はじめに
本記事は、Java Advent Calendar 2024の13日目の記事です。
Java8を主戦場に開発業務を実施してきましたが、そろそろ知識のアップデートをするべく、2024年12月現在の最新LTSバージョンであるJava21までで日々の業務ソースコードを書くのに有用そうな追加機能のキャッチアップをします。
なお、本記事の著者は大企業向け勤怠管理システムを開発するアプリケーションエンジニアです。
今回はすべてのアップデート内容を網羅するというよりも、特に実務に関わってきそうなアップデートに絞って記載します。
もし「これは押さえておいた方がいいよ」というものが漏れている、あるいは認識違いのものがありましたら、優しくご指摘をお願いいたします。
まとめ
個人的にいい!と思った新機能の順にまとめています。
記事の分量が大きくなったため、このまとめをご覧いただいて気になった箇所にジャンプしていただければと思います。
※これ以降の機能ごとの詳細はLTSバージョン順に記載しています
実務上ダイレクトに恩恵を受けられそうなものたち
- NPEが発生したときのメッセージがめちゃくちゃわかりやすくなった(Java14~)
- Switch式が使えるようになり、switch文の冗長さやbreak忘れなどのバグの温床化と決別できるようになった(Java14~)
- ListやSetにof/copyOfメソッドが追加され、不変なコレクションを作りやすくなった。ただしMapは絶対にofは使わずにofEntriesを使うべき
- 順序が担保されたCollectionクラス群にいい感じのスーパークラスが追加され、軒並みaddFirst/addLast/reversedなどが使えるようになった(Java21~)
- Sealedクラス/インターフェースが使えるようになり、継承関係を明示しやすくなった(Java17~)
- Recordクラスの登場でDTOクラスが驚異的にシンプルに書ける&安全に使えるようになった(Java16~)
- switch文の中でnullのcaseを書けるようになった(Java21~)
- instanceof判定時に変数を定義可能になり、型キャストを別途書く手間がなくなった
- if文での定義(Java16~)
- switch文での定義(Java21~)
- Files.writeStringで文字列をファイルに一気に書き込めるようになったのはとても便利な予感がしている(Java11~)
- その一方で、Files.readStringで一気に読み込む方は案外使いどころがない気がする(Java11~)
実務で効いてきそうだけどまだよさが理解しきれていないものたち
- 仮装スレッド(Java21~)
テンションは上がるが実務上は(まだ)使えないであろうものたち
- モジュール・システムで他ライブラリに対してpublicメソッドのカプセル化ができるようになった(Java9~)
使いどころがあれば使うかも・・・くらいなものたち
- JavaDoc上でCode Snippetが簡単に書けるようになった(Java18~)
- テキストブロック(Java15~)
- さらに簡潔になったtry-with-resources文(Java9~)
- privateなインターフェースメソッド(Java9~)
業務ロジックでは使いたくないものたち
- varを使った型推論(Java10~)を実務コードで使う日は来ないと思う
そのほか
キャッチアップの起点ページ
ありがたいことにJava12以降は主要な新機能に関するいい感じのまとめページが用意されているので、それをベースにしていきます。
Java9~11は残念ながら公式のまとめページがなさそうだったので、OracleのHelpCenterの中でまとめられていたページを参考にします。
- Java9~11:1 Java言語の変更(Java/Java SE/11/Java言語更新)
- Java12~17:JEPs in JDK 17 integrated since JDK 11
- Java18~21:JEPs in JDK 21 integrated since JDK 17
各バージョンの新機能などをもっと詳細に見る場合、
Java9は、 https://openjdk.org/projects/jdk9/ のURLで直接アクセスします。
Java10以降は、https://openjdk.org/projects/jdk/ のページから各バージョンの詳細ページへアクセスし、Featuresセクションを確認していくとよいです。
Java10以降は https://openjdk.org/projects/jdk/ に各バージョンのサマリページへのリンクがあります。
Java 9~11
Project Jigsaw(Java9~)
日本語では「モジュール・システム」と呼ばれています。大規模なアプリケーション開発のシーンで、アプリケーションやライブラリを継続的にメンテナンスをしやすくするための仕組みとして導入されました。
モジュール・システムの目的は大きく以下の2つです(公式ドキュメントの1つであるThe State of the Module Systemから抜粋)。
- Reliable configuration, to replace the brittle, error-prone class-path mechanism with a means for program components to declare explicit dependences upon one another, along with
- Strong encapsulation, to allow a component to declare which of its public types are accessible to other components, and which are not.
上記をOracleヘルプセンターの記事なども参考に意訳すると、
- プログラムコンポーネント(≒モジュール、ライブラリ)間の依存関係を明示的に宣言できるようにするため(Java8以前のクラスパスに代わる仕組み)
- プログラムコンポーネント内の特定のパッケージを外部へ公開(エクスポート)したり、逆にカプセル化(=非公開、自ライブラリに閉じた状態)したりするため
外部ライブラリとの依存関係や公開範囲の情報はmodule-info.javaの中で管理します。
まだモジュール化未対応のライブラリをモジュール・システムに内包したい場合の仕様や記載方法のルールも定義されています。
それぞれ詳しくは参考セクションの記事を参照してください。
所感
publicクラスへのライブラリ間アクセスを制御できるというのが、日々の開発業務の中では大きなメリットになりそうだと感じました。
モジュール・システム化していない場合、同一ライブラリ内の別パッケージに公開する目的でクラスのアクセス修飾子をpublicにすると、参照されている別ライブラリからもそのクラスにアクセス可能になり、結果的に意図しないアクセスを許容してしまうことになりました。
Javadocに記載したり、アノテーションを自作するなどでなんとか意図しないアクセスを回避したりしていたかなと思います。
それがモジュール・システムを導入することで、仕組みとして制御できるようになります。
参考
Convenience Factory Methods for Collections(JEP 269、Java9~)
各コレクションクラスにofというファクトリーメソッドが追加され、不変(immutable)なコレクションを簡単に作れるようになりました。
Java8でもCollecetions.unmodifiableXXXメソッドを使うことで、読み取り専用のコレクションを作ることができました。
以下はJava8で不変なListを作る例です。
List<String> originalList = new ArrayList<String>();
originalList.add("a");
originalList.add("b");
originalList.add("c");
final List<String> unmodifiableListUntil8 = Collections.unmodifiableList(originalList);
ただし、上記の場合は元となるリストを作ったうえでCollections.unmodifiableListに渡す必要があり、ロジックが冗長になりがちでした。1
Java9以降、Listの場合List.ofというファクトリ・メソッドを使う際、ofの引数にリストの要素を渡すことで、事前にListを形成せずに不変なリストを作ることができます。
final List<String> unmodifiableListAfter9 = List.of("a", "b", "c");
すでにオリジナルのリストがあり、それを不変にしたい場合は、List.copyOfが使えます。
final List<String> unmodifiableListFromOriginal = List.copyOf(generateOriginalList());
List.ofを使って作られたリストは、要素の追加・編集・削除いずれもできません。
Java8までと同様にリストそのものの再代入は可能なので、再代入も許容したくない場合は変数宣言時にfinalを付ける必要があります。
ただし、Listの要素自体が可変な場合までは守り切れません。
final List<MutableDto> unmodifiableListAfter9 = List.of(new MutableDto("1"), new MutableDto("2"),
new MutableDto("3"));
// これは実行時にUnsupportedOperationExceptionが発生する
// unmodifiableListAfter9.set(0, new MutableDto("再代入"));
// これはできる
unmodifiableListAfter9.get(0).setString("Dtoの中身のStringを再セット");
unmodifiableListAfter9.stream().forEach(dto -> System.out.println(dto.getString()));
Dtoの中身のStringを再セット
2
3
これも阻止したい場合の手っ取り早い方法としては、以下の2つかなーと思います。
- リストに渡すクラスにsetterを用意しない(基本的にnew時にsetするのみ)
- Java16で追加されたRecordクラスを利用する
あと、nullを要素に追加することができないので要注意です。
Set, Mapでのofメソッド
SetとMapにもofメソッドは追加されています。
Setはわかりやすいです。Set.of(要素a, 要素b, ...)です。List.ofと同様に大活躍の予感です。
それに比べてMapのofはカオスです。Map.of(要素aのkey, 要素aのvalue, 要素bのkey, 要素bのvalue, ...)だそうです。
Map<Integer, Integer> unmodifiableMap = Map.of(1, 3, 2, 2, 3, 5);
ちなみに、引数が奇数だとコンパイルエラーで怒られます。

さすがに使いづらすぎるので、ちゃんと現実的なメソッドが用意されています。Map.ofEntriesです。
引数にMap.entryメソッドを使う必要があるため、keyとvalueをセットで記載できます。
Map<Integer, Integer> unmodifiableMap = Map.ofEntries(
Map.entry(1, 3), Map.entry(2, 2), Map.entry(3, 5));
List.(copy)ofはCollecetions.unmodifiableListを完全に置き換える目的では使わない方がいい
Lists.(copy)ofはCollecetions.unmodifiableListを完全に置き換えることはできません。
一見似ていますが、目的が違います。
Collecetions.unmodifiableListは、文字通りunmodifiableです。それから作られたリストそのものへの変更はできませんが、元となったリストに変更が入った場合、それに追随してunmodifiableList側も書き換わります。
それに対してList.copyOfは、immutableです。作られたリストそのものへの変更もできませんし、仮に元となったリストに変更が入った場合でも、copyOfで作られたリストは影響を受けません。
private static void compareUnmodifiableAndImmutable() {
List<String> originalList = new ArrayList<String>();
// originalListには"a"という要素のみ格納する
originalList.add("a");
List<String> unmodifiableList = Collections.unmodifiableList(originalList);
List<String> immutableList = List.copyOf(originalList);
System.out.println("[1] -------------------");
System.out.println("unmodifiableList:");
unmodifiableList.stream().forEach(el -> System.out.println(el));
System.out.println("immutableList:");
immutableList.stream().forEach(el -> System.out.println(el));
// ここでoriginalListに要素を追加する
originalList.add("b");
System.out.println("[2] -------------------");
System.out.println("unmodifiableList:");
unmodifiableList.stream().forEach(el -> System.out.println(el));
System.out.println("immutableList:");
immutableList.stream().forEach(el -> System.out.println(el));
}
[1] -------------------
unmodifiableList:
a
immutableList:
a
[2] -------------------
unmodifiableList:
a
b
immutableList:
a
2回目の出力時、Collections.unmodifiableListから作られたリストのみ、要素が追加されているのがわかります。
また、Collecetions.unmodifiableListはリスト内のnull要素を許容しますが。Lists.(copy)ofはnullを許容しません。入れようとするとNPEが発生します。
所感
先に書いた通り完全に置換できるものではないものの、不変なコレクションを作るためのメソッドは基本的にof, copyOfを使えばよさそうです。
オリジナルのリストが書き換わったことに影響を受けたい場面はあまりなく、かつnullも許容するとあまりいいことはないので。
Guavaが使える環境の場合、GuavaのImmutableCollectionを利用するのとどちらがいいんだろう?は未確認です。
参考
varを使った型推論
Local-Variable Type Inference(JEP 286、Java10~)
Javaで型推論が使えるようになったというものです。
これまで変数宣言時に明確に型指定していた場所にvarという識別子を入れることで右辺からよしなに型を判断してくれます。
たしかに、varで宣言したものをいい感じに推論してくれています。コンパイル時もラインタイムでもエラーは起こりません。

Local-Variable Syntax for Lambda Parameters(JEP 323、Java11~)
型推論がラムダ式でも利用できるようになったらしいです。
(var a, var b) -> a + b;
(var a, b) (var a, int b) など、var以外の型指定方法と混在することはできないようです。
所感
うーん、業務ロジックで使うメリットは感じませんでした。
どう頑張っても可読性が下がると感じるので、自身が業務ロジック内で利用することはないですし、レビュー時にも使わないようにしてもらうつもりです。
ただ、個人用に使い捨てのツールをさくっと作るときには便利かもしれないです。
参考
Files.writeString, Files.readString(Java11~)
テキストファイルの一括書き込み/読み込みに使えるFiles.writeStringとFiles.readStringが追加されました。
Files.writeStringを使ったファイルの一括書き込み
Java11以前は、Files.newBufferedWriterなどで1行ずつ小分けにファイルに書き込んでいくしかありませんでした。
List<String> lines = List.of("a", "b", "c");
try (BufferedWriter bw = Files.newBufferedWriter(path)) {
for (String line : lines) {
bw.write(line);
bw.newLine();
}
} catch (IOException e) {
e.printStackTrace();
}
実行結果
Java11以降は、以下のように、指定したファイルをへの書き込みが可能です。
Path path = Path.of(".", "files", "write_test.csv");
String separator = System.lineSeparator();
// write_test.csvファイルを新規(既存の場合は上書き)作成
StringBuilder sb = new StringBuilder();
sb.append("a").append(separator).append("b").append(separator).append("c").append(separator);
try {
Files.writeString(path, sb.toString());
} catch (IOException e) {
e.printStackTrace();
}
// write_test.csvファイルに追記(StandardOpenOption.APPENDにより実現)
StringBuilder additionalSb = new StringBuilder();
additionalSb.append("d\td").append(separator).append("e").append(separator).append("f");
try {
Files.writeString(path, additionalSb.toString(), StandardOpenOption.APPEND);
} catch (IOException e) {
e.printStackTrace();
}
作成されたcsvファイル
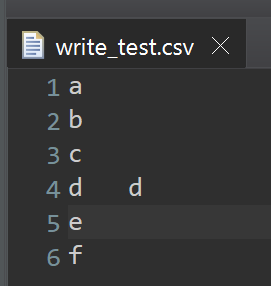
Files.newBufferedWriterと同様、OpenOptionを変更することで、ファイルの中身を空にしたりファイルそのものを削除することも可能です。
try {
// write_test.csvファイルの中身を空にする
Files.writeString(path, "", StandardOpenOption.TRUNCATE_EXISTING);
// write_test.csvファイルを削除
Files.writeString(path, "", StandardOpenOption.DELETE_ON_CLOSE);
} catch (IOException e) {
e.printStackTrace();
}
所感
Files.newBufferedWriterなどを使った既存の書き込み処理と比べてコードの量も減るし書き方もシンプルになると感じました。これは今後使っていきたい。
ただ、書き込みたい内容をStringBuilderなどでためておかなければいけないので、書き込みサイズが大きくなるとよろしくなさそうなのでそこだけ要注意ですね。
Files.readStringを使ったファイルの一括読み込み
Java8ではFiles.linesメソッドが使えましたが、Stream<String>が返ってくるのでそれをぐるぐる回す必要がありました。
try (Stream<String> lines = Files.lines(Path.of(".", "files", "test.csv"), StandardCharsets.UTF_8)) {
lines.forEach(line -> System.out.println(line));
} catch (IOException e) {
e.printStackTrace();
}
Files.readSringでは返り値がStringなので、そのままどん!と表示させるのには便利です。
1行ずつ処理したいのだけど・・・という場合、同じくJava11でStringクラスに追加されたlinesを併用することもできます。
try {
String contents = Files.readString(Path.of(".", "files", "test.csv"));
System.out.println(contents);
// Stringのlines()メソッドを使うことでStream形式で取得することも可能
Stream<String> lines = contents.lines();
lines.forEach(line -> System.out.println(line));
} catch (IOException e) {
e.printStackTrace();
}
以下のようなtest.csvを用意して上記の処理を実行してみます。

実行結果はこちら。Files.lines、Files.readStringいずれも同じ結果が返ってきました。
空欄や空行(途中も末尾も)もちゃんと出力してくれました。
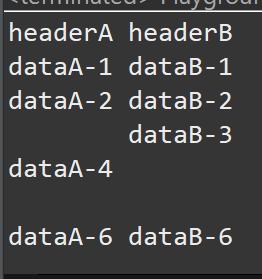
ただし、Files.readStringは巨大なテキストファイルの読み込みは想定していないようです。
ファイルサイズが巨大になる可能性がある場合は、Files.linesまたはFiles.readAllLinesを利用した方がよさそうです。2
所感
小さめのファイルをさくっと読み込んで一気に処理する場合は有効そうです。ツール作成などにも効果を発揮しそうです。
ただ、1行ごとに読み込んで何か処理をしたい場合にわざわざFiles.readStringを使うことはないかな・・・それならFiles.linesで充分です。
参考
Java 12~17
Helpful NullPointerExceptions(JEP 358、Java14~)
NPEが発生した時のメッセージが親切になったよ、というもの。
たとえば以下のロジックのgetC()がnullを返し、NPEが発生したとします。
package sample;
public class SampleClass {
public static void main(String[] args) {
// getA~getCはそれぞれClassA~ClassCを返す
String str = getA().getB().getC().getString();
System.out.println(str);
}
...
}
Java13以前はエラーログはこんな感じでした。
Exception in thread "main" java.lang.NullPointerException
at SampleClass.main(SampleClass.java:7)
行数がわかるので、getA() getB() getC()のどれかがnullで返ってきたらしいということはわかりますが、それ以上はログからは計り知れません。
開発中であればデバッグして一発で突き止められますが、運用中のユーザー環境などでこんなエラーが発生した場合、データベースの値などと突合して具体的にどのクラスでnullが返ってきているのかを推測していくしかありませんでした。
それがJava14以降はこんな感じになりました。
Exception in thread "main" java.lang.NullPointerException: Cannot invoke "sample.ClassC.getString()" because the return value of "sample.ClassB.getC()" is null
at sample.SampleClass.main(SampleClass.java:7)
・・・すごい!全部教えてくれている!
NPEの調査がとんでもなく楽になりそうです。
Pattern Matching for instanceof(JEP 394、Java16~)
instanceofの判定時に変数を定義可能になった&if文でそれを利用可能になった
instanceofの判定時に変数を定義できるようになりました。
これにより、判定をしたあとでの明示的な型キャストが不要になり、ソースコードの簡略化とヒューマンエラーによるキャストミスを防ぐことができるようになりました
if (obj instanceof String) {
String s = (String)obj;
... use s ...
}
if (obj instanceof String s) {
... use s ...
}
// if文の中で利用することも可能
if (obj instanceof String s && s.equals("piyopiyo")) {
...
// これはエラーになる
if (obj instanceof String s || s.equals("piyopiyo")) { // <= 2つめの条件でsがStringとは限らない!!
なんだかんだinstanceofは登場するので、明示的にキャストしなくて済むのは楽になりそうです。
Records(JEP 395、Java16~)
Recordクラスというものが使えるようになりました。
Recordクラスは平たく言うとシンプルなデータのまとまりを格納し取得するのに特化したクラスです。
これまで、いわゆるDTOライクなクラスは、標準ライブラリだけで書こうとすると以下のように書く必要がありました。
public class User {
private String id;
private String name;
private Date birthday;
public User(String id, String name, Date birthday) {
this.id = id;
this.name = name;
this.birthday = birthday;
}
public String getId() {
return id;
}
public String getName() {
return name;
}
public Date getBirthday() {
return birthday;
}
}
Recordクラスを使うと、以下のように置き換えられます。
public record User(String id, String name, Date birthday) {
}
・・・これだけ?!
拍子抜けするほどのシンプルさです。
Recordクラスでは、コンストラクタ、getter/setter、toString/hashCode/equalsを自動生成してくれるため、開発者が虚ろな目をしながらこれらを記載する必要がなくなりました。
利用方法は普通のクラスと大差ありません。Recordクラスをnewする際に宣言されているフィールドを引数として渡すだけです。
getterにあたるメソッドはフィールド変数名をメソッド名として利用することで取得できます。
public static void main(String[] args) {
User user = new User("userId001", "鈴木 太郎", getBirthday());
System.out.println("id: " + user.id());
System.out.println("name: " + user.name());
System.out.println("birthday: " + sdf.format(user.birthday()));
}
また、Recordクラスは不変(イミュータブル)です。
getterにあたる各メソッドは用意されていますが、setterにあたるものはありません。

「DBから取得した値のここだけ別途setしたいんだけど・・・」ということはできません。
新たなインスタンスを生成する必要があります。
DTOクラス、ドメイン駆動設計の値オブジェクトとしてかなりお世話になりそうです。
参考:現状だとちょっと惜しい点があり、改善予定があるらしい
Java Advent Calendar 2024 10日目に@kazu_kichi_67さんが書かれている下記の記事が、Recordクラスのちょっと惜しい点や今後の改善予定の紹介があって「なるほどな〜たしかに!」と思いました。
参考
Sealed Classes(JEP 409、Java17~)
クラスやインターフェースの継承先を限定することができるようになりました。
Sealed Classesと書いてありますが、インターフェースも対象です。
sealedは「密封された」という意味だそうです(参考)。
また、Sealed Classという英語名ですが、日本語読みは「シールクラス」のようです。
基本ルール
- Sealedクラスにする場合は
sealedという修飾子をつける- 必ず
permits句を指定し、継承先を定義する
- 必ず
- 継承先クラスには
finalsealednon-sealedのいずれかの修飾子をつける- final: これ以上継承できない(従来どおり)
- sealed: さらに継承先を限定する
- non-sealed: 継承先を限定しない
- permits句に列挙されるサブクラスは、親クラスと同一package内に配置しなければいけない
各クラスの関係性
今回は形(Shape)に関するクラス群をsealedクラスで表現してみます。
各クラスの関係性は以下。
Shape: 限定的に継承させる(sealed)
├ Circle: これ以上継承させない(final)
├ Quadrilateral: さらに限定的に継承させる(sealed)
│ └ Square: final
│ └ Rectangle: final
├ Polygon: 継承先を限定しない(non-sealed)
│ ├ Pentagon
│ └ ...
└ Triangle: ???(実装段階で決めきれていない想定)
各クラスの書き方
上記の関係性をもとに各クラスを実装すると以下のようになります。
// sealedを付けることで継承先を限定
// permits句でCircle, Quadrilateral, TriangleのみShapeクラスを継承できることを表現
abstract sealed class Shape permits Circle, Quadrilateral, Triangle {
}
// これ以上extendsできないようにするためには"final"をつける(従来通り)
final class Circle extends Shape {
}
// Quadrilateral(四角形)はSquareとRectangleだけが継承できる
abstract sealed class Quadrilateral extends Shape permits Square, Rectangle {
}
non-sealed class Polygon extends Shape {
}
// Polygonクラスを継承する場合はfinal/sealed/non-sealedはつけなくていい(final以外はむしろ怒られる)
public class Pentagon extends Polygon {
}
// sealedクラスの子クラスの場合、final/sealed/non-shealedのいずれかを付けないとエラーになる
class Triangle extends Shape { // <= エラー:The class Triangle with a sealed direct superclass or a sealed direct superinterface Shape should be declared either final, sealed, or non-sealed
}
// Circle, Square, Triangle以外はShapeを継承できないため、エラーが発生
final class Star extends Shape { // <= エラー:The type Star extending a sealed class Shape should be a permitted subtype of Shape
}
Sealedクラスをしっかりと使うことで、より抽象クラスやインターフェースの意図を伝えやすくなるし、意図しない継承を防ぐことができます。
sealed修飾子を使うことで、親クラス/インターフェースを見るだけで継承先がわかるようになるのはコードリーディングが捗りそうです。
今後新規実装やリファクタリング時に利用していきたいです。
参考
より細かな仕様や他機能との組み合わせについては下記が詳しいです。
Switch Expressions(JEP 361、Java14~)
「switch式」という名前で発表されていますが、このアップデートのサマリは大きく以下の3点だと感じました。
- switch文に加えてswitch式というものが利用できるようになり、値をダイレクトに返せるようになった
- switch文・switch式ともにcase文の中で複数の条件を列挙することができるようになり、case文を書く行数も文字数も短縮できるようになった
- switch文・switch式ともにアロー構文が使えるようになり、意図せぬフォールスルーを起こしがちだった
case L:の構文を使わなくてよくなった
switch文とswitch式の違い
- switch「文」なので、処理を実行する。if「文」的な。そのため値を返さず、
breakやreturnで処理を後続に送る役割を果たす - switch「式」なので、式の評価結果として何らかの値を返す。値を返すときは
yield文を使う- 値を返すので、変数に代入したり、return句にそのまま入れることができる
- yieldは「生み出す」という意味があるみたいです
以下は「ユーザーのロケールがカナダの公用語か」を返すメソッドを3パターン書いています。
boolean isOfficialLanguageOfCanada(UserLocale locale) {
boolean result = false;
switch (locale) {
case EN:
case FR:
result = true;
break;
case JA:
case ZH:
result = false;
break;
default:
System.err.println("Unexpected locale: " + locale);
result = false;
}
return result;
}
boolean isOfficialLanguageOfCanada(UserLocale locale) {
boolean result = switch (locale) {
case EN, FR -> true;
case JA -> false;
default -> {
System.err.println("Unexpected locale: " + locale);
yield false;
}
};
return result;
}
boolean isOfficialLanguageOfCanada(UserLocale locale) {
return switch (locale) {
case EN, FR -> true;
case JA -> false;
default -> {
System.err.println("Unexpected locale: " + locale);
yield false;
}
};
}
アロー構文とcase文でのカンマ区切りの活用(switch式・switch文 共通)
上述の例ですでに使っていますが、switch式でもswitch文でもアロー関数を使うことができるようになっています。いくつかお作法があります。
- 右辺が1行の場合は
{}やyieldは省略可能(アロー構文なので) - Enumの検査をする場合、すべての列挙子をcaseで挙げるか、default句を書く必要がある
-
case L:で書く場合は警告は出るものの許容されていた。アロー関数ではコンパイルエラーになる
-
以下は アロー構文、case L:共通で使えます。3
- 複数の条件に対して同じ結果や処理をする場合、カンマ区切りでの列挙が可能
所感
これまで「caseに応じて異なる値を返す」という処理を(今となっては冗長な)switch文で書いたり、意図せぬフォールスルーを避けるために敢えてif文で書いたり・・・としてきましたが、今後はほぼswitch式を使っていくことになりそうだなーという感じがします。switch文はif文とどちらが読みやすいかで、使用頻度がさらに落ちそう。
また、その際はアロー構文での分岐を徹底し、switch文のスリム化と意図せぬフォールスルーを確実に潰すことの両取りをしていきたいです。
私自身もswitch文、switch式問わずcase -> Lの書き方を使うし、レビュー時にも指摘していこうと思います。
あとEnumのswitch式をアロー構文で書くとき、defaultは考慮漏れを防ぐために基本的には使わずにすべて列挙する方に倒した方がよさそうだなと感じています。
今回例に出した「カナダの公用語か否か」であればdefaultでもOKかもしれませんが、それでもUserLocaleで管理する言語が増える、かつカナダの公用語が増える可能性はゼロじゃないと思うので、やっぱり危険な感じがします。
実装段階で処理を止める意味で例外をスローするとかでなければ、defaultは使わずに実装していくのがよさそうです。
こんなの↓とかはもう撲滅していく所存。
boolean isOfficialLanguageOfCanada(UserLocale locale) {
boolean result = false; // なんとなくfalseな初期化
switch (locale) {
case FR: // え、`FR`のとき本当にtrueで大丈夫なんだっけ??とつい疑って読んで無駄に疲れるやつ
case EN:
result = true;
break;
case JA:
result = false; // あれっbreakは?!・・・あ、case文の1番最後かあ・・・てなるやつだし、このあとさらにcase文が追加されていったときのことを思うと一抹の不安があるやつ
}
return result;
}
boolean isOfficialLanguageOfCanada(UserLocale locale) {
return switch (locale) {
case EN, FR -> true;
case JA, ZH -> false;
default -> throw new IllegalArgumentException("Unexpected locale: " + locale);
};
}
参考
Text Blocks(JEP 378、Java15~)
3つのダブルクオーテーションで囲むことで、複数行にわたる文字列を一気に書けるというもの。
以下のような文字列を書いて出力してみました。
String textBlock = """
hogehoge
fugafuga(tab)
fugafuga(2spaces)
piyopiyo
""";
System.out.println(textBlock);
hogehoge
fugafuga(tab)
fugafuga(2spaces)
piyopiyo
改行やタブ、スペースなどが入力内容そのままにコンソールに出力されました。
ちなみに、ダブルクオーテーションと同行に文字列を書こうとすると怒られました。
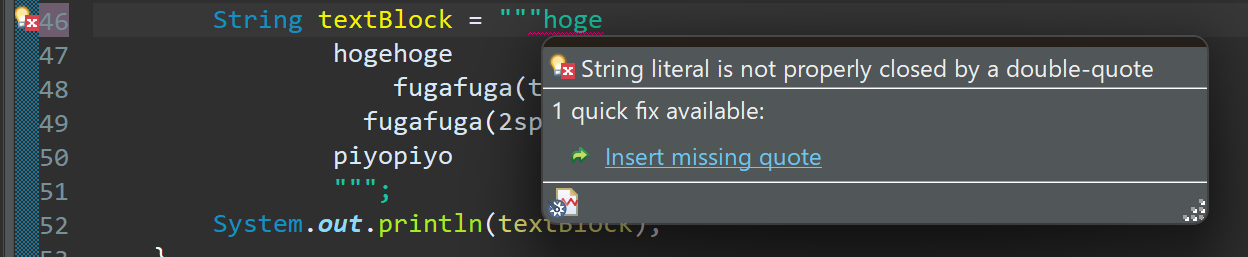
公式の例ではjson, SQL, HTMLなどが取り上げられていました。
ちなみにJavaDoc内で試してみましたが、さすがにだめでした。
所感
書いたものそのまま出力できるという特性はたしかに大きな武器で、エスケープ処理が必要な文字列を記述するのにすごい威力を発揮しそうです。
HTMLなど、インデントがあることでかなり視認性が上がる文字列もインデントそのままに記述できるのは便利です。
ただ、実務上こういった記述をしたいと思う場面はあまり思いつかないです。
視認性を上げる目的でStringBuilderでappendしていたようなものが、一部移行できるかもしれないなあとは感じました。
参考
Java 18~21
Pattern Matching for switch(JEP 441、Java21~)
instanceof判定時の変数定義がswitch文でも利用可能になった
前述のとおり、Java 16でinstanceofの判定時に変数を定義できるようになり、判定後の明示的な型キャストが不要になりました。
Java21以降、このinstanceof判定時の変数定義がswitch文でも使えるようになりました。
static String getTitle(AbsClass absClass) {
String title = "unknown";
if (obj instanceof ClassA classA) {
title = classA.getTitle();
} else if (obj instanceof ClassB classB) {
title = classB.getTitle();
} else if (obj instanceof ClassC classC) {
title = classC.getTitle();
} else {
title = absClass.getDefaultTitle();
}
return title;
}
static String getTitle(AbsClass absClass) {
return switch (absClass) {
case ClassA classA -> classA.getTitle();
case ClassB classB -> classB.getTitle();
case ClassC classC -> classC.getTitle();
default -> absClass.getDefaultTitle();
};
}
instanceofの判定時の変数定義がif文で利用できるようになっただけでもかなりソースコードがすっきりしたと感じましたが、switch文にも展開されたことで、さらにシンプルかつ分かりやすく書けるようになりそうです。4
switch文でnullの判定ができるようになった
Java 20まではswitch文でnull判定をしようとするとNPEが出るため、以下のようにロジックを分ける必要がありました。
static void testFooBarOld(String s) {
if (s == null) {
System.out.println("Oops!");
return;
}
switch (s) {
case "Foo", "Bar" -> System.out.println("Great");
default -> System.out.println("Ok");
}
}
Java 21以降は、nullの判定をswitch文の条件に追加できるようになります。
static void testFooBarNew(String s) {
switch (s) {
case null -> System.out.println("Oops");
case "Foo", "Bar" -> System.out.println("Great");
default -> System.out.println("Ok");
}
}
これはすっきりする&nullの場合がぱっと見でわかりやすくなります。
今後よくお世話になりそうです。
Record Patterns(JEP 440、Java21~)
if文でのinstanceof判定時にレコードクラスを使用しやすくなりました。
public static void main(String[] args) {
User user = new User("id-001", "鈴木 太郎", getBirthday(2000,3,1));
printUserInfo(user);
}
private static void printUserInfo(Object obj) {
if (obj instanceof User user) {
System.out.println(user.id() + ": " + user.name() + "(" + user.formattedBirthday() + ")");
}
}
private static void printUserInfo(Object obj) {
if (obj instanceof User(String id, String name, Date birthday)) {
System.out.println(id + ": " + name + "(" + format(birthday) + ")");
}
}
instanceofにマッチした後の処理はかなりすっきり書けます!
ただし、Recordパターンマッチングの記述ルールには以下の制約がありそうです。
- Recordクラス内で宣言されているフィールドをすべて明記する必要がある
- Recordクラス内で実装されたメソッドを呼び出すことはできない
Recordクラスの中でさらにRecordを持っている場合のパターンマッチング
1つ前のUserクラスにchildというフィールドを追加します。childもUserクラスで表現します。
public record User(String id, String name, Date birthday, User child) {
}
public static void main(String[] args) {
User user = new User("id-001", "鈴木 太郎", getBirthday(2000,3,1), new User("id-002", "鈴木 花子", getBirthday(2000,6,15), null));
printUserInfo(user);
}
private static void printUserInfo(Object obj) {
if (obj instanceof User(String id, String name, Date birthday, User child)) {
System.out.println(id + ": " + name + "(" + format(birthday) + ")");
System.out.println("[child]" + child.id() + ": " + child.name() + "(" + format(child.birthday()) + ")");
}
}
childフィールド内の各データへのアクセスは、通常のレコードクラスの各データ取得と同様の書き方でできました。
Recordクラスの中でさらに別のRecordを保持し、そのRecordの中には列挙型があり・・・といったさらに複雑なパターンの場合には、パターンマッチングなどともうまく共鳴して、さらに真価を発揮しそうです(が、ちょっとまだキャッチアップしきれてません)。
所感
レコードクラス内の変数があまり多くない場合は、すっきり書けるし使いやすかもしれません。
ただ、変数が多くなってくると、instanceofの後で明記しなければならないフィールドが多くなり読みにくくなる予感がします。
今のところ、実務での利用頻度はあまり高くならなさそうです。
Recordを使いこなせて来たらより有用性がわかるかな。
参考
Virtual Threads(JEP 444、Java21~)
仮装スレッド
まだキャッチアップ中。
参考URLなどを参考にキャッチアップを進めていきます。
所感
メッセージ送信機能などで有効活用できそうだなーとふんわり考えています。
参考
Sequenced Collections(JEP 431、Java21~)
いくつかのクラスについて、順序が担保されたCollectionクラス(Sequenced Collections)がスーパーメソッドとして追加されました。
具体的には以下の図の緑の箇所です。
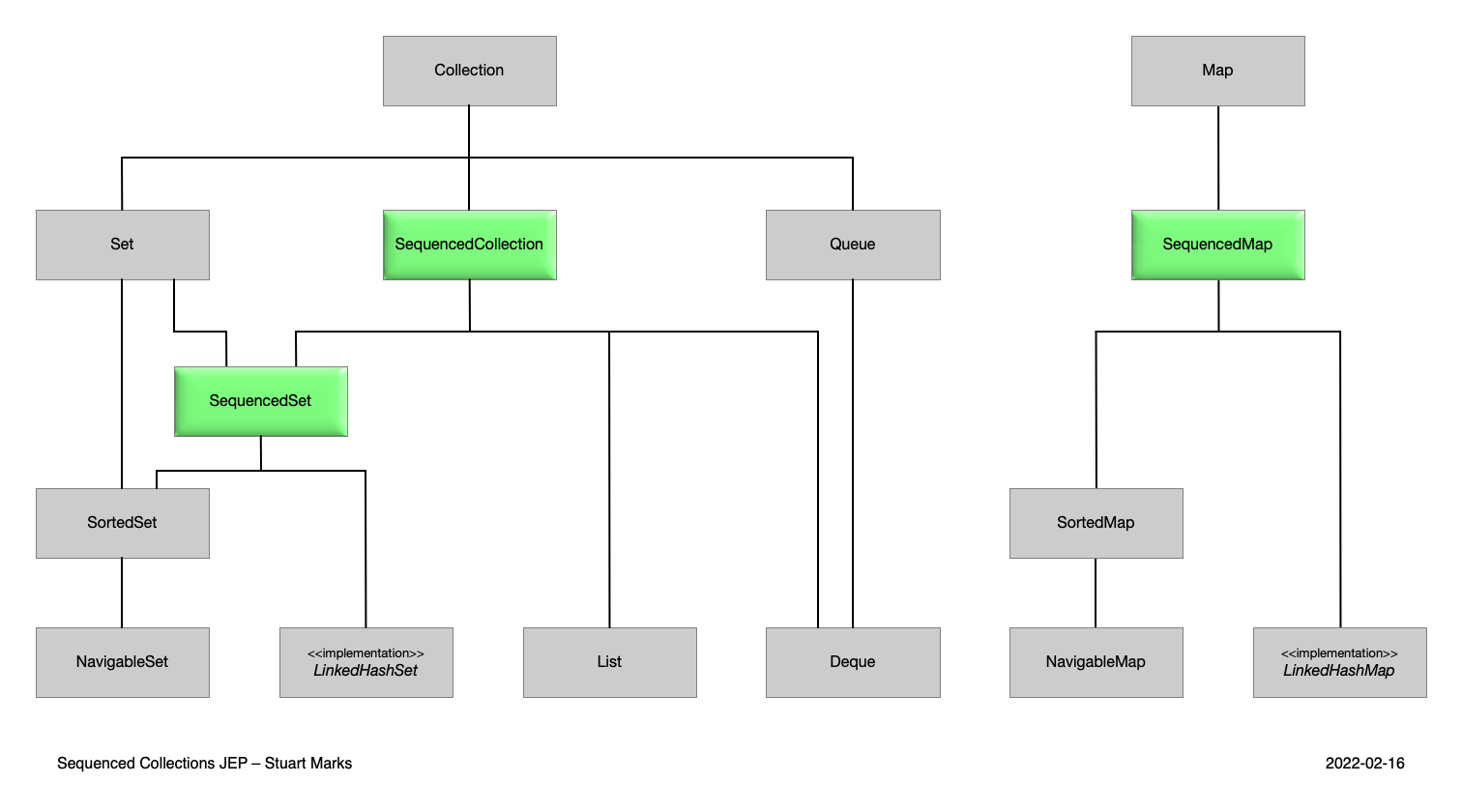
Sequenced Collectionsが追加される以前は、最初や最後の要素を取得するメソッドが各クラスで独自実装されており、そのメソッド名やメソッドの有無がバラバラでした。
| First element | Last element | |
|---|---|---|
| List | list.get(0) | list.get(list.size() - 1) |
| Deque | deque.getFirst() | deque.getLast() |
| SortedSet | sortedSet.first() | sortedSet.last() |
| LinkedHashSet | linkedHashSet.iterator().next() | // missing |
Sequenced Collectionは以下のメソッドをサポートしているため、その子クラスたちからはすべて以下のメソッドを通して要素の取得などができるようになりました。
interface SequencedCollection<E> extends Collection<E> {
// new method
SequencedCollection<E> reversed();
// methods promoted from Deque
void addFirst(E);
void addLast(E);
E getFirst();
E getLast();
E removeFirst();
E removeLast();
}
interface SequencedMap<K,V> extends Map<K,V> {
// new methods
SequencedMap<K,V> reversed();
SequencedSet<K> sequencedKeySet();
SequencedCollection<V> sequencedValues();
SequencedSet<Entry<K,V>> sequencedEntrySet();
V putFirst(K, V);
V putLast(K, V);
// methods promoted from NavigableMap
Entry<K, V> firstEntry();
Entry<K, V> lastEntry();
Entry<K, V> pollFirstEntry();
Entry<K, V> pollLastEntry();
}
LinkedHashSetから逆順のstreamを取得するのが大変だったのが、
linkedHashSet.reversed().stream()とするだけで取れるようにもなりました。
今回のインターフェース追加に伴って、順序が担保可能で変更不可のCollectionを作成可能な以下のメソッドが追加されました。
- Collections.unmodifiableSequencedCollection(sequencedCollection)
- Collections.unmodifiableSequencedSet(sequencedSet)
- Collections.unmodifiableSequencedMap(sequencedMap)
所感
Collectionクラス群で軒並みaddFirst/addLast/reversedなどができるようになるのはうれしいです。
ただ、順序が担保されたコレクションはList以外多用していないので、実質使うのはListに対してばかりになりそうな予感はします。
参考
UTF-8 by Default(JEP 400、Java18~)
ファイルの読み書きの文字コード指定がない場合のデフォルトがUTF-8に変更されるようです。
LinuxなどUTF-8をベースにした環境であれば問題ないが、Windows環境の場合は注意が必要です。
関連するシステムプロパティ
-
-Dfile.encoding=COMPAT:JDK17以前のアルゴリズムを使って文字コードを判断する。下位互換するためにはこの引数を入れておくとよさそう -
-Dfile.encoding=UTF-8:デフォルト文字コードをUTF-8とする
公式にはこれら2つしかサポートされていないとのこと。
所感
文字コードは基本的に指定しているのであまり問題にはならなさそうです。
万が一文字コード指定をしておらず、デプロイ先がLinux、実装しているローカル端末がWindowsの場合などはハマる可能性があるので頭の片隅においておこうと思います。
参考
Code Snippets in Java API Documentation(JEP 413、Java18~)
@snippetというタグをJavaDocの中で使えるようになりました。
これまでは<pre>{@ code ... }</pre>で囲んでコードのスニペットを書く必要がありましたが、{@snippet : ... }だけで書けるようになりました。
記法や併せて使える小技は公式や参考URLに記載したページで確認可能です。
所感
JavaDoc内でコードスニペットを書きやすくなったなという印象。
共通メソッドなどで利用例を書くときなどに役立ちそうです。
参考
おわりに
なかなかに読まれる方の精神力を試す分量になってしまいました・・・
しかしながら、自身の学習になりました。
今後も「あ、これもよさそうだった!」というものがあれば適宜追加していきたいと思います。
-
Listの作り方はいくつかあるので、originalListを別の変数として定義しなくてもいい実装方法はあります。また、
unmodifiableListUntil8への再代入を許容する場合は、unmodifiableListUntil8を使いまわすことでoriginalListを宣言する必要はなくなります ↩ -
このどちらを使うかについては、各行の処理がシンプルな場合は
Files.lines、そうでなければFile.readAllLinesで書くと可読性が上がるのではと思います。 ↩ -
同じswitch文/switch式の中で
case: Lcase -> Lの併用はできません。 ↩ -
instanceofを並べて分岐させるロジックの是非は議論の余地が大いにあるものの、熟成された実務コードにはこういった条件分岐が存在しているのもまた事実です・・・ ↩