PySparkでこういう場合はどうしたらいいのかをまとめた逆引きPySparkシリーズの基本操作編です。
(随時更新予定です。)
- 原則としてApache Spark 3.3のPySparkのAPIに準拠していますが、一部、便利なDatabricks限定の機能も利用しています(利用しているところはその旨記載しています)。
- Databricks Runtime 11.0 上で動作することを確認しています。
- ノートブックをこちらのリポジトリ からReposにてご使用のDatabricksの環境にダウンロードできます。
- 逆引きPySparkの他の章については、こちらの記事をご覧ください。
例文の前提条件
- SparkSessionオブジェクトがsparkという変数名で利用可能なこと
1-1 ファイルからデータフレームにデータを読み込む (入力)
spark.readオブジェクトを使って、ファイルからデータを読み込みます。
# 構文
df = ( spark
.read
.format(<フォーマット名>)
[.option(<オプションのキー>,<オプションの値>)]
.load(<ファイルパス>) )
# 例文
df = ( spark
.read
.format("csv")
.option("header","true")
.load("dbfs:/databricks-datasets/nyctaxi/tripdata/yellow/") )
1-2 カラムを追加する
withColumn()で、データフレームに新しいカラムを追加できます。
# 構文
df_2 = df.withColumn( <追加するカラム名>, <追加するColumnオブジェクト> )
# 例文
from pyspark.sql import functions as f
df_2 = df.withColumn("pickup_date", f.to_date("pickup_datetime"))
1-3 特定の条件にあてはまるデータを取り出す
filter()で、データフレームから、特定の条件を持つデータだけからなる新しいデータフレームを作ります。
# 構文
df_3 = df_2.filter(<データを絞り込む条件>)
# 例文その1
from pyspark.sql import functions as F
df_3 = df_2.filter( F.col("trip_distance") > 10 )
# 例文その2
df_3 = df_2.filter( "trip_distance > 10" )
1-4 データ件数を集計する
count()で、データフレームの中のデータ件数を表示できます。
# 構文
df_3.count()
# 実行結果
64708276
1-5 カラムを削除する
drop()で、指定したカラムを削除できます。
# 構文
df_4 = df_3.drop( <削除するカラム> )
# 例文
df_4 = df_3.drop( "pickup_datetime" )
1-6 データフレーム同士を結合する(join)
join()で、データフレーム同士を結合します。
デフォルトの結合方法は内部結合(INNER JOIN)です。
# 構文
df_5 = df_4.join( <結合相手のデータフレーム>, <結合条件>[, <結合方法>] )
# 例文
df_5 = df_4.join( df_code, df_4.rate_code == df_code.RateCodeID )
1-7 値ごとの件数をカウントして降順に整列する
groupby()で、カラムの値ごとに集約し、count()で件数を集計し、orderBy()で降順に整列します。
# 構文
df.groupby(<集計するカラム名>).count().orderBy("count", ascending=False)
# 例文
display( df_5.groupby("vendor_id").count().orderBy("count", ascending=False) )
実行結果
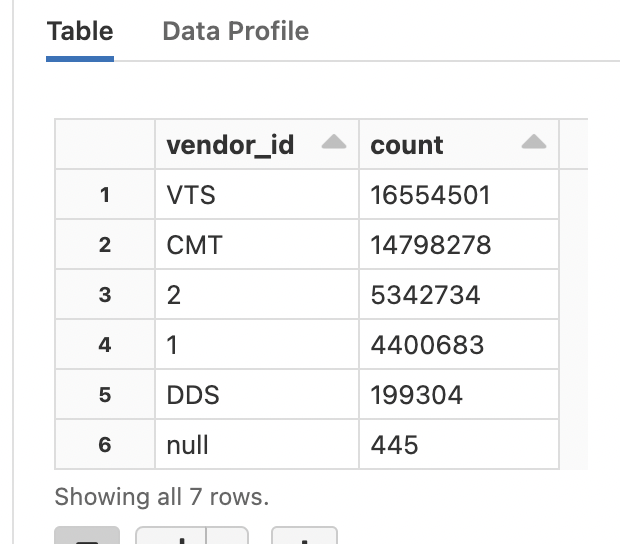
display()は、データフレームの中身を見やすく表示するためのDatabricks独自のメソッドです。
1-8 データフレームからデータを書き出す(出力)
データフレームのwriteインターフェースを使って、ファイルにデータを出力します。
# 構文
( df.write
.format(<フォーマット>)
[.mode(<書き込みモード>)]
.save(<ディレクトリパス>) )
# 例文
( df.write
.format("parquet")
.mode("append")
.save("/tmp/hoge/fuga") )
書き込みモードでは、すでにファイルが存在していた場合の動作を以下の中から指定します。
| 書き込みモード | 説明 |
|---|---|
| append | 既存のデータに追加します |
| overwrite | 既存のデータを上書きします |
| error or errorifexists | データが既にある場合はExceptionを投げます |
| ignore | データが既にある場合は処理を実行しません |