検証して、「すごい」と思ったので画面キャプチャを取得し、記事を書く準備を進めていたのですが、上手に伝える文章がイマイチ考えられなかったので、Claude 3 Opusを使って、文章を生成してもらいました。
「追記:」の部分は後で付け足しましたが、それ以外の部分はOpusの出力そのままです。
文章生成に使用したプロンプトは最後に記載します。
また、検証に使用したファイルは「DX白書2023」で公開されている「第3部 企業DXの戦略」のPDFです。
Amazon Bedrockの新機能 Advanced parsing options
Amazon Bedrockに、PDFなどのファイルから非テキスト情報を解析するための高度な解析技術「Advanced parsing options」が追加されました。この新機能により、表やグラフなどの複雑なデータの解析にファウンデーションモデルを選択できるようになりました。
従来のPDFからのテキスト抽出では、以下のように本文のテキストは抽出できるものの、表の情報などはうまく抽出できていませんでした。

一方、Advanced parsing optionsを使用すると、以下のように表組みのデータもきれいに抽出できるようになりました。
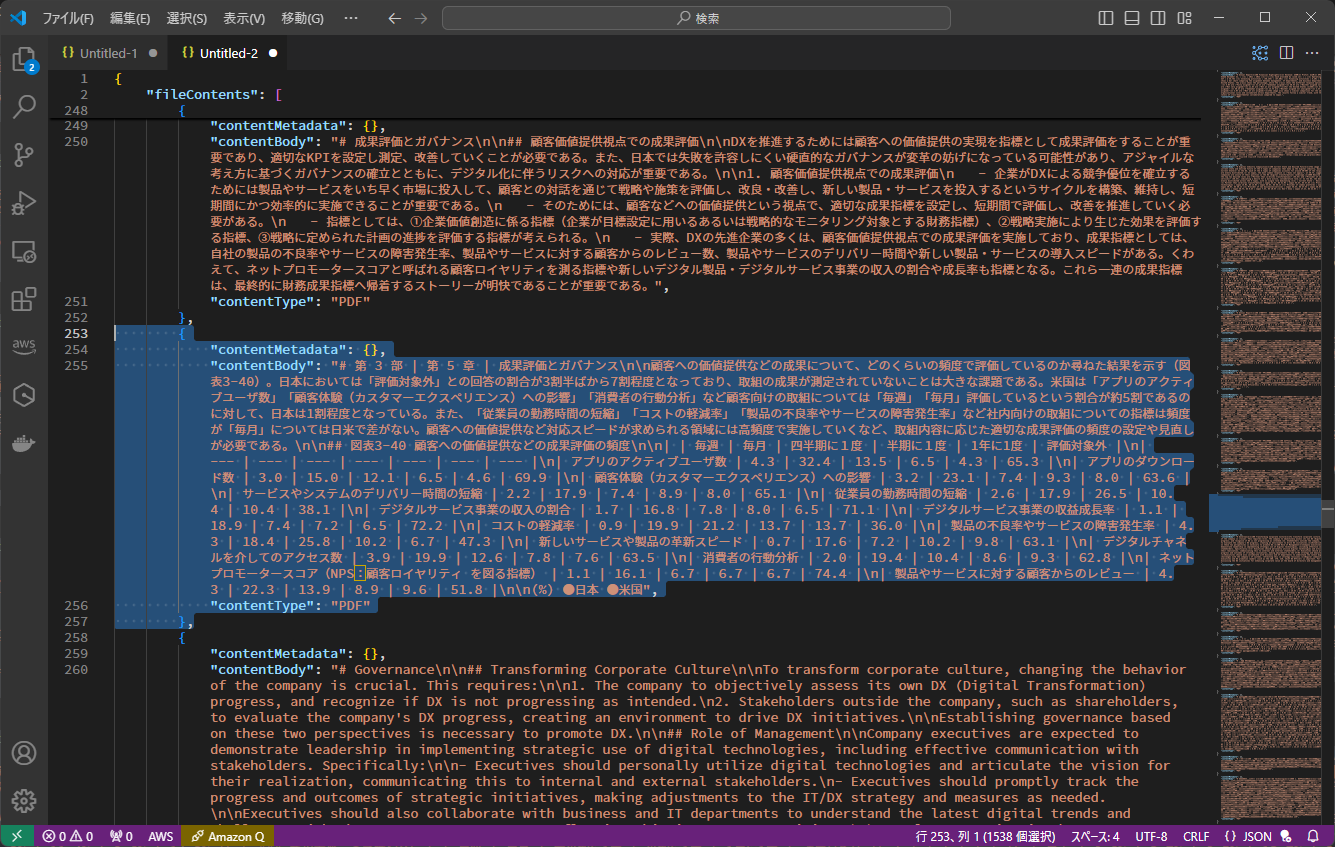
さらに、抽出したデータはMarkdown形式で出力されるため、そのままブログ記事などに埋め込んで参照することができます。

追記:
表組みのデータの抽出は行えるのですが、細かく見ると、表の内容を正しくは抽出できていません。(ずれちゃってます)
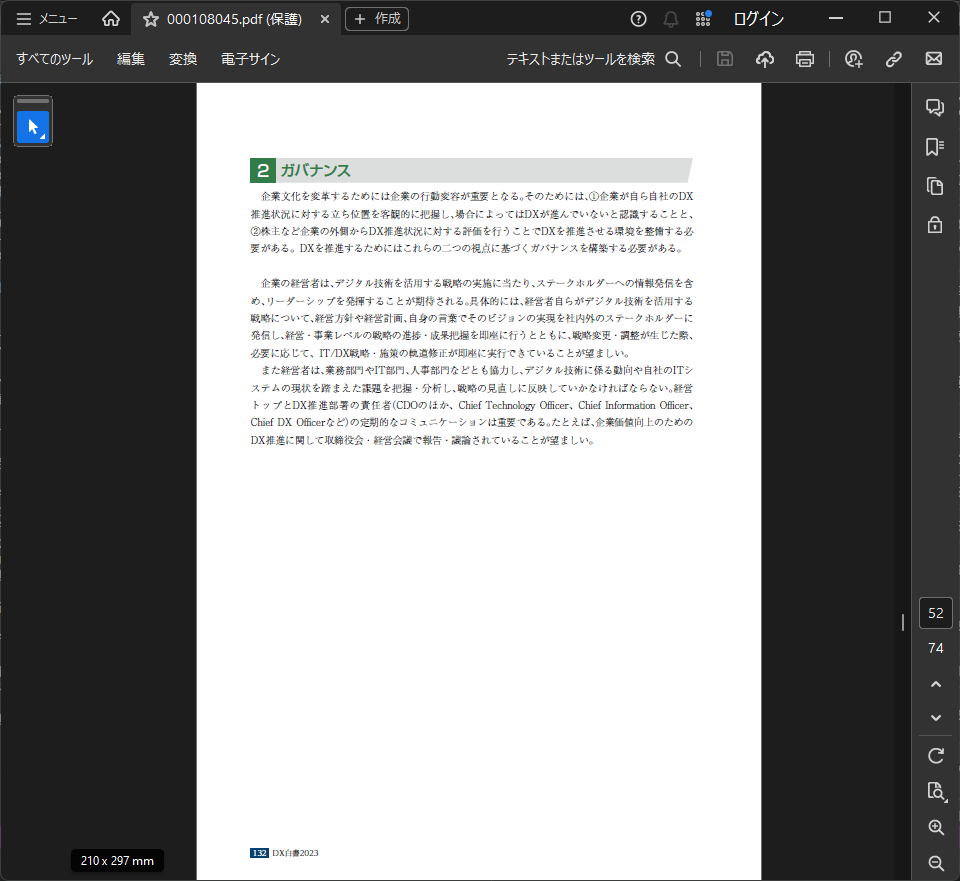
対象のページ

Advanced parsing optionsは他のページでも同様に機能し、テキストだけでなく表組みのデータもうまく抽出できています。

追記:
上記ページの抽出結果は、なぜか英語になりました。もとのデータは日本語です。

追記:
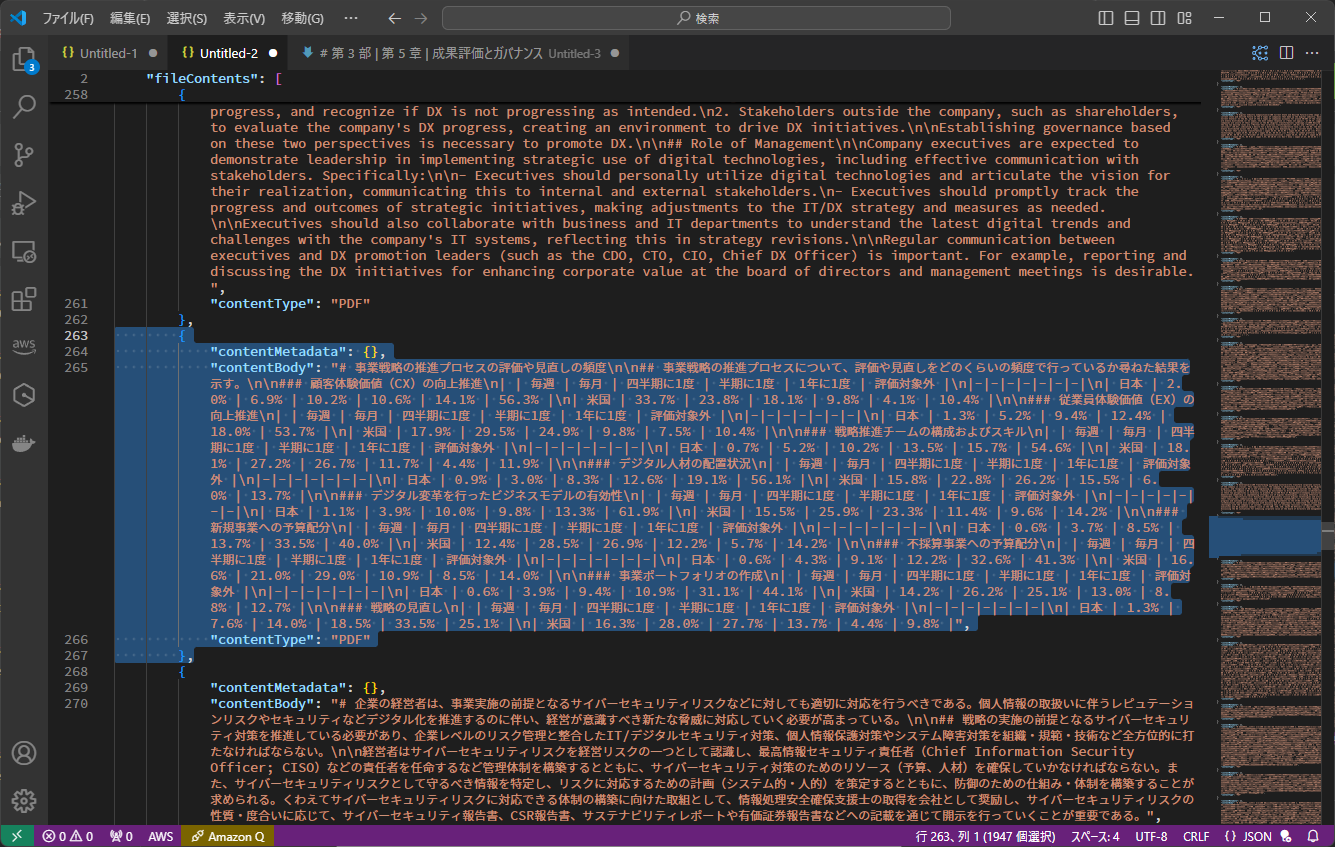
このページはすごいです。ヤヴァイです。
表が日本と米国を対象とした表であることを読み取り、凡例にある緑が日本で黄色が米国の数値であることを理解しています。数値の読み取りも完璧です!
ただ、表の上段にある文字情報はバッサリ抽出されていません。

Advanced parsing optionsのすごいところ
Advanced parsing optionsの大きな特徴は以下の2点だと考えられます。
- ファウンデーションモデルを選択して解析できる
- データ抽出のためのプロンプトをカスタマイズできる
1つ目の特徴により、表やグラフなど構造化されたデータに特化したファウンデーションモデルを使うことで、高精度な解析が可能になります。
2つ目の特徴により、ユースケースに合わせてプロンプトを最適化することで、多様なデータ形式に対応できるようになります。
これらの特徴により、PDFなどのドキュメントに埋め込まれた知見やデータを、機械学習モデルで効率的に抽出・活用できるようになるのがAdvanced parsing optionsの大きな強みだと言えます。
現時点での課題
Advanced parsing optionsは強力な機能である一方、現時点ではいくつかの課題もあります。
- 対応しているファウンデーションモデルがClaude 3 SonnetとClaude 3 Haikuのみ
- 一部のレイアウトが崩れる場合がある
- 図表の画像自体は認識できない
今後のアップデートで、より多くのファウンデーションモデルに対応し、レイアウトや図表の認識精度が向上することに期待したいところです。
まとめ
Amazon Bedrockの新機能「Advanced parsing options」は、PDFなどのファイルに埋め込まれた表形式のデータを機械学習モデルで解析し、Markdownフォーマットで出力できる強力な機能です。
ユースケースに合わせたファウンデーションモデルの選択とプロンプトのカスタマイズにより、幅広いドキュメントの知見を効率的にデータ化できるようになりました。
現時点では対応モデルの少なさやレイアウト認識の課題はあるものの、今後の発展により、ドキュメントに眠るデータの活用が大きく進むことが期待されます。
使用したプロンプト
「image1: 」などの直後に画面キャプチャを挿入しました。
技術ブログを書く目的で、画面キャプチャを色々取得しました。
image1:
image1は、これまでの方法でテキスト化した画面キャプチャです。
image2:
image2は、image1、image2で抽出の検証を行ったPDFのページです
image3:
image3は、Advanced parsing optionsを使用して文字抽出を行った結果です。
image4:
image4は、image3の文字列を抜き出し、Markdown形式だったため、Markdownでプレビューを行っています。
image5:
image5は、文字列抽出対象の別のページです。
image6:
image6は、image5をAdvanced parsing optionsを使用して文字抽出を行った結果です。
image7:
image7は、文字列抽出対象の別のページです。
image8:
image8は、image7をAdvanced parsing optionsを使用して文字抽出を行った結果です。
image9:
image9は、image8の文字列を抜き出し、Markdown形式だったため、Markdownでプレビューを行っています。
取り上げたいテーマは以下の、Amazon Bedrockの新機能です。
<新機能>
Advanced parsing options
You can use advanced parsing techniques for parsing non-textual information from supported file types, such as PDF. This feature allows you to select a foundation model for parsing of complex data, such as tables and charts. Additionally, you can tailor this to your specific needs by overwriting the default prompts for data extraction, ensuring optimal performance across a diverse set of use cases. Currently, Claude 3 Sonnet and Claude 3 Haiku are supported.
</新機能>
ブログの文章をMarkdownで記載してください。適宜、image1~9を挿入するようにしてください。
新しいオプションの何がすごいのか、また、まだ未熟な点などよく考えて考察するようにしてください。
ステップバイステップで考えてください。