概要
Kaggle公式のPythonチュートリアル(https://www.kaggle.com/learn/python) を遊び感覚で受講してみたら意外と知らないPythonのTipsがちらほらあったので,振り返りがてらメモ代わりに残しておきます.
無料なのに,コースの質と量が大学の講義並ですごい.
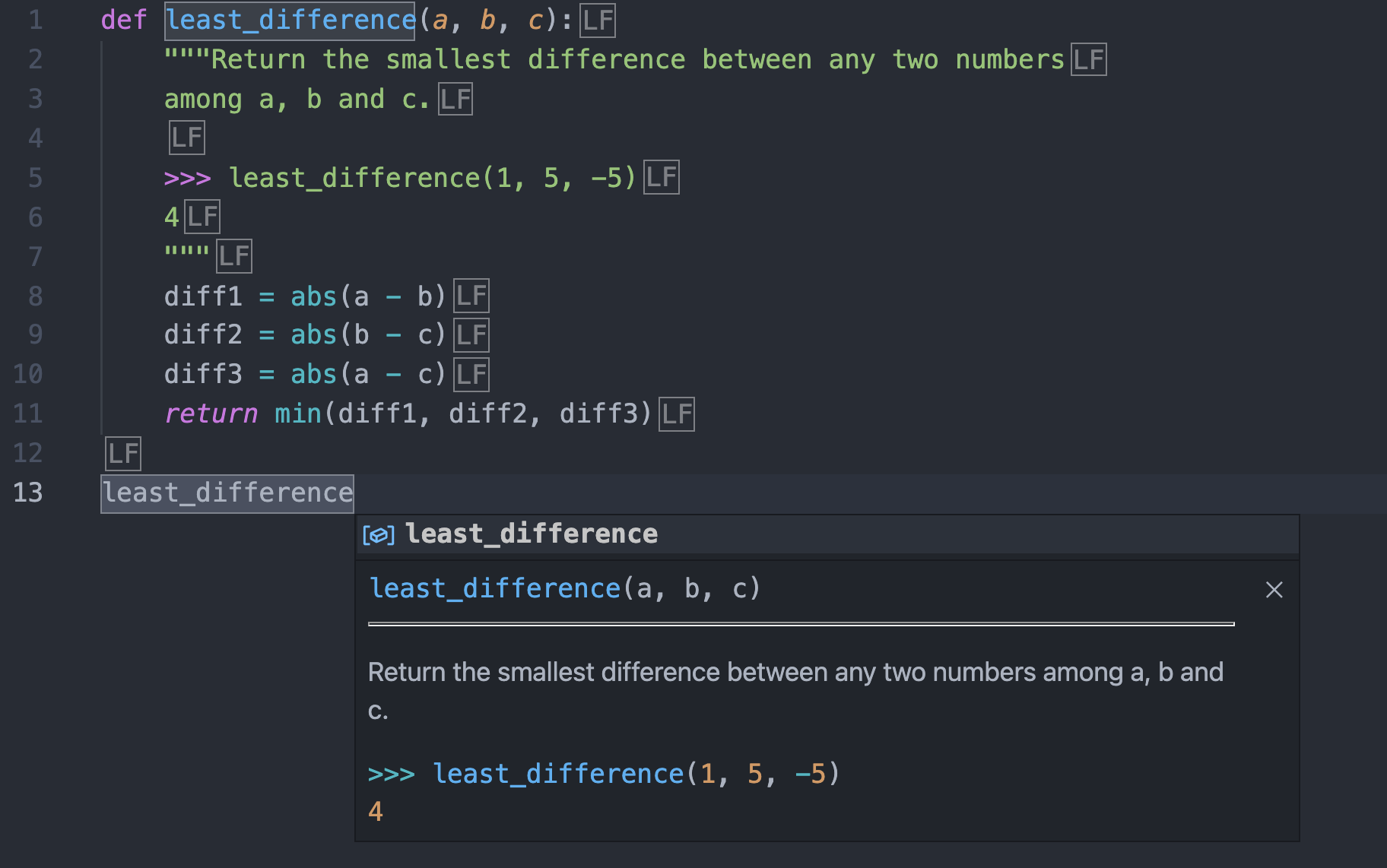
docstringで関数の説明が書ける(JavaDoc的な)
def least_difference(a, b, c):
"""Return the smallest difference between any two numbers
among a, b and c.
>>> least_difference(1, 5, -5)
4
"""
diff1 = abs(a - b)
diff2 = abs(b - c)
diff3 = abs(a - c)
return min(diff1, diff2, diff3)
# help(least_difference)の説明として表示される
VSCodeでサジェスト/マウスオーバーしたとき表示される説明文にもなる
boolean以外をbooleanに変換したときの挙動
print(bool(1)) # 0以外はTrue
print(bool(0)) # 0はFalse
print(bool("asf"))#""(中身のない長さ0の文字列)以外はTrue
print(bool("asf"))#""はFalse
# 一般に,中身が空の時系列データ (strings, lists, listsやtuplesに類するもの)は"Falsey"(Falseっぽいという専門語)
# それ以外は"Truthy"(Trueっぽいという専門語)
intに対するbooleanの演算
a=1
b=2
a or b#1
b or a#2
a and b#2
b and a#1
0 or a#False
式の評価はbooleanとして行う.Pythonのand/orは短絡評価.
式全体がTrueの場合は最後に評価した値が,Falseの場合はFalseが出てくる.
booleanに対するintの演算
a=b=c=True
a+b+c#3
booleanにint演算をするとintで帰ってくる
文字列関係
大文字小文字
claim = 'Pluto is a planet!'
# 全部大文字にする
claim.upper()#'PLUTO IS A PLANET!'
# 全部小文字にする
claim.lower()#'pluto is a planet!'
文字列探索
# マッチした場合一番最初のインデックスを返す
claim.index('plan')#11
# 先頭の部分文字列マッチ
claim.startwith('Pluto')#True
左寄せ・センタリング・右寄せ
testlist=['a','bbb','ccccc']
for t in testlist:
print(t.ljust(5))
# a
# bbb
# ccccc
for t in testlist:
print(t.center(5))
# a
# bbb
# ccccc
for t in testlist:
print(t.rjust(5))
# a
# bbb
# ccccc
文字列の条件
# 以下,空文字はfalseとなる
# 含まれる文字が全てアラビア数字
'12345'.isdecimal()#True
# 含まれる文字が全て「数字を表す文字」
'四'.isnumeric()#True
# 含まれる文字が全て英数字
'm0ssyc4t'.isalpha()#True
# 文字列全体が
# 全部Ascii文字
'this is ascii'.isascii()#True
'†hîs îß asçîî'.isascii()#False
文字列の長さについて
文字列長はエスケープ用の特殊文字を無視して考える.
"It's ok" と'It\'s ok'が同一の文字列をさす(identical)ことを考えるとわかりやすい.
len("it's ok") #7
len('it\'s ok') #7
フォーマット文字列関係
str.format()を使うのが一般的だが,個人的にはf-stringがコンパクトで好み.
ただし,f-stringはpython3.6〜でないと使えないので注意.
who_made_perl='Larry Wall'
who_made_python='Guido van Rossum'
print('Who made perl is {}.'.format(who_made_perl))#Who made perl is Larry Wall.
print(f'Who made python is {who_made_python}.')#'Who made python is Guido van Rossum.'
このフォーマッティングは,公式によると以下の書式設定子の書式に従って解釈される.
format_spec ::= [[fill]align][sign][#][0][width][grouping_option][.precision][type]
# fill ... alignする時,埋めるのに使う文字.デフォルトは多分ホワイトスペースになる.
# align ... 左詰め,中央寄せ,右詰めを選択可能.それぞれ<,^,>
# sign ... 符号を付けるかどうか."+"で正負かかわらず符号をつけ,"-"で負数のみ符号を付け," "で負数のみ符号をつけ,正数先頭には空白を入れる
# "#" ... 数値型の先頭に0xとか0bみたな進数表記を付ける.
# "0" ... ゼロパディングする
# width ... 最小の幅.
# grouping_option ... 千の位のセパレータに何を使うか.","か"_"が選べる.
# .precision ... 小数点以下の表示される桁数.
# type ... データの表現について.出力を2進数,8進数,10進数,16進数にしたい場合,それぞれb,o,d,x(またはX)を用いる.
# 特殊な場合として,記数表記にしたい場合,e(またはE),
# 固定小数点表記にしたい場合,f(またはF),
# パーセント表示にしたい場合,%とする.
ライブラリインポート
インポートするモジュールクラスのatrribute名,method名はdir()メソッドで確認できる
import math
dir(math) #['__doc__', '__file__', '__loader__',...,'tau', 'trunc', 'ulp']
よく使うメソッドの便利引数
printメソッドはセパレータを変更できる
print(1, 2, 3, sep=' < ') #1 < 2 < 3
printメソッド呼び出し後に自動で入る文字はend引数で定義される.デフォルト引数はend='\n'であり,printメソッドを呼ぶ度に改行が入るのはこのため.
for i in range(4):
print(i)
# 0
# 1
# 2
# 3
これを応用して,print後に改行をさせないようにするにはend=''とすればよい.
for i in range(4):
print(i,end=" ")
# 0 1 2 3
maxメソッドはkey引数で指定したメソッドをmapできる
def mod5(num):
return num%5
max(100,51,14,key=mod5) #14
roundメソッドはndigits引数で指定した桁数で丸めれる
round(54321.12345,-2) #54300.0
複素数
a=12
a.imag #0
b=12+3j
b.imag #3.0
複素数を使って昔解いた
# x2を中央揃えする
x2 -= chuoux
y2 -= chuouy
# 90度回転
x3= -y2
y3 = x2
# 90度回転
x4= -y3
y4 = x3
雑すぎる.もしこうやって雑にやるにしても,最低限x3,y3のペアは構造体なりクラスなりにまとめて扱いたい.
修正後の結果はこちら.
# x2を中央揃えする
b-=chuou
# 90度回転
c=b*(1j)
d=c*(1j)
いい感じ.
おわりに
コースを全部履修した所,そこそこ立派な認定証がもらえました.
やったね!