こちらのブログを見まして、そもそもGraphRAGがなんなのかわかってないですが、PropertyGraphStoreってのに対応したようです。
とっつきやすそうなサンプルが、LlamaIndexのドキュメントにありましたので、やってみました。
参考:https://docs.llamaindex.ai/en/stable/module_guides/indexing/lpg_index_guide/
とにかくやってみた
LLMにはBedrockを使用し、どのようなプロンプトが投げられているかの確認にLangfuseを使用しました。
-
Langfuseを立ち上げる
git clone https://github.com/langfuse/langfuse.git cd langfuse docker compose upブラウザでアクセスし、初期設定を行います。
-
ライブラリーをインストール
pip install -qU \ llama-index \ llama-index-readers-file \ llama-index-llms-bedrock \ llama-index-embeddings-bedrock \ langfuse -
サンプルデータをダウンロード
LlamaIndexの用意しているデータセットは、CLIでダウンロードできます。
参考:https://llamahub.ai/l/llama_datasets/Paul%20Graham%20Essay?from=
llamaindex-cli download-llamadataset PaulGrahamEssayDataset --download-dir ./PaulGrahamEssayDataset実態は、ここ( https://paulgraham.com/worked.html )の文章のようです。
-
おまじない
import nest_asyncio nest_asyncio.apply() -
Langfuseのコールバックを設定する
from llama_index.core import Settings from llama_index.core.callbacks import CallbackManager from langfuse.llama_index import LlamaIndexCallbackHandler langfuse_callback_handler = LlamaIndexCallbackHandler( public_key="pk-lf-*****", secret_key="sk-lf-*****", host="http://localhost:3000", ) Settings.callback_manager = CallbackManager([langfuse_callback_handler]) -
データを読み込む
from llama_index.core import SimpleDirectoryReader documents = SimpleDirectoryReader("./PaulGrahamEssayDataset/source_files").load_data() -
Bedrockモデルの定義
Claude 3 SonnetとTitan Embeddings V2を使います。
from llama_index.embeddings.bedrock import BedrockEmbedding from llama_index.llms.bedrock import Bedrock llm = Bedrock(model="anthropic.claude-3-sonnet-20240229-v1:0") embedding = BedrockEmbedding(model_name="amazon.titan-embed-text-v2:0") Settings.llm = llm Settings.embed_model = embedding -
PropertyGraphIndexを生成
from llama_index.core import PropertyGraphIndex index = PropertyGraphIndex.from_documents( documents, llm=llm, embed_model=embedding, show_progress=True, )しばらく時間がかかります。
Langfuseを確認すると、ClaudeとTitan Embeddingsがどちらも呼ばれてました。 おそらく、チャンクごとに、ナレッジグラフに必要なトリプレット(?)を生成させているようです。

プロンプトはこんな感じ
Some text is provided below. Given the text, extract up to 10 knowledge triplets in the form of (subject, predicate, object). Avoid stopwords.
---
Example:Text: Alice is Bob's mother.Triplets:
(Alice, is mother of, Bob)
Text: Philz is a coffee shop founded in Berkeley in 1982.
Triplets:
(Philz, is, coffee shop)
(Philz, founded in, Berkeley)
(Philz, founded in, 1982)
---
...
このあとにチャンクのデータが入る -
ネットワークグラフをHTMLで保存
index.property_graph_store.save_networkx_graph(name="./kg.html")こんなのができました。

拡大するとこんな感じ。これがナレッジグラフでしょうか
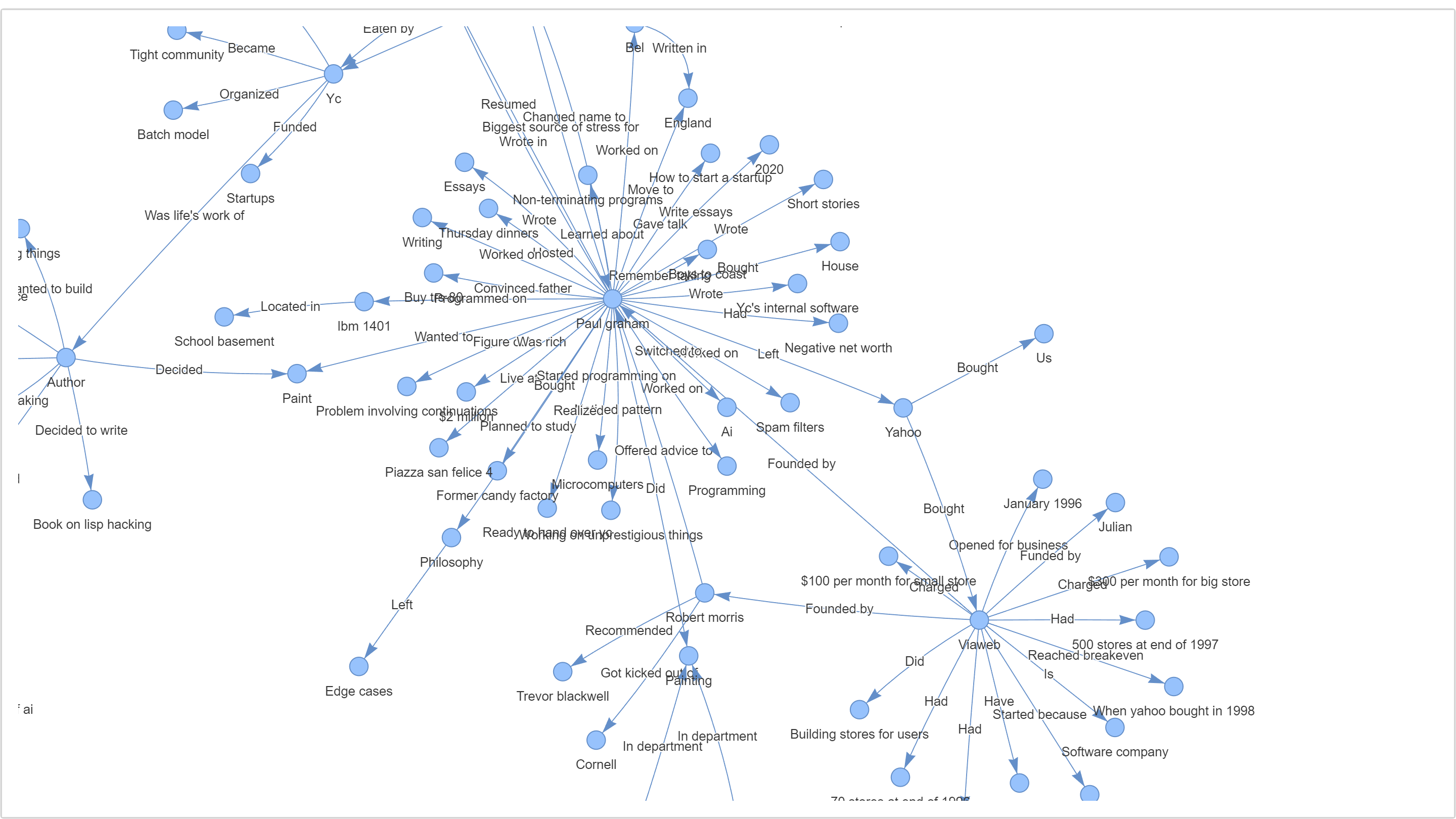
-
retrieveする
なんだかよくわかりませんが、検索できているような感じです。
retriever = index.as_retriever( include_text=False, ) nodes = retriever.retrieve("What happened at Interleaf and Viaweb?") for node in nodes: print(node.text)Viaweb ({'file_path': 'PaulGrahamEssayDataset/source_files/source.txt', 'file_name': 'source.txt', 'file_type': 'text/plain', 'file_size': 75084, 'creation_date': '2024-08-18', 'last_modified_date': '2024-08-18', 'triplet_source_id': '48380066-c484-4dc9-a23a-b5ddc4f1611b'}) -> Funded by ({'file_path': 'PaulGrahamEssayDataset/source_files/source.txt', 'file_name': 'source.txt', 'file_type': 'text/plain', 'file_size': 75084, 'creation_date': '2024-08-18', 'last_modified_date': '2024-08-18', 'triplet_source_id': '7baa0f5a-6505-415b-89f3-0c5b6707f1d6'}) -> Julian ({'file_path': 'PaulGrahamEssayDataset/source_files/source.txt', 'file_name': 'source.txt', 'file_type': 'text/plain', 'file_size': 75084, 'creation_date': '2024-08-18', 'last_modified_date': '2024-08-18', 'triplet_source_id': '7baa0f5a-6505-415b-89f3-0c5b6707f1d6'}) Viaweb ({'file_path': 'PaulGrahamEssayDataset/source_files/source.txt', 'file_name': 'source.txt', 'file_type': 'text/plain', 'file_size': 75084, 'creation_date': '2024-08-18', 'last_modified_date': '2024-08-18', 'triplet_source_id': '48380066-c484-4dc9-a23a-b5ddc4f1611b'}) -> Founded by ({'file_path': 'PaulGrahamEssayDataset/source_files/source.txt', 'file_name': 'source.txt', 'file_type': 'text/plain', 'file_size': 75084, 'creation_date': '2024-08-18', 'last_modified_date': '2024-08-18', 'triplet_source_id': '7baa0f5a-6505-415b-89f3-0c5b6707f1d6'}) -> Paul graham ({'file_path': 'PaulGrahamEssayDataset/source_files/source.txt', 'file_name': 'source.txt', 'file_type': 'text/plain', 'file_size': 75084, 'creation_date': '2024-08-18', 'last_modified_date': '2024-08-18', 'triplet_source_id': '4aa95ad2-0e9c-462e-b009-c5d860889734'}) Viaweb ({'file_path': 'PaulGrahamEssayDataset/source_files/source.txt', 'file_name': 'source.txt', 'file_type': 'text/plain', 'file_size': 75084, 'creation_date': '2024-08-18', 'last_modified_date': '2024-08-18', 'triplet_source_id': '48380066-c484-4dc9-a23a-b5ddc4f1611b'}) -> Had ({'file_path': 'PaulGrahamEssayDataset/source_files/source.txt', 'file_name': 'source.txt', 'file_type': 'text/plain', 'file_size': 75084, 'creation_date': '2024-08-18', 'last_modified_date': '2024-08-18', 'triplet_source_id': '1103479b-0a73-4e1a-9961-40c6cdce0f35'}) -> 70 stores in 1996 ({'file_path': 'PaulGrahamEssayDataset/source_files/source.txt', 'file_name': 'source.txt', 'file_type': 'text/plain', 'file_size': 75084, 'creation_date': '2024-08-18', 'last_modified_date': '2024-08-18', 'triplet_source_id': '1103479b-0a73-4e1a-9961-40c6cdce0f35'}) Interleaf ({'file_path': 'PaulGrahamEssayDataset/source_files/source.txt', 'file_name': 'source.txt', 'file_type': 'text/plain', 'file_size': 75084, 'creation_date': '2024-08-18', 'last_modified_date': '2024-08-18', 'triplet_source_id': '4aa95ad2-0e9c-462e-b009-c5d860889734'}) -> Made software for ({'file_path': 'PaulGrahamEssayDataset/source_files/source.txt', 'file_name': 'source.txt', 'file_type': 'text/plain', 'file_size': 75084, 'creation_date': '2024-08-18', 'last_modified_date': '2024-08-18', 'triplet_source_id': '38047613-10be-4608-8e84-d654e27f378f'}) -> Creating documents ({'file_path': 'PaulGrahamEssayDataset/source_files/source.txt', 'file_name': 'source.txt', 'file_type': 'text/plain', 'file_size': 75084, 'creation_date': '2024-08-18', 'last_modified_date': '2024-08-18', 'triplet_source_id': '38047613-10be-4608-8e84-d654e27f378f'}) Viaweb ({'file_path': 'PaulGrahamEssayDataset/source_files/source.txt', 'file_name': 'source.txt', 'file_type': 'text/plain', 'file_size': 75084, 'creation_date': '2024-08-18', 'last_modified_date': '2024-08-18', 'triplet_source_id': '48380066-c484-4dc9-a23a-b5ddc4f1611b'}) -> Founded by ({'file_path': 'PaulGrahamEssayDataset/source_files/source.txt', 'file_name': 'source.txt', 'file_type': 'text/plain', 'file_size': 75084, 'creation_date': '2024-08-18', 'last_modified_date': '2024-08-18', 'triplet_source_id': '7baa0f5a-6505-415b-89f3-0c5b6707f1d6'}) -> Robert morris ({'file_path': 'PaulGrahamEssayDataset/source_files/source.txt', 'file_name': 'source.txt', 'file_type': 'text/plain', 'file_size': 75084, 'creation_date': '2024-08-18', 'last_modified_date': '2024-08-18', 'triplet_source_id': '27dfa6a8-b85f-4eac-8ec2-34e18fe83a3b'}) ... -
queryする
なんだかよくわかりませんが、回答を生成してくれました。
query_engine = index.as_query_engine( include_text=True, ) response = query_engine.query("What happened at Interleaf and Viaweb?") print(str(response))回答
Based on the context provided:
At Interleaf, the narrator got a job there after leaving art school. Interleaf was a software company that made software for creating documents, similar to Microsoft Word. However, Interleaf added a scripting language that was a dialect of Lisp, which was bold at the time. The narrator was hired as a Lisp hacker to write things in this scripting language, though he admits he was not a very good employee there.
Later, the narrator co-founded a company called Viaweb with Robert Morris and Trevor Blackwell. Viaweb created software that allowed users to build online stores via the web. The software had three main components - an editor for building sites (written by the narrator), a shopping cart (written by Robert), and a manager for tracking orders and statistics (written by Trevor). Viaweb opened for business in January 1996 with 6 online stores, aiming to be an inexpensive and easy-to-use ecommerce solution like Microsoft Word, in contrast to more complex enterprise software like Interleaf's. However, the early years of Viaweb were very stressful for the founders despite the seemingly simple software.
-
ストレージをディスクに保存
メモリ上で処理していたので、作成したデータベースをディスクに永続化します。
index.storage_context.persist(persist_dir="./storage")永続化したデータからインデックスを復元するには、こうするようです。
from llama_index.core import StorageContext, load_index_from_storage index = load_index_from_storage(StorageContext.from_defaults(persist_dir="./storage"))
まとめ
やってみたけど、あまり理解はできてないです。。
プロンプトでナレッジグラフのデータを作ってるので、日本語でも上手に動作するのかはちょっと心配
普通のRAGの代替ではなくて、得意な用途が違うってことなのかな?