AWS上でAIを実現する場合は通常SageMakerを使いますが、軽量なモデルを使う場合であればサーバーレスで実現することもできると思い環境を構築しました。実際に構築することで得た知見を5つ紹介します。
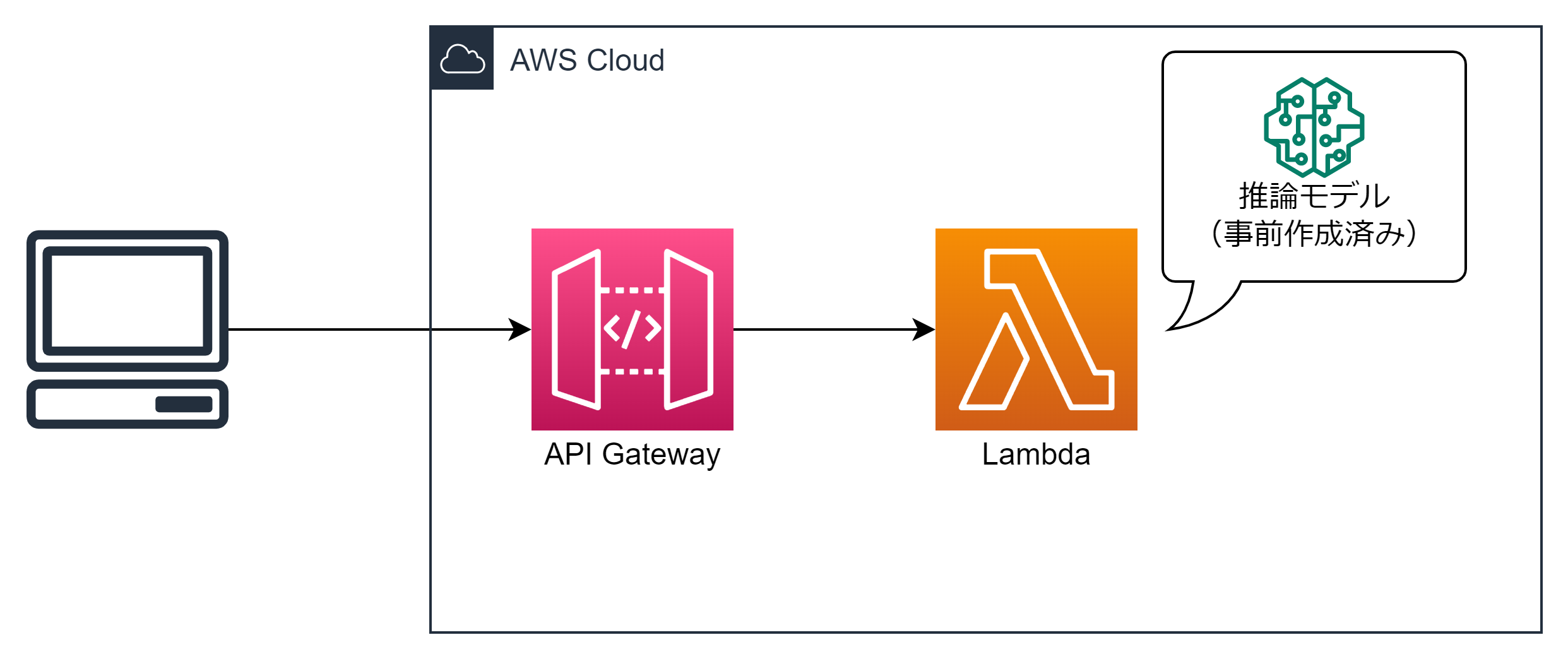
以下のチュートリアルで作成した犬と猫を見分けるモデルを使用しました。
// 余談ですが、言語表示を英語にすると、犬と猫の識別ではなく、花の分類に題材が変わります。
TenslorFlowのライブラリーはCPU版を指定する
Lambdaでの推論はCPUで行いますので、TensorFlowのライブラリーもCPU版を指定します。
また、内部で使用するKerasのバージョンも合わせておかないとエラーとなります。
- requirements.txt
https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow_cpu-2.6.0-cp39-cp39-manylinux2010_x86_64.whl
keras==2.6.0
Kerasとのバージョン不一致時のエラー
[ERROR] AlreadyExistsError: Another metric with the same name already exists.
LambdaのパッケージはZIPではなくコンテナを選択する
Lambdaのサービス制限で以下の決まりがあります。
| 項目 | 条件 |
|---|---|
| デプロイパッケージ (.zip ファイルアーカイブ) のサイズ | 50 MB (zip 圧縮済み、直接アップロード) 250 MB (解凍後)このクォータは、レイヤーやカスタムランタイムなど、アップロードするすべてのファイルに適用されます。 3 MB (コンソールエディタ) |
| コンテナイメージのコードパッケージサイズ | 10 GB |
圧縮済みzipで300MB超、展開後で1GB超のサイズとなるため、zipでのデプロイは失敗します。
コンテナイメージのサイズは約1.7GBですのでデプロイ可能です。
API Gatewayの種類はHTTP APIだと画像の扱いが簡単
API GatewayにはREST APIとHTTP APIがあり、どちらもバイナリデータを受け取ることが可能です。REST APIの場合は明示的にバイナリデータを受信する設定が必要ですが、HTTP APIでは特に設定なく受信ができました。
バイナリデータを受信した際にAPI GatewayでBase64に変換され、lambda_handlerに渡されます。event[’isBase64Encoded’]がTrueとなり、event[’body’]にBase64されたHTTPボディが格納されます。base64.b64decode(event['body'])とすることで画像ファイルのバイナリが受け取れます。
少し横道にそれますが、以下のような(古き良き)フォームで画像データをアップロードする場合は、multipart/form-data形式でのアップロードとなります。
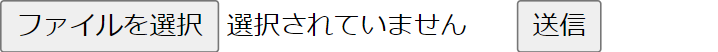
<form action="https://x.x.x.x/predict" method="POST" enctype="multipart/form-data">
<input type="file" name="file" value="file">
<input type="submit">
</form>
multipart/form-data形式の場合はHTTPボディに画像のバイナリ以外の情報も含まれるため、考慮が必要です。自前で行うのは大変なので、requests-toolbeltというライブラリーを使用することで簡単に画像部分が取得できます。
import base64
from requests_toolbelt.multipart import decoder
content_type = event['headers']['content-type']
decode_body = base64.b64decode(event['body'])
multipart_body = decoder.MultipartDecoder(decode_body, content_type)
for part in multipart_body.parts:
try:
c_type = part.headers.get(b'Content-Type')
if c_type and c_type == b'image/jpeg':
return part.content
except:
pass
- 参考サイト
https://pypi.org/project/requests-toolbelt/
https://developer.mozilla.org/ja/docs/Web/HTTP/Methods/POST
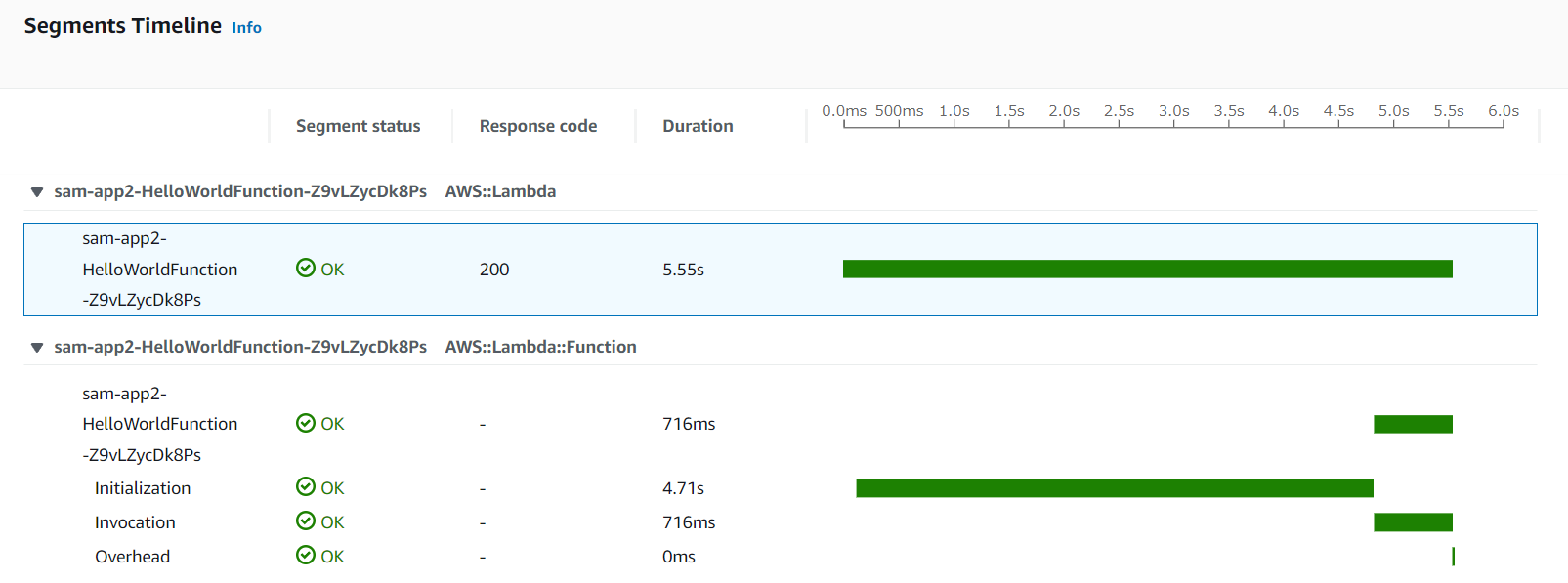
コールドスタートは気になるが使えないことはない
Lambdaで気になるのがコールドスタートですが、数回試した限り、Initializationで5秒程度でした。lambda_handler内の推論処理は1秒かからず終わっていますので、簡単な処理であれば実用的かもしれません。(メモリの割当は1GB。)
AutoGluonで作成したモデルは動作しない
AutoGluonはAutoML の OSS のフレームワークです。3行でモデルが作れるよというのが売りです。
犬と猫を見分けるAIについてはデータセットのダウンロードから含めて5行です。
pets = ag.utils.download('https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip')
pets = ag.utils.unzip(pets)
train_data, _, test_data = ImageDataset.from_folders('cats_and_dogs_filtered', train='train', test='validation')
predictor = ImagePredictor()
predictor.fit(train_data, hyperparameters={'epochs': 2}) # you can trust the default config, we reduce the # epoch to save some build time
モデルは簡単に作れたのですが、残念ながらLambda上では推論実行時に以下のエラーモデルは簡単に作れたのですが、残念ながらLambda上では推論実行時に以下のエラーとなり、実行できません。となり、実行できません。
[ERROR] OSError: [Errno 38] Function not implemented
Traceback (most recent call last):
File "/var/task/app.py", line 72, in lambda_handler
result = predictor.predict(file_pass)
File "/var/lang/lib/python3.9/site-packages/autogluon/vision/predictor/predictor.py", line 579, in predict
proba = self._classifier.predict(data)
File "/var/lang/lib/python3.9/site-packages/gluoncv/auto/estimators/base_estimator.py", line 199, in predict
return self._predict(x, **kwargs)
File "/var/lang/lib/python3.9/site-packages/gluoncv/auto/estimators/torch_image_classification/torch_image_classification.py", line 631, in _predict
return self._predict((x,), **kwargs).drop(columns=['image'], errors='ignore')
File "/var/lang/lib/python3.9/site-packages/gluoncv/auto/estimators/torch_image_classification/torch_image_classification.py", line 655, in _predict
for input, _ in loader:
File "/var/lang/lib/python3.9/site-packages/torch/utils/data/dataloader.py", line 354, in __iter__
self._iterator = self._get_iterator()
File "/var/lang/lib/python3.9/site-packages/torch/utils/data/dataloader.py", line 305, in _get_iterator
return _MultiProcessingDataLoaderIter(self)
File "/var/lang/lib/python3.9/site-packages/torch/utils/data/dataloader.py", line 891, in __init__
self._worker_result_queue = multiprocessing_context.Queue() # type: ignore[var-annotated]
File "/var/lang/lib/python3.9/multiprocessing/context.py", line 103, in Queue
return Queue(maxsize, ctx=self.get_context())
File "/var/lang/lib/python3.9/multiprocessing/queues.py", line 43, in __init__
self._rlock = ctx.Lock()
File "/var/lang/lib/python3.9/multiprocessing/context.py", line 68, in Lock
return Lock(ctx=self.get_context())
File "/var/lang/lib/python3.9/multiprocessing/synchronize.py", line 162, in __init__
SemLock.__init__(self, SEMAPHORE, 1, 1, ctx=ctx)
File "/var/lang/lib/python3.9/multiprocessing/synchronize.py", line 57, in __init__
sl = self._semlock = _multiprocessing.SemLock(
[ERROR] OSError: [Errno 38] Function not implemented Traceback (most recent call last): File "/var/task/app.py", line 72, in lambda_handler result = predictor.predict(file_pass) File "/var/lang/lib/python3.9/site-packages/autogluon/vision/predictor/predictor.py", line 579, in predict proba = self._classifier.predict(data) File "/var/lang/lib/python3.9/site-packages/gluoncv/auto/estimators/base_estimator.py", line 199, in predict return self._predict(x, **kwargs) File "/var/lang/lib/python3.9/site-packages/gluoncv/auto/estimators/torch_image_classification/torch_image_classification.py", line 631, in _predict return self._predict((x,), **kwargs).drop(columns=['image'], errors='ignore') File "/var/lang/lib/python3.9/site-packages/gluoncv/auto/estimators/torch_image_classification/torch_image_classification.py", line 655, in _predict for input, _ in loader: File "/var/lang/lib/python3.9/site-packages/torch/utils/data/dataloader.py", line 354, in __iter__ self._iterator = self._get_iterator() File "/var/lang/lib/python3.9/site-packages/torch/utils/data/dataloader.py", line 305, in _get_iterator return _MultiProcessingDataLoaderIter(self) File "/var/lang/lib/python3.9/site-packages/torch/utils/data/dataloader.py", line 891, in __init__ self._worker_result_queue = multiprocessing_context.Queue() # type: ignore[var-annotated] File "/var/lang/lib/python3.9/multiprocessing/context.py", line 103, in Queue return Queue(maxsize, ctx=self.get_context()) File "/var/lang/lib/python3.9/multiprocessing/queues.py", line 43, in __init__ self._rlock = ctx.Lock() File "/var/lang/lib/python3.9/multiprocessing/context.py", line 68, in Lock return Lock(ctx=self.get_context()) File "/var/lang/lib/python3.9/multiprocessing/synchronize.py", line 162, in __init__ SemLock.__init__(self, SEMAPHORE, 1, 1, ctx=ctx) File "/var/lang/lib/python3.9/multiprocessing/synchronize.py", line 57, in __init__ sl = self._semlock = _multiprocessing.SemLock(
調べてみると、LambdaではPythonのmultiprocessing.Queueとmultiprocessing.Poolは動作しない制約があるようです。(参考サイト:https://aws.amazon.com/jp/blogs/compute/parallel-processing-in-python-with-aws-lambda/)
ログを見る限りPyTorch内部でこの処理が使われているため、回避することができませんでした。
AutoGluonのサイトにはLambdaへのデプロイ方法が紹介されていますが、おそらく画像を使わないテーブルデータに対する推論の場合のみ適用できるのだと思います。残念。