この記事は株式会社ビットキー Advent Calendar 2022 19日目の記事です。
Workspace & Experience Product Circle所属の @moroball14 が担当します。
■これはなにか
- 循環的複雑度の高かったソースコードに対して、現状のロジックをほんのちょっと信じて単体テストを書いた
- テストが失敗した箇所の、ロジックを修正した
- そしたらみんなハッピーになった 🎉
というお話です。
どう進めたのか、だけ気になる方は「何をしたか」の章に進んでください!
■対象読者
- バグが多くて困っている
- バグを直す時間がなくて困っている
- バグを効率的に見つけられなくて困っている
こんな方々の役に少しでもなれれば幸いです!
■なぜやったか
チームは以下のような状況でした。
- 顧客からのバグ報告が多かった
- チームは疲弊していた
- 機能開発に充てる時間はそう多くなく
- 難解なソースコードと起きた事象をもとにバグの調査することにほとんどの時間を割いていた
ありがたいことに、弊社のプロダクトは多くの顧客に使われています。これは利用してくださる多くのお客様にいち早く機能を届けるためにデリバリ速度に重きを置いた成果だと思います。その一方で、不具合もそれなりに多く検知され、チームはバグの原因調査に多くの時間を費やしていました。
そういう状況もあってか、「ちゃんと時間をとって改善活動をやっていこう」とチームの方針として決まり、改善活動をすることになりました。
■どんな意図を持っていたか
僕らとしては、お客さまにプロダクトの価値を最大限感じてもらえるよう、バグはすぐにでも無くしたいです。
また、ずっとプロダクトの価値を提供し続けられるよう、長期的にバグの再発を防ぎたいとも思ってます。
そこで、
- 時間をかけずにバグを発見・解消すること
- 目先の対処で終わらず、長期的に見てもバグの発生を防ぐ対策をとること
という2点を重視し、改善活動に取り組むこととしました。
■何をしたか
タイトルの通り、循環的複雑度の高かったソースコードに対して単体テストを書きました。簡単な流れは以下の通りです。
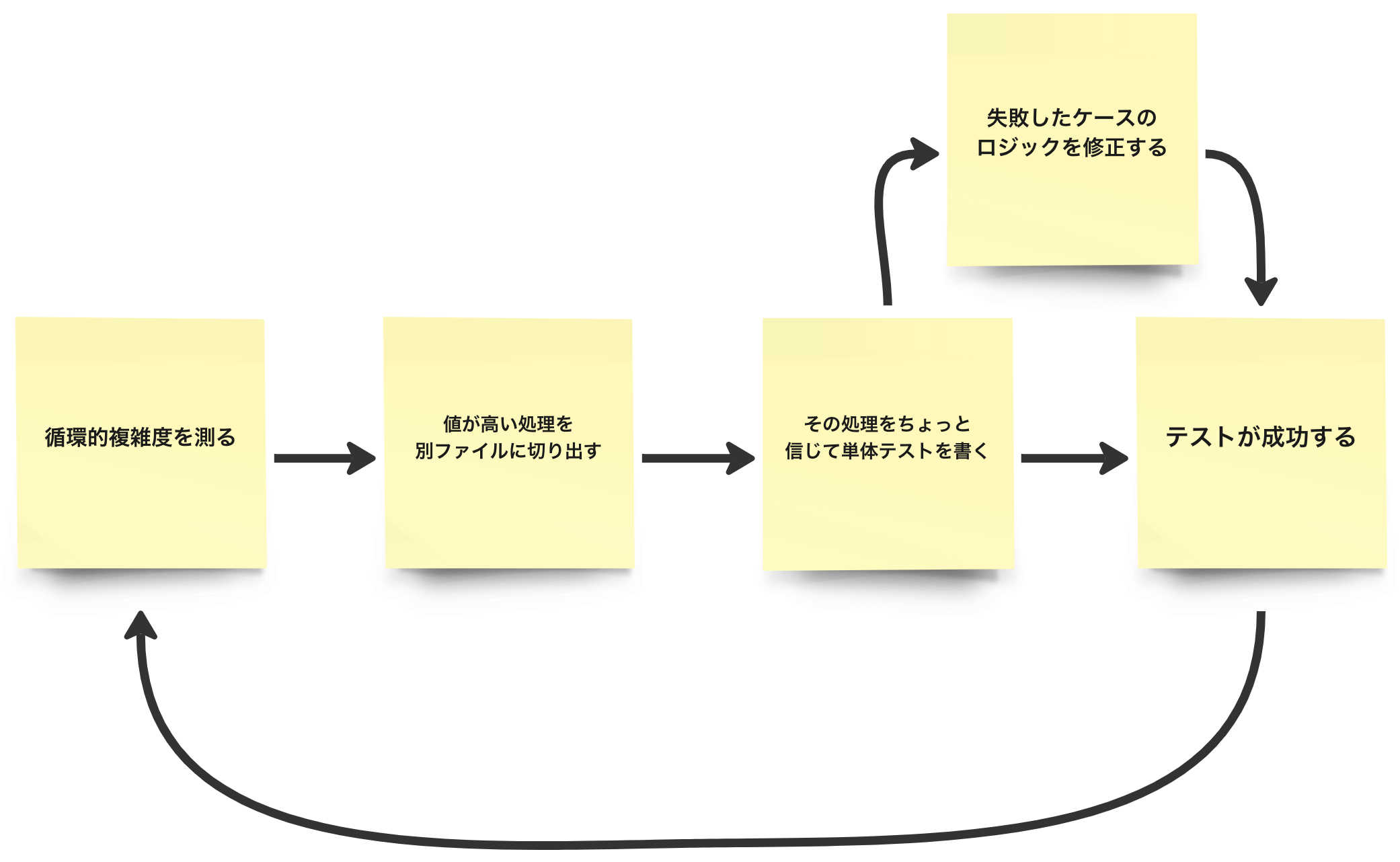
0. 【事前準備】バグ報告の集計
上述したフローチャートには載せていませんが、事前準備でバグ報告の集計をしておくと、どこに問題があるか、がすぐに可視化できます(可視化して、問題の所在を見つけます)。
弊社は、バグ報告をSlackワークフロー経由でGoogleスプレッドシートに貯めていたため、その情報をもとにデータポータルでまず可視化しました。
週次の推移を出したり
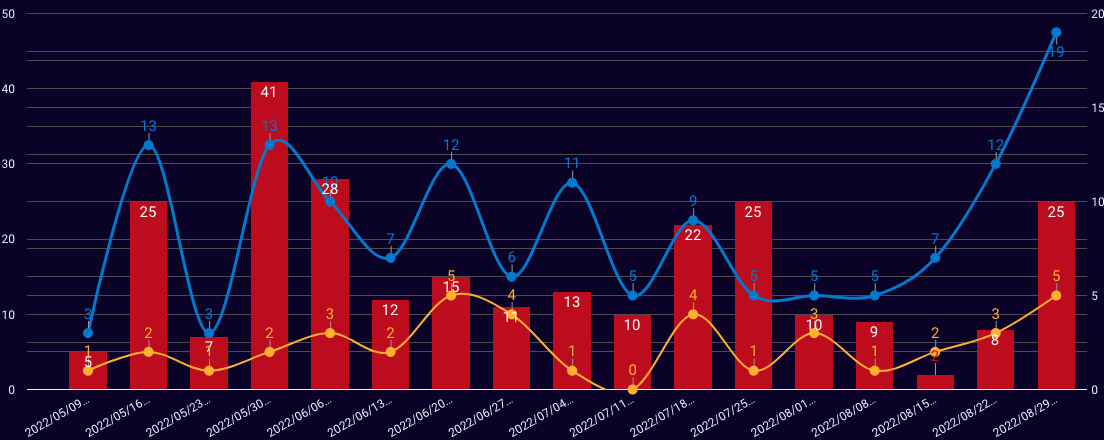
調査にかかった工数を機能別で出したり
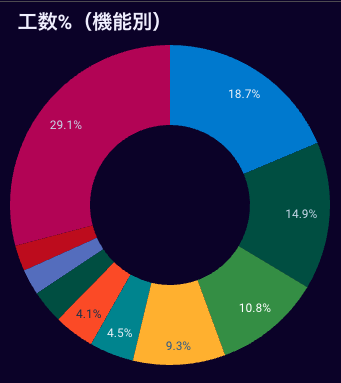
して、どこに問題があるかを分析します。
僕たちのチームは機能という軸で問題を切り分けると、問題の所在が見えてきました。また、その機能(以下、機能A)のバグ報告が多い原因を分析すると、ロジック不備によるバグが大多数を占めることが判明しました。
後述しますが循環的複雑度とバグには相関関係があります。また、現行のロジックが仕様通りかを確認・検証するには、いちいちロジックを目で追うのはつらく、単体テストを書くのが良さそうです。上記から、循環的複雑度の高いロジックに単体テストを書いたら、バグの発見・解消が効率良くできるのでは?と仮説を立て、実行することとしました。
では各ステップでどんなことをしたか、紹介していきます。
1. 循環的複雑度を測る
バグ報告の多かった機能Aの循環的複雑度を測ります。
◯循環的複雑度について
Wikipediaには
循環的複雑度(英: Cyclomatic complexity)とは、ソフトウェア測定法の一種である。Thomas McCabe が開発したもので、プログラムの複雑度を測るのに使われる
引用: https://ja.wikipedia.org/wiki/循環的複雑度
とあり、循環的複雑度の考え方では、条件分岐の数だけ複雑度が増すと言われています。
また、MATLABなどの製品を生み出しているアメリカのソフトウェア会社MathWorksによると
循環的複雑度が高くなると、プログラムは複雑になります。バグの混入リスクや発見されたバグの修正にかかる時間が増え、修正で新たなバグが購入する可能性も増えるため、再利用が困難になります。
循環的複雑度を計測し、低く保つことで、プログラムの可読性、保守性、移植性は高まります。また、テストに必要なテストパターンの数も減るため、カバレッジも上げることができます。
引用: https://jp.mathworks.com/discovery/cyclomatic-complexity.html
と循環的複雑度の重要性が語られています。
循環的複雑度と欠陥の関係性については以下のように語られています。
The results show that the files having a CC value of 11 had the lowest probability of being fault-prone (28%). Files with a CC value of 38 had a probability of 50% of being fault-prone. Files containing CC values of 74 and up were determined to have a 98% plus probability of being fault-prone.
引用: https://www.infoq.com/news/2008/03/cyclomaticcomplexity/
上記を表にしてみました。
| 循環的複雑度 | 障害の発生確率 |
|---|---|
| 11 | 28%(最も障害が起こりにくい) |
| 38 | 50% |
| 74 ~ | 98% |
循環的複雑度が11を超えると、循環的複雑度が高いほどバグが混入している確率が高まるのです。1~10よりも11が一番低いのは面白い結果ですね。
(引用元では、この計測方法は少し違うと言われていますが、大体合っているので今回は気にしないで進めます)
まとめると
- 循環的複雑度は、ソフトウェア測定法の一種で、プログラムの複雑度を測るのに使われる
- 循環的複雑度は、条件分岐が増えるほど高くなる
- 循環的複雑度が高いと、バグの混入確率が上がる
- 循環的複雑度を低く保つことで、コードの品質(可読性・保守性・移植性など)が上がる
です。
◯循環的複雑度の測定方法
計測対象はTypeScriptのプロジェクトだったので、ESLintで循環的複雑度によるエラーを出力していきます。
shellで実行するときは
$ eslint --rule 'complexity: [error, 38]'
や
$ npm run lint -- --rule 'complexity: [error, 38]'
など、お使いの設定に合わせてすぐに実行できます。
eslintrc.js で設定しているときは
rules: {
complexity: ['warn', {max: 38}]
}
のルールを追加します(38という値は任意ですが、前述した通り38を超えるとバグの混入確率が50%を超えてくると言われているため、ここでは設定しています)。
(今回はTypeScriptのプロジェクトだったため、ESLintを活用して測定しましたが、RubyではRuboCopを使用して測定できたりと、言語ごとにそれぞれ測定方法があるので、「(使用言語) cyclomatic complexity」などでググってみてください)
2. 循環的複雑度の高い処理を別ファイルに切り出す
循環的複雑度の閾値を38と設定して、実行すると以下のような出力が得られます。
warning Async arrow function has a complexity of 53. Maximum allowed is 38 complexity
これで出力された関数を別ファイルに切り出します(関数が一つだけのクラスを作成する、などのイメージです)。
今回はロジック不備によるバグをなくしにいくために、テストを書きます。データベースへのアクセスなどは、考慮に入れたくありません。そこを避けて関数を切り出すことで、ちょっと単体テストが書きやすくなります。
3. その処理をちょっと信じて単体テストを書く
次のステップは文字通り、切り出した関数の処理を少しだけ信じて、単体テストを書きます。
- ある程度は動いている
- ただ、循環的複雑度が高いので潜在的にバグが埋まっている可能性は高い
という状況から、現行のロジックはちょっと信じて、単体テストを書くと良いです。
信じすぎては、本来の目的であるバグを潰すことはできませんし、疑いすぎては手が止まってしまう恐れがあります。
ある程度感覚で進めつつ、実装者がいたら実装者と話しながら進めるのがおすすめです。どこまで書くかについて迷ったら、C0 = 100%まで書くこととしましょう(実際僕もC0 = 100%を目標として書きました)。
正直、ここは根気のいる作業になります。つらかったポイントは以下の2点です。
① 条件分岐が多く、読みづらいためC0 = 100%に到達することに少し手間取った
循環的複雑度の高いソースコードは、それなりに条件分岐などが多い、かつ読みづらいため、C0 = 100% に到達することがちょっと難しかったです。
僕個人は、サイドディスプレイに、Jestで出力されたカバレッジレポートを見ながら、次はこの分岐のテストを書こう、という感じでコツコツと進めてました。
② 仕様がわからない
自分自身仕様がわからない箇所に対してテストを書いているため、実装者と話をしながら進めていかなければいけない時もありました。周囲の協力がこのステップでは必須です。どんな意図を持っていたか、にも書いたように、時間をかけずにバグを発見・解消することを念頭に置いて改善活動を進めているので、この場合は「わからなかったらすぐ聞く」を徹底しました。
周囲にもわかる人がいない、といった時は、残っているドキュメントを漁る、ソースコードを読む、などして時間をかけて、仕様を理解してからテストを書くようにしました。本来担保してはならないテストを書いてしまっては、そもそも改善活動と矛盾する行動となってしまうため、ここは一定時間かけることを自分に許容していました。
4. 失敗したテストケースのロジックを修正する
テストコードを書いて、もし失敗していたらロジックを修正しましょう!
5. テストが成功する
テストが全て成功したら、また「1. 循環的複雑度を測る」に戻りましょう。
1 ~ 5を循環的複雑度を下げつつ繰り返すことで、バグの発見&解消のサイクルを何度も回します(僕は50 → 40 → 30 → 20と4サイクルをだいたい1週間で回しました)。
■結果どうだったか
7個のバグが潜在していました。
これほどわかりやすく結果に現れるとは思っていなかったので、自分でも驚きです。
また、チームからは
- 「安心して変更を加えることができるようになった ☺️ 」
- 「いつもバグが多くて検証に工数がかかっていたけど、今回はバグもなく検証が早く終わって本当にありがたい 🙌 」
と多方面から喜びの声をいただきました。
■改善活動を通して感じたこと
周囲の合意を得ることで行動がしやすい
どうして疲弊していたチームが改善活動を行えたかというと、「ちゃんと改善活動に時間割くよ」と周囲の合意を得ることができたことが大きな理由だと考えられます。
それまで口で改善していこうと言っても、実際は改善なんか行う時間もなく、時間がなければどう改善すればいいかを考えることもありませんでした。
- ちゃんと改善活動に時間を割く、という意思決定
- 周囲と「機能開発もするが、改善活動により多くの時間を割くよ」という合意をとること
この2点は、とても大事だと実感しました。
計測できる形にしておくことは大事
計測できるようにしておくことで、以下のメリットを得ることができます。
- 事実ベースで物事の判断を行うことができる
- 現状を容易に可視化ができる
- 可視化することで、問題の所在地がわかる
問題解決のステップとして、①どこに問題があるか②なぜそれが問題なのか③どうやって問題を解決するか、という進め方を個人としては意識しています。なので可視化して問題がどこにあるか、がわかるようになっている状態はとても大事でした。
正しく問題を認識できていないと、どれだけ打ち手を取っても、問題は一向に改善できません。今回の事例で言うとそもそも、単体テストを書こう、という打ち手にならなかったかもしれませんし、単体テストを書こうとなっても、そこまでバグが混入していないロジックに書いてしまっていたかもしれません。
計測できる形になっていてよかったと、改めて感じました。
単体テスト、みんなで効率的に書こう
まあ、こういうテーマの締めは、やっぱりこうなると思います。
カバレッジ100%を目指すのが必ずしも良いとは言えませんし、Googleは60% を「許容できる」、75% を「推奨できる」、90% を「模範的」な基準としています。壊れてほしくない箇所や、仕様が複雑になってしまう機能に絞って書くなど、効率的に書けると、単体テストの価値を存分に発揮できると思いました。
実際、今回効果を得られたことで、チームにも少しずつ、テストを書く流れができてきました。喜ばしい限りです。
■終わりに
今回は循環的複雑度 × 単体テストでバグを発見&解消していきました。この改善活動を進める中で、コードの品質に対する意識がガラッと変わりましたので、今後はコード品質を高める取り組みを継続的に続けていきたいです。
また、そもそものアーキテクチャが良くないよね?みたいな問題に対しては、この手法では対応できないです。そういった問題へもアプローチできるよう自分の中での武器を増やし、よりお客様へ価値を届けられるプロダクトに育てていきたいと思います。
最後までお読みいただきありがとうございました!!
20日目の株式会社ビットキー Advent Calendar 2022は、Home Product所属の @takuuuuuuu777 が担当します。お楽しみに!