re:Invent 2024で、Kendraに新しいインデックス「GenAI Index」が追加されました。
3行まとめ
- 検索性能がバージョンアップ(マネジメントコンソールから新規作成する際に"Recommended"される)
- ドキュメント上は英語のみのサポートだが、日本語でも動作はしそう
- 一部機能制限あり
- 料金体系が変更され、少額から使用が可能に
Kendra GenAI Indexとは
Kendra GenAI Indexは、最新のセマンティック検索が組み込まれることにより、検索精度が向上しているとのことです。RAG用途にお勧めされています。
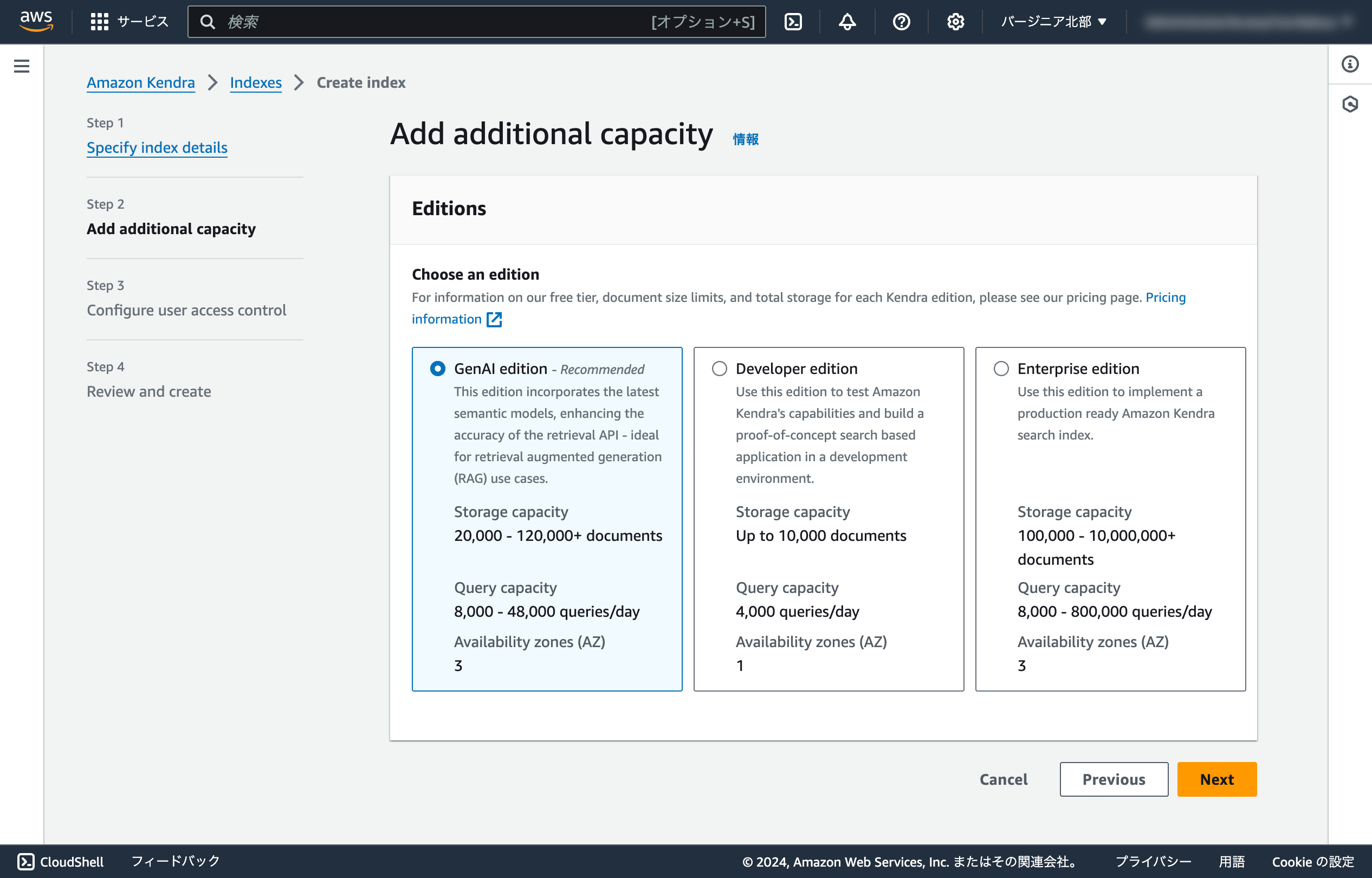
一部機能制限があり、アクセスコントロールの機能が使用できなくなっています。

また、Bedrockナレッジベースのナレッジベースとして利用できるようになりました。Kendraで提要されている様々なデータソースコネクターを利用することで、開発することなくRAGを構築できます。
検証
Kendraの日本語ドキュメントのPDFをS3に格納し、以下の質問を行いました。
Kendraが対応しているデータソースを教えてください。
従来のインデックス
Kendraの検索に使用できるAPIはQuery APIとRetrieve APIがあり、RAG用途にはRetrieve APIの使用が推奨されています。
-
Query API
response = kendra.query( IndexId=non_genai_index_id, QueryText=question, AttributeFilter={ "EqualsTo": { "Key": "_language_code", "Value": {"StringValue": "ja"}, }, }, ) response["ResultItems"][0]["DocumentExcerpt"]["Text"]コンソールを使用してデータソースフィールドマッピングを編集してカスタムフィールドを\n追加するか、 UpdateIndex API を使用してインデックスフィールドを作成します。フィールドを作\n成すると、フィールドデータ型を変更することはできません。\n\n\nほとんどのデータソースの場合、外部データソースのフィールドを Amazon Kendraの対応する\nフィールドにマッピングします。詳細については、データソースフィールドのマッピングを参照して\nください。S3 データソースでは、JSONメタデータファイルを使用してカスタムフィールドまたは\n属性を作成できます。
日本語ドキュメントを登録する場合は、データソースの「Default language of source documents」を日本語に設定し、検索の際にAttributeFilterで言語を指定する必要があります。
-
Retrieve API
response = kendra.retrieve( IndexId=non_genai_index_id, QueryText=question, AttributeFilter={ "EqualsTo": { "Key": "_language_code", "Value": {"StringValue": "ja"}, }, }, ) response["ResultItems"][0]["Content"]インデックスにマッピングする場合、それらを使用して検索結果をフィルタリングし、「HR」部門 属性によってドキュメントを含めることができます。 カスタムフィールドまたは属性を使用するには、まずインデックスにフィールドを作成する必要があ ります。 コンソールを使用してデータソースフィールドマッピングを編集してカスタムフィールドを 追加するか、 UpdateIndex API を使用してインデックスフィールドを作成します。 フィールドを作 成すると、フィールドデータ型を変更することはできません。 ほとんどのデータソースの場合、外部データソースのフィールドを Amazon Kendraの対応する フィールドにマッピングします。 詳細については、データソースフィールドのマッピングを参照して ください。 S3 データソースでは、JSONメタデータファイルを使用してカスタムフィールドまたは 属性を作成できます。 FAQ 英語以外の言語の ファイル 196 https://docs.aws.amazon.com/kendra/latest/APIReference/API_CreateFaq.html https://docs.aws.amazon.com/kendra/latest/APIReference/API_UpdateIndex.html https://docs.aws.amazon.com/kendra/latest/dg/field-mapping.html Amazon Kendra 開発者ガイド 最大 500 のカスタムフィールドまたは属性を作成できます。 Amazon Kendra 予約フィールドまたは共通フィールドを使用することもできます。
Query APIより長い文章で結果が取得できるのがRetrieve APIの特徴です。
Kendra GenAI Index
新しく追加されたKendra GenAI Indexで検証します。
Kendra GenAI Indexを使用する場合、データソースの「Default language of source documents」は英語以外を選択することができません。(作成時にエラーになります。
ドキュメントでも制限事項として明記されています。
ただ、今回検証した限り、日本語でも検索が行えました。
-
Query API
response = kendra.query( IndexId=genai_index_id, QueryText=question, ) response["ResultItems"][0]["DocumentExcerpt"]["Text"]...Amazon Kendra\n\n\nCopyright © 2024 Amazon Web Services, Inc. and/or its affiliates. All rights reserved.\n\n\n\n\n\n\n\nAmazon Kendra 開発者ガイド\n\n\nAmazon Kendra: 開発者ガイド\n\n\nCopyright © 2024 Amazon Web Services, Inc. and/or its affiliates. All rights reserved.\n\n\nAmazon の商標およびトレードドレスは、Amazon...
-
Retrieve API
response = kendra.retrieve( IndexId=genai_index_id, QueryText=question, ) response["ResultItems"][0]["Content"]\nサポートされているデータベースをデータソースとして使用する場合は、フィールドマッピングオプ\nションを使用してフィールドを設定できます。\n\n\nデータソース\n\n\nデータソースは、 のデータリポジトリまたは場所です。 Amazon Kendra はドキュメントまたは\nコンテンツに接続し、インデックスを作成します。例えば、 Amazon Kendra を Microsoft に接続 \nSharePoint して、このソースに保存されているドキュメントをクロールしてインデックスを作成\nします。URLs の を指定してウェブページのインデックスを作成することもできます。 Amazon \nKendra をクロールします。データソースを と自動的に同期できます。 Amazon Kendra インデック\nス。データソース内の追加、更新、または削除されたドキュメントもインデックスに追加、更新、ま\nたは削除されます。\n\n\nサポートされているデータソースは以下の通りです。\n\n\n• Adobe Experience Manager\n\n\n• Alfresco\n\n\n• Aurora (マイ SQL)\n\n\n• Aurora (Postgre SQL)\n\n\n• Amazon FSx (Windows)\n\n\n• Amazon FSx (NetApp ONTAP)\n\n\n• データベースデータソース\n\n\nデータソース 14\n\n\n\nhttps://docs.aws.amazon.com/kendra/latest/APIReference/API_BatchPutDocument.html\n\nhttps://docs.aws.amazon.com/kendra/latest/dg/s3-metadata.html\n\nhttps://docs.aws.amazon.com/kendra/latest/dg/data-source-database.html#data-source-procedure-database\n\nhttps://docs.aws.amazon.com/kendra/latest/dg/data-source-database.html#data-source-procedure-database\n\nhttps://docs.aws.amazon.com/kendra/latest/dg/data-source-aem.html\n\nhttps://docs.aws.amazon.com/kendra/latest/dg/data-source-alfresco.html\n\nhttps://docs.aws.amazon.com/kendra/latest/dg/data-source-aurora-mysql.html\n\nhttps://docs.aws.amazon.com/kendra/latest/dg/data-source-aurora-postgresql.html\n\nhttps://docs.aws.amazon.com/kendra/latest/dg/data-source-fsx.html\n\nhttps://docs.aws.amazon.com/kendra/latest/dg/data-source-fsx-ontap.html\n\nhttps://docs.aws.amazon.com/kendra/latest/dg/data-source-database.html\n\n\n\n\n\nAmazon Kendra 開発者ガイド\n\n\n• Amazon RDS (Microsoft SQL サーバー)\n\n\n• Amazon RDS (マイ SQL)\n\n\n• Amazon RDS (Oracle)\n\n\n• Amazon RDS (Postgre SQL)\n\n\n• Amazon S3 バケット\n\n\n• Amazon Kendra ウェブクローラー\n\n\n• Amazon WorkDocs\n\n\n• [Box] (ボックス)\n\n\n• Confluence\n\n\n• カスタムデータソース\n\n\n• Dropbox\n\n\n• Drupal\n\n\n• GitHub\n\n\n• Gmail\n\n\n• Google Workspace ドライブ\n\n\n• IBM DB2\n\n\n• Jira\n\n\n• Microsoft Exchange\n\n\n• Microsoft OneDrive\n\n\n• Microsoft SharePoint
Bedrockナレッジベース(ベクトルストアを使用)
以下の条件で検証しました。
- ベクトルデータベースはOpenSearch Serverless
- データソースはS3
- チャンキング戦略はデフォルト
response = bedrock.retrieve(knowledgeBaseId=bedrock_kb_id, retrievalQuery={"text": question})
response["retrievalResults"][0]["content"]["text"]
Amazon Kendra はドキュメントまたは コンテンツに接続し、インデックスを作成します。例えば、 Amazon Kendra を Microsoft に接続 SharePoint して、このソースに保存されているドキュメントをクロールしてインデックスを作成 します。URLs の を指定してウェブページのインデックスを作成することもできます。 Amazon Kendra をクロールします。データソースを と自動的に同期できます。 Amazon Kendra インデック ス。データソース内の追加、更新、または削除されたドキュメントもインデックスに追加、更新、ま たは削除されます。 サポートされているデータソースは以下の通りです。 • Adobe Experience Manager • Alfresco • Aurora (マイ SQL) • Aurora (Postgre SQL) • Amazon FSx (Windows) • Amazon FSx (NetApp ONTAP) • データベースデータソース データソース 14
Bedrockナレッジベース(Kendra GenAI Indexを使用)
新しく追加されたKendra GenAI Indexは、Bedrockナレッジベースと連携して使用することもできます。
Kendra GenAI Indexを新規作成するか既存のIndexを使用するか選択できます。
既存のIndexから選択する場合はGen AI Indexのみが選択可能で、これまでのIndexは選択できません。
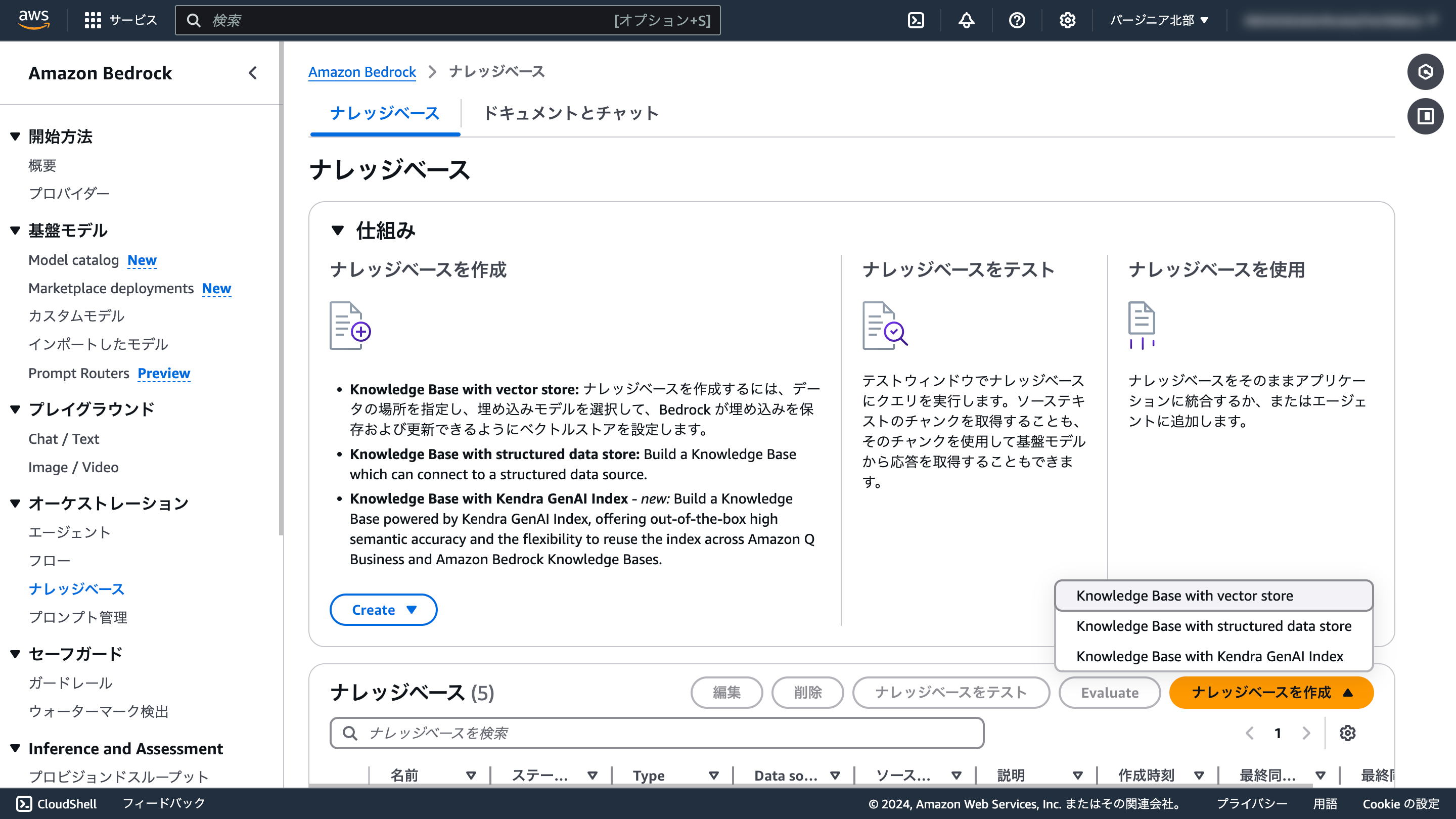
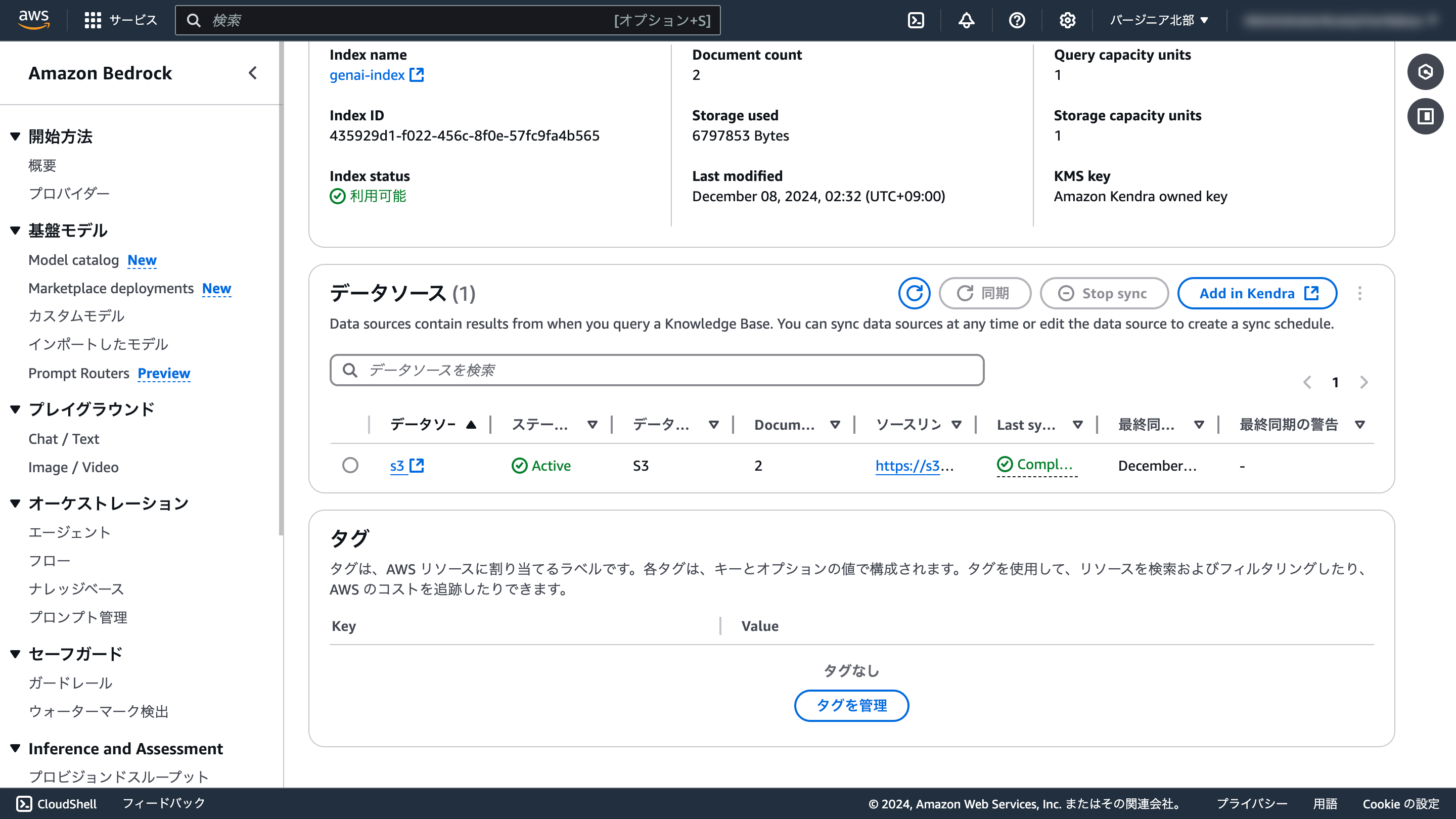
データソースの設定はKendraにて行うため、Bedrockナレッジベースの画面では指定できません。
response = bedrock.retrieve(knowledgeBaseId=bedrock_kb_id, retrievalQuery={"text": question})
response["retrievalResults"][0]["content"]["text"]
\n• Amazon RDS (MySQL )\n\n\n• Amazon RDS (Microsoft SQL Server)\n\n\n• Amazon RDS (Oracle)\n\n\n• Amazon RDS (PostgreSQL )\n\n\n• IBM DB2\n\n\n• Microsoft SQL Server\n\n\n• MySQL\n\n\n• Oracle Database\n\n\n• PostgreSQL\n\n\nAmazon Kendra コンソールと DatabaseConfiguration API を使用してデータベースデータソース \nAmazon Kendra に接続できます。\n\n\nAmazon Kendra データベースデータソースコネクタのトラブルシューティングについては、「」を\n参照してくださいデータソースのトラブルシューティング。\n\n\nトピック\n\n\n• サポートされている機能\n\n\n• 前提条件\n\n\n• 接続手順\n\n\nサポートされている機能\n\n\nAmazon Kendra データベースデータソースコネクタは、次の機能をサポートしています。\n\n\n• フィールドマッピング\n\n\n• ユーザーコンテキストフィルタリング\n\n\n• 仮想プライベートクラウド (VPC)\n\n\nAmazon RDS/Aurora 645\n\n\n\nhttps://docs.aws.amazon.com/kendra/latest/dg/data-source-aurora-mysql.html\n\nhttps://docs.aws.amazon.com/kendra/latest/dg/data-source-aurora-postgresql.html\n\nhttps://docs.aws.amazon.com/kendra/latest/dg/data-source-rds-mysql.html\n\nhttps://docs.aws.amazon.com/kendra/latest/dg/data-source-rds-ms-sql-server.html\n\nhttps://docs.aws.amazon.com/kendra/latest/dg/data-source-rds-oracle.html\n\nhttps://docs.aws.amazon.com/kendra/latest/dg/data-source-rds-postgresql.html\n\nhttps://docs.aws.amazon.com/kendra/latest/dg/data-source-ibm-db2.html\n\nhttps://docs.aws.amazon.com/kendra/latest/dg/data-source-ms-sql-server.html\n\nhttps://docs.aws.amazon.com/kendra/latest/dg/data-source-mysql.html\n\nhttps://docs.aws.amazon.com/kendra/latest/dg/data-source-oracle-database.html\n\nhttps://docs.aws.amazon.com/kendra/latest/dg/data-source-postgresql.html\n\nhttps://console.aws.amazon.com/kendra/\n\nhttps://docs.aws.amazon.com/kendra/latest/APIReference/API_DatabaseConfiguration.html\n\n\n\n\n\nAmazon Kendra 開発者ガイド\n\n\n前提条件\n\n\nを使用してデータベースデータソース Amazon Kendra のインデックスを作成する前に、データベー\nスと AWS アカウントでこれらの変更を行います。\n\n\nデータベースで以下を確認してください。\n\n\n• データベースのユーザー名とパスワードの基本認証情報を記録しました。\n\n\n• ホスト名、ポート番号、ホストアドレス、データベース名、ドキュメントデータが含まれている\nデータテーブルの名前をコピーしました。PostgreSQL の場合、データテーブルはパブリックテー\nブルまたはパブリックスキーマである必要があります。\n\n\nNote\n\n\nホストとポートは、インターネット上のデータベースサーバー Amazon Kendra の場所を\n指定します。データベース名とテーブル名は、データベースサーバー上のドキュメント
理由は分かりませんが、KendraのRetrieve APIを使用した場合とも異なる結果が返ってきました。
(左がKendaraのRetrieve API、右がBedrockナレッジベース)
料金
2024/12/7時点の料金です。月額(720時間)にすると以下の通り。
| エディション | 月額料金 |
|---|---|
| GenAI Enterprise Edition | $ 230.4 |
| GenAI Enterprise Edition 10万ドキュメント登録する場合 |
$ 950.4 |
| Basic Enterprise Edition | $ 1008.0 |
| Basic Developer Edition | $ 810.0 |
GenAI Indexは料金に含まれるドキュメント数が異なるので、10万ドキュメントの場合も算出しました。Basic Editionより高くなることはなさそうです。
フリートライアル対象ですので、まずはお試しでやってみてはいかがでしょうか!
