はじめに
近年、SaaS化に伴いパッケージ製品を導入するケースが増加しており、データモデルをきっちり作成するということは減ってきたかと思います。ただ、構築するシステムがスクラッチであれパッケージであれ、要件定義時に論理データモデルを作成することで、そのテーブルの範囲、粒度、保持すべき項目、他テーブルとの関係性など整理することができます。この記事では要件定義時に論理データモデル(テーブル定義)を作成する上で必要なタスクや具体的な進め方についてご紹介していきたいと思います。
本記事は教科書的なデータモデリング方法ではなく、どちらかと言うと実務的なデータモデルの進め方を記載しています。
論理データモデル作成に向けたタスク一覧とスケジュール
タスクとタスクスケジュールについては以下の図の通りです。以下の文章で1~4の具体的なタスクの進め方について記載している。


1:要件定義
新しくテーブルを作るきっかけはたいていシステム刷新やデータ分析基盤の構築などがあげられます。
上記のような新規に構築する各テーブルに対して、要件を洗い出します。例えば、顧客マスタであれば顧客をグルーピングできるテーブルを保持したい。顧客を細かく分類する項目がほしいなどです。これらはデータモデル上で解決可能な要件となります。
一方で、既存システム側のテーブルに対する要件なども洗い出します。例えば、同じ意味のテーブルが複数の既存システムの中で別コードとして採番されて利用されているため、統一したい。データを管理する組織が定まっていないため、明確にしたいなどの課題です。これらの課題はデータモデルだけでなく、業務フローやデータフローなどの成果物を含めて対応する必要があります。
したがってこの要件定義タスクのアウトプットとしては要件定義一覧を洗い出し、その要件に対応する成果物をマッピングします。ただし、一覧化した全ての要件に対して対応できるかどうかも合わせて検討する必要があるので、対応可否をつけると良いです。
具体的なアウトプットイメージは以下の通りです。

2:実データ、項目定義書収集
新しくテーブルを作るきっかけは上述した通りシステム刷新やデータ分析基盤の構築などがあげられます。
この際に、既存システムに新しく構築するテーブルと同じようなテーブルがないか確認して、情報収集する必要があります。これらの情報から既存システムのテーブルの範囲や粒度、構造などを把握することができます。
たとえば、新しく取引先マスタを構築する必要があれば、既存システムの取引先マスタの項目定義書や実データなどを収集します。
項目定義書が存在しない場合は、既存システムの画面などをキャプチャします。
3:Asisデータモデリング
収集した項目定義書、実データ、画面キャプチャなどに対してAsisデータモデルを作成します。(既存システム側にデータモデルが作成されている場合は、無理に作成する必要はないです。)
既存システムのテーブルや実データからAsisデータモデルとして可視化することで、新しく作成するテーブルの範囲や粒度、構造、項目などを決める要素を集めます。
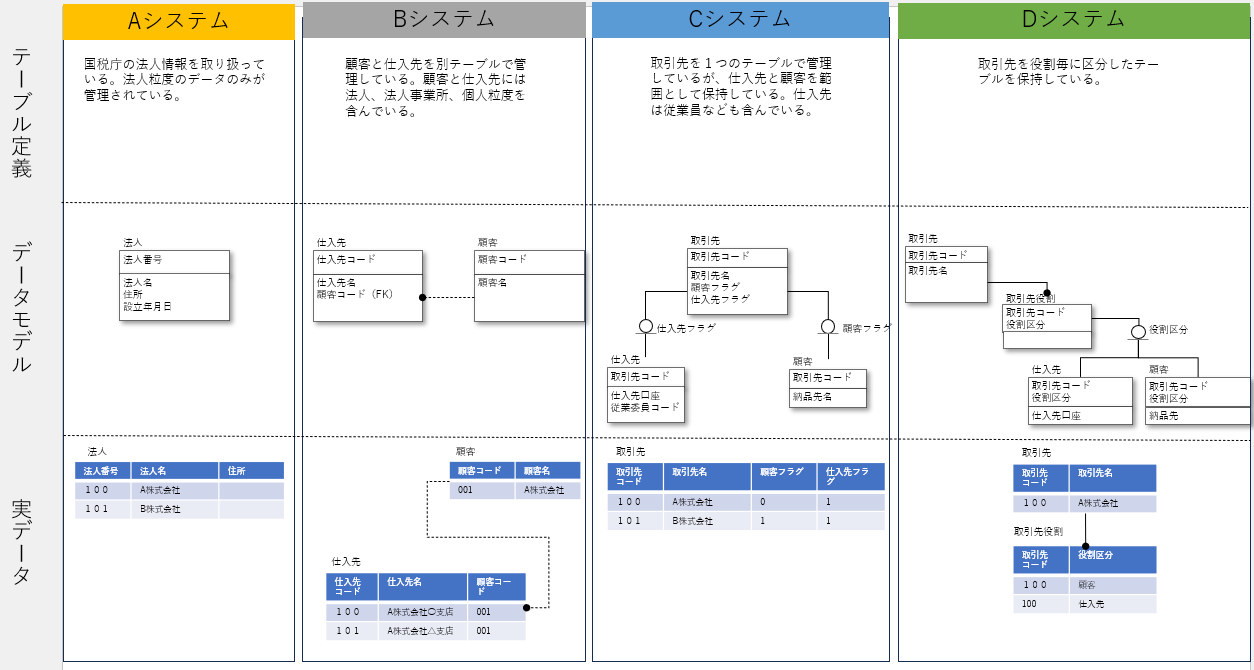
例えば、新システムで取引先マスタを構築するケースを想定してみましょう。4つの既存システムにそれぞれ取引先マスタがあるとします。それらをAsisデータモデルで可視化します。Asisデータモデルを書く際に、既存システムで保持しているレコードの粒度や範囲、他テーブルとの関係性を意識して、データモデルに反映します。テーブルの範囲はサブタイプで、他テーブルとの関係性はリレーションで表現するのはもちろんのこと、値事例やテーブル定義についても纏められると比較や理解がしやすくなります。
具体的には下記のようなアウトプットイメージになります。
※Asisデータモデリング例
4:Tobeデータモデリング
4-1:データモデリング
要件定義で洗い出したテーブルに対する要件とAsisデータモデルからTobeデータモデルを作成します。
Asisデータモデルの中でTobeでも踏襲するデータモデルがあれば、それをベースにデータモデルを作成します。
また、要件一覧の中でデータモデルとして解決できるものについては反映させていきます。例えば、顧客をグルーピングできるようにしたいという要件があれば、それに対応できるデータモデル案を考えて、検討を進めます。
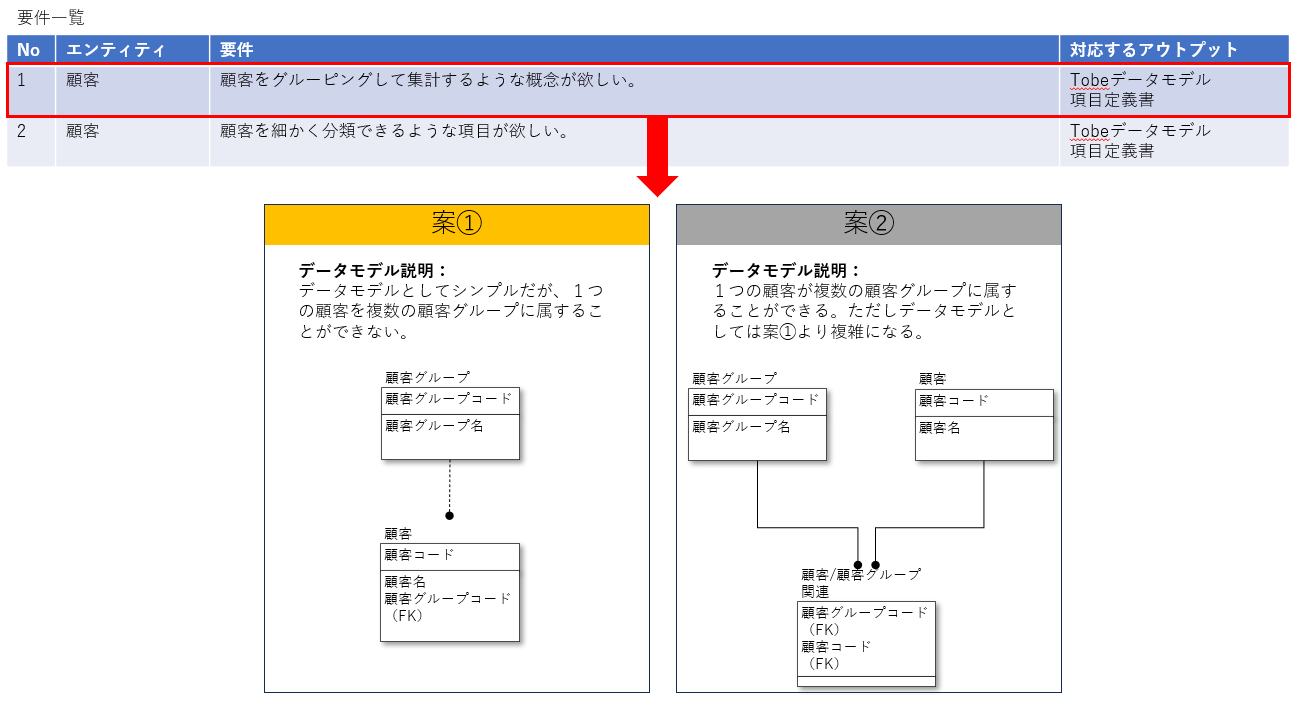
要件として一覧化されているか否かに関わらず、Tobeデータモデルとしての範囲とレコードの粒度を決めます。
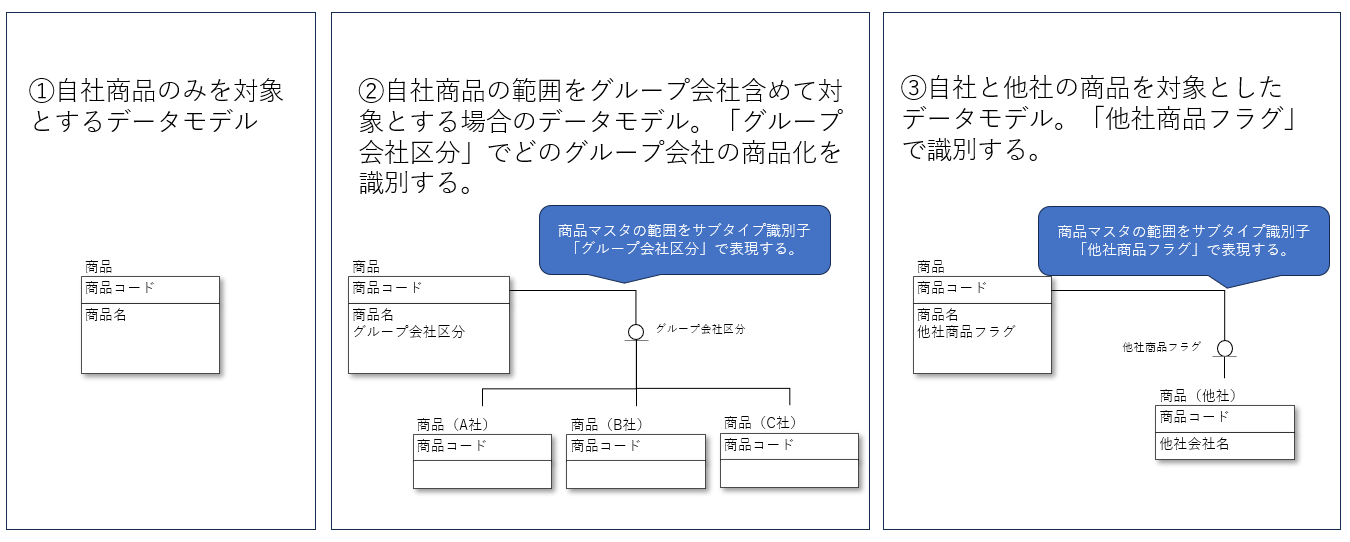
まずデータモデルの範囲はそのマスタが対象とするレコードの範囲を意味します。商品マスタを例にすると、商品マスタとして取り扱う範囲や自社商品なのか?他社商品も含めるのか?自社商品を対象とした場合、自社の範囲をグループ会社まで含めるのか等を検討します。データモデルの範囲は視覚的に分かりやすくするためにサブタイプで表現します。
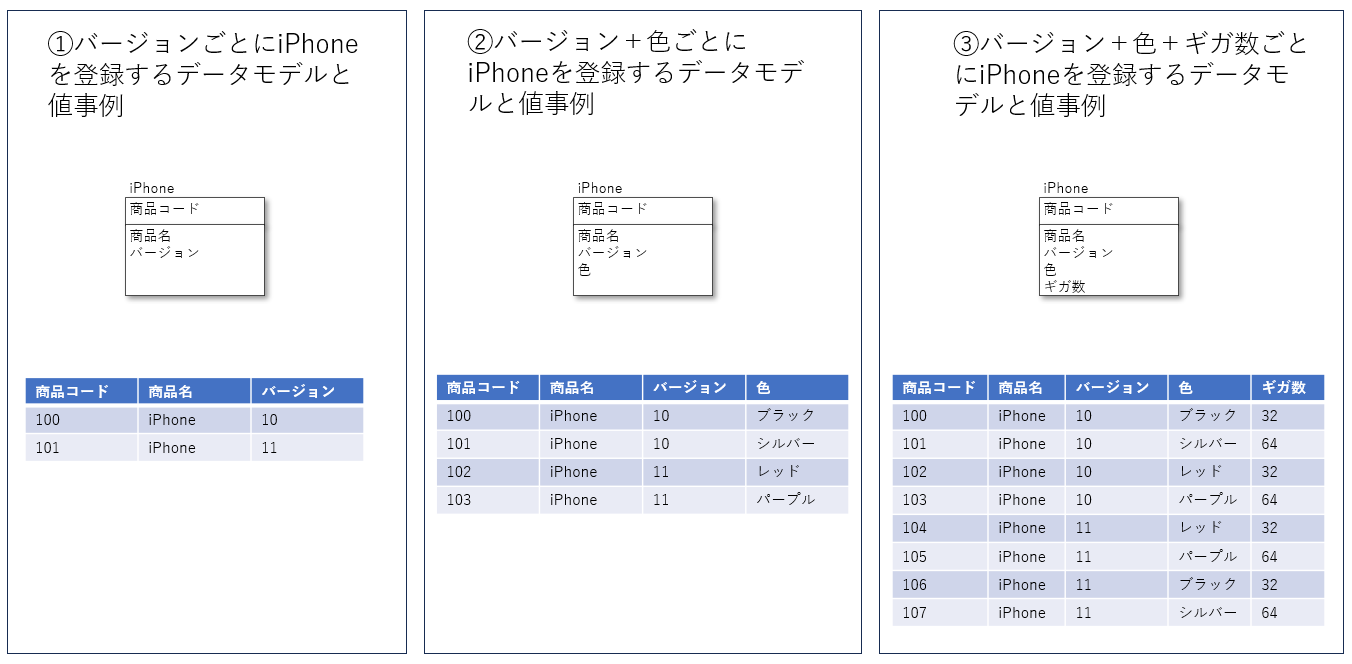
範囲と同じような観点で、粒度を検討する場合があります。粒度はそのテーブルで取り扱うレコードの細かさという意味になります。商品マスタであれば、商品として登録する1件のレコードはどのような単位になるかということです。例えば、iPhoneを取り扱うマスタがあるとします。そのiPhoneマスタに登録する1レコードはiPhone10,iPhone11のようなバージョンごとに登録するのか?それともさらに細かいiPhone10 ブラック、iPhone10 シルバーのようにバージョン+色で登録するのか?さらに細かくiPhone10 ブラック 32G、iPhone10 ブラック 64Gのようなバージョン+色+容量でするのか?という観点を決める必要があります。
4-2:キー項目選定
SaaSのパッケージ製品であれば、そもそもキー項目を選定する必要はなく、コード自体もシステムで設定されたコードを利用することなるでしょう。ただし、パッケージ製品でもコード定義が行えるケースやデータベースで構築する場合はこのステップを踏む必要があります。
基本的にキー項目はそのテーブルを一意に識別するキー項目を一つ設定するのが望ましいです。なぜなら、複合キーを設定するとデータの整合性やテーブル変更に課題が生じやすいからです。
ただし、1つのキー項目で一意にならないようなテーブルも存在します。下記図②のような顧客と担当者の組み合わせを管理する顧客別担当者マスタは顧客コードと担当者コードの2つ複合キーとして保持する必要があります。
一方で1顧客に対して1人の担当者が紐づく下記図②のデータモデルは複合キーとはならずに管理が可能です。
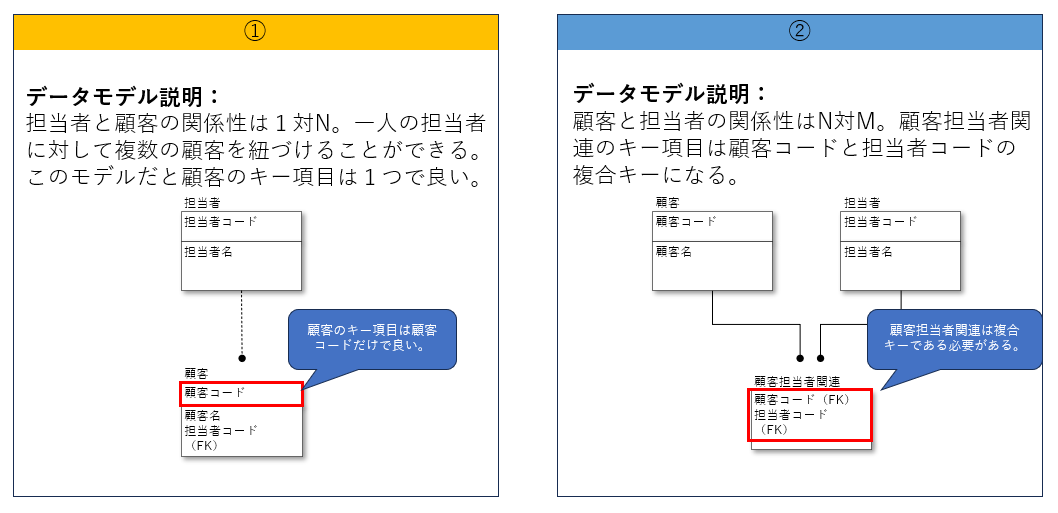
したがって、キー項目の選定は一意になるような項目を1つとすることを目標にしながら、他テーブルとの関係性も考慮して決定する必要があります。
4-3:コード定義
コード定義はキー項目のコード体系を決めることを指します。
コード定義の考え方は以下の通りですが、新規でコード定義を行う場合は、既存システムへの配信など影響度を考慮する必要があります。
①Asisデータモデルで分析した既存システムのコードを利用する。
②新規でコード定義を行う。
②-1:無意味連番コードとする。
②-2:意味ありコードを定義する。
決定したコード体系を項目定義書などに反映させます。
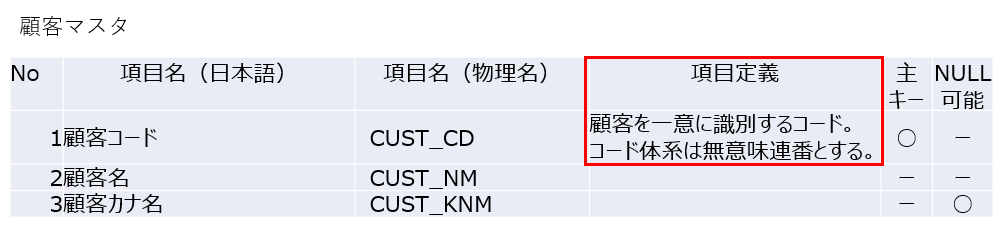
4-4:項目選定
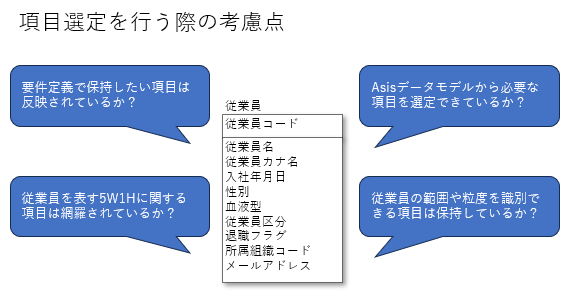
大まかなテーブル定義ができれば、次に保持する項目を検討します。まず上記データモデリングで決めたテーブルの範囲や粒度を識別できる項目を保持させます。具体的には商品マスタにおいては他社商品か自社商品かを識別するフラグを保持する。顧客マスタであれば、顧客区分を持たせて、その範囲を識別します。
次にAsisデータモデルの中で必要な項目や要件定義で必要となった項目を保持させます。例えば、既存システムのAsisデータモデルで頻繁に保持されている項目をTobeデータモデルにも反映することや要件定義で必要となった区分を持たせるなどです。
項目として抜け漏れがないかをチェックする際はそのテーブルに必要な5W1Hを意識して項目を保持させると良いです。例えば、従業員マスタであれば、従業員名や入社年月日など5W1Hにあたるような代表的な項目が抜けていないかチェックします。
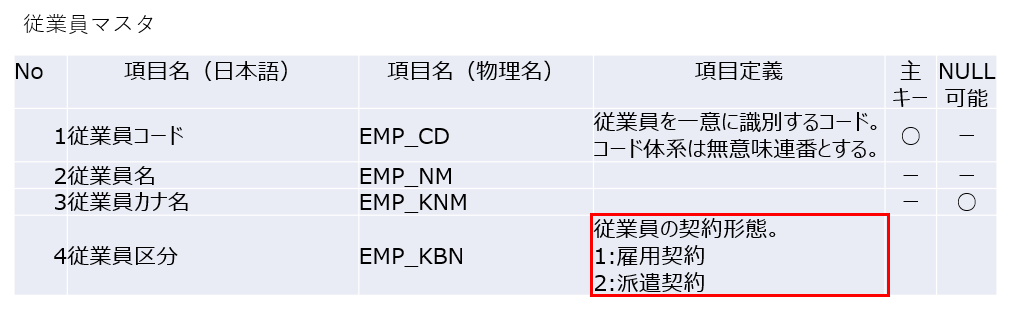
4-5:項目定義
項目定義はその項目の意味や取り得る値などを要件定義時に項目定義書などに反映させます。氏名や血液型など明らかに意味の分かるような項目については項目定義を行う必要はありません。しかし従業員区分などぱっと見で意味や値が分からない項目については項目定義を行う必要があります。
項目定義は4-4のコード定義と同じような形で項目定義書などに反映させます。
4-6:命名ルール
項目を命名する際はその項目の意味が第三者でも分かるような名前にすると良いです。
先ほどの例にあげた従業員区分も従業員の契約形態を指しているのか?新卒、中途などどのように会社に入社したかを表しているのか?など人によって解釈が変わります。
前者の場合であれば従業員契約区分、後者であれば従業員入社区分など意味の取りやすい命名にできると良いです。
また項目の接尾語として0,1しか取らない項目は○○フラグ、2値以上取る項目は○○区分、名称については○○名のような簡単なルールを決めて命名すると統一感のある理解がしやすい項目定義を行えます。