LangChainを使って色々LLMアプリを作って遊んでいます。
体感速度が遅いけど、どこが遅いかわからない
サンプルソースをコピペして作ったので、実は中身のことをわかってない
入力と出力だけじゃなくて、中間の状態も知りたい
みたいなことってありませんか?そんなときに使えるツールを見つけましたのでご紹介します。
環境構築の方法などは前回の内容を参照ください。
トークン数計算
Langfuseにはトークン数と価格を計算する機能があります。Bedrockのモデルの場合は少し設定が必要です。
Modelsメニューを開きます。
モデルごとの価格が設定されています。LangfuseのデフォルトではOpenAIのGPT-4やAnthropicのClaudeなどが登録されています。
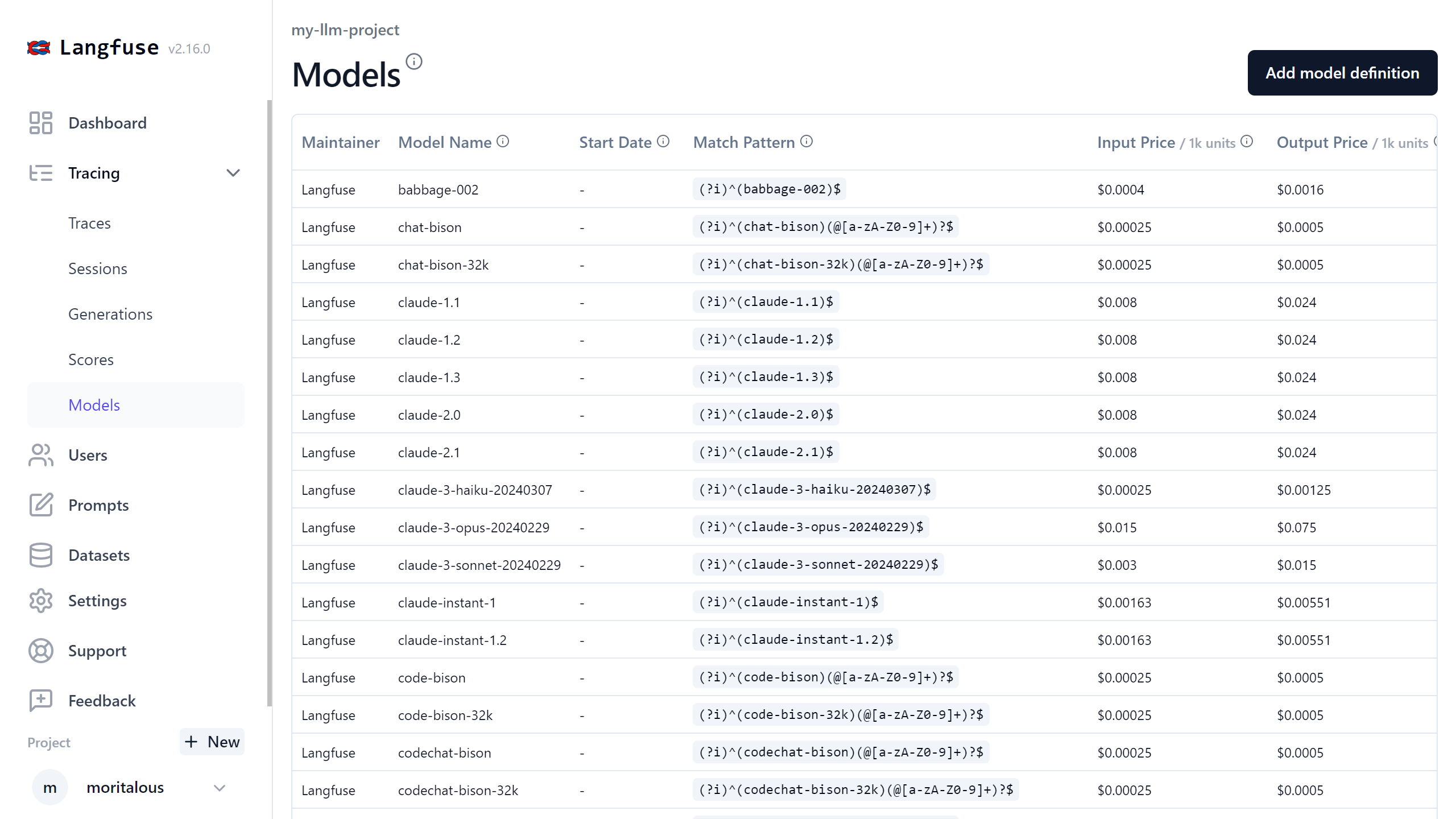
モデル名の正規表現で対応するモデルがある場合にトークン計算が行われますが、Bedrockで使用できるClaudeの場合はマッチしないので、Add model definitionをクリックし、価格情報を登録します。
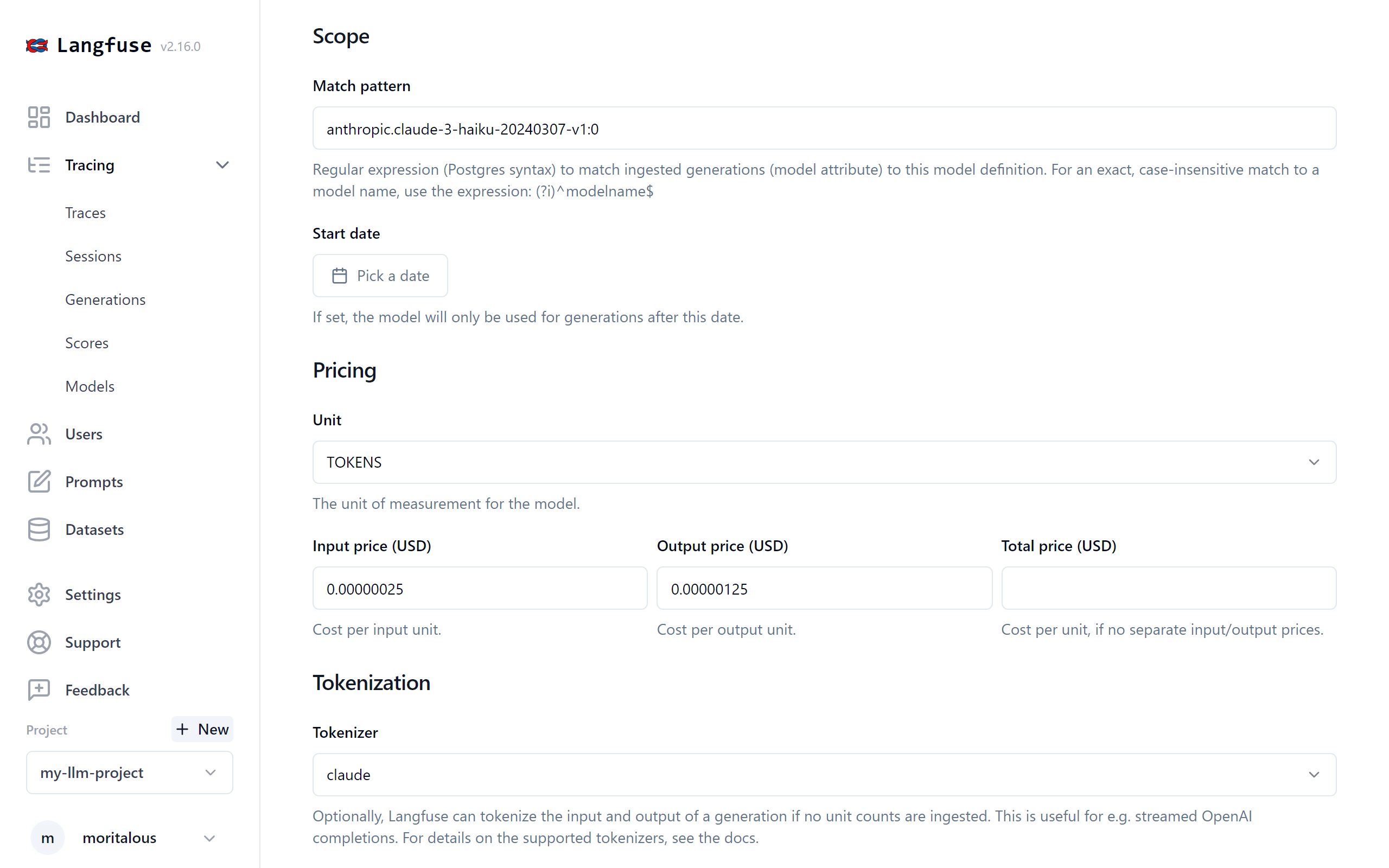
トレース情報がLangfuseに届いたタイミングでモデル情報があれば、トークン数と価格が表示されます。
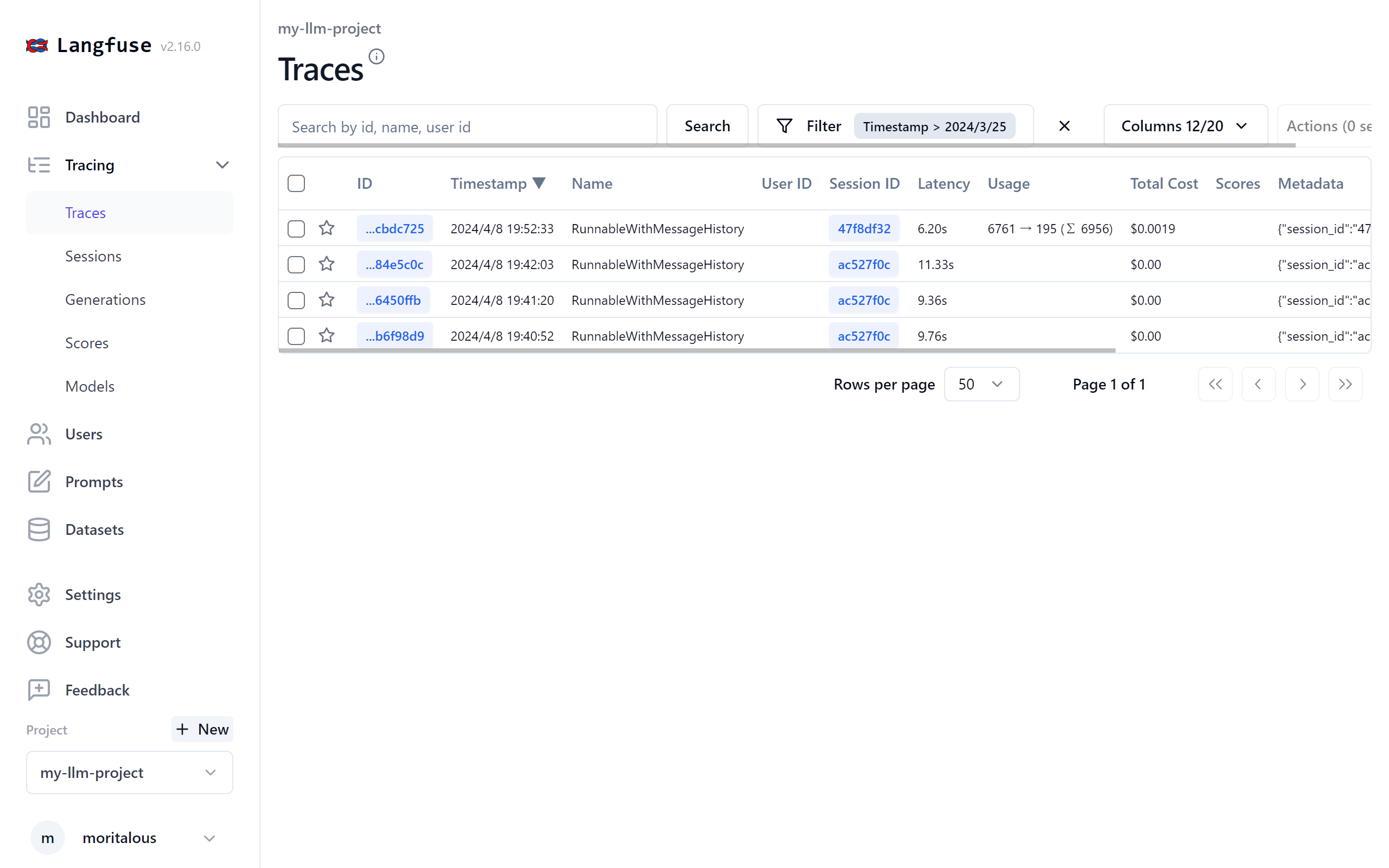
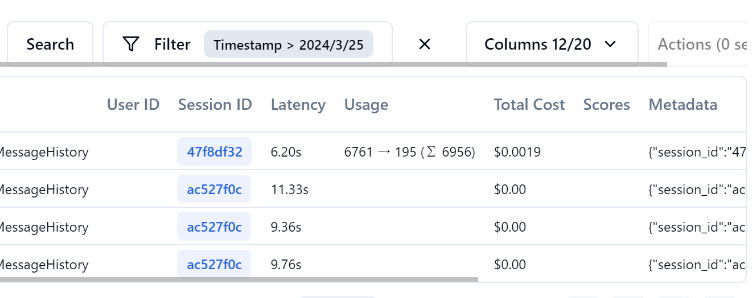
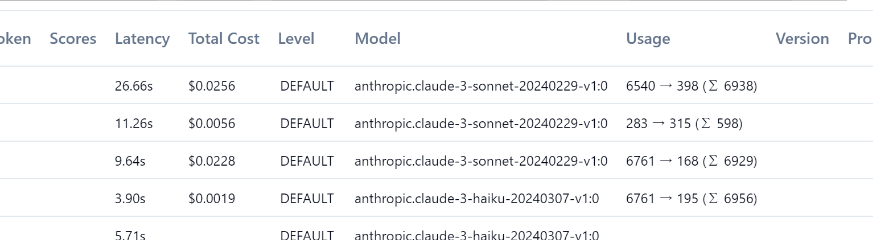
適当に構築したRAGは、一度のやり取りで6700トークンのやり取りがあるようです。以外に多いと感じませんか??
上から3件がClaude 3 Sonnet、4件目がClaude 3 Haikuです。
処理時間が半分以下で値段も10分の1ぐらいです。こういった情報が可視化されるのもいいですね。
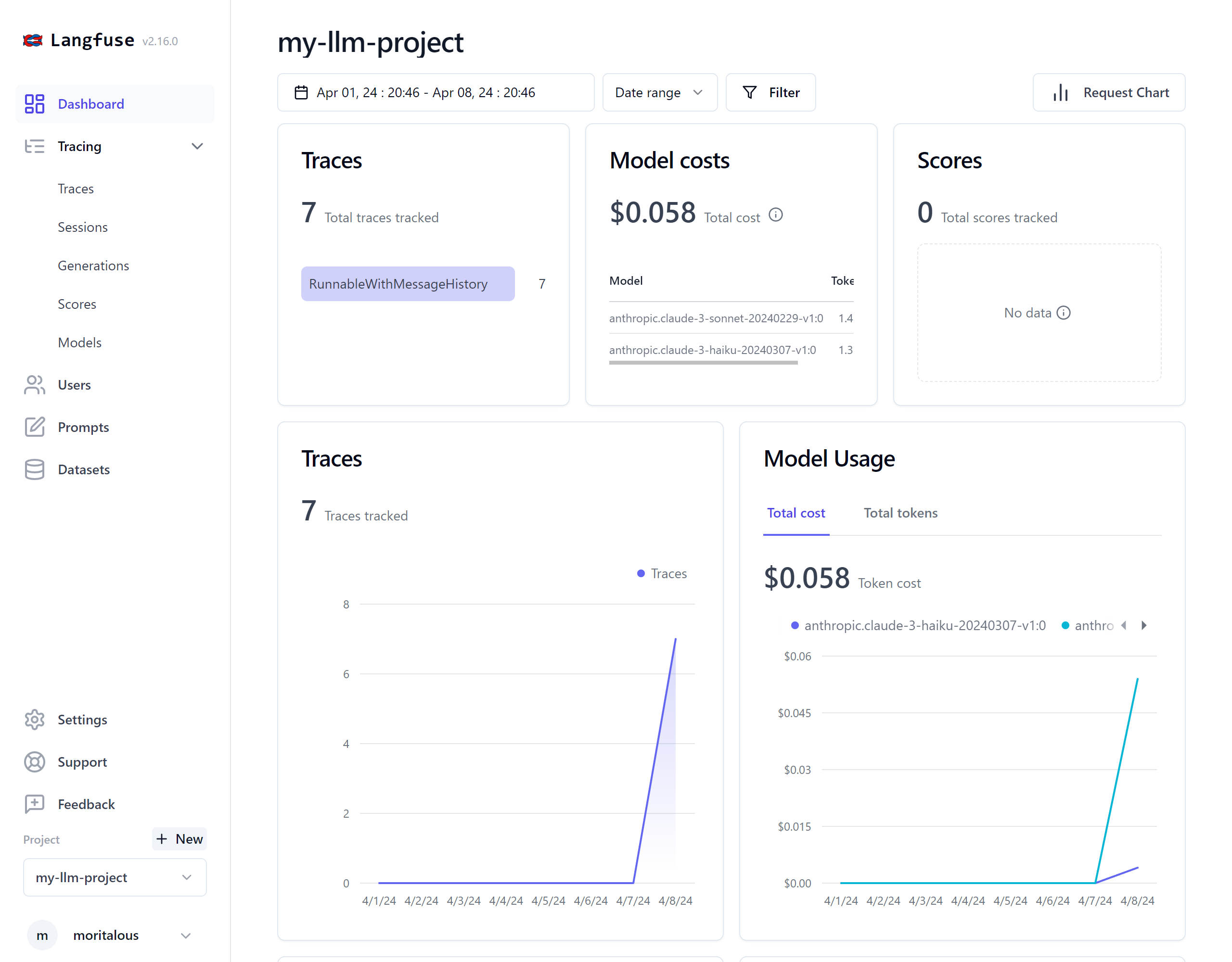
ダッシュボードでも確認できます。
生成AIの評価をする
トレース情報をもとに、生成AIの評価を行います。流れは以下のようなものとなります。
- Langfuseからトレース情報を取得する
- 取得したトレース情報から評価を行う
- 評価結果をLangfuseに登録する
Langfuse自体には評価機能はないようで、他のツールで評価した結果を可視化できるという仕組みのようです。
参考ドキュメント
ドキュメントを読んで知ったのですが、なんと、LangChainに評価機能がある ようです。知らなかった。
LangChainの評価機能で評価を行い、Langfuseと連携してみます。
RAGの評価ツールとしてはRagasが有名です。
-
準備
import os os.environ["LANGFUSE_SECRET_KEY"] = "sk-lf-8031e607-0777-4abd-8d7d-ba4ed79db1fd" os.environ["LANGFUSE_PUBLIC_KEY"] = "pk-lf-f43905de-138c-43de-a81f-66ada70cd1fa" os.environ["LANGFUSE_HOST"] = "http://localhost:3000" from langfuse import Langfuse langfuse = Langfuse() -
LangfuseからGenerations(生成AIの部分)のデータを取得
generations = langfuse.get_generations(limit=100) -
評価器を生成する
from langchain.evaluation import Criteria, EvaluatorType, load_evaluator from langchain_community.chat_models import BedrockChat evaluator = load_evaluator( EvaluatorType.CRITERIA, criteria=Criteria.CONCISENESS.value, llm=BedrockChat( model_id="anthropic.claude-3-haiku-20240307-v1:0", model_kwargs={ "temperature": 1, }, ), ) -
評価を実行する
eval_result = evaluator.evaluate_strings( input=generations.data[0].input, prediction=generations.data[0].output )簡単!
-
評価結果をLangfuseに登録する
langfuse.score( name=Criteria.CONCISENESS.value, trace_id=generations.data[0].trace_id, observation_id=generations.data[0].id, value=eval_result["score"], comment=eval_result["reasoning"], )
以上です。
複数の評価指標で、複数データの処理を行う場合はこんな感じです。
from langchain.evaluation import Criteria, EvaluatorType, load_evaluator
from langchain_community.chat_models import BedrockChat
CRITERIA = [
Criteria.CONCISENESS,
Criteria.RELEVANCE,
Criteria.COHERENCE,
Criteria.HELPFULNESS,
]
for c in CRITERIA:
evaluator = load_evaluator(
EvaluatorType.CRITERIA,
criteria=c.value,
llm=BedrockChat(
model_id="anthropic.claude-3-haiku-20240307-v1:0",
model_kwargs={
"temperature": 1,
},
),
)
for generation in generations.data:
eval_result = evaluator.evaluate_strings(
input=generation.input, prediction=generation.output
)
langfuse.score(
name=c.value,
trace_id=generation.trace_id,
observation_id=generation.id,
value=eval_result["score"],
comment=eval_result["reasoning"],
)
これを定期的に実行すればOKです。
Langfuseの画面で見てみましょう。
Generations画面

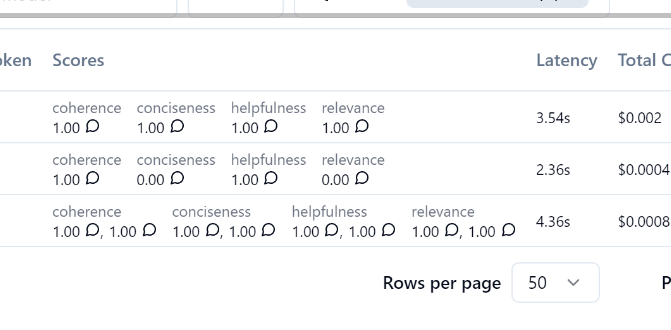
3行目に値が2個登録されているのは2回実行したからです。。一度登録したデータの消し方がわかりませんでした。。
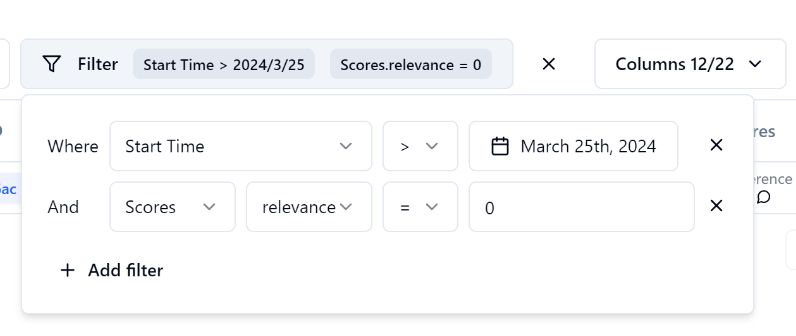
フィルタリングできるので、評価の悪いものだけをピックアップしたりできます。
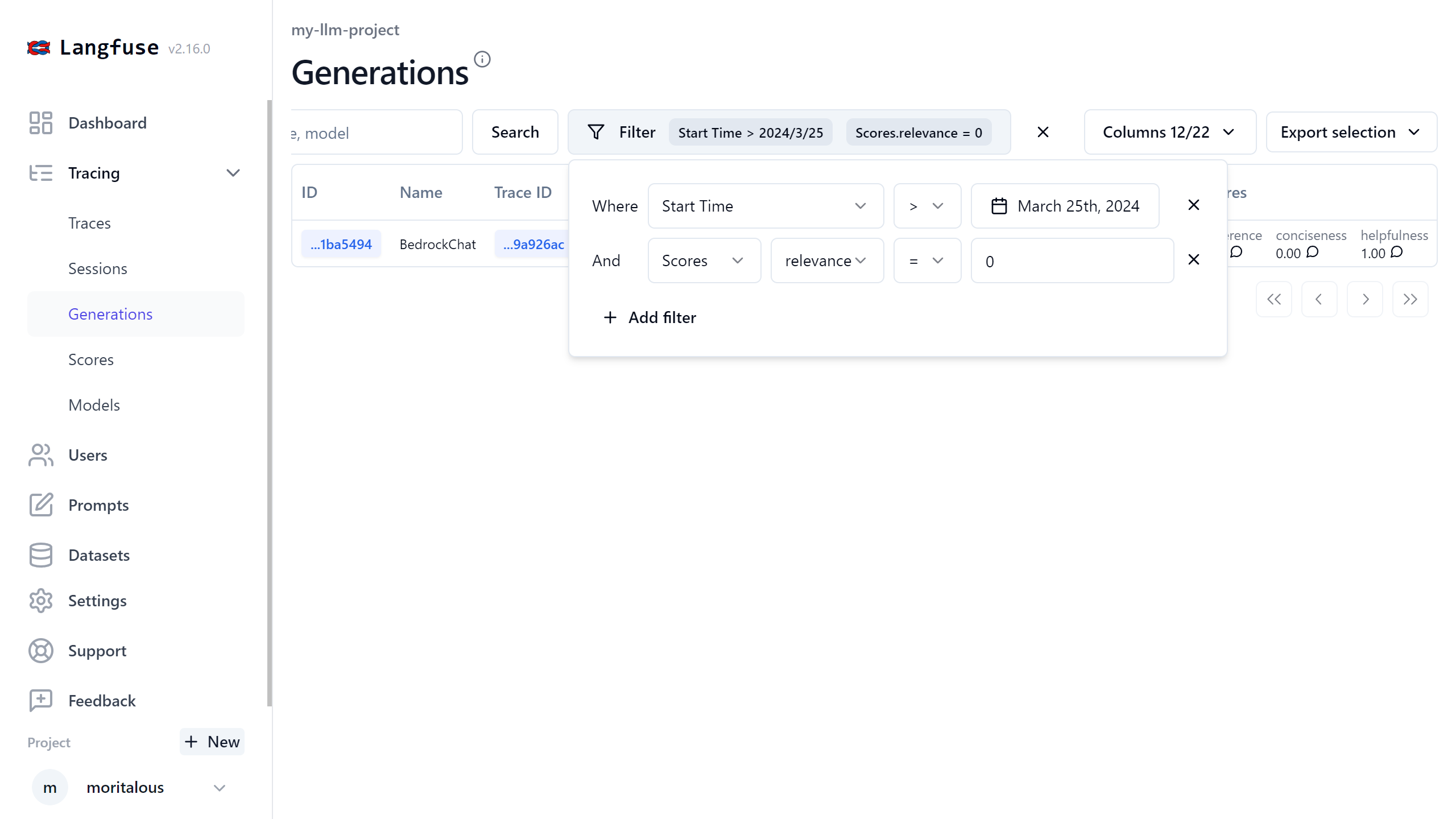
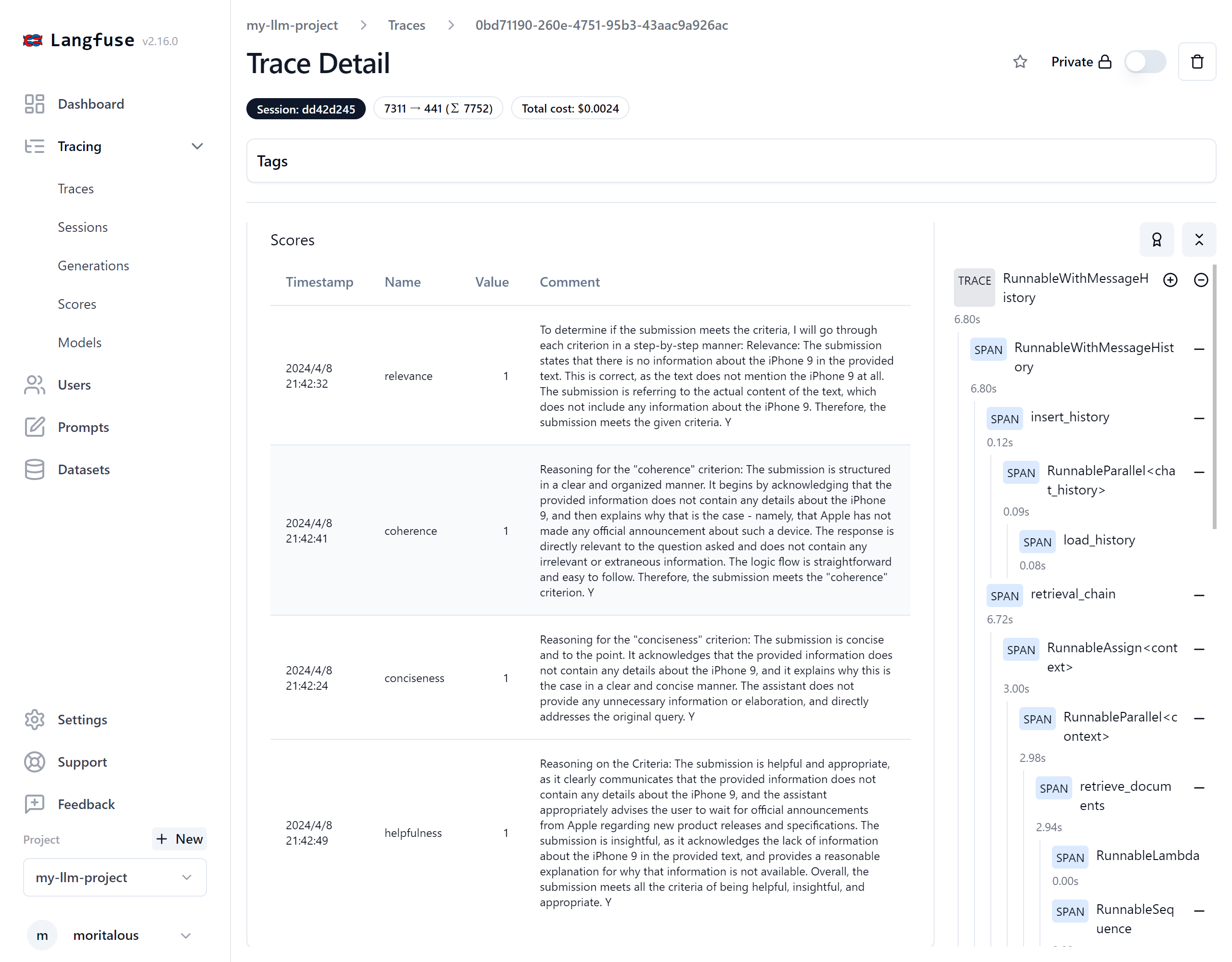
Traceの画面では、評価の値と、評価の理由が表示されます。
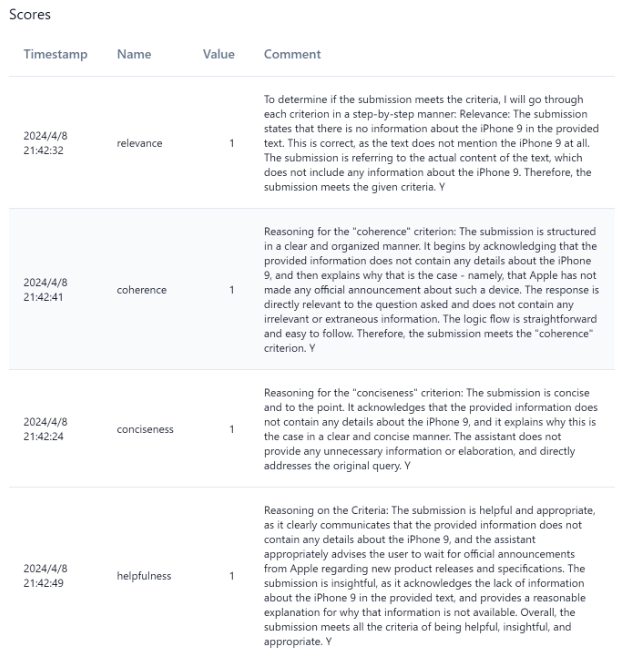
素晴らしい。
まとめ
Langfuseのトークン数算機能と評価機能について紹介しました。
まだ続くかもなので、いいねとストックをしてお待ち下さい(笑)