Databricksのワークフローはデータエンジニアリング、AI、データアナリティクスの処理からなるパイプラインを作成できる機能です。一部ワークスペースでif/elseの条件分岐のタスク機能がパブリックプレビューとなっているので早速試してみました。
注意
本機能はパブリックプレビュー中のものです
If/Else条件分岐タスクとは
If/Else条件分岐タスクは、以下のワークフローの中で赤四角で囲んだタスクです。タスクの条件式の判定結果により、それぞれ別のタスクが次に実行されることになります。

作り方
If/Else条件分岐タスクの作り方を見ていきましょう。
手順1: ワークフローの編集画面で[+Add task]ボタンをクリックすると一番下に[If/else condition]が出てくるのでこれを選択します。
手順2: タスクの情報を設定する画面で、Expressionのところに判定条件を設定します。[Browse dynamic values]をクリックすると、判定条件で使える各種の動的なパラメーターを確認することができます。各種情報を入力して[Create task]をクリックして作成完了です。
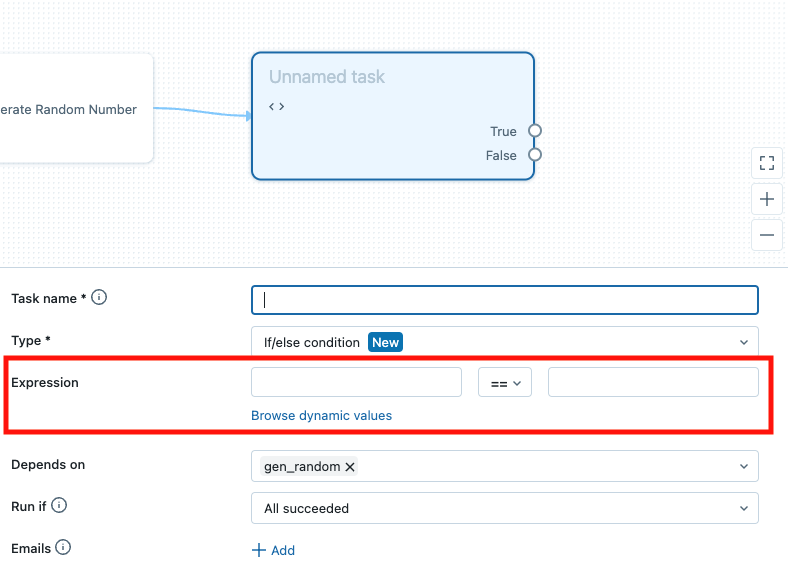
判定条件で使える動的な値のリスト

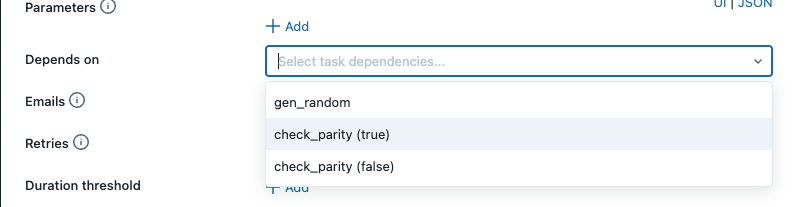
手順3: 下流のタスクを作成する際、依存するタスクとして、条件判定タスクの判定結果がTrueの場合と、Falseの場合を選択できるようになっているので、選択します。
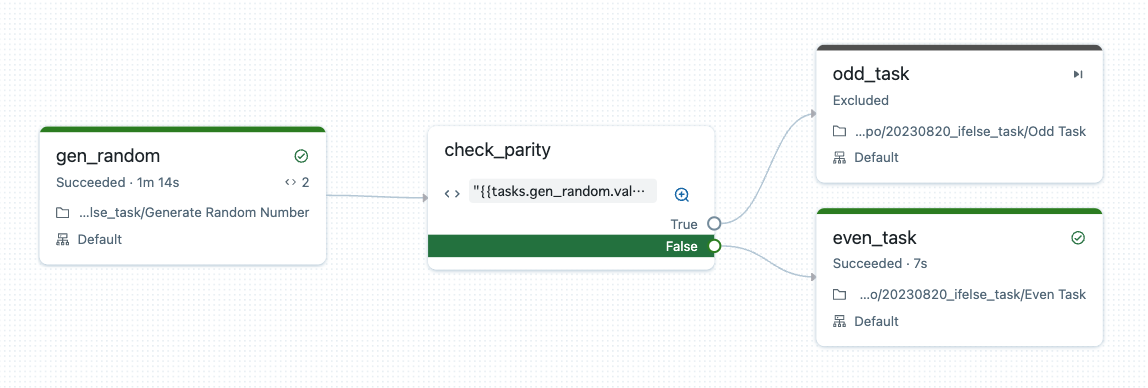
実行結果の例
他に良い例が思いつかなかったのでランダムに生成した整数が偶数か奇数かで処理を分岐させるワークフローを試しに作ってみました。
最初のタスクで以下のように整数を生成し、その整数が偶数かどうかをis_oddというタスク値に設定します。
import random
random_int = random.randint( 1, 100 )
dbutils.jobs.taskValues.set( key = 'my_int', value = random_int )
dbutils.jobs.taskValues.set( key = 'is_odd', value = ( random_int % 2 == 1 ) )
If/Else条件分岐タスクのExpressionで、{{tasks.<タスク名>.values.<タスク値名>}}の形式で、上流タスクで設定されたタスク値を参照できます。以下のようにis_oddがtrueかどうかで処理を分岐するように設定します。

このワークフローを実行すると、整数が奇数の場合はtrueの方のタスクが、偶数の場合はfalseの方のタスクが実行されることを確認できました。

活用例
If/Elseの条件分岐はパイプラインにとっては重要な機能になります。例えば以下のような場面で活用できそうです。ワークフロー機能がだんだんと充実していっていますね。
- AIモデルのメトリクスが基準値以下の場合に再トレーニングさせたい
- 日次のジョブに対して、月の最初の営業日だけ特別な処理をさせたい