TL;DR
Youtubeライブのコメントの感情分析を行うことで、単なる時間あたりのコメント数だけに比べてよりよい精度で"エモい"、"みどころ"の抽出を行うことができるのではないかという提案、実験です。
実際コメント数だけで見るよりも、精度が上がりそうという結果を得ることができました。
はじめに
前回私は、COTOHA APIをお借りして、自由な発想をしようと実用性の無い記事を書きました。
今回は、もう少し実用性や、応用性を考えた取り組みをしてみました。
序盤は背景の共有なので、飛ばしても特に問題は無いです。
YoutubeLiveとeスポーツ
皆様も度々お聞きになると思いますが、近年eスポーツ市場が発展してきています。このeスポーツ市場と切っても切り離せない関係にあるのが、Youtubeやその他媒体によるLive配信です。
従来のゲーム実況動画投稿と異なり、編集負担が少ない、コミュニケーションがとれる、"投げ銭"文化、まさにスポーツとしてリアルタイムで体験を共有できるなどの強みがあるためLive配信はeスポーツと同様に拡大していると考えます。ところが、このLive配信周りにはいくつかの問題点があります。
Live配信の問題点。
しかし、そんな強みのあるライブ配信にもいくつか問題点が存在します。
その中でも大きいものとして、視聴者の負担増、及びそれを利用する"盗人"の存在です。
配信側に負担の少ないLive配信は逆に言えば見どころを探す手間を視聴者側に押し付ける側面があります。そこに目をつけた一部の人が有名配信者の配信の切り抜きをして収益を得るといった問題が発生しています。
↓この記事は主題は違いますが、このあたりの問題について軽く書かれていて読みやすいです。
https://gigazine.net/news/20191216-youtuber-hired-youtuber-leech-off/
そもそも配信自体がゲーム会社の著作物を利用して収益を得ているためいろいろ難しいところはあると思いますが、Live配信市場等を考えると問題だと思います。
解決案?
この問題に対する一つの解決策は公式(本人)が、素早く切り抜きを作ってアップロードしてしまうことだと思います。
ところが、それができてないからこうなってるわけです。
なので、この切り抜き作成をいくぶんか自動化するモチベーションがここに生まれると考えます。
手法
自動ハイライト作成には様々なものなどが提案されていますが、動画自体を学習するものはデータセットが必要であったり、また、そこそこな割合が現実世界を写した動画をまずは対象にしており、そのままeスポーツの文脈に持ってくるためにはいくぶんか工夫が必要となると考えます。
そこで今回はライブ配信中のコメントに着目しました。
先行例
先行例にこのような記事がありました。この方はコメントから"草"という単語をキーワードにして見どころを抽出していました。しかし、この方がおっしゃってるように判定基準には疑問が残ります。そこで今回はこの判定基準をいくぶんか自然言語処理の力を借りてアップデートしようと思います。
コメントと感情と見どころ
ライブ配信の見どころとはどんなところかと考えてみると、"多く人の感情が動かされるところ"だと考えられます。
では、そのようなシーンでは何が予期されるかといえば、最も単純な例としてはコメントの数が挙げられると思います。
見どころでは「すごい」などの大量のコメントが流れるのは直感的にも明らかです。
そこでまずはこのコメントの数に基づいて見どころの分析をしてみようと思います。(しかし、後に述べますが、これだけでは不十分です)
対象動画
今回はEGSさんのスマパ! #48をお借りしようと思います。特に深く考えての選定ではなく、eスポーツ(スマブラ)であって、コメントストリームがオンになっていたため選択しました。
今回はなるだけ動画内容がわからないようなコメントを例に選択しますので、内容が気になった方は本家動画を見に行ってみてください。
コメントの取得
コメントの取得はこちらを参考にしました。
[PythonでYouTube Liveのアーカイブからチャット(コメント)を取得する(改訂版)]
(http://watagassy.hatenablog.com/entry/2018/10/08/132939)
めちゃくちゃ楽に取得できました。ありがとうございます。
こちらから取得した時間を秒数に直して適当に処理していきます。
時間あたりのコメント数による見どころ判定
動画時間がおおよそ10000秒だったので、適当に500分割(1区間20秒くらい)でヒストグラムを書いて見ます。

このピークは急激にコメントが増えているところなので、おおよそ見どころということができると思います。
誤判定された見どころ。
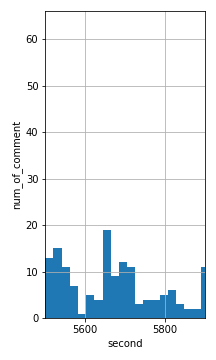
この部分に注目していただきたいと思います。この部分、5660秒付近にピークっぽいものが現れていますが、これはなんと配信が切れたことに疑問をいだいた視聴者がコメントを書き込んだことによるものでした。
(この小さいピークは元から見逃せよ、という考えもあるかもしれませんが、一般に大会ライブ配信などは最後に近づくにつれコメント数が増えるので、このピークが相対的に小さいかどうかを判定するのは常に可能とは限りません。)(時系列データって難しい)
こういった部分を取り除くために、コメントの感情値を利用することを考えます。
COTOHAによるコメント感情分析
漸くここまでたどり着きました。
COTOHAとはNTTさんによる自然言語処理を簡単にできるAPIです。
こちらのCOTOHA API PORTALから無料ユーザー登録をすると、無料ユーザーであっても1000/日もAPIを使用する事ができます。
COTOHAの登録〜トークン発行までは私の前の記事でも解説していますし、他の方の記事でも解説されているのでそちらを御覧ください。
今回はCOTOHA APIの感情分析を使用します。
def get_senti(txt):
header = {
"Content-Type":"application/json",
"Authorization":"Bearer "+[トークン]
}
datas = {
"sentence":txt,
}
r = requests.post(api_base+"nlp/v1/sentiment",headers=header,data=json.dumps(datas))
parsed = json.loads(r.text)
return parsed
こんな感じの関数を用いて、コメントについて感情分析をループで回します。
感情分析結果の集計
全体の一部であるため、少々わかりにくいコードですが、kouhoは解析対象のコメントが、区間ごとに区切って入っています。今回であればkouho[0]は先程でた5600〜5800秒のコメントが[コメント、秒数]の配列の形で入っています。
sentisにはコメントに対応する感情分析結果が[Pos or Neg,sentiment score]の形で入っています。
コードとしてやっていることは、ある地点を基準として過去20秒のコメント中でどのくらいの割合PositiveもしくはNegativeな感情を持ったコメントが入っているかを計算しています。
Negativeもカウントしているのは、性質上例えば応援している側が負けたり、いい意味で"やばい"といった単語を使うときを含めるためです。
buf = [0 for i in range(200)]
doubled = [0 for i in range(200)]
target = 0
for i in range(len(sentis[0])):
if sentis[target][i][0] == "Positive" or sentis[target][i][0] == "Negative":
base = 1
else:
base = 0.0001
buf[kouho[target][i][1]-5600] += base
doubled[kouho[target][i][1]-5600] += 1
for i in range(200):
if doubled[i] != 0:
buf[i] = buf[i]/doubled[i]
buf = pd.Series(buf)
rolled = [0 for i in range(200)]
for i in range(19,200):
temp = 0
temp_c = 0
for j in range(20):
temp += buf[i-j]
if buf[i-j] != 0:
temp_c += 1
if temp_c == 0:
rolled[i] = 0
else:
rolled[i] = temp/temp_c
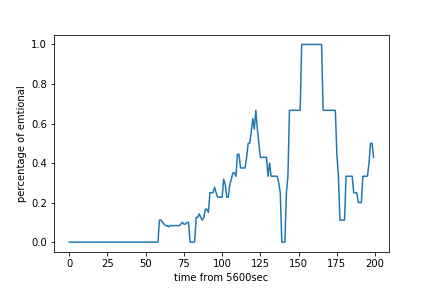
結果のプロット
コメント例
['Neutral', 0.5976078134278074] ['え?' 5646]
['Neutral', 0.2972885953707938] ['切れた' 5646]
['Neutral', 0.5971540523081994] ['おつ?' 5648]
['Positive', 0.5905005661402767] ['イケメンや' 5705]
['Positive', 0.6376353638242411] ['かっこいい' 5710]
['Positive', 0.5408603768859751] ['ガンの使い方上手いなぁ' 5766]
['Neutral', 0.30682113884940243] ['うめえ' 5795]
['Positive', 0.2976389932477489] ['きれいわかる' 5797]
['Neutral', 0.3140117003315527] ['うま' 5799]
(動画をお借りしてる関係上できるだけ内容に関わらないものを選んでるので、全コメントが気になる方は動画本家のご視聴をお願いいたします。)
この時間帯では、コメント数では5660付近がピークになっていましたが、それは真の見どころではなく、むしろ5800付近の方が見どころに近いことがわかりました。
結果2
もう一つの場面についても解析を行おうと思います。
対象としたのは9500〜9700秒付近
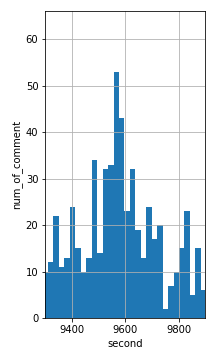
まさに優勝が決まった付近のようです。この場面のコメントに対しても感情分析を行いプロットをしてみます。
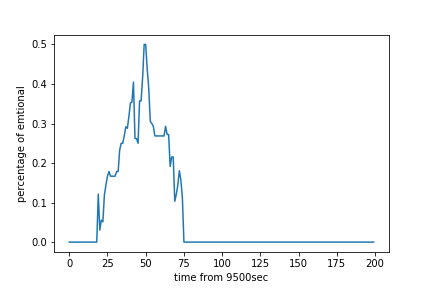
その結果が上のグラフのとおりです。どうやら9550秒付近が最もエモーショナルな瞬間のようです。
コメントを確認してみます。
['Neutral', 0.3140117003315527] ['えええええええええええええええ' 9554]
['Positive', 0.5873145362524327] ['うますぎ' 9554]
['Neutral', 0.5972752547353822] ['上しふと!?' 9555]
['Neutral', 0.2932173519717803] ['ああ~w' 9555]
['Neutral', 0.30920978004290844] ['うますんぎ' 9555]
['Neutral', 0.31430016829530116] ['うおおおおおおおお' 9555]
['Positive', 0.6049280950215463] ['完璧' 9555]
['Neutral', 0.31322001724349124] ['やべえええ' 9555]
['Negative', 0.7934200331057456] ['えげつない' 9555]
実際なんかが起こったっぽいです。エモいですね。
まとめ
COTOHA感情分析APIを利用することで、コメントベースでのYoutube Live見どころ判定の精度があげられそうという事がわかった。
課題等
- そもそもポジネガの割合でいいのか?Sentiment scoreの利用は?
- 一部の感嘆表現などがNeutralと判定されている。→ 品詞解析してなんらかの処理をすればもっと精度上がる?
- 時間窓のサイズは?
- "うますんぎ"等々口語的表現の一部は感情分析がうまくいってないことがある。
その他妄想。
リアルタイムで視聴者のエモーション値が見れたりするとそれだけで面白いかなとか思いました。
今回はコメントがたくさんつくような動画を対象としましたが、コメント数の少ない個人実況者向けなどとして、本人が喋ったことを文字起こしし、それに対して感情分析を行えば、"実況者の感情がうごいた"→"なにかおもしろいことがおきた"という事がある程度成り立つと思うので、そういったアプローチから見どころを切り出すなども考えられるかなと思いました。