2024/5/5更新:生成AIに興味を持った方向け、続編を投稿しました。
「Qiitaに聞いた!!」をAmazon Bedrockで作った!(Claude 3でRAG)
タイトルはふざけてますが、プロンプトエンジニアリングにより本投稿と同様の内容を行う解説をしています。
(BedrockのClaude 3モデルと、Google検索を使った構成です)
生成AIはとても注目度が高い技術ですが、すこしとっつきにくいところがあるかもしれません。新しいモデルや活用手法が毎日のように登場し、ウォッチし続けるのはかなり大変です。
タイミングを逃して入門できていない方向けに、 とりあえず作って体感してみよう というコンセプトで、ハンズオン記事を作成しました。🎉🎉🎉
ハンズオンの内容は「RAG」です。RAGは生成AIの活用法としてよく出てくるキーワードです。ハンズオンでは、ただのRAGではなく最先端の「Advanced RAG」を体験できます。
RAGガチ勢には鼻で笑われるかもしれませんが、RAGちょっとわかる勢(「にわかRAGGER」と呼ぶことにします)には十分追いつけるのではないでしょうか?!
AWSやPythonについては、わかる前提で進めます。
超特急でRAGを体験するコンセプトのため、生成AIとは何なの?、プロンプトってどうやって書くの?ということには全く触れません(プロンプトは登場すらしません)。本ハンズオンで生成AIに興味を持っていただいた方は、Qiitaの様々な記事を参考に生成AIの世界に足を踏み入れてみてはいかがでしょうか?
参考にしたAWSアーキテクチャ
2024/5/1に公開されたAWS公式ブログです。
- RAGは生成AIを活用する際の課題を解決する技術
- 一方で単純なRAGのアーキテクチャでは期待する回答が得られない場合がある
- パフォーマンス向上の手法として、Advanced RAGが論文で考案された
- KendraとBedrock(Claude 3)を使用してAdvanced RAGを構築し評価
構築するアーキテクチャ
生成AI未経験でもとっつきやすいように、AWS公式ブログを参考に、わかりやすさ重視のアーキテクチャを考えました。
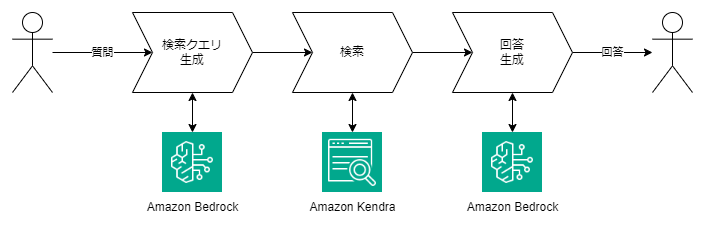
ブログで紹介されている「検索結果の関連度評価」は精度向上の寄与が少ないと判断し除外しています。
2024年5月時点で最もナウいRAGアーキテクチャをAWS上にサクッと構築します。
サービス解説
使用するAWSのサービスは2つです。
Amazon Kendra
Amazon Kendra は、機械学習 (ML) を利用した インテリジェント検索サービス です。Amazon Kendra は、ウェブサイトやアプリケーションのエンタープライズ検索を再構築します。企業の従業員やお客様は、組織内のさまざまな場所やコンテンツリポジトリにコンテンツが散在している場合でも、目的のコンテンツを見つけることができます。
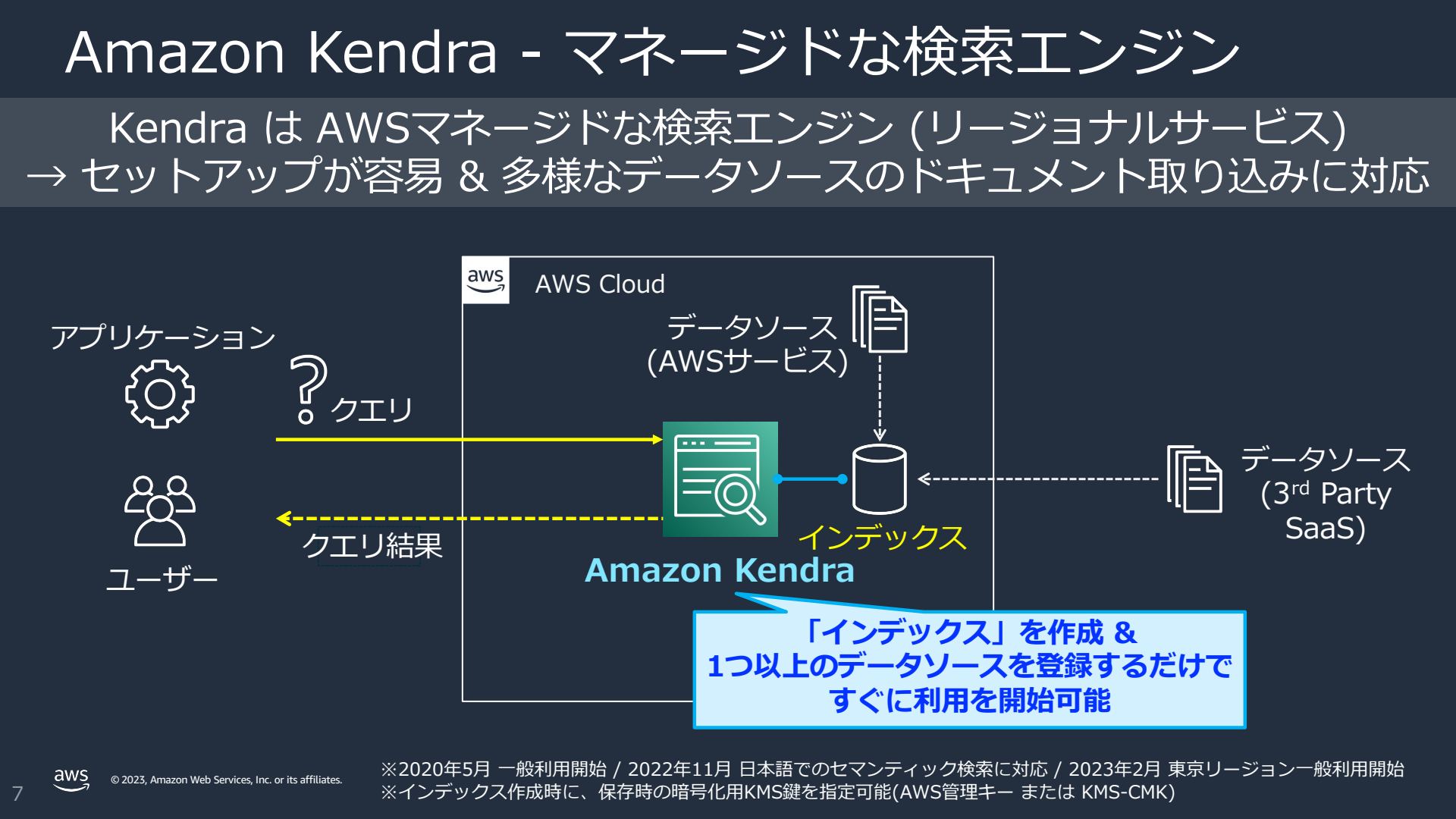
引用:https://pages.awscloud.com/rs/112-TZM-766/images/20230330_28th_ISV_DiveDeepSeminar_Kendra.pdf
Kendraは検索サービス
Amazon Bedrock
Amazon Bedrock は、単一の API を介して AI21 Labs、Anthropic、Cohere、Meta、Mistral AI、Stability AI、および Amazon といった大手 AI 企業からの高性能な基盤モデル (FM) を選択できるフルマネージドサービスで、セキュリティ、プライバシー、責任ある AI を備えた生成 AI アプリケーションを構築するために必要な幅広い機能を提供します。

Bedrockでは色々な生成AIモデルを使用できますが、今回はCohereという会社の Command R+ を使用します。4/29に利用できるようになったばかりのモデルです。
Bedrockは生成AIサービス
構築手順
BedrockとKendraの構築を行います。
手順が長いので折りたたみ表示にしました。興味のある方はごらんください。
Amazon Bedrock
Bedrockの設定
Cohere社のCommand R+というモデルを使えるようにします。
-
AWSのマネジメントコンソールにサインインします。バージニア北部を選択してください。
-
「Bedrock」で検索して、
Amazon Bedrockを選択します。
-
左のメニューを開き、
モデルアクセスをクリックします。
-
モデルアクセス管理をクリックします。
-
「Command R+」のチェックを入れ、画面最下部の
モデルアクセスをリクエストをクリックします。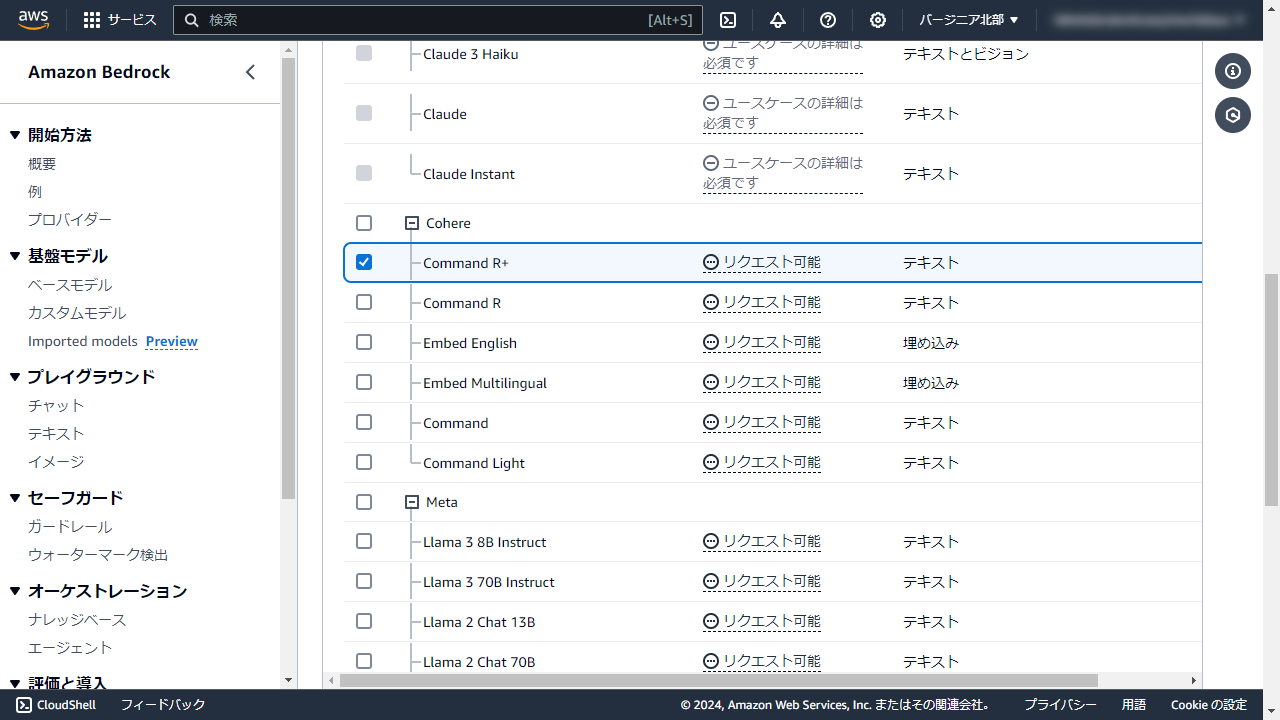
-
5分ぐらい待つと、「アクセスが付与されました」に変わると思います。
(You accepted an AWS Marketplace offerという件名のメールも届くと思います。)
Bedrockの設定は以上です。
Amazon Kendra
Kendraの設定
Kendraには無料利用枠があります。
最初の 30 日間で最大 750 時間の無料利用枠が提供される Amazon Kendra Developer Edition を無料で始めることができます。コネクタの使用は無料利用には含まれず、通常の使用時間とスキャンの料金が適用されます。無料利用枠の制限を超過した場合、使用した追加のリソースに対して Amazon Kendra Developer Edition の料金が発生します。
https://aws.amazon.com/jp/kendra/pricing/
無料枠を超えるとまぁまぁな課金が発生するので、不要になったら、作成したインデックスは削除してください。
-
「Kendra」で検索して、
Amazon Kendraを選択します。
-
Create an Indexをクリックします。
-
もろもろ設定を入力し、
Nextをクリックします。項目 値 Index name my-rag-index IAM role Create a new roleを選択Role name AmazonKendra-us-east-1-my-rag-index (プレフィックスの AmazonKendra-us-east-1-が自動付与されます)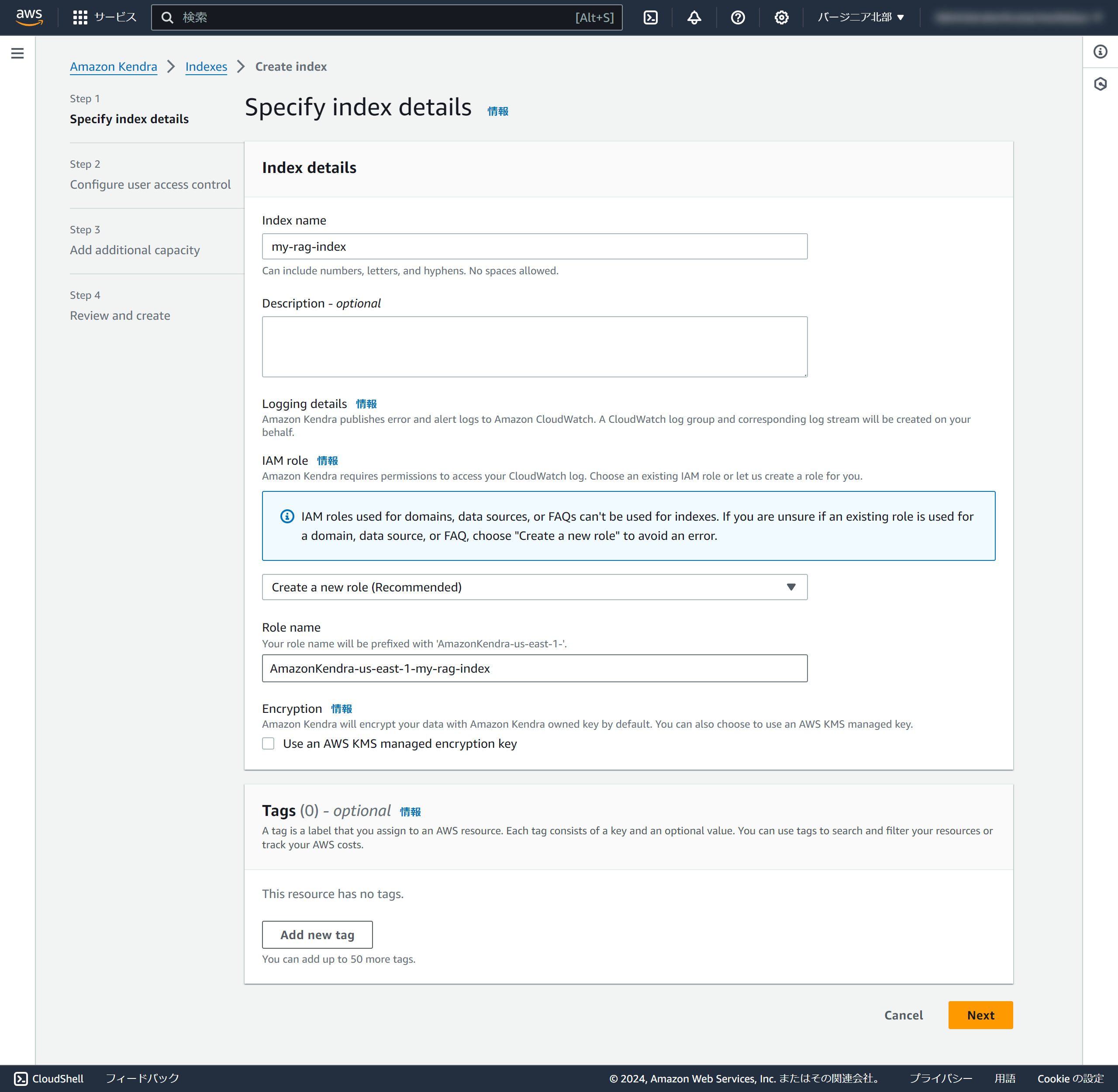
-
特に設定変更せず、
Nextをクリックします。
-
Developer editionを選択した状態でNextをクリックします。
-
内容を確認して
Createをクリックします。
-
Indexが作成されました。
続いて、データソースを作成します。データソースとは、検索対象のことです。S3バケットや各種データベースなどが指定できます。
Kendraは、データソースの情報を事前にクローリングし、インデックスに登録します。こうすることで、検索結果を迅速に返却できます。(検索の際にデータソースそのものに毎回アクセスしているわけではありません)
Add data sourcesをクリックします。
-
たくさんコネクターが表示されます。今回は、AWSのドキュメントサイトをクローリングして登録します。
検索欄に「Web」と入力してWeb Crawler (V2.0)をクリックします。
-
データソースの設定を行います。
Default languageは結構大事な設定です。日本語ドキュメントの場合はJapanese (ja)を必ず指定します。(Englishのままだと、全く検索に引っからないので気をつけてください。)項目 値 Data source name kendra-developer-guide Default language Japanese (ja) 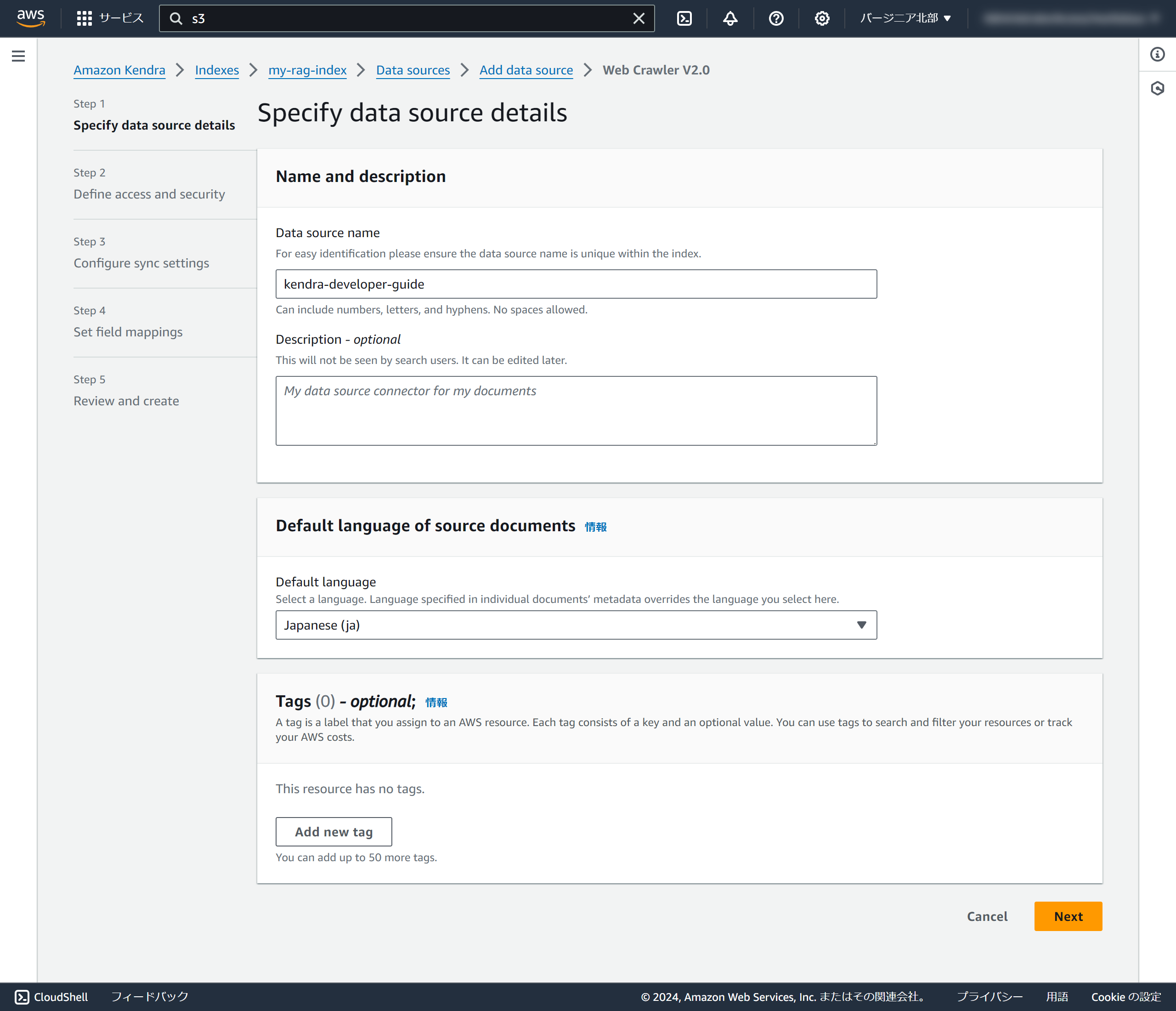
-
続きの設定を行います。入力後、
Nextをクリックします。項目 値 Source Source sitemapsを選択Source sitemap URL https://docs.aws.amazon.com/ja_jp/kendra/latest/dg/sitemap.xmlIAM role Create a new roleを選択Role name AmazonKendra-kendra-developer-guide(プレフィックスのAmazonKendra-が自動付与されます)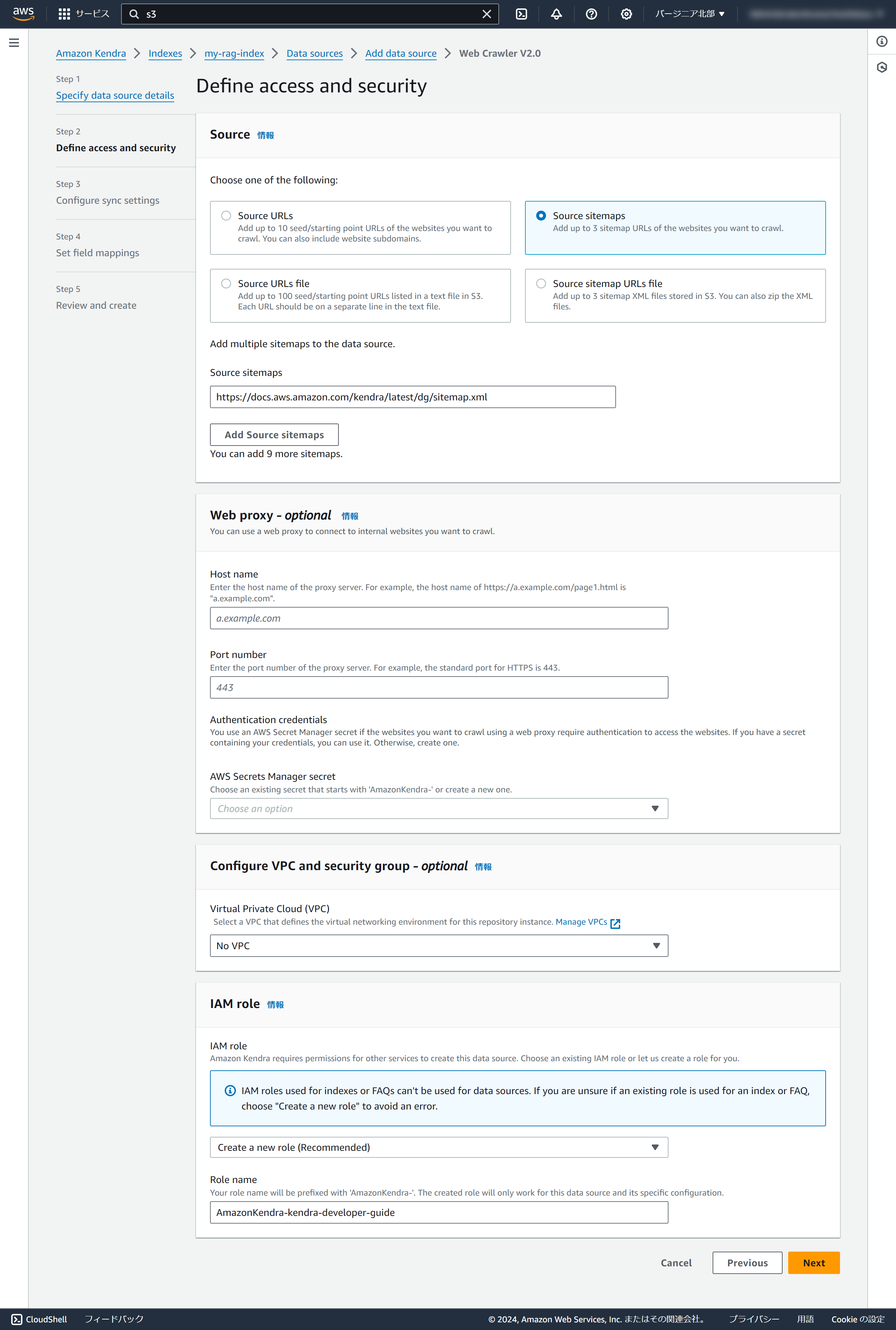
-
もうちょっと続きます。入力後、
Nextをクリックします。項目 値 Sync domain range Sync domains onlyを選択Sync mode Full syncを選択Sync run schedule Run on demandを選択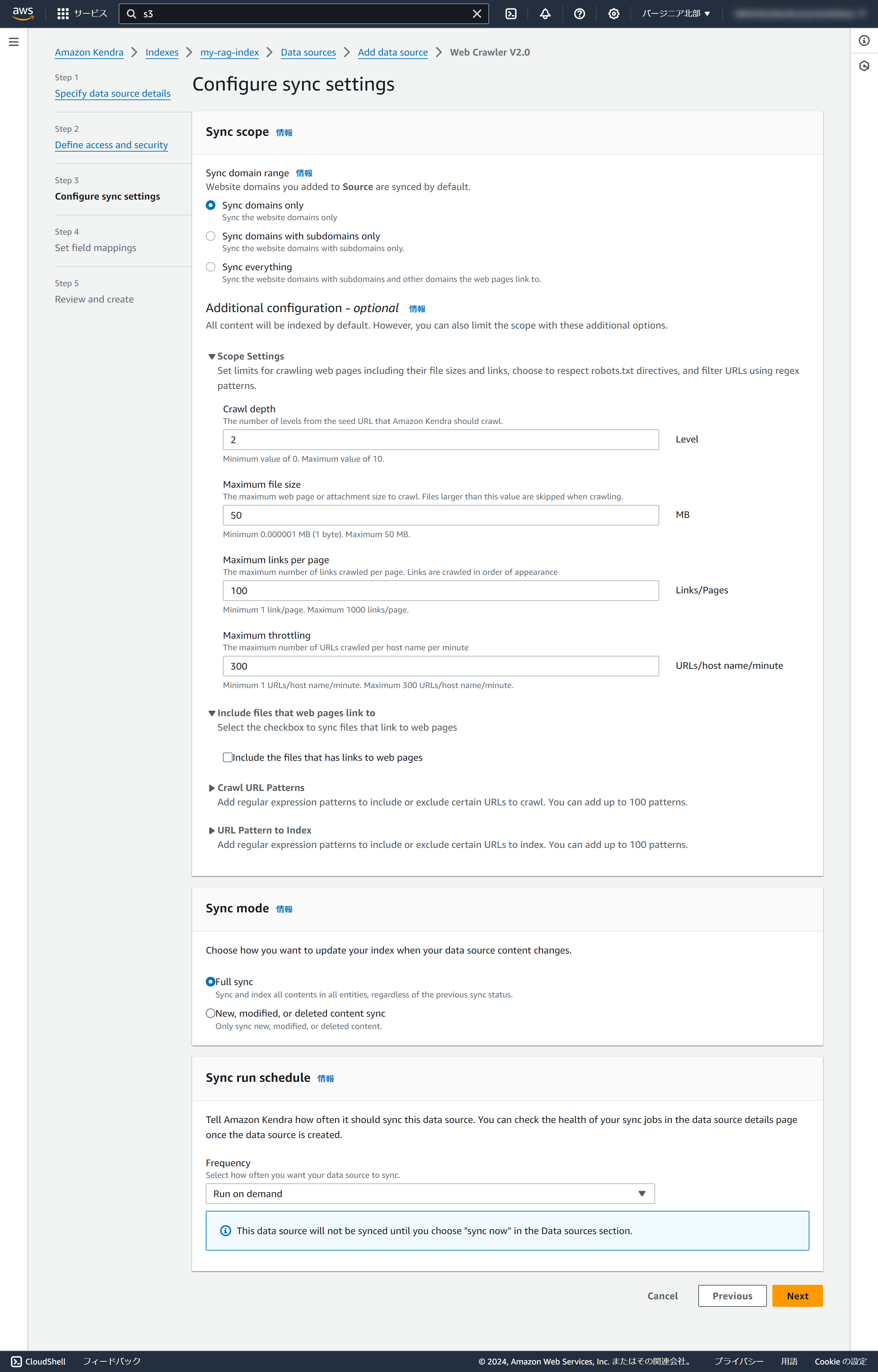
-
この画面は設定を変更せず
Nextをクリックします。
-
確認画面が出るので、
Add data sourceをクリックします。
(画面は省略) -
データソースが作成できました。作成しただけでは検索できないので同期処理を実行します。
Sync nowをクリックします。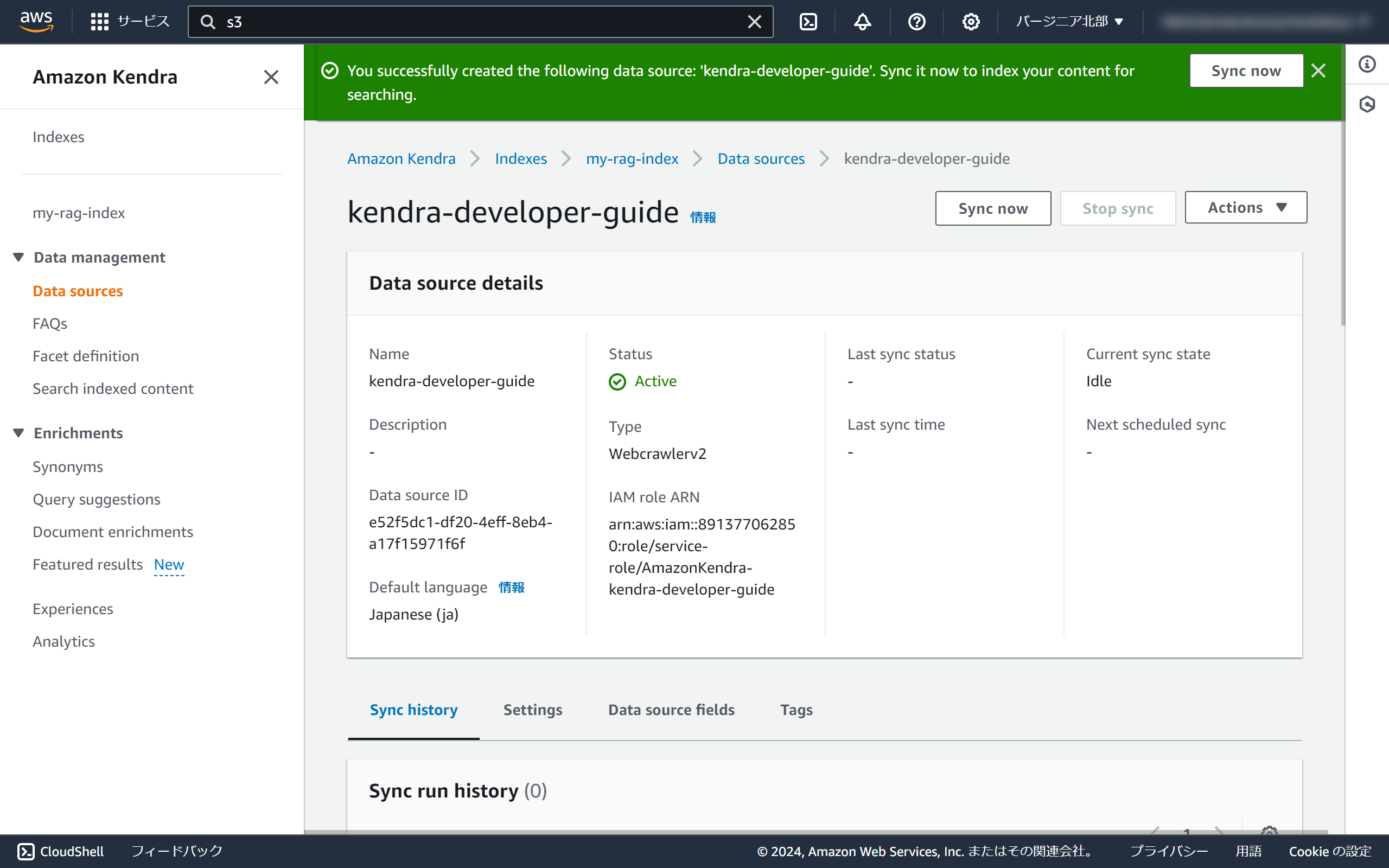
同期には1時間以上かかるので先に進みましょう
-
同じようにBedrockの開発者ガイドとComprehendの開発者ガイドをデータソースとして追加してください。
手順の途中でIAMロールを指定する箇所は、
Create a new roleを選んで毎回新しいIAMロールを作成したほうが確実です。
Sync nowも忘れず実行してください。- Bedrock
項目 値 Data source name bedrock-developer-guide Default language Japanese (ja) Source Source sitemapsを選択Source sitemap URL https://docs.aws.amazon.com/ja_jp/bedrock/latest/userguide/sitemap.xmlIAM role Create a new roleを選択Role name AmazonKendra-bedrock-developer-guide(プレフィックスのAmazonKendra-が自動付与さSync mode Full syncを選択Sync run schedule Run on demandを選択- Comprehend
項目 値 Data source name comprehend-developer-guide Default language Japanese (ja) Source Source sitemapsを選択Source sitemap URL https://docs.aws.amazon.com/ja_jp/comprehend/latest/dg/sitemap.xmlIAM role Create a new roleを選択Role name AmazonKendra-comprehend-developer-guide(プレフィックスのAmazonKendra-が自動付与さSync mode Full syncを選択Sync run schedule Run on demandを選択
Kendraの設定は以上です。
データソースの同期が終わったら次の手順に進んでください。
ハンズオンが終わったあとの削除は、この画面でDeleteをクリックです。
アプリケーション作成
アプリケーションを作成します。
Python 3.11の環境を準備し、boto3をインストールしてください。
pip install boto3
Step1: 検索クエリ生成
-
必要なライブラリーをインポート
まずは必要なライブラリーをインポートします。
import json import boto3 -
クライアント生成
boto3からクライアントを生成します。
Bedrockのモデル呼び出しに使うサービス名はbedrock-runtimeです。bedrock_client = boto3.client("bedrock-runtime")他に
bedrockなども存在しますが、一旦忘れましょう。 -
モデルIDを定義
Bedrockで使用するモデルのIDです。今回使用するCohere Command R+のモデルIDはこちらです。
model_id = "cohere.command-r-plus-v1:0" -
BedrockのAPIを呼び出す
Bedrockの呼び出しは、
invoke_modelです。questionをJSONのmessageにセットして呼び出します。それ以外はこういうものだと思ってこのまま書いてください。response = bedrock_client.invoke_model( modelId=model_id, body=json.dumps( { "message": question, "search_queries_only": True, } ), ) -
レスポンスから必要な項目を抽出する
レスポンスは単純なJSON文字列ではなく、
body部分がStreamingBody型で返却されます。bodyをJSONに変換します。response_body = json.loads(response.get("body").read())S3バケットからオブジェクト取得に使用する
get_objectと同じです。Bedrockには画像生成モデルもあるので、テキスト以外も返却できる設計したと思われます。body部分をJSONに変換した値{ "chat_history": [], "finish_reason": "COMPLETE", "generation_id": "1e17eba2-3a45-49b4-b3b7-57247d7a0b40", "is_search_required": true, "response_id": "a3bee56e-b65d-4853-ab72-2455ea62e493", "search_queries": [ { "generation_id": "1e17eba2-3a45-49b4-b3b7-57247d7a0b40", "text": "Amazon Kendra クロール URL 制限" } ], "text": "" }search_queriesの配列内にあるtextのみを取り出します。search_queries = list(map(lambda x: x["text"], response_body["search_queries"]))
完成しました。
import json
import boto3
bedrock_client = boto3.client("bedrock-runtime")
kendra_client = boto3.client("kendra")
model_id = "cohere.command-r-plus-v1:0"
def generate_search_query(question: str) -> dict:
"""
Generate search queries from question.
question: str
"""
response = bedrock_client.invoke_model(
modelId=model_id,
body=json.dumps(
{
"message": question,
"search_queries_only": True,
}
),
)
response_body = json.loads(response.get("body").read())
search_queries = list(map(lambda x: x["text"], response_body["search_queries"]))
return search_queries
if __name__ == "__main__":
question = "Amazon Kendra を使って Web サイトのコンテンツを検索可能にしたいと考えています。クロールの対象とする URL を制限する方法はありますか?"
search_queries = generate_search_query(question=question)
print(search_queries)
実行してみましょう。
ユーザーからの質問は「Amazon Kendra を使って Web サイトのコンテンツを検索可能にしたいと考えています。クロールの対象とする URL を制限する方法はありますか?」です。
python app.py
['Amazon Kendra クロール URL 制限']
上記の例では配列の中は1項目だけでしたが、例えば、「Kendraの対応リージョンとBedrockの対応リージョンを教えて」と質問した場合は、以下の2項目が返却されます。
- Kendra available regions
- Bedrock coverage
Step2: 検索
生成した検索クエリを使って、Kendraで検索を行います。
-
クライアント生成
Kendraのクライアントを生成します。kendra_client = boto3.client("kendra") -
Kendraで検索する
retrieveAPIを呼び出します。
IndexIdはKendraのIndex ID、QueryTextに前の手順で生成した検索キーワードをセットします。
AttributeFilterは 日本語でインデックス登録したデータを検索するための設定です。response = kendra_client.retrieve( IndexId="5a28372c-6ad3-4e51-8263-d9d271d845cf", QueryText=search_query, AttributeFilter={ "EqualsTo": {"Key": "_language_code", "Value": {"StringValue": "ja"}} }, )AttributeFilterで検索言語を指定しない場合は英語(en)での検索となります。
-
レスポンスから必要な項目を抽出する
レスポンスのJSONに含まれる
ResultItemsが検索結果です。以下のような構成で返却されます。ResultItemsの一部{ "Id": "94980f7c-0c1f-4337-b994-927039ab37a5-e0b3aa98-532f-4f99-9489-f22c645c75d0", "DocumentId": "https://docs.aws.amazon.com/ja_jp/kendra/latest/dg/ds-schemas.html", "DocumentTitle": "データソーステンプレートスキーマ - Amazon Kendra", "Content": "crawlSubDomaincrawlAllDomainまたはを設定しない場合true、クロール対象の Web Amazon Kendra サイトのドメインのみがクロールされます。 honorRobots クロールするウェブサイトの robots.txt ディレクティブを優先する場合は、true にします。 これらのディレクティブは、 ...省略", "DocumentURI": "https://docs.aws.amazon.com/ja_jp/kendra/latest/dg/ds-schemas.html", "DocumentAttributes": [ { "Key": "_source_uri", "Value": { "StringValue": "https://docs.aws.amazon.com/ja_jp/kendra/latest/dg/ds-schemas.html" } } ], "ScoreAttributes": { "ScoreConfidence": "NOT_AVAILABLE" } }検索クエリが複数になる場合があるので、
ResultItemsの値をsearch_resultsに格納します。search_results.extend(response["ResultItems"])すべての検索クエリの実行が終わったら、「
Id、DocumentTitle、Content、DocumentURI」を残した形に変換します。documents = list( map( lambda x: { "Id": x["Id"], "DocumentTitle": x["DocumentTitle"], "Content": x["Content"], "DocumentURI": x["DocumentURI"], }, search_results, ) )
検索処理は以上です。
kendra_client = boto3.client("kendra")
def search(search_queries: dict):
"""
Search documents from search queries.
search_queries: dict
"""
search_results = []
for search_query in search_queries:
response = kendra_client.retrieve(
IndexId="5a28372c-6ad3-4e51-8263-d9d271d845cf",
QueryText=search_query,
AttributeFilter={
"EqualsTo": {"Key": "_language_code", "Value": {"StringValue": "ja"}}
},
)
search_results.extend(response["ResultItems"])
documents = list(
map(
lambda x: {
"Id": x["Id"],
"DocumentTitle": x["DocumentTitle"],
"Content": x["Content"],
"DocumentURI": x["DocumentURI"],
},
search_results,
)
)
return documents
if __name__ == "__main__":
question = "Amazon Kendra を使って Web サイトのコンテンツを検索可能にしたいと考えています。クロールの対象とする URL を制限する方法はありますか?"
search_queries = generate_search_query(question=question)
documents = search(search_queries=search_queries)
print(json.dumps(documents, indent=2, ensure_ascii=False))
python app.py
[
{
"Id": "b0701a9f-3928-49e5-a98d-a48f6e7e3a58-9d3749bf-3d22-4361-add3-e90945426f1b",
"DocumentTitle": "Confluence コネクタ V2.0 - Amazon Kendra",
"Content": "[追加設定] で [スペースキー] ...",
"DocumentURI": "https://docs.aws.amazon.com/ja_jp/kendra/latest/dg/data-source-v2-confluence.html"
},
...
{
"Id": "b0701a9f-3928-49e5-a98d-a48f6e7e3a58-89d91765-63e3-44c0-acd6-0c5d61b9353b",
"DocumentTitle": "データソーステンプレートスキーマ - Amazon Kendra",
"Content": "repositoryConfigurations データソースの...",
"DocumentURI": "https://docs.aws.amazon.com/ja_jp/kendra/latest/dg/ds-schemas.html"
}
]
Step3: 回答生成
質問と検索結果から回答を生成します。
-
回答生成
再度Bedrockを呼び出し回答を生成します。
「検索クエリ生成」のときは
bodyにmessageとsearch_queries_onlyを指定して呼び出しましたが、回答生成の場合はmessageとdocumentsを指定します。response = bedrock_client.invoke_model( modelId=model_id, body=json.dumps( { "message": question, "documents": documents, } ), )レスポンスの受け取り方は、先程同様ですが、
response_bodyの構造は異なります。
textが、 「生成AIがドキュメントを参考に生成した質問に対する回答」 となります。response_body = json.loads(response.get("body").read())response_bodyの内容(一部省略){ "chat_history": [], "citations": [], "documents": [], "finish_reason": "COMPLETE", "generation_id": "71bb4862-5aa1-49a2-801b-16e3231b55f8", "response_id": "6e2ab7ac-a74b-464d-875b-b824b9de13d5", "text": "はい、Amazon Kendra ではクロールする URL を制限できます。同期設定を構成するときに、ドメイン、ファイルサイズ、リンクなど、Web ページのクロールに制限を設定し、正規表現パターンを使用して URL をフィルタリングできます。" }
完成しました。
😀質問:
Amazon Kendra を使って Web サイトのコンテンツを検索可能にしたいと考えています。クロールの対象とする URL を制限する方法はありますか?
🤖回答:
はい、Amazon Kendra ではクロールする URL を制限できます。同期設定を構成するときに、ドメイン、ファイルサイズ、リンクなど、Web ページのクロールに制限を設定し、正規表現パターンを使用して URL をフィルタリングできます。
完成しました。これが RAG (Retrieval-Augmented Generation)です。
[R] Retrieval:検索を
[A] Augmented:拡張して
[G] Generation:回答生成
ソースコードの全体はこちらです。
app.py
import json
import boto3
bedrock_client = boto3.client("bedrock-runtime")
kendra_client = boto3.client("kendra")
model_id = "cohere.command-r-plus-v1:0"
def generate_search_query(question: str) -> dict:
"""
Generate search queries from question.
question: str
"""
response = bedrock_client.invoke_model(
modelId=model_id,
body=json.dumps(
{
"message": question,
"search_queries_only": True,
}
),
)
response_body = json.loads(response.get("body").read())
search_queries = list(map(lambda x: x["text"], response_body["search_queries"]))
return search_queries
def search(search_queries: dict):
"""
Search documents from search queries.
search_queries: dict
"""
search_results = []
for search_query in search_queries:
response = kendra_client.retrieve(
IndexId="5a28372c-6ad3-4e51-8263-d9d271d845cf",
QueryText=search_query,
AttributeFilter={
"EqualsTo": {"Key": "_language_code", "Value": {"StringValue": "ja"}}
},
)
search_results.extend(response["ResultItems"])
documents = list(
map(
lambda x: {
"Id": x["Id"],
"DocumentTitle": x["DocumentTitle"],
"Content": x["Content"],
"DocumentURI": x["DocumentURI"],
},
search_results,
)
)
return documents
def generate_answer(question: str, documents: dict):
"""
Generate answer from question and documents.
question: str
documents: dict
"""
response = bedrock_client.invoke_model(
modelId=model_id,
body=json.dumps(
{
"message": question,
"documents": documents,
}
),
)
response_body = json.loads(response.get("body").read())
return response_body
if __name__ == "__main__":
question = "Amazon Kendra を使って Web サイトのコンテンツを検索可能にしたいと考えています。クロールの対象とする URL を制限する方法はありますか?"
search_queries = generate_search_query(question=question)
print(search_queries)
documents = search(search_queries=search_queries)
print(json.dumps(documents, indent=2, ensure_ascii=False))
answer = generate_answer(question=question, documents=documents)
print(json.dumps(answer, indent=2, ensure_ascii=False))
100行程度でRAGができました。
citationsは、「ドキュメントのどの内容を参考に生成したか」を示す引用情報です。使い方はこちらの投稿を参考にしてください。
生成結果の確認
アプリケーションが完成したので、色々質問してみます。
質問は、参照元のブログから拝借しました。
😀質問:
Knowledge Bases for Amazon Bedrock ではどういったベクトルデータベースを利用できますか?
🤖回答:
Knowledge Bases for Amazon Bedrock では、Amazon OpenSearch Serverless、Amazon OpenSearch Service、Amazon Aurora、Pinecone、Redis Enterprise Cloud などのベクトルデータベースを利用できます。
😀質問:
Amazon Kendra がサポートしているユーザーアクセス制御の方法は?
🤖回答:
Amazon Kendra では、ユーザーやグループごとに、特定のドキュメントにアクセスできるかどうかを制御できます。この機能は、ユーザー コンテキスト フィルタリングと呼ばれます。
Amazon Kendra では、次の種類のトークンを使用したユーザー アクセス制御がサポートされています。
- Open ID JWT with a shared secret
- JWT with a public key
- JSON
Amazon Kendra は現在、S3 データ ソースと BatchPutDocument API を使用してインデックスを作成したドキュメントでのみ、アクセス制御構成をサポートしています。
😀質問:
Amazon Kendra の検索分析のメトリクスには何がありますか?
🤖回答:
Amazon Kendra の検索分析には、検索アプリケーションのパフォーマンスや、ユーザーが検索している情報について分析するための 10 のメトリクスがあります。
- 合計クエリグラフ: 1 日に発行されたクエリ数の折れ線グラフ
- 上位のクエリ: ユーザーが検索した上位 100 件のクエリ
- ゼロ検索結果の上位クエリ: 検索結果内のゼロクリックにつながる上位 100 クエリ
- クリックされた上位ドキュメント: 検索結果内で最もクリックされたドキュメントの上位 100 件
これらのメトリクスから、ユーザーが使用する優先用語と言語が通知され、実用的なインサイトが得られます。
おさらい
以下のような処理行うRAG(Advanced RAG)アプリケーションを作成しました。それぞれのステップがとても単純であることが理解できたと思います。
生成AI使ってる感覚が全くなかった と思いますが、いかがでしょうか?
「プロンプト」とか「プロンプトエンジニアリング」とかは全く登場せず、単純に
- ユーザーの質問から検索クエリを生成するAPI呼び出し
- 検索するAPI呼び出し
- 検索結果から回答を生成するAPI呼び出し
という3ステップを実行しただけでした。
この使いやすさは Cohere Command R+の特徴 です。
GPT-4やClaude 3の場合は、「プロンプトの中にどのように質問を書くのか」、「ドキュメントはどう参照させるのか」などプロンプトを書くテクニックが必要になる部分がとっつきにくさにつながると思います。
Command R+はとても上手にAPIが設計されていると感動しました。
「 なーんだ、RAGって簡単じゃん、完全に理解した!! 」という方は、そのままBedrockの世界へお越しください。一緒にワイワイしましょう!!
最後に宣伝
Bedrockの書籍を出版することになりました。興味を持っていただいた方は、どうぞお手に取ってください。
Amazon Bedrock 生成AIアプリ開発入門 [AWS深掘りガイド]
