この記事は、2025-03-27(木) に行なわれた、OutSystems User Group Tokyo のオンラインイベントで発表した内容を、あらためて解説する内容です。発表で利用したスライドは、Speaker Deck に公開しています。
【Online OSUG Meetup】AI活用最前線!OutSystems × AIで広がる開発の可能性
https://usergroups.outsystems.com/events/details/outsystems-inc-tokyo-presents-online-osug-meetup-aihuo-yong-zui-qian-xian-outsystems-x-aideguang-garukai-fa-noke-neng-xing/
【Speaker Deck】発表スライド
https://speakerdeck.com/moriyan/outsystems-azure-nowen-zi-qi-kosisabisuwomobairuapurideshi-uhua?slide=4
文字起こしサービスと AI
AI 活用と言えば「生成 AI を中心とした話」が主流な 2025年春に、文字起こしサービス(音声認識サービス - 音声情報を文字列情報に変換するサービス)を、AI 活用話のネタとして取り上げたのは、次の2つの理由によります。
- 十年以上前から iPhone の Siri や Amazon の Alexa などの形で身の回りに普及し、いまでは、スマホや Windows 11 の標準の文字入力機能としても普通に使えるようになった、枯れた印象すらある音声認識は、機械学習や自然言語処理といったれっきとした AI 技術の産物のひとつである。
- 最近になって、普及帯?の生成 AI の精度と速度が向上したことで、音声認識入力で得られた「聞き取りを間違っちゃった部分が含まれる雑な文章」を、「前後の文脈から意味が通るように正しい文章」に直してから使うというのが、とても現実的になった(つまり、以前より、音声認識で得られた文章が利用しやすくなった)。
OutSystems と AI
OutSystems での AI 活用の話に登場する「AI 機能」には、大きく分けて「開発者に作用する AI 機能」と「開発されたアプリの利用者に作用する AI 機能」とがあります。
【開発者に作用する AI 機能】
- ODC Mentor の App Generator/App Editor
- ODC Mentor の Code Quality や、O11 の AI Mentor Studio
- ODC/Service Studio のコードアシストやデータタイプ推定
- C# 拡張コードや JavaScript の開発に LLM を活用
【開発されたアプリの利用者に作用する AI 機能】
- AI Agent Builder を使った LLM 機能の組み込み
- SaaS の AI サービスや、デバイス AI 機能を用いる Forge など
本稿で紹介する、Azure の文字起こしサービスをアプリに組み込む話は、もちろん、2つめの「開発されたアプリ利用者に作用する AI 機能」の話です。
Azure の文字起こしサービス
本稿で取り上げるのは、Azure の音声サービス(Speech Service)にある、「リアルタイムの音声テキスト変換」というサービス。文字起こしサービスとしては、他に、音声ファイルからというのもありますが、本稿では触れません。
音声テキスト変換の概要 - 音声サービス - Azure AI services | Microsoft Learn
https://learn.microsoft.com/ja-jp/azure/ai-services/speech-service/speech-to-text
OutSystems アプリでこの機能を使う、という観点では、次のような特徴があります。
- 認識された文字列は、アプリ都合のタイミングで扱える。OS 標準の音声認識入力と違って、入力がテキストカーソルの位置にしばられることはない。
- アプリ側で音声ファイルを扱う必要がない。OutSystems アプリでのファイルハンドリングには気を遣う必要があることが多いため、ファイルを扱わなくて良いのは〇。
- 用意されている JavaScript SDK が難しいところをすべてカバーしてくれており、扱いが容易。
- Web API のウェブ音声 API の音声認識より高機能(追加トレーニングなどにも対応可)。
ウェブ音声 API - Web API | MDN
https://developer.mozilla.org/ja/docs/Web/API/Web_Speech_API - 月に音声5時間分までは無料(2025-04 時点)
Azure AI Speech Pricing | Microsoft Azure
https://azure.microsoft.com/en-us/pricing/details/cognitive-services/speech-services/
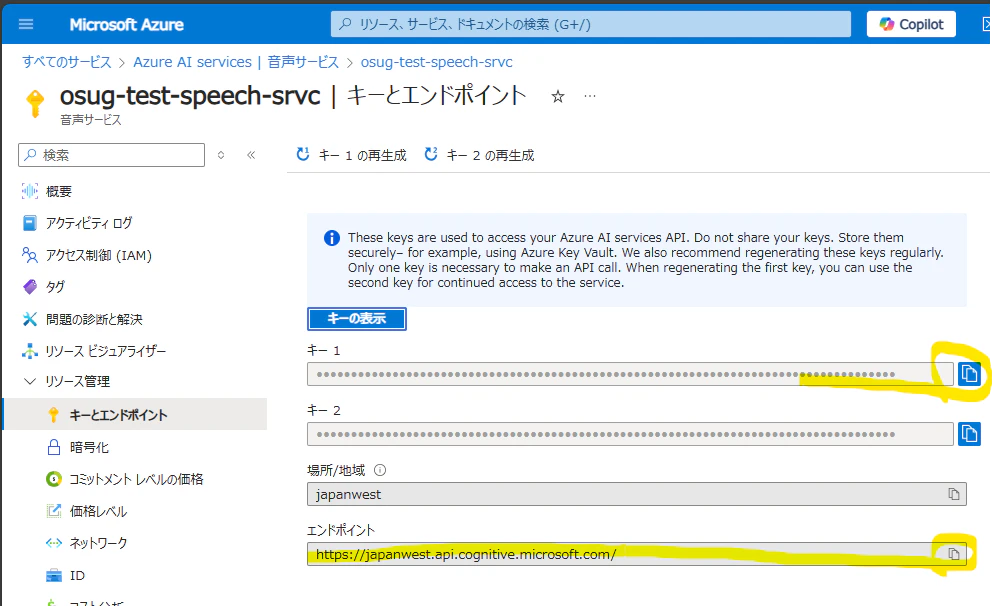
Azure 側の準備
ここからは、実際に OutSystems アプリに、Azure リアルタイム音声テキスト変換を組み込む手順の解説です。まず、Azure 側の準備です。作業は、Azure Portal で行ないます。
Microsoft Azure Portal
https://portal.azure.com
すべてのサービスから、AI + Machine Learining にある「音声サービス」を開いて作成します。
- リソースグループは、すでに利用しているものを選択しても問題ない。
- リアルタイム利用での遅延を考慮して、リージョンは、アプリ使用場所に近いものを選ぶ。
作成したら、キーとエンドポイントがコピーできます。
JavaScript SDK は CDN を使う
JavaScript SDK は、CDN で配布されているものが使えます。Service Studio の Manage Dependencies で、(System) から追加できる RequireScript という標準クライアントアクションを使って、この CDN アドレスを指定すれば、SDK を利用する準備は完了。
JavaScript 用 Cognitive Services Speech SDK | Microsoft Learn
https://learn.microsoft.com/ja-jp/javascript/api/overview/azure/microsoft-cognitiveservices-speech-sdk-readme
JavaScript SDK の CDN アドレス
https://cdn.jsdelivr.net/npm/microsoft-cognitiveservices-speech-sdk@latest/distrib/browser/microsoft.cognitiveservices.speech.sdk.bundle-min.js
CDN アドレスが掲載されているドキュメントページ(↑ドキュメントからたどれます) Speech SDK のインストール - Azure AI services | Microsoft Learn
https://learn.microsoft.com/ja-jp/azure/ai-services/speech-service/quickstarts/setup-platform?pivots=programming-language-javascript&tabs=windows%2Cubuntu%2Cdotnetcli%2Cdotnet%2Cjre%2Cmaven%2Cbrowser%2Cmac%2Cpypi#html-script-tag
下図の実装例では、将来の変更に備えてサイトプロパティに保持している CDN アドレスを、スクリーンのデータアクションで取得し、その OnAfterFetch で、RequireScript に渡しています。

文字起こし開始処理
SDK が使えるようになったら、あとは、SDK 機能を適切に呼び出すだけで、文字起こしを開始できるようになります。例えば、開始ボタンに紐づけたスクリーンアクションに配置した JavaScript 要素に、下記のようなスクリプトを記載します。
const speechConfig = SpeechSDK.SpeechConfig.fromAuthorizationToken($parameters.Token, $parameters.Region);
speechConfig.speechRecognitionLanguage = $parameters.RecognitionLanguage; // eg) "ja-JP"
speechConfig.enableDictation();
const audioConfig = SpeechSDK.AudioConfig.fromDefaultMicrophoneInput();
const recognizer = new SpeechSDK.SpeechRecognizer(speechConfig, audioConfig);
recognizer.recognizing = (_, e) => $actions.Recognizer_OnRecognizing(e.result.text);
recognizer.recognized = (_, e) => $actions.Recognizer_OnRecognized(e.result.text);
recognizer.canceled = $actions.Recognizer_OnStopped;
recognizer.sessionStopped = $actions.Recognizer_OnStopped;
recognizer.startContinuousRecognitionAsync(() => {
$parameters.Recognizer = recognizer;
$resolve();
}, $actions.Recognizer_OnError);
この 13 行のスクリプトが、今回書いた最長スクリプトです。
内容は大きく3つに分かれています。
-
SpeechRecognizer インスタンス作成(1~5 行目)
SDK で定義されている SpeechRecognizer インスタンスを作成します。 -
スクリーンアクションとのバインド(6~9 行目)
インスタンスで発火されるイベントを、スクリーンアクションにバインドし、OutSystems のローコードで処理できるようにします。 -
文字起こしを開始した上で、インスタンスをスクリーン変数に保存(10~13 行目)
インスタンスの開始関数を呼び出した上で、停止などの処理に備えてインスタンスを JavaScript 要素の出力パラメーター(Data Type は Object)に書き出しておきます。書き出したインスタンスは、JavaScript 要素の下流で、スクリーン変数に代入しておきます。
インスタンス作成に使う認証情報の扱い
SDK の SpeechRecognizer インスタンスの作成は、Azure サーバー側の設定を保持する SpeechConfig オブジェクトと、デバイス側の設定を保持する AudioConfig オブジェクトを作成して、この2つをコンストラクタ関数に渡す形で行ないます。
SpeechConfig では、Azure 接続に必要な情報も管理しているのですが、ドキュメントを見ると、いくつかの方法でこの SpeechConfig オブジェクトを生成できることが分かります。
SpeechConfig 作成用の関数の SDK ドキュメント - SpeechConfig class | Microsoft Learn
https://learn.microsoft.com/ja-jp/javascript/api/microsoft-cognitiveservices-speech-sdk/speechconfig?view=azure-node-latest#microsoft-cognitiveservices-speech-sdk-speechconfig-fromauthorizationtoken
サービスを動作させる、という点だけ見れば、どの関数を使って SpeechConfig を作っても問題はないですが、セキュリティの観点からは、避けた方が良い方法もあります。
例えば、上の Azure 側の準備のステップで取得したキー情報をそのまま利用する fromSubscription(key, region) を使おうとすると、アプリのクライアント側で、キー情報を扱う必要があります。この手の、悪用される余地の大きな情報を、クライアント側、特にモバイルアプリで扱うのは、基本的には避けた方が良いです。
今回は、キーをサイトプロパティに保存し、サーバー側で実行する Consume REST API アクションで Azure からサービス利用のためのトークンを取得するところで、そのキーを使うようにしています。そうして得られる短寿命のトークンだけをクライアントに送出するようにし、クライアント側ではこのトークンを使って、fromAuthorizationToken(token, region) を呼び出すことで、SpeechConfig を作成しました。
Consume REST API で呼び出すトークンエンドポイントは、上の Azure 準備で取得したエンドポイント情報に、下記公式サンプルのドキュメントに記載されているエンドポイントパス情報を組み合わせる形が使えました。トークン更新のタイミングについても、この記事で解説されています。
AzureSpeechReactSample/README.md at main · Azure-Samples/AzureSpeechReactSample · GitHub
https://github.com/Azure-Samples/AzureSpeechReactSample/blob/main/README.md#token-exchange-process
Recognizing と Recognized
recognizer.recognizing = (_, e) => $actions.Recognizer_OnRecognizing(e.result.text);
recognizer.recognized = (_, e) => $actions.Recognizer_OnRecognized(e.result.text);
文字起こし処理、という観点で中心になるのは、SDK の SpeechRecognizer から発火される2つのイベント、recognizing と recognized です。recognizing は、認識中、つまりいま聞き取っている内容が送られてくるイベントで、もう一方の recognized は、ある程度のカタマリが認識完了したタイミングで発火されます。高頻度で recognizing が起こり、たまに recognized が起こる、というイメージです。
recognizing: こ
recognizing: こんに
recognizing: こんにちは
recognized: こんにちは。
OutSystems で作成するスクリーンには、画面に表示するテキストを保持する変数と、認識完了して確定済みのテキストを保持する変数を用意しておきます。recognizing、つまり認識途中に対応するイベントを処理するアクションでは、確定済みテキストとイベントからのテキストを繋いだ上で、画面用の変数を更新します。もう一方の recognized では、確定済みテキストの末尾に、イベントからのテキストを追加する形で、確定済みを更新します。
この実装内容であれば、それぞれのイベントハンドラーアクションでは、JavaScript コードは必要なく、OutSystems 変数の単なる代入操作を行なうフローを用意するだけで OK です。
変数に保存した Recognizer インスタンス
スクリーン変数に保存した SpeechRecognizer インスタンスを使って、終了ボタンやエラー発生時に、インスタンスの処理終了関数 stopContinuousRecognitionAsync() を呼び出せるようにしておきます。
この関数が実行されると、sessionStopped イベントが発火されます。開始処理でこの sessionStopped イベントに紐づけたスクリーンアクションでは、やはり、スクリーン変数に保存した SpeechRecognizer インスタンスを使って、その dispose() を呼んで後片付けを行ないます。
const recognizer = $parameters.Recognizer;
if (recognizer) {
recognizer.stopContinuousRecognitionAsync();
}
const recognizer = $parameters.Recognizer;
if (recognizer) {
recognizer.dispose(true);
}
以上で、Azure 文字起こしサービスを利用するための実装は完了です。
まとめ
- Azure AI サービスによるリアルタイム文字起こしは、CDN 配布されている SDK を使うことで、ほんの少しの JavaScript を書くことで、OutSystems アプリで利用できる。
- 文字起こしは、LLM 利用などの前段に使える、現代的には適用範囲の広いサービス。
- リアルタイムだと音声データファイル(大容量になりがち)を使わないので、OutSystems アプリ開発では扱いやすい。
- サブスクリプションキーのような悪用の余地のある情報は、クライアント(特にモバイル端末)には送らないようにする。
- 短寿命トークンを Consume REST API で取得してクライアント利用すると良い。
この記事で解説した内容を実装した O11 サンプルアプリは、下記 Forge で公開しています。
Azure Speech To Text - Overview (O11) | OutSystems
https://www.outsystems.com/forge/component-overview/21237/azure-speech-to-text-o11