この記事は インフォマティカ Advent Calendar 2022 Day7 の記事として書かれています。
はじめに
データマネジメントのエバンジェリストをやっているもりたくです。
本日は今年最も相談を受けることの多かった「データファブリック」について解説してみたいと思います。
この記事を読んだ人が「データファブリックとは何もので、どのように実現すべきものなのか」を少しでも理解できれば嬉しく思います。
データファブリックとは何か?
データファブリックとは2022年に注目を集めたテクノロジーのトレンドの一つであり、あらゆる企業が目指すべき理想的なデータ管理手法として注目を集めてきました。
また、ForresterはForrester Waveという市場レポートでその評価を発表していますし、その他にも各種ソフトウェアベンダーがその定義について言及しています。
本記事では、Data Fabricについて勉強した結果について独自解釈した解説をしていきたいと思います。
データファブリックの定義と目指すべき世界
データファブリックを説明する時、私は以下のように表現することが多いです。
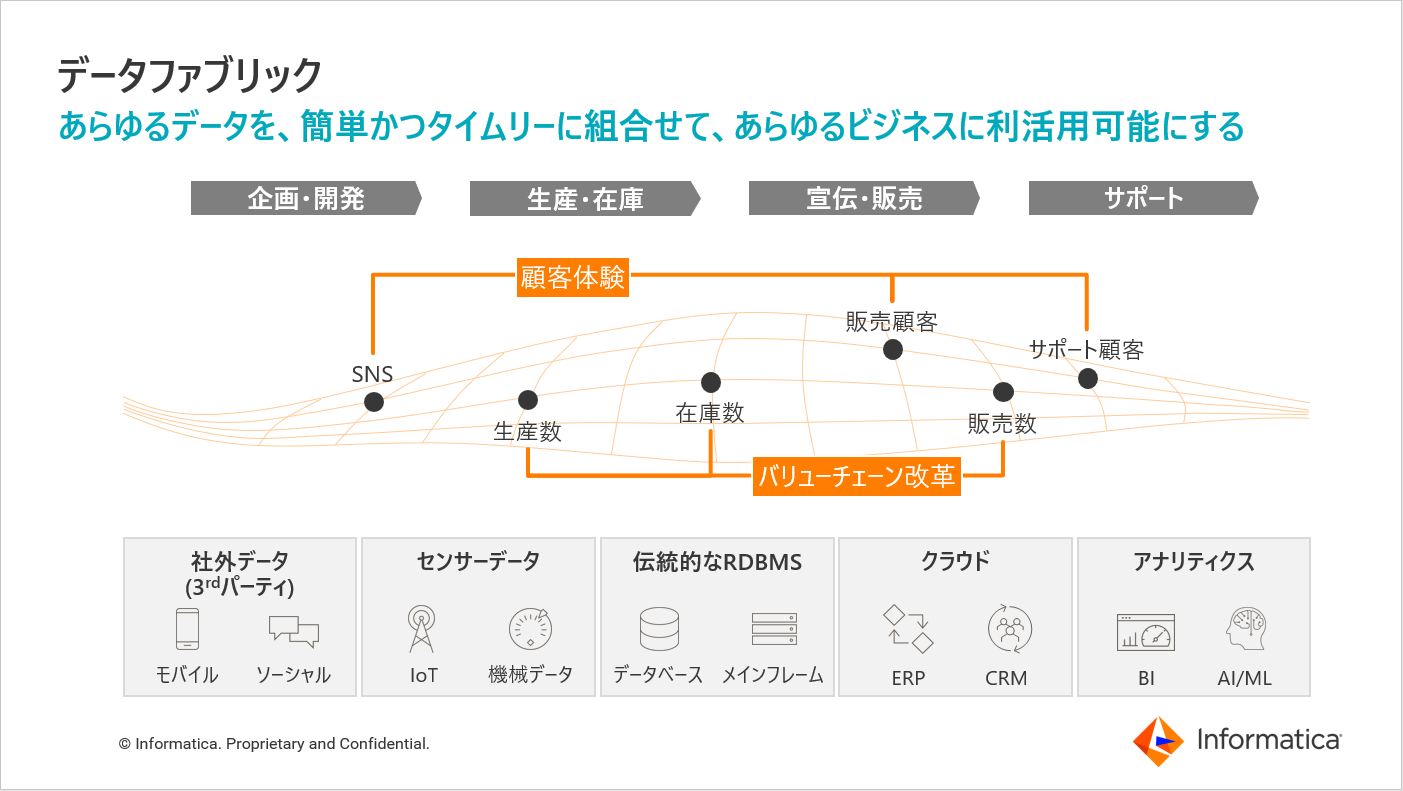
もう少し詳細な言葉で表現すると、以下のようになります。
データが分散する環境において、テクノロジーやデータ形式に依存せず、
あらゆるデータを簡単且つタイムリーに組合せて利活用可能にするための、
新しいデータ管理の設計手法(機能・ツール・アーキテクチャの組合せ)のこと。
この定義をまず紐解いていきたいと思います。
まず「データが分散する環境」とはどういうものなのか。
企業には多くの事業部があり、各事業部で個別最適化したデータを持っていると思います。そして、各データを格納するシステム、データの形式は様々で、これらのデータが点としてのみ存在する限り、その価値は特定の業務の中でしか発揮されませんでした。
例えば、企業内に販売事業部とサポート事業部がいたとしても、各事業部の業務上の責務、取り扱う業務システムや管理データは以下のように異なります。というのも、販売事業部は販売後のサポートをする責務を持たないし、サポート事業部は販売時のサポートはする責務を持たないためです。
| 事業部 | 責務 | 業務システム | 管理データ |
|---|---|---|---|
| 販売事業部 | 商品の販売を促進・管理する | 販売管理システム | (サポート前の)販売顧客データ |
| サポート事業部 | ユーザーの顧客満足度を上げる | 問合せ管理システム | (販売後の)サポート顧客データ |
結果、販売管理システムと問合せ管理システムの中で管理している顧客データは別々で管理され、それらを組合せて業務に活かすような取り組みは行われてきませんでした。
しかし、データファブリックでは、この点として分散しているデータを糸で繋ぎ、価値あるデータの組合せともいえる布、ファブリックを生み出していけるように企業全体を変革していこう、と言っています。
販売顧客とサポート顧客のデータを事業部、システム横断で紐づけて把握することができれば、問合せの傾向から解約リスクの高い顧客を把握して繋ぎとめるための営業活動を行ったり、優良顧客のプロファイルや趣味嗜好を販売/サポート横断的に分析することでそれに該当する見込み顧客を増加させるためのマーケティング活動を行ったり、より顧客満足度の高い新製品開発を行ったりできます。システム構築当初に想定された責務や目的以上の業務の中で、データがより高い価値を発揮するようになります。
また昨今では、この「データが分散する環境」がより多様化、複雑化していると言えます。顧客にまつわるデータと一言で言っても、SNSなどを中心としたソーシャルデータもあれば、顧客のリアル/デジタルの足跡を追跡したセンターデータもあるし、各顧客にまつわるトランザクション履歴もトラディショナルなオンプレミスシステムからモダンなクラウドサービスの中で管理され、そのテクノロジーやデータ形式は様々です。
「データが分散する環境」を受け入れるためには、この「テクノロジーやデータ形式に依存せず」、むしろそれを余裕で受け入れて「簡単かつタイムリーに組合わせて利活用可能にする」アーキテクチャやツールの活用も必要不可欠と言えます。そして、これを実現する技術的アプローチのことをデータファブリックと言います。
なぜ今、理想的なデータ管理手法が求められているのか?
あらゆる企業にとって、ビジネス上の価値を生み出す、DX、データ利活用を前提としたビジネス変革は今や企業戦略に必要不可欠で、最大の投資領域の一つです。これを逆説的に考えると、もしデータがビジネスに利活用できない状態ならばDXは成功しない、とも言えます。
例えば、もし事業やシステム横断で顧客にまつわるデータが統合できない、データがバラバラで、誰も簡単にアクセスできない、そんな状態のデータでは、顧客分析は成功せず、CXを改革してブランド価値を上げていくのは不可能でしょう。
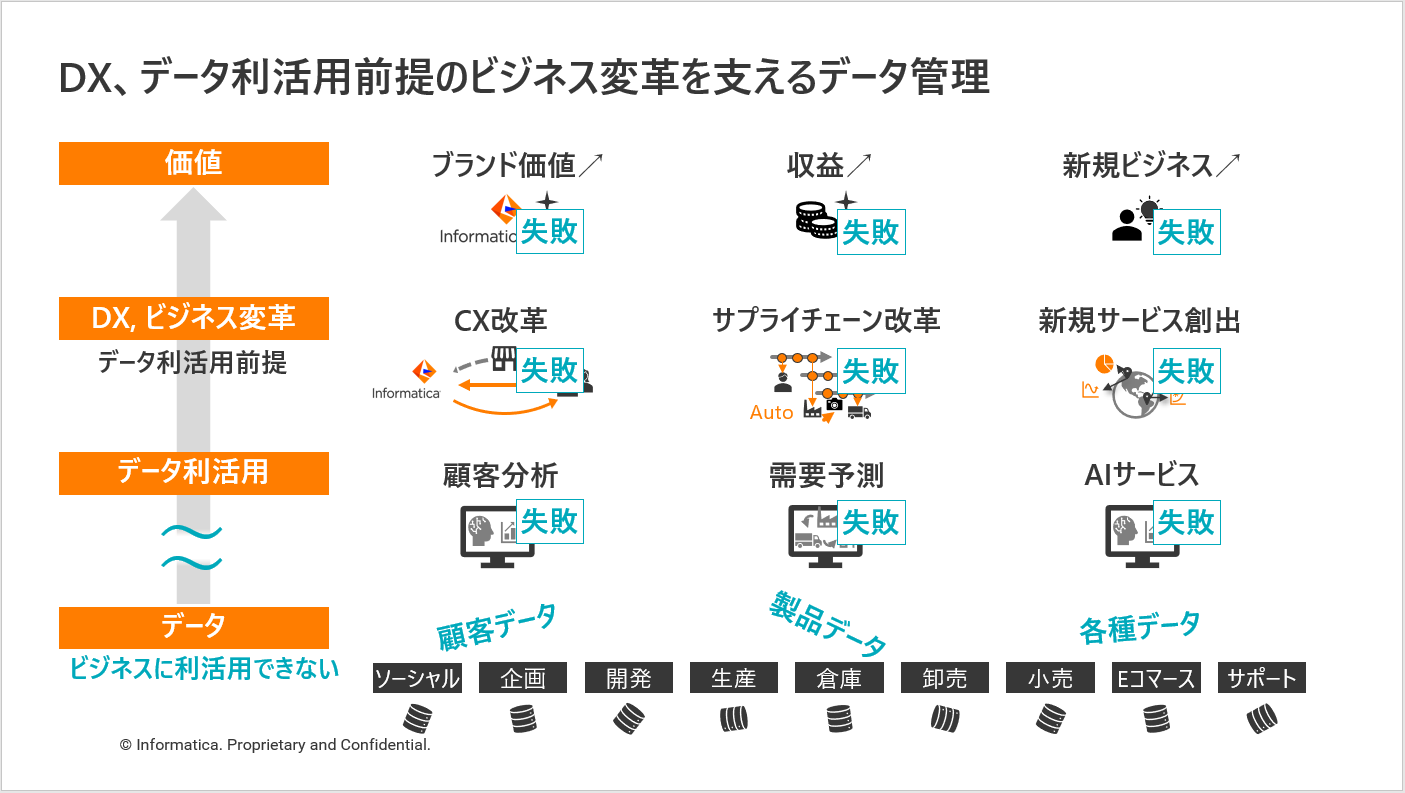
データ管理(データマネジメント)は、この状況を打破し、あらゆるデータをあらゆるビジネスに利活用できる状態に整える取り組みです。システム横断でデータが繋がり、信頼性のある、誰もが簡単かつ安心安全に使えるデータを提供します。
つまりデータ管理は、データ利活用を前提としたあらゆるDXに必要不可欠なものなので、今DXと共に最もホットな取り組みの一つである、と言えます。
そして、このデータ管理について今、あえて理想的な手法が求められている背景としては、世の中の3つのトレンドが大きく影響しています。これを更に紹介しておきたいと思います。
1. データの複雑性の拡大
2. マルチハイブリッドクラウドの拡大
3. データユーザーの拡大
データの複雑性の拡大
グローバルの各種レポートによれば、世界のデータ量は毎年2倍以上のスピードで増加していると言われていることが多いです。また、企業がデータを取り扱うテクノロジーは年々増えていて、構造化/半構造化/非構造化データといったデータイプや、大量データのバッチ処理からリアルタイム性を求めるAPI応答といったデータのレイテンシーに対する要件も複雑化しています。
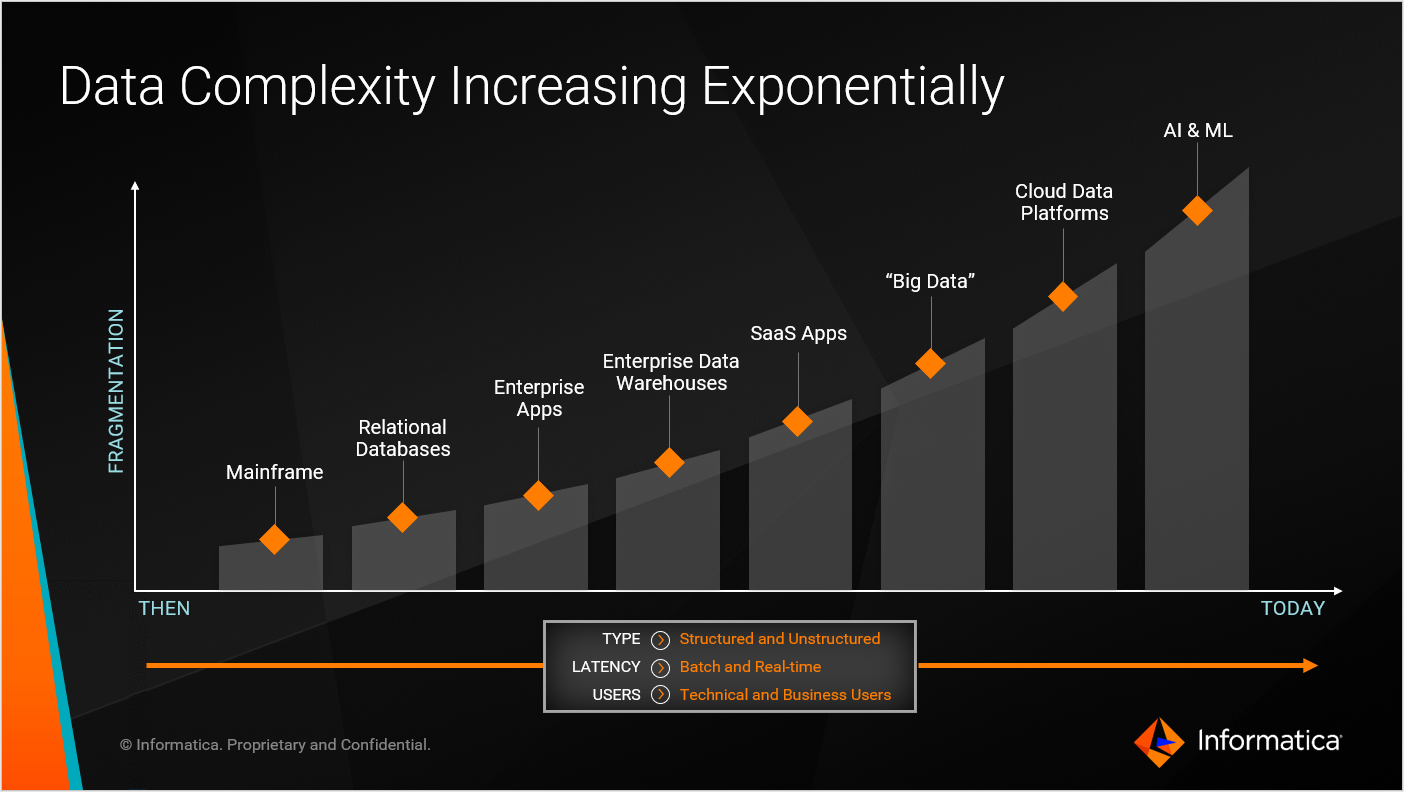
あらゆる企業がこの将来的に永遠に増え続けるデータの管理に対処しなければなりません。
しかしながら、もしこの作業負荷がデータ量や複雑性に単純比例して増加するとなったら、どうなるでしょう。どこかで管理が破綻してしまうのは目に見えています。
そこで必要になってくるのが、より自動化された理想的なデータ管理手法です。データの量や複雑性が今後増加したとしても、その作業負荷には極力影響を与えず、簡単に管理を継続できる仕組みが必要です。
マルチハイブリッドクラウドの拡大
グローバルの各種レポートによれば、3分の2以上の組織が複数のクラウドを定期的に利用していて、80%近くの組織がデータの半分以上をハイブリッドおよびマルチクラウドのインフラストラクチャに保存している、と言われています。
データのボリュームが増えるだけでなく、多くの種類のデータソースがマルチハイブリッドなクラウドの世界へと広がり、今まで以上にデータの発見、管理、制御が難しくなっていると言えます。
このマルチハイブリッドな環境に対応して、データ管理を自動化できる理想的な仕組みも必要です。
データユーザーの拡大
データ利活用に関わるユーザーとして、データサイエンティストやデータアナリストと言われるテクニカルなユーザーだけでなく、LOBなどのビジネスユーザーも増えている事実も、無視できないトレンドです。
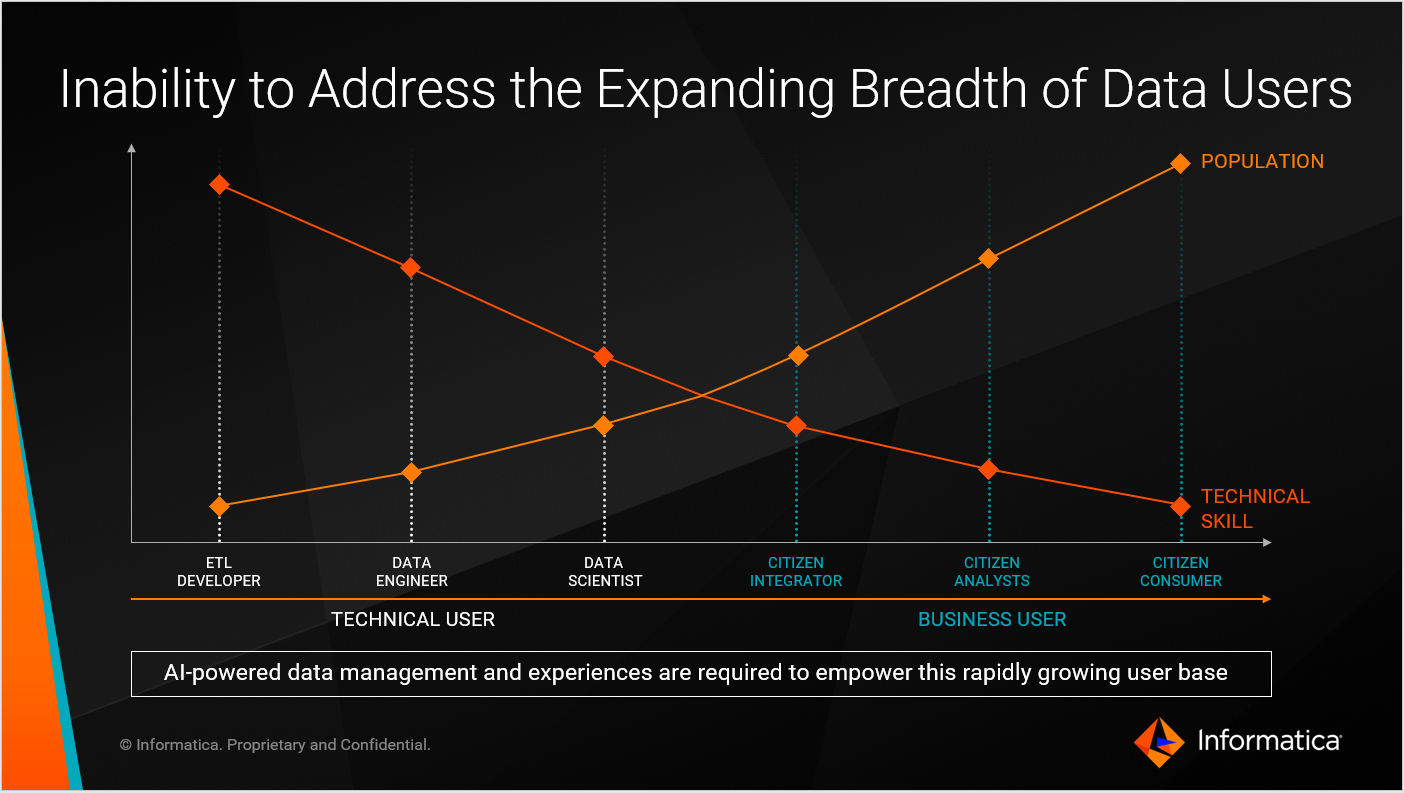
一部のテクニカルユーザーのみがデータ利活用に関わっているだけでは、実施できるビジネス変革には限界があります。そこで、一般のビジネスユーザーもデータの世界へ巻き込んでいく必要があります。
その際、データの発見、管理、制御が面倒な仕組みのままだと、ビジネスユーザーは誰もデータを積極的に利用しようとは思わないでしょう。誰でも簡単に、蛇口を捻れば水が出るかのように、データが欲しいと思ったら安心安全で高品質なデータがすぐに入手できる、そんな素敵なデータ管理の世界も実現することが必要です。
何をしたらデータファブリックを実現したと言えるのか?
私はデータファブリックの実現に向けて、理想とすべきアーキテクチャの実現を目指すべき、と説明しています。
ただ、この理解が簡単ではないため、2段階に分けて説明していきます。
データファブリックに求められるハイレベルなシステム要件
データファブリックについてハイレベルなシステム要件を考えるとき、データが分散する環境において、あらゆるユーザーがあらゆるデータを簡単に組合わせて利活用するための7つの機能要素について理解する必要があります。
しかし、いきなりその詳細を説明してもわかりにくいため、まず以下3種類のケーパビリティの実装を目指すべき、と説明しています。
共有とガバナンス
再利用とセルフサービス
メタデータドリブンなAIと自動化
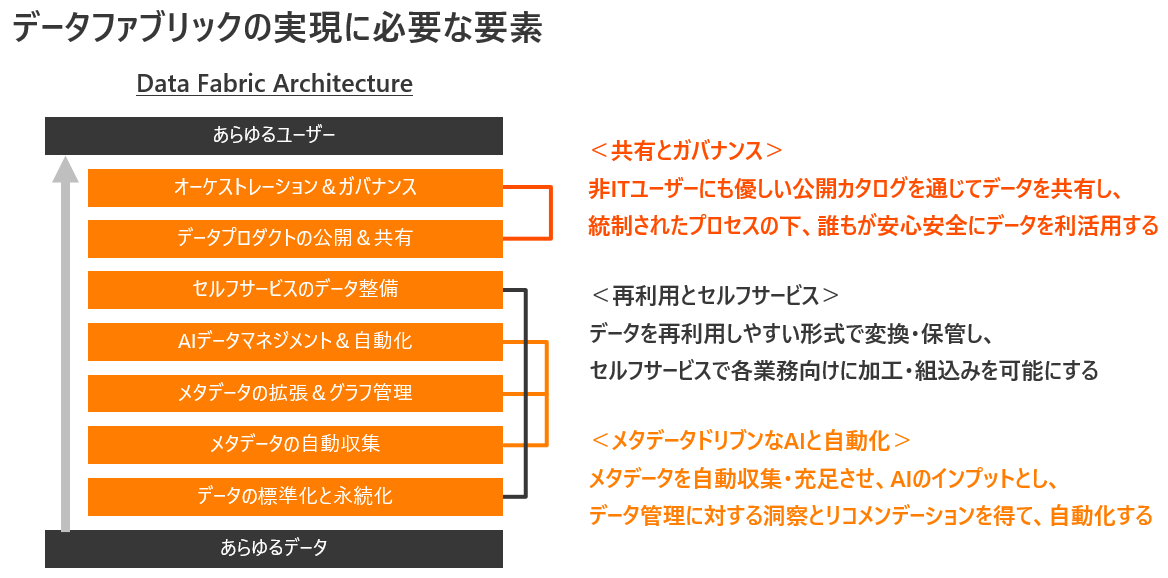
「共有とガバナンス」とは、ビジネスユーザーにも優しい公開カタログを通じてデータを共有し、統制されたプロセスの下、誰もが安心安全にあらゆるデータを利活用できるようにする、というものです。
これが実現できていないと、あらゆるユーザーがデータを利活用できる世界にはならない、というのは想像しやすいかもしれません。
「再利用とセルフサービス」は、公開カタログに掲載されるデータは、物理的に再利用しやすい形式で変換・保管し、ユーザーがセルフサービスで各業務向けにちょちょっと加工し、あらゆる業務プロセスの中に関単に組込めるようにする、というものです。
企業のデータは本来、事業横断の分析目的で作られたデータでは無いため、基本再利用できない状態で存在するというのを忘れてはなりません。これが実現できないと、テクノロジーやデータ形式に依存せずにデータを組合せて利活用するのは難しいといえます。また、セルフサービスでデータ加工ができないと、毎回誰かに依頼が必要となり、とてもタイムリーなデータ利活用は実現困難となります。
「メタデータドリブンなAIと自動化」は、公開カタログのもとにもなるメタデータを自動で収集し、人とAIの力で充足させながら、それをAIのインプットにすることで、データ管理に対する洞察とリコメンデーションを得て面倒な運用を自動化しよう、というものです。
これは理想的なデータ管理手法という意味で、最も重要なケーパビリティと言えます。マルチハイブリッドな環境下でデータの複雑性が拡大していく今、人間の力でデータ管理をやるのは限界を迎えています。そこでAIの力を使って、データ管理そのものを自動化しようという取り組みです。特に、公開カタログのベースとなるメタデータの管理は、自動化しないと運用負荷が大きく破綻するケースも多いため、その管理運用は自動化を追求し続ける必要があります。
企業のデータアーキテクチャとしてこれらの3つのケーパリティを備えることができれば、概ねデータファブリックを実現できたと言えます。
しかし、あくまでこれはハイレベルなシステム要件であり、実際は各技術要素を一つずつ詳細なシステム要件に落とし込み、アーキテクチャの中に実装していく必要があります。
データファブリックに求められる詳細なシステム要件
続いて、3つのケーパビリティを支える、データファブリックに必要な以下7つの実装すべき詳細なシステム要件を一つずつ理解してみましょう。(図の下から上の順番で説明していきます)
- データの標準化と永続化
- メタデータの自動収集
- メタデータの拡張&グラフ管理
- AIデータマネジメント&自動化
- セルフサービスのデータ整備
- データプロダクトの公開&共有
- オーケストレーション&ガバナンス

「データの標準化と永続化」は、データの再利用性を高めるために、データ利活用のユースケースに応じてデータをより価値ある利用しやすい形式に変換し、永続的に保管しいつでも簡単に取り出せる状態にデータを管理できる、クラウドデータレイクやデータウェアハウスを備えなければならない、というものです。これはその他の要素がメタデータというデータの論理的な管理にフォーカスしているのに対し、これはデータの物理的な管理をサポートしているステップと言えます。また、データ品質とマスタデータも標準化することで、あらゆるデータを組合せて利活用できるように整えるのもポイントです。
「メタデータの自動収集」は、データレイクやデータウェアハウス、BIツールといったデータを格納する機能要素だけでなく、あらゆるデータ管理ツール(データ統合、データ品質ツールなど)からメタデータを抽出し、データカタログとして管理しなければならない、というものです。この後に登場するAIによるデータ管理の自動化、公開されたデータカタログの整備へと繋がる重要な初期メタデータ収集ステップと言えます。ポイントは、あらゆるデータ管理ツールからメタデータを自動抽出していく点で、従来の一般的なデータカタログとはそのカバー範囲が大きく異なるのも特徴です。
「メタデータの拡張&グラフ管理」は、先の「メタデータの自動収集」が抽出したテクニカル、オペレーショナルのメタデータを自動収集し、そこにビジネスメタデータを付与しながら、あらゆるメタデータをグラフモデルとして関係性も含めて管理できる、そんなメタデータ管理を備えなければならない、というものです。このステップは、あらゆるユーザーがデータを正しく情報として理解し、安心安全に利活用できるようにする目的と、次のAIデータマネジメントを実現するための布石となるステップです。
「AIデータマネジメント&自動化」は、データファブリックの設計、つまりデータ管理のあらゆる運用を自動化、効率化するために、先のステップで作成したあらゆるメタデータのナレッジグラフをデータ管理向けのAI/MLのインプットとし、洞察とリコメンデーションを得ることができる、そのようなAI/ML データ管理エンジンを備えなければならない、というものです。このステップを実現してはじめて、複雑化するデータの分散環境を受け入れることができるようになると言えます。AIの支援を受けることで、データ品質管理を自動化したり、個人情報関連のデータの分類やセキュリティ強化を自動化したり、データの再利用性を高めるデータ変換を自動化したり、マスタデータ管理における名寄セ処理を自動化したり、とデータの複雑性に対処し、イイ感じにデータ管理を行うための最重要ステップといえます。
「セルフサービスのデータ整備」は、「データの標準化と永続化」に近いデータの物理的な管理にフォーカスしていて、あらゆるユーザーがデータを利活用する上で、セルフサービスで最後に自らのユースケースに最適な形にデータを整えたり、関連システムへデータを配信したりすることができる、ローコード/ノーコードのUIによるデータプレパレーション、API統合を備えなければならない、というものです。「データの標準化と永続化」のステップで再利用しやすいデータが格納されていたとしても、あらゆるユースケースに完全に対応するのは難しいです。そのため、最後はユーザー自身が自ら望む形式にデータを整備しながら利活用できるようにする必要があります。その際、毎回プログラミングが必要となると誰もが自ら対応ができなくなってしまうため、セルフサービスで使えるツールでサポートすることが重要となります。
「データプロダクトの公開&共有」は、ビジネスユーザーを含むあらゆるユーザーがデータを簡単かつタイムリーに利活用できるようにするために、公開されたデータカタログを使用し、データプロダクトと呼べるレベルの高品質なデータを共有しよう、というものです。Amazonでショッピングするかのように、誰もが簡単かつ高品質なデータに公開データカタログを通じてアクセスし、事業部を越えたあらゆる欲しいデータを探索・入手できるようになれば、あらゆるユーザーがあらゆるデータを使えるようになる、といえます。もちろん、この公開されたデータカタログ(データマーケットプレイスとも呼ぶ)で高品質なデータを入手できる裏には、これまでのステップで物理的に再利用しやすい永続的なデータが整備されていること、そして誰も理解できる形でのカタログを構成するための論理的なメタデータも整備されていること、が前提条件としてあります。これらの前提条件を他の技術要素が担保してくれているために、最終的に実現できる世界と言えます。
「オーケストレーションとDataOps」は、シンプルに言えば、これまで説明した全てのサービス機能を横断するコラボレーション・レイヤーです。データの管理者が消費者と共同でコラボレーションする機能を提供し、データの発見から収集、変換と格納、品質と関連付け、統制のきいた活用と共有まで、データ利活用にまつわる全てのデータライフサイクルをムダなくフルサポートできる、データ管理とガバナンスを備えなければならない、というものです。特に、データ利活用は関わる人が多く、ゴールが見えない、絶えず要件が変化するアジャイルな取り組みと表現されることも多っかたりします。そのため、各データライフサイクルの運用のムダを極力排除し、透明性を保ちながら円滑にコラボレーションできるようにすることが継続的なデータ管理を成功に導くために必要不可欠といえます。
以上、長くなりましたが、これらの技術要素を一つ一つ備えることによって、最終的にデータファブリックを実現することができます。
ただ忘れてはならないポイントは、これらの技術要素を全て独立して実装してしまっては意味がなく、各技術要素がシームレスに連携・統合した形でデータファブリックレイヤーを構築する必要があることです。これは言うは易く行なうは難しです。もしかしたら、ここまでデータファブリックを勉強しても、その実装の難易度の高さから諦めてしまう人もいるかもしれません。
しかし、この包括的な実装を簡単にサポートできるクラウドサービスが唯一存在します。インフォマティカのデータマネジメントクラウド(正式名称はIntelligent Data Management Cloud、略してIDMC)です。
インフォマティカと共に実現するデータファブリック
インフォマティカのデータマネジメントクラウドは、先に説明したシステム要件の内、データの永続化以外を全て満たすことができるクラウドサービスを提供しています。
一部機能として不足しているデータの永続化は、我々にとってのエコシステムであるAWS、Azure、GCP、Oracle、Snowflake、Databricksなどのクラウドレイクハウスのサービスと組合わせることで実現することができます。

今回、一つ一つのサービスがいかにして各システム要件を満たしているのかまでは細かく説明しませんが、Oneプラットフォームでデータファブリックの包括的な機能要素を満たすことができているデータ管理ツールを、私は他に知りません。
ただ唯一ここで知っておいて欲しいのは、あらゆるデータ管理を横断する形で収集し、グラフモデルとして管理したメタデータをインプットに機能するCLAIREというAIエンジンが、データマネジメントクラウドに含まれている点です。
CLAIREは、データ統合、データカタログ、データ品質、マスタデータ管理、データガバナンスなどのサービスを横断する形であらゆるメタデータを把握しています。そのため、データ統合時にPIIデータを識別して自動マスキングの実装を求めるアドバイスを推奨したり、データ品質の標準化を行う際には同類データを識別して一括で標準化適用することを推奨したり、人による手動名寄せのオペレーションを真似て行う自動名寄せを推奨したり、多くのデータ管理作業の自動化、効率化をサポートしてくれます。
なお、余談として、今回のデータファブリックの説明をご紹介した某製造業のお客様は、「インフォマティカのデータマネジメントクラウドを真似してデータファブリックの定義って作られたのですか?」、「データマネジメントクラウドをとりあえず採用さえしておけば、データファブリックの実現ができますね」という嬉しいコメントをくれました。
リファレンスアーキテクチャ:インテリジェント・データファブリック
また参考までに、データマネジメントクラウドとクラウドエコシステムによって実現する、インテリジェント・データファブリックのリファレンスアーキテクチャを紹介します。
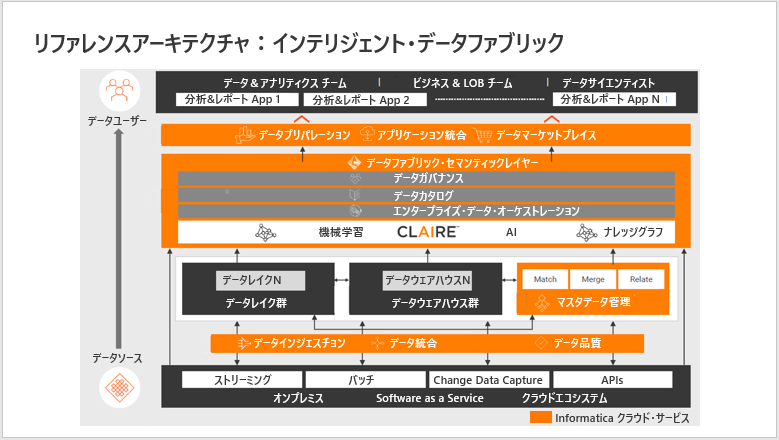
(画面下から)データインジェスチョン、データ統合、データ品質では、オンプレミス、SaaS、クラウドのエコシステムから、あらゆるデータを、あらゆるレイテンシーのもとに取り込み、標準化し、クレンジングすることができます。
データレイク、データウェアハウス、その他の分析用データストアでは、目的に応じたデータ管理技術(RDBMS、Spark、Cloud Storage Objects、NoSQL DB)を使用して、セマンティックを充実させながら、再利用性の高い構造化および非構造化データを永続的に格納します。
マスターデータ管理では、ドメイン間で断片化された企業内の共通マスタデータを調和させます。顧客や商品など重複するデータをマッチングさせ、共通データを「ゴールデンマスター」にマージし、この共有された価値の高いデータを他の関連データと関連付けます。この「ゴールデンデータ」をファブリック全体でアクセスできるようにすることで、従来、点でしか扱えなかったデータをファブリックとして横串に紐づけて利活用することが可能になります。
セマンティックレイヤーでは、すべてのデータストアにまたがるメタデータの管理をサポートする。機械学習とAIは、異種データソースからのメタデータの取得と補強を自動化し、データとビジネスの間のつながりを文書化するナレッジグラフを生成します。データカタログは、データのリネージュ、データプロファイリングの結果、このメタデータの意味的に検索可能なストアを提供し、データの発見と理解を促進します。データガバナンスは、技術的な理解、ビジネスとの関連性、データの使用とアクセスに関するコンテキストを提供します。エンタープライズ・データ・オーケストレーションは、これらの透明性を担保し、データ管理者と消費者を跨るコラボレーションとデータ配信をサポートします。
データプリパレーションとデータマーケットプレイスは、あらゆるデータユーザーのために、分析用データをセルフサービスで提供します。データプリパレーションでは、データの収集、結合、構造化、整理を行うためのユーザーフレンドリーなインターフェースを提供し、データマーケットプレイスでは、データを検索して配信するための「データのショッピング」体験を提供します。
以上のクラウド・サービスを包括的に提供することで、インテリジェントなデータファブリックの世界を実現することができます。
おわりに
本記事では、「データファブリックとは何もので、どのように実現すべきものなのか」についてご紹介しました。
2022年は、日本の企業から実際に「データファブリックを目指したいがどう実現したらいいの?」と質問されることが多く、またその解説をした結果として、実際にデータファブリックの実現を目指す企業が増えた一年と言えました。
一方で、世界の先進企業に目を向けてみると、先に紹介したデータアーキテクチャと似ている絵を描いており、既にデータファブリックに適応しているといえます。
2023年以降にその実現を目指して行く上で、本記事が少しでも参考になっていれば幸いです。
最後に、データファブリックと一緒に語られることの多いデータメッシュについては、別日程の記事で紹介予定です。
ぜひそちらも合わせて読んでいただけると嬉しいです。
(おまけ)データファブリックのよくある勘違い
世の中ではデータファブリックについて様々な説明がなされていますが、そのスコープを狭めて、言及しているケースも多いです。
その一部を実現するだけでデータファブリックが実現できる、といっているようなケースも多いため、そこは注意して情報収集されることを推奨します。