昨日、JAWS PANKRATION 2024に登壇し、「The Ultimate RAG Showdown」という内容で登壇させていただきました。
AWS上で以下の構成でRAGを作って対決させる内容です。
- Knowledge Bases for Amazon Bedrock
- Kendraを使ったRAG
- OpenSearch Serviceを使ったRAG
アーカイブ動画も公開されるようですので、その際はご確認いただければと思います。
AWS上で構築する検証が間に合わず、発表に含められなかったのですが、GraphRAGをローカル環境で構築できましたので、記事にさせていただきます。
Neo4jの起動
Docker Composeを使って起動します。
services:
neo4j:
image: neo4j:5.22.0-community
restart: always
environment:
- NEO4J_apoc_export_file_enabled=true
- NEO4J_apoc_import_file_enabled=true
- NEO4J_apoc_import_file_use__neo4j__config=true
- NEO4J_PLUGINS=["apoc"]
- NEO4J_AUTH=neo4j/password
volumes:
- ./volume/logs:/logs
- ./volume/data:/data
ports:
- 7474:7474
- 7687:7687
docker compose up
ライブラリーのインストール
pip install \
llama-index \
llama-index-llms-openai \
llama-index-embeddings-openai \
llama-index-graph-stores-neo4j \
llama-index-readers-wikipedia \
wikipedia
GraphRAGを構築
-
LLM、Embeddingを定義
APIキーは環境変数にセットしてください。
from llama_index.core.settings import Settings from llama_index.embeddings.openai import OpenAIEmbedding from llama_index.llms.openai import OpenAI llm = OpenAI(model="gpt-4o-mini") embedding = OpenAIEmbedding(model_name="text-embedding-3-small") Settings.llm = llm Settings.embed_model = embedding -
Readerを作成
Wikipediaから北斗の拳のラオウのページを取得しました。
from llama_index.readers.wikipedia import WikipediaReader reader = WikipediaReader() documents = reader.load_data(pages=["ラオウ"], lang_prefix="ja") -
Property Graph Storeを作成
いよいよGraphRAGっぽいところに踏み込んできました。まず、プロパティグラフストアを作成します。
Neo4jの接続先情報を指定します。from llama_index.graph_stores.neo4j import Neo4jPropertyGraphStore graph_store = Neo4jPropertyGraphStore( username="neo4j", password="password", url="bolt://localhost:7687", ) -
Property Graph Indexを作成
つづいてプロパティグラフインデックスを作成します。
from llama_index.core import PropertyGraphIndex from llama_index.core.indices.property_graph import SimpleLLMPathExtractor index = PropertyGraphIndex.from_existing( embed_model=embedding, kg_extractors=[ SimpleLLMPathExtractor(), ], property_graph_store=graph_store, show_progress=True, )kg_extractorsには、ナレッジグラフを抽出する処理を指定します。
LlamaIndexのクックブック(これやこれ)では、独自でプログラムを記述していたのですが、LlamaIndexであらかじめ用意されている「SimpleLLMPathExtractor」を使用します。
(他にDynamicLLMPathExtractorやSchemaLLMPathExtractorが用意されています)SimpleLLMPathExtractorのデフォルトで指定されているプロンプトはこちら
Some text is provided below. Given the text, extract up to 10 knowledge triplets in the form of (subject, predicate, object). Avoid stopwords. --------------------- Example:Text: Alice is Bob's mother.Triplets: (Alice, is mother of, Bob) Text: Philz is a coffee shop founded in Berkeley in 1982. Triplets: (Philz, is, coffee shop) (Philz, founded in, Berkeley) (Philz, founded in, 1982) --------------------- Text: {{ここにチャンク分割したドキュメントが入ります}} Triplets:LLMの抽出結果は以下のようなものです。(デフォルトではチャンクごとに10個の関係を生成します)
(カイオウ, 知っていた, ラオウの死亡) (ラオウ, 知っていた, 幼い頃の仕打ち) (ラオウ, 言い残していた, ケンシロウに伝えるよう) (ラオウ, 尊敬していた, 兄の哀しみ) (ラオウ, 実子がいる, リュウ) (ケンシロウ, 戻ってきた, 修羅の国から) (ケンシロウ, 説いた, 北斗神拳の真髄) (ケンシロウ, 説いた, ラオウの生きざま) (バルガ, 預けた, リュウを) (バルガ, 信頼できる, ラオウの忠臣) -
Indexにドキュメントを登録
以下の方法で登録します。
for document in documents: index.insert(document)PropertyGraphIndex.from_documentsでも良いのですが、個別に登録したかったのでこの方法を採用しましたinsert処理では、以下の処理を行われます。- ドキュメントをチャンクに分割
- チャンクごとにkg_extractorを使って、ナレッジグラフの関係をLLMにて生成
- 関係のエンティティ部分をEmbeddingモデルで埋め込み
- Neo4jに登録
これでGraphRAGが完成しました。意外と簡単にできましたね。
ナレッジグラフの確認
http://localhost:7474/にアクセスすると、Neo4jの管理画面が表示されます。
ユーザー名とパスワードを入力し、ログインします。
neo4j$と書かれている部分に、Cypherというクエリ言語を使って問い合わせができます。
試しに、MATCH(n) RETURN nと入力します。
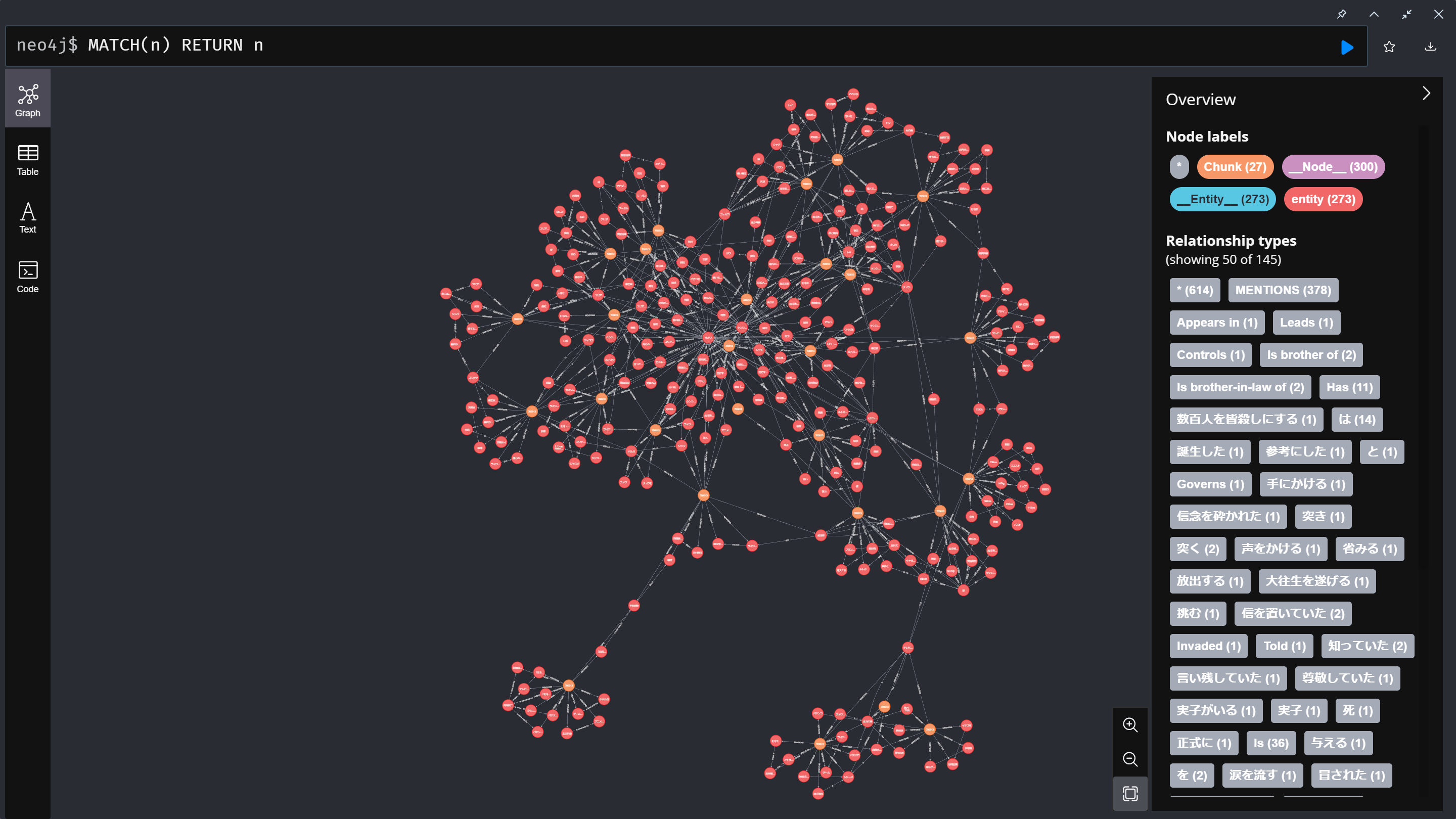
一度に表示できるのは300個までのようです。
ラオウを中心に拡大すると、このようになります。
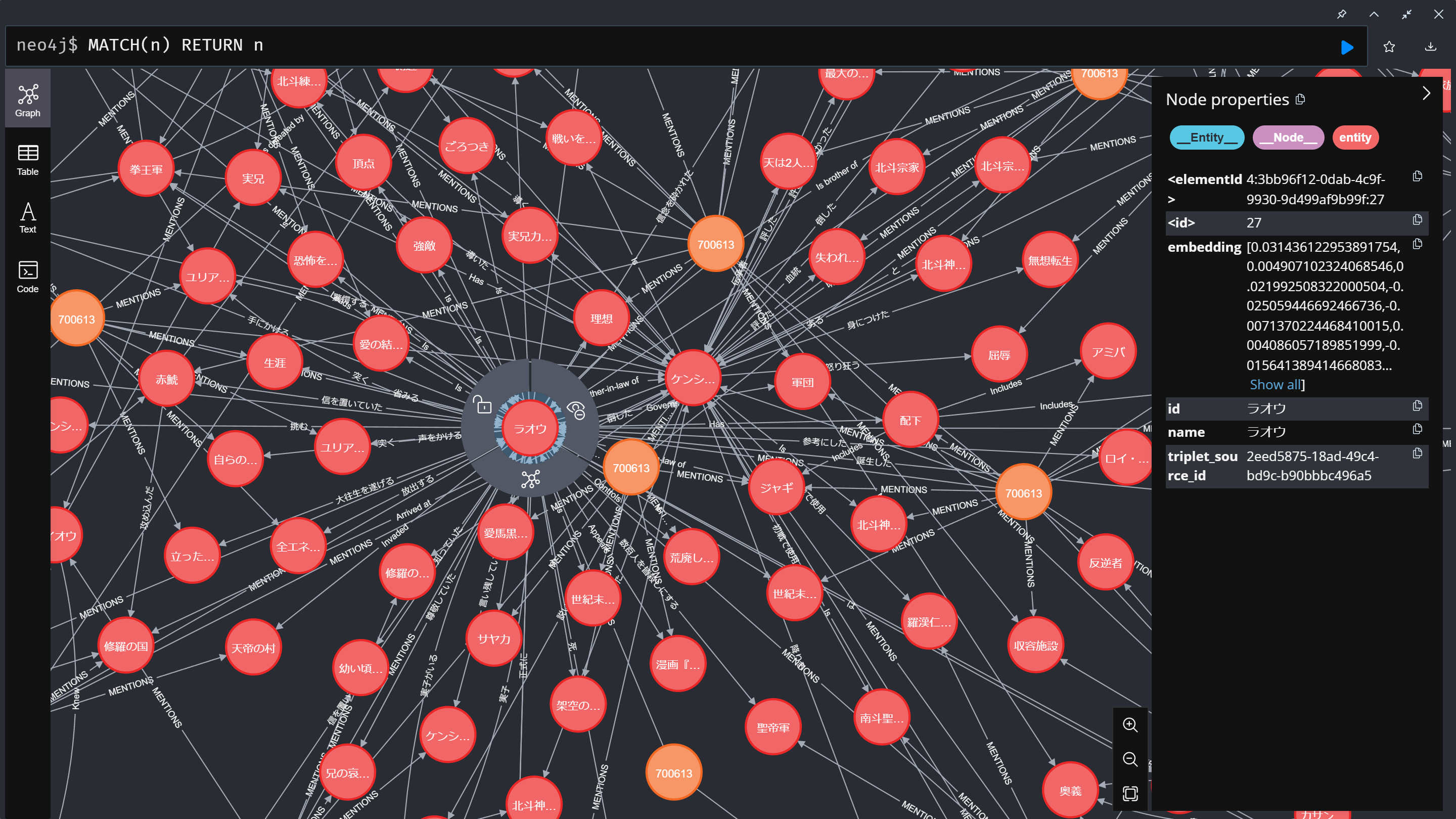
オレンジの丸がチャンクで、赤の丸がエンティティです。線の上に書かれた文字が関係です。
オレンジの「チャンク情報」から、LLMを使って赤の「エンティティ情報」と、「関係」の線を生成させています。
GraphRAGの利用
検索
単純な検索を行う場合は、retrieverを使用します。
retriever = index.as_retriever(
include_text=False,
)
query = "ラオウの兄弟の名前を教えて"
results = retriever.retrieve(query)
for record in results:
print(record.text)
バルガ ({'name': 'バルガ', 'triplet_source_id': '3b36f92a-a715-46f7-afd7-8768846a39dd'}) -> 信頼できる ({'triplet_source_id': '68ba72e0-7e41-4136-9081-3c401d4d1302'}) -> ラオウの忠臣 ({'name': 'ラオウの忠臣', 'triplet_source_id': '68ba72e0-7e41-4136-9081-3c401d4d1302'})
ラオウ ({'name': 'ラオウ', 'triplet_source_id': '2eed5875-18ad-49c4-bd9c-b90bbbc496a5'}) -> Appears in ({'triplet_source_id': '2dbe8c47-2015-49a1-98db-84087bfd01e1'}) -> 漫画『北斗の拳』 ({'name': '漫画『北斗の拳』', 'triplet_source_id': '2dbe8c47-2015-49a1-98db-84087bfd01e1'})
ラオウ ({'name': 'ラオウ', 'triplet_source_id': '2eed5875-18ad-49c4-bd9c-b90bbbc496a5'}) -> Leads ({'triplet_source_id': '2dbe8c47-2015-49a1-98db-84087bfd01e1'}) -> 拳王軍 ({'name': '拳王軍', 'triplet_source_id': '75751dc8-8f90-46f4-8cbc-8c568f29f0f7'})
ラオウ ({'name': 'ラオウ', 'triplet_source_id': '2eed5875-18ad-49c4-bd9c-b90bbbc496a5'}) -> Controls ({'triplet_source_id': '2dbe8c47-2015-49a1-98db-84087bfd01e1'}) -> 荒廃した世界 ({'name': '荒廃した世界', 'triplet_source_id': '2dbe8c47-2015-49a1-98db-84087bfd01e1'})
ラオウ ({'name': 'ラオウ', 'triplet_source_id': '2eed5875-18ad-49c4-bd9c-b90bbbc496a5'}) -> Is brother of ({'triplet_source_id': '2dbe8c47-2015-49a1-98db-84087bfd01e1'}) -> トキ ({'name': 'トキ', 'triplet_source_id': '2039d68a-cbb7-494f-a033-9e7bcc931ff9'})
ユーザーの質問文でNeo4jに問い合わせているだけなので、LLMやEmbeddingは使用しません。
検索と回答生成
検索だけでなく回答生成も合わせて行う場合は、queryを使用します。
query_engine = index.as_query_engine()
query = "ラオウの兄弟の名前を教えて"
response = query_engine.query(query)
ラオウの兄弟の名前はトキとサヤカです。
ラオウに妹がいるとは知りませんでした。カイオウは見つからなかったようです。
回答生成のプロンプト
以下のようなプロンプトで回答を生成しています。
You are an expert Q&A system that is trusted around the world.
Always answer the query using the provided context information, and not prior knowledge.
Some rules to follow:
1. Never directly reference the given context in your answer.
2. Avoid statements like 'Based on the context, ...' or 'The context information ...' or anything along those lines.
Context information is below.
---------------------
Here are some facts extracted from the provided text:
{{ここに検索結果が入ります。関係性の情報とチャンク分割したドキュメントが入ります}}
Query: {{ここにユーザーのクエリが入ります。}}
Answer:
感想
面白いアプローチだと思いましたが、通常のRAGとの違いについては追加で検証が必要だと感じました。今までのRAGを置き換えるものなのか、ユースケースによって向き不向きがあるのかわからずでした。
通常RAGとGraphRAGのハイブリッドとか出てくるのかな。?
あと、ナレッジグラフ作成の際にLLMを使用します。通常のRAGの場合は、Embeddingsだけでよいのですが、LLMも呼び出すので、利用料が心配です。
チャンクからナレッジグラフを生成するので、チャンクはある程度小さいほうが、情報の見逃しがないのかなと思ったりしました。
おまけ Bedrockを使いたい場合
LlamaIndexはBedrockに対応しているため、プログラム上はLLMを切り替えるだけで良いのですが、ドキュメントを登録しようとすると、エラーが発生しました。エラーメッセージを見る限り、LLMごとにメッセージフォーマットが異なることに起因しているようでした。
どうしてもBedrockを使用したい場合は、LiteLLMを間に挟むことで、エラーを起こさず動作することを確認しました。
pip install \
llama-index-llms-litellm \
llama-index-embeddings-litellm \
boto3
from llama_index.embeddings.litellm import LiteLLMEmbedding
from llama_index.llms.litellm import LiteLLM
llm = LiteLLM(model="bedrock/anthropic.claude-3-haiku-20240307-v1:0")
embedding = LiteLLMEmbedding(model_name="bedrock/amazon.titan-embed-text-v2:0")
OpenAIで行った際は発生しなかったのですが、Claude 3 Haikuの場合には、ナレッジグラフの関係作成の結果が英語になることがありました。(ラオウがRaohに)
全部英語になるわけではなく、日本語と英語が混ざる形のため、ナレッジグラフがあまり上手につくれないかも?と思いました。