LLMアプリのトレース確認に、Langfuseが人気です。
Qiitaにもタグがあります。知見が少しずつ増えてきてますね。(私も投稿してるのでぜひ見てください!)
今回、Langfuseみたいな感じで、もっとライトに使えるPhoenixというOSSを見つけましたので紹介します。
Phoenixとは
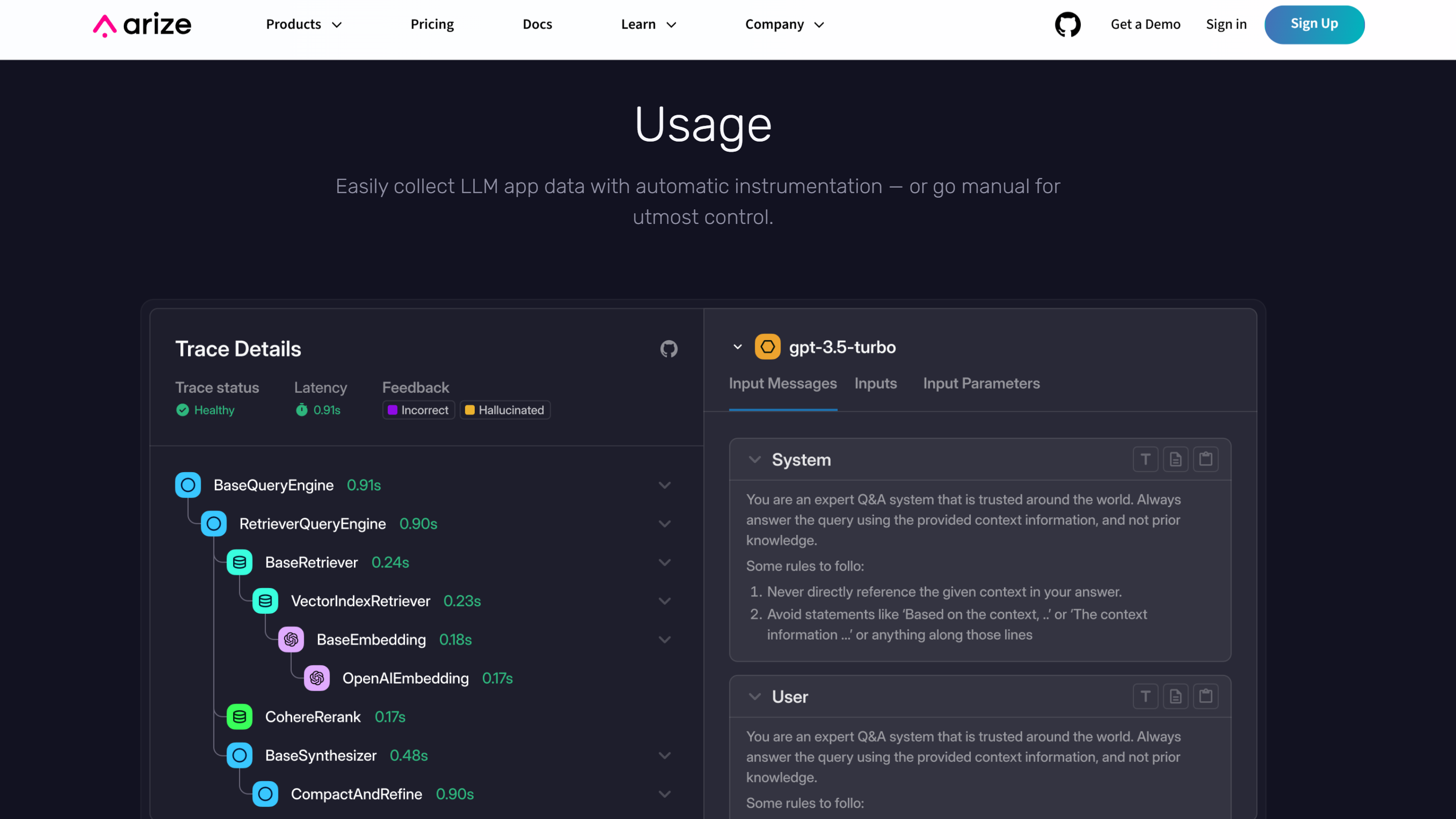
ドキュメントでこのように表現されています。
Phoenix は、実験、評価、トラブルシューティング用に設計されたオープンソースの可観測性ライブラリです。AI エンジニアやデータ サイエンティストは、Phoenix を使用することで、データをすばやく視覚化し、パフォーマンスを評価し、問題を追跡し、改善のためにデータをエクスポートすることができます。
Langfuse使ったことがある人はわかると思いますが、説明はほぼLangfuseです。
以下の機能が提供されています。
- Tracing
- Prompts
- Datasets
- Evals
- Inferences
Arize AIという会社が開発元で、Phoenix以外にもプロダクトを開発しています。
- Arize AX : Arize AX は、AI アプリとエージェントの開発を加速し、運用環境で完璧にするために構築された単一のプラットフォームです。
- Arize AX : Arize AX は、機械学習エンジニアリング チームが運用環境で ML モデルのパフォーマンスを監視、デバッグ、改善できるように支援する統合プラットフォームです。
Langfuseと比べてどうなの? ※個人の感想です。
Phoenixを使ってみた感想としては、「とにかく簡単に使える」というものでした。
Langfuseの場合
以下がドキュメントに記載されているLangChainとLangfuseの組み合わせです。
# Initialize Langfuse handler
from langfuse.callback import CallbackHandler
langfuse_handler = CallbackHandler(
secret_key="sk-lf-...",
public_key="pk-lf-...",
host="https://cloud.langfuse.com", # 🇪🇺 EU region
# host="https://us.cloud.langfuse.com", # 🇺🇸 US region
)
# Your Langchain code
# Add Langfuse handler as callback (classic and LCEL)
chain.invoke({"input": "<user_input>"}, config={"callbacks": [langfuse_handler]})
他の方法もあるのかもしれませんが、invokeする際に毎回コールバックを指定する必要があります。個人的にではありますが、結構めんどくさいなぁと思うポイントでした。
Phoenixの場合
Phoenixの場合は、OpenTelemetryの自動計装の仕組みが採用されているため、「事前の設定をしてしまえばその後のコードは変更不要」という特徴があります。(コード例はこのあと解説します)
私は試してないのですが、Langfuseも自動計装をサポートしているようなので、同じようにできるのかもしれません。(参考)
試された方いれば感想を教えて下さい。
今回はTracing機能を使ってみるところまでを紹介します。
バックエンド側の構築
pipコマンドでインストールします。
pip install arize-phoenix
起動します。
phoenix serve
以上です!
ブラウザで「https://localhost:6006」にアクセスします。
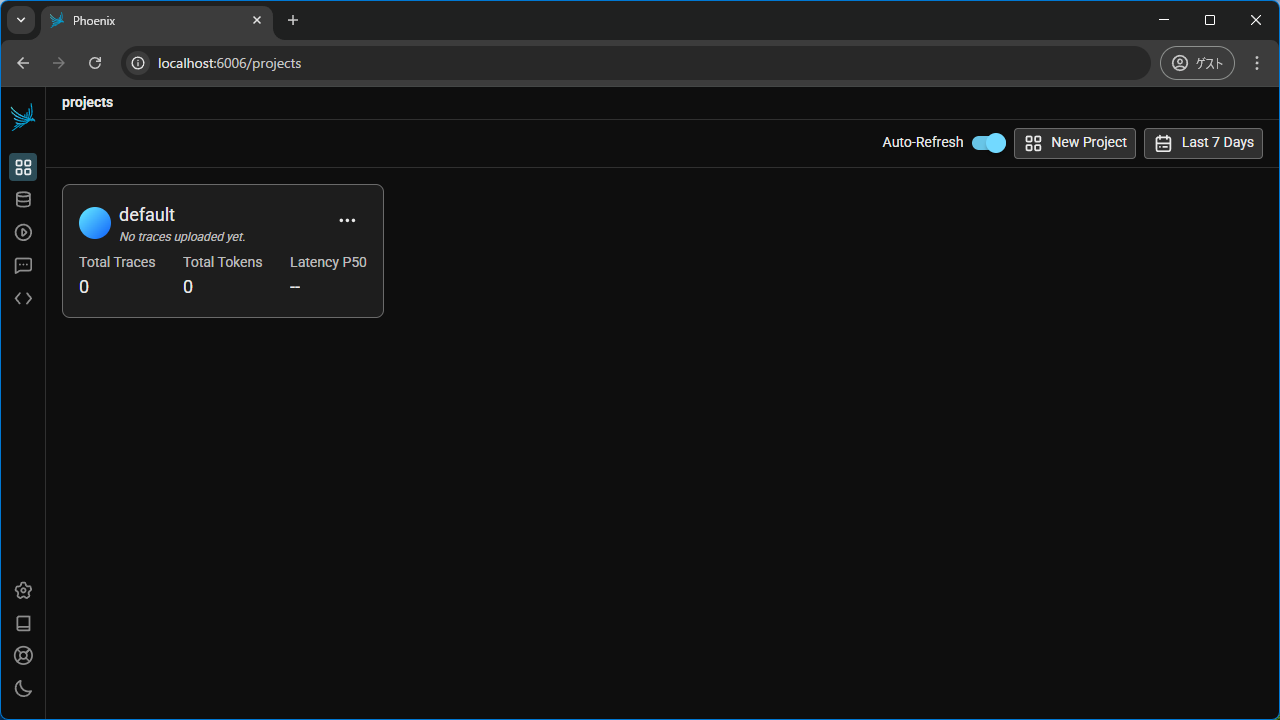
これでバックエンド側(ダッシュボード側)は構築できました。
使用するポート番号は以下のとおりです。
| ポート番号 | プロトコル | 用途 |
|---|---|---|
| 6006 | HTTP | Webインターフェイス |
| 6006 | HTTP | トレースの受信(/v1/traces) |
| 4317 | gRPC | トレースの受信 |
Webインターフェイスのポート番号を変えたい場合は環境変数「PHOENIX_PORT」で指定します。
export PHOENIX_PORT=8080
phoenix serve
クライアント側の実装
続いてクライアント側をセットアップしましょう。
OpenAI SDKの場合
OpenAIのSDKを使用する場合
必要なライブラリーをインストールします。
pip install \
openai \
arize-phoenix-otel \
openinference-instrumentation-openai
- openai : OpenAI SDK
- arize-phoenix-otel : Phoenixのクライアント側SDK
- openinference-instrumentation-openai: OpenAI SDK向けのOpenTelemetryの自動計装ライブラリー
OpenAIなど、有名なライブラリーについてはopeninference-instrumentation-???が用意されています。
このopeninference-instrumentation-???もArize AI社が提供してします。Phoenixで使えるのはもちろんですが、他のOpenTelemetry対応バックエンドへのトレース送信にも使用可能です。
それではコーディングします。
自動計装のおまじない的にtracer_providerを生成してOpenAIInstrumentor().instrument()を行います。
その後は、通常のOpenAIのAPIを呼ぶ方法と変わりません。
Langfuseと異なり、ユーザー認証なしで動作しますので、ユーザー作成やAPIキーの生成は不要です。ローカル環境でとりあえず動作させるには、楽ちんです。
バージョン5.0以降で認証機能をサポートしているので、APIキーを発行して利用することも可能です。(参考)
import openai
from openinference.instrumentation.openai import OpenAIInstrumentor
from phoenix.otel import register
tracer_provider = register(
project_name="openai-app-project",
endpoint="http://localhost:6006/v1/traces",
)
OpenAIInstrumentor().instrument(tracer_provider=tracer_provider)
## ここから先は通常のOpenAIのAPI呼び出し
client = openai.OpenAI()
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "Write a haiku."}],
)
print(response.choices[0].message.content)
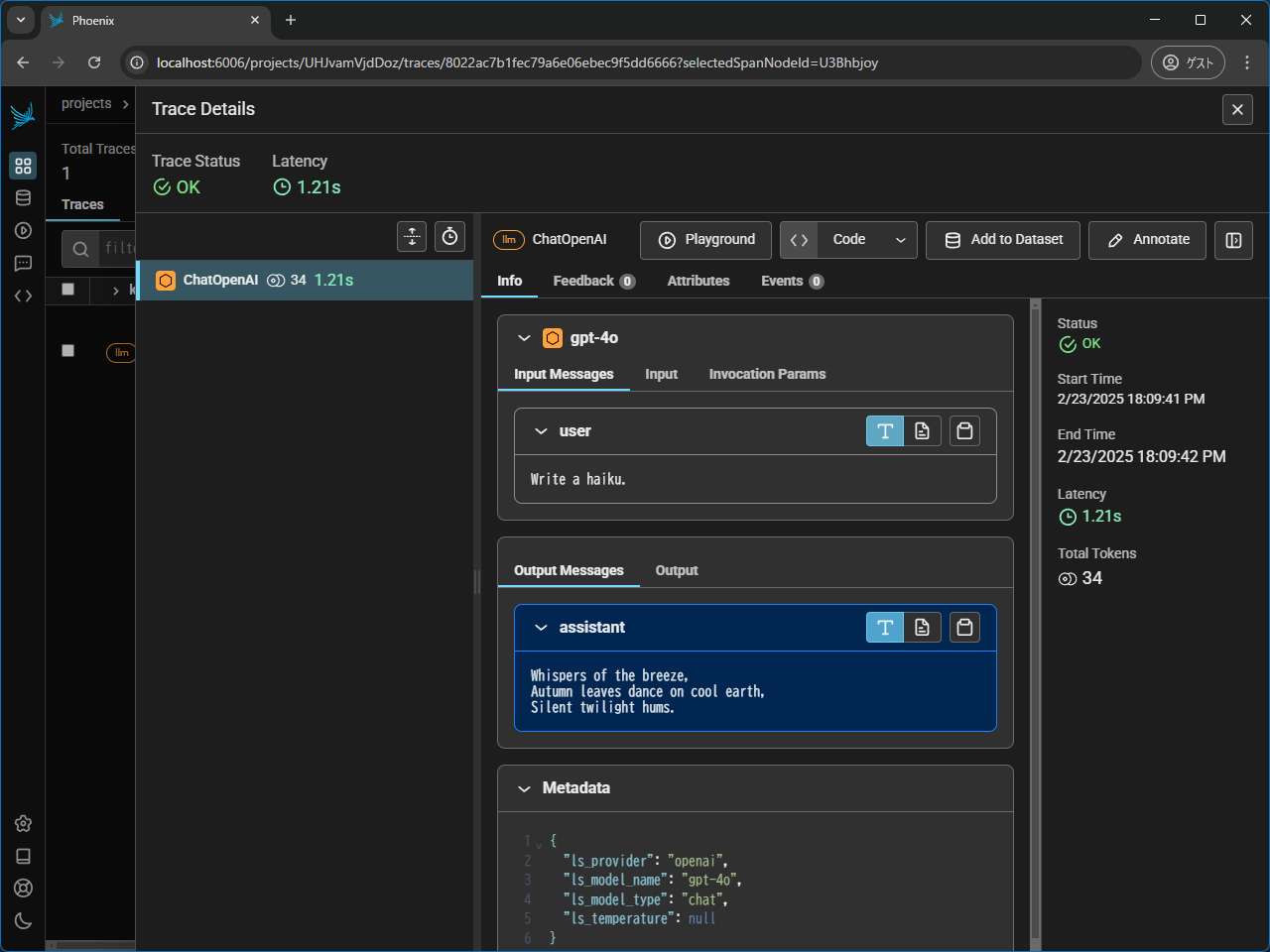
実行するとバックエンド側にトレース情報が送信され、ダッシュボードで確認できます。
(project_nameに指定した名前で分類されます)
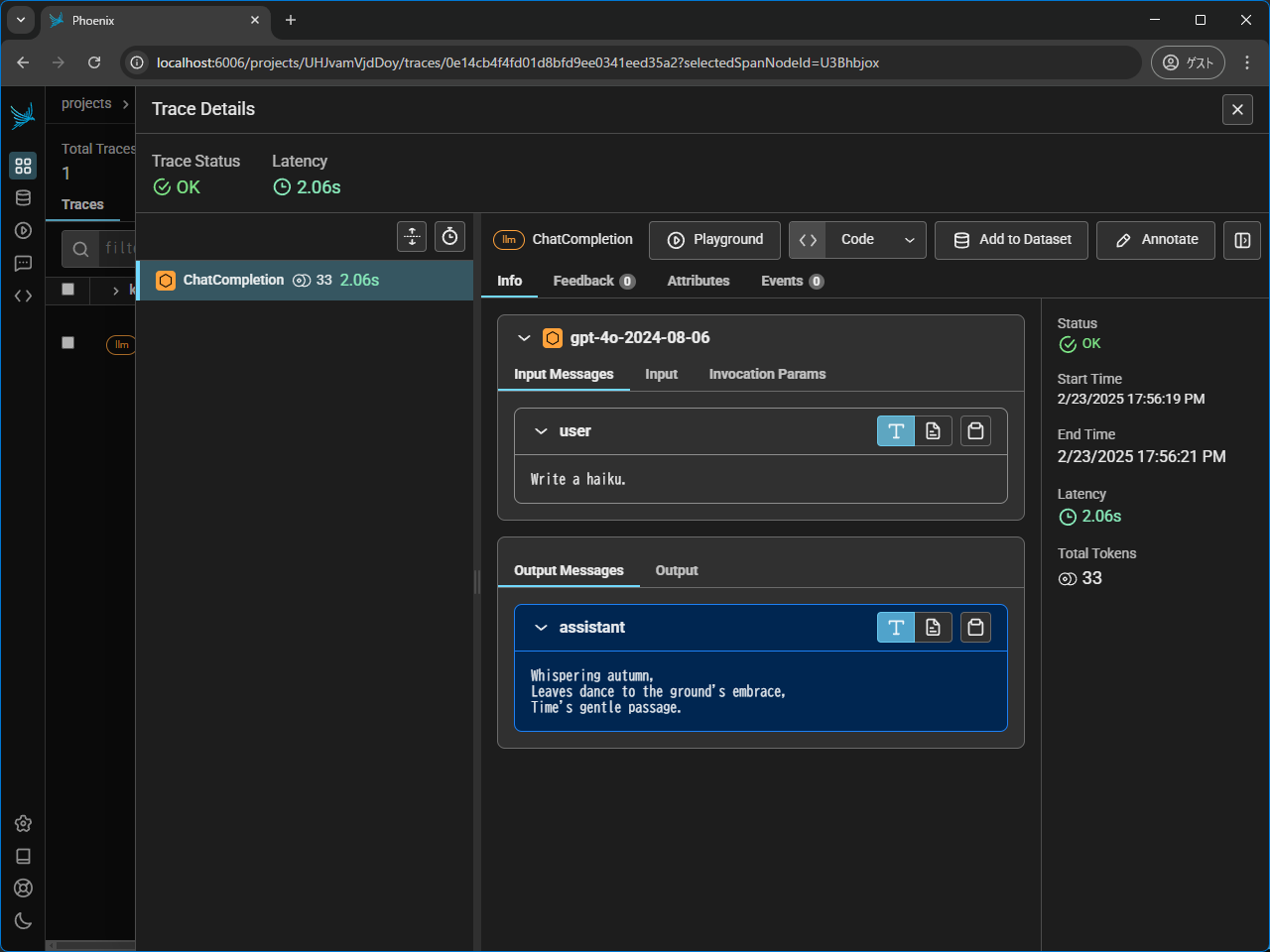
トレースもこのように確認できます。
LangChainの場合
指定する自動計装ライブラリーが違うぐらいです。
pip install \
langchain_openai \
arize-phoenix-otel \
openinference-instrumentation-langchain
from langchain_openai import ChatOpenAI
from openinference.instrumentation.langchain import LangChainInstrumentor # LangChain用の自動計装ライブラリー
from phoenix.otel import register
tracer_provider = register(
project_name="langchain-app-project",
endpoint="http://localhost:6006/v1/traces",
)
LangChainInstrumentor().instrument(tracer_provider=tracer_provider)
## ここから先は通常のLangChain呼び出し
llm = ChatOpenAI(model="gpt-4o")
response = llm.invoke(input="Write a haiku.")
print(response.content)
Bedrockの場合
こちらも自動計装ライブラリーが違いますが、それぐらいの差です。
pip install \
boto3 \
arize-phoenix-otel \
openinference-instrumentation-bedrock
import boto3
from openinference.instrumentation.bedrock import BedrockInstrumentor
from phoenix.otel import register
tracer_provider = register(
project_name="bedrock-app-project",
endpoint="http://localhost:6006/v1/traces",
)
BedrockInstrumentor().instrument(tracer_provider=tracer_provider)
## ここから先は通常のBedrockのAPI呼び出し
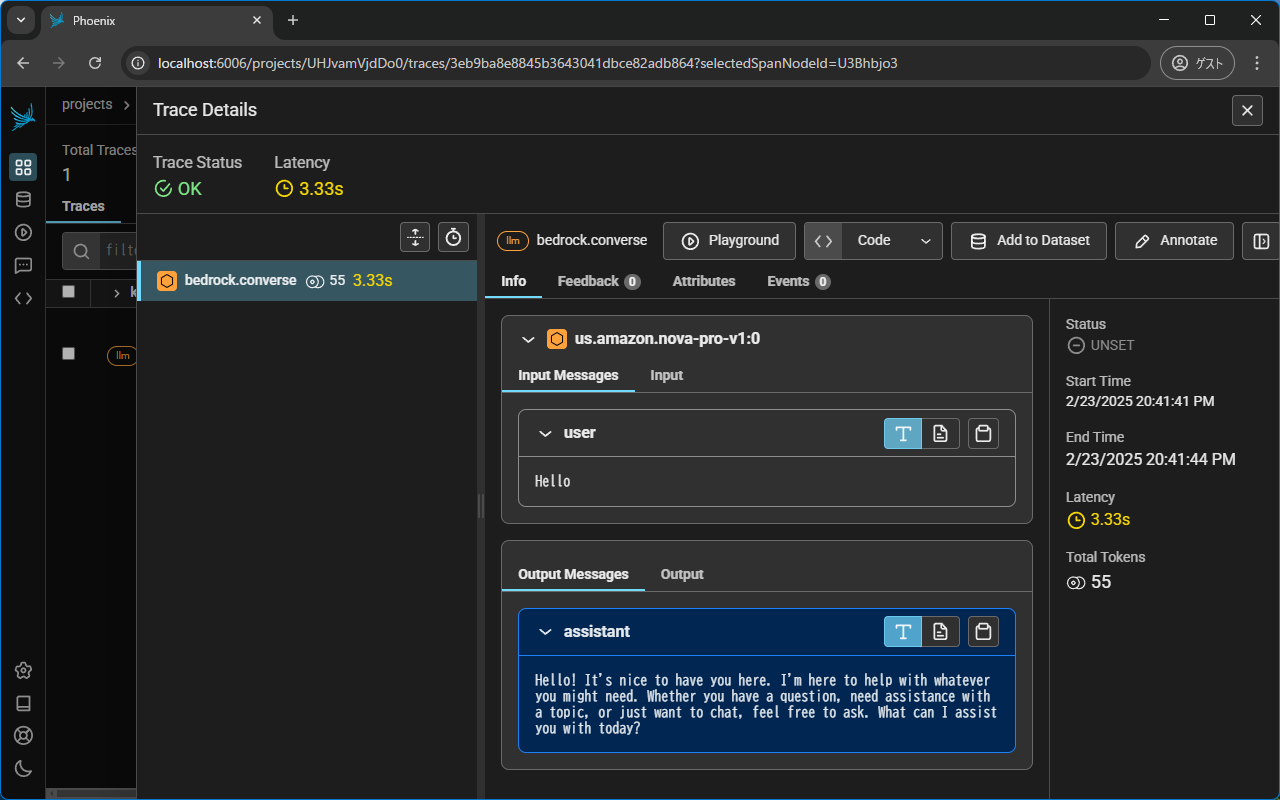
client = boto3.client("bedrock-runtime")
response = client.converse(
modelId="us.amazon.nova-pro-v1:0",
messages=[{"role": "user", "content": [{"text": "Hello"}]}],
)
print(response["output"]["message"]["content"][0])
永続化について
phoenixはバージョン4.0.0以降、永続化がサポートされています。デフォルトではSQLiteが使われ、ホームディレクトリー配下(~/.phoenix/)に保存されます。環境変数PHOENIX_WORKING_DIRで指定可能です。
PostgreSQLもサポートされています