善されました。
学習を続ければもう少し精度が向上しそうです。
学習曲線
復元結果
