普段AWSばかりですが、他社の動向も知っておきたいと思って、Azure AI Searchを試しました。
先入観としては、Amazon KendraのAzure版だと思って始めました。うまく行けばRAGの情報源にしてKendraと比較がしたいと目論んでおります。
Azureに詳しい方のツッコミお待ちしております(笑)
Kendraについてはここを見るとわかった気になれます。
「Vertex AI Search and Conversationやってみた」はこちら
Azure AI Searchを作ってみた。
Azureポータルでポチポチしてみました。
-
Azure AI serviceのポータルを表示。
Search サービス の作成をクリック
-
サービス名などを入力し、
確認及び作成をクリック

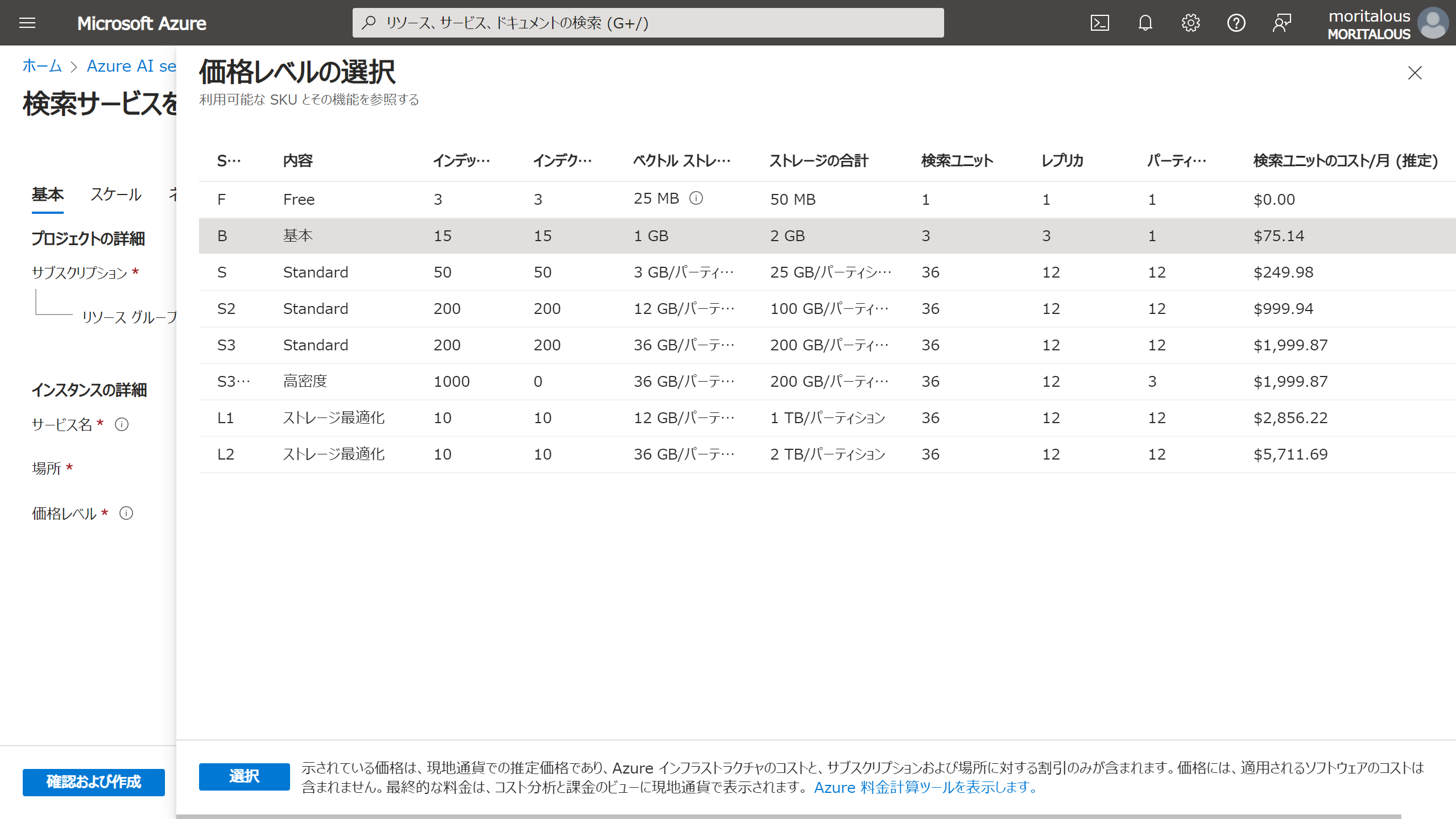
価格レベル。(料金が見れるの便利!AWSにもほしい)
-
作成をクリック
-
デプロイの完了を待つ
デプロイが終わったら、
リソースに移動をクリック
データを登録してみた。
-
データのインポートをクリック

-
データソースを
Azure BLOB ストレージを選択し、データソース名を入力
接続文字列部分の既存の接続を選択しますをクリックして、BLOBストレージを選択
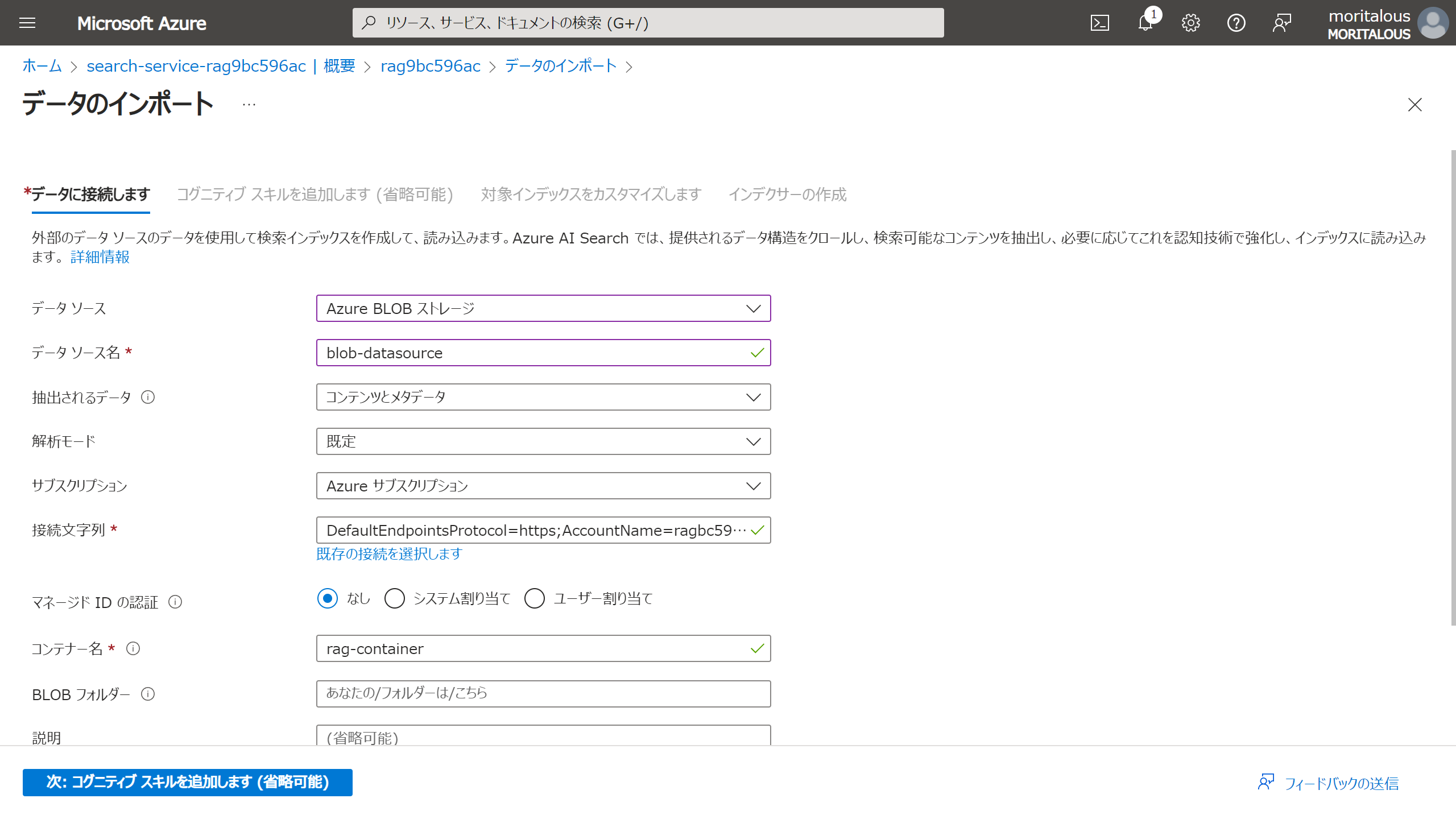
BLOBストレージの選択はこんな感じ
BLOBストレージ以外の選択肢
-
スキップをクリック

-
contentのアナライザーを日本語に変更し、次をクリック

-
名前を入力して
送信をクリック

-
初回同期が自動で始まります。同期ステータスはインデクサーから確認できます。
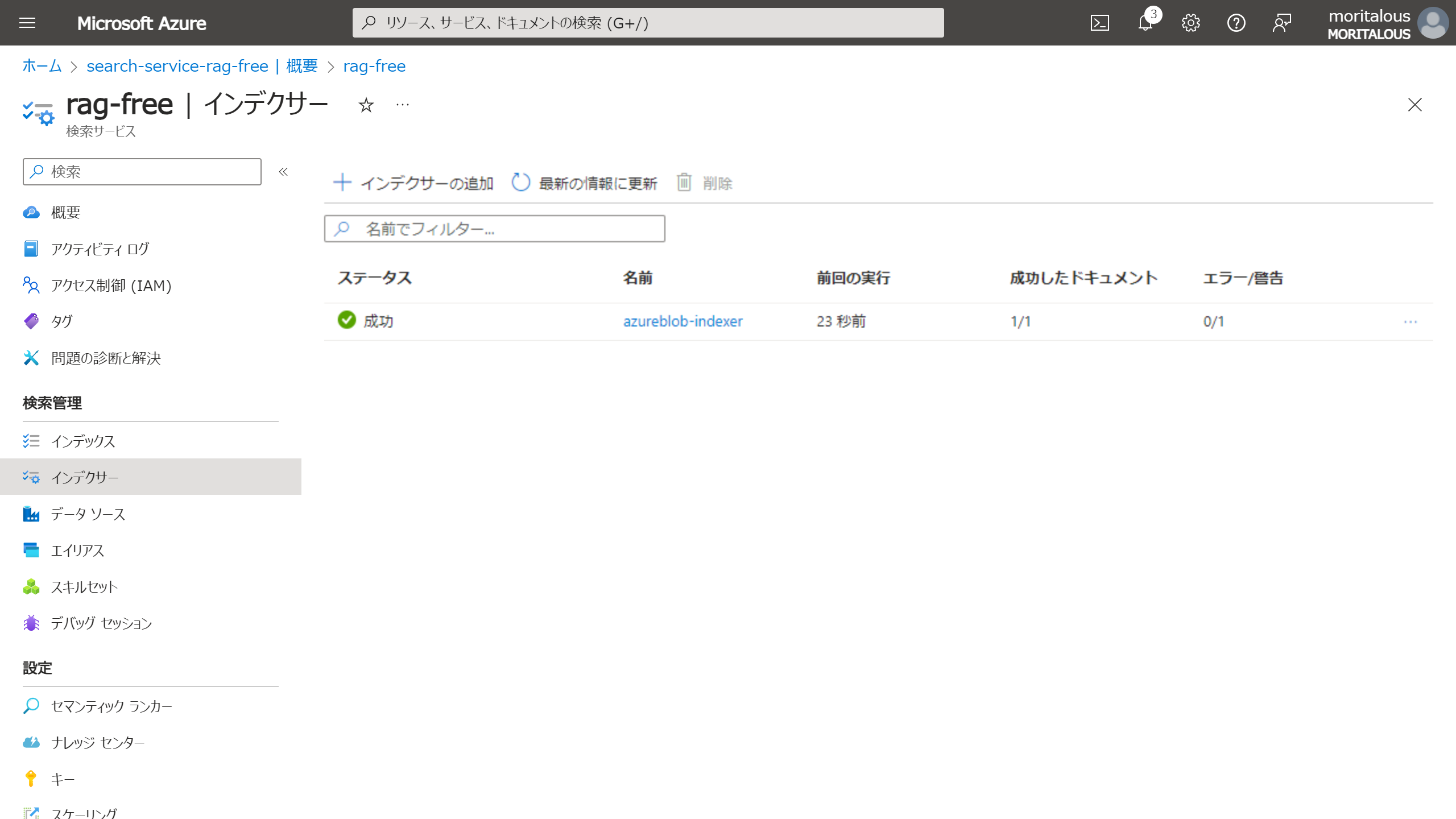
同期には成功していますが、エラーが出ています。
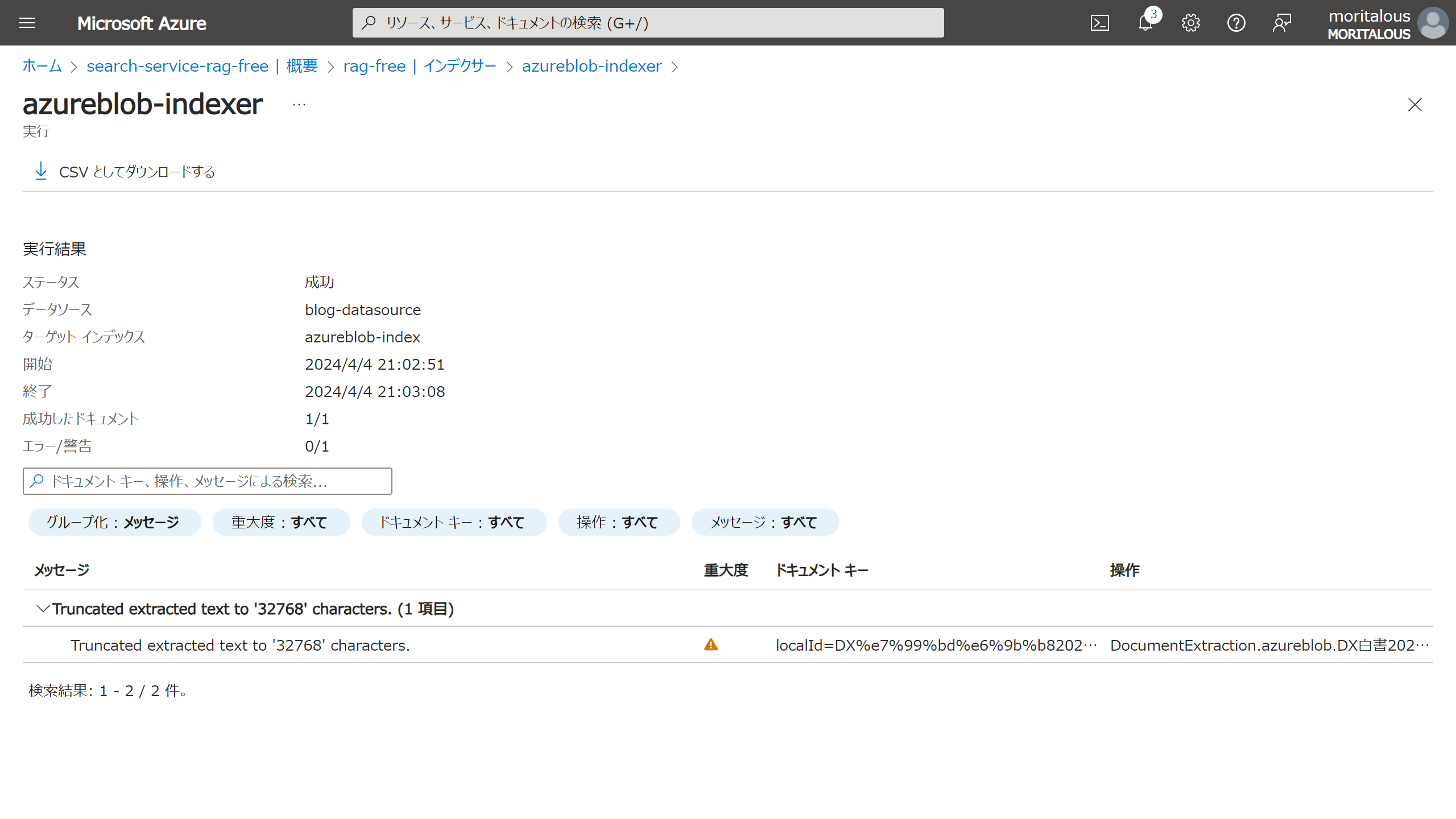
ドキュメントによると、価格レベルにより、取り込めるサイズが決まっているとのことです。
インデクサーには、1 つのドキュメントから抽出できるテキストの量の制限があります。 この制限は、価格レベルによって異なります。Free レベルの場合は 32,000 文字、Basic の場合は 64,000 文字、Standard の場合は 400 万文字、Standard S2 の場合は 800 万文字、Standard S3 の場合は 1,600 万文字です。 切り詰められたテキストには、インデックスが付けられません。 この警告を回避するには、大量のテキストを含むドキュメントを複数の小さなドキュメントに分割してみてください。
https://learn.microsoft.com/ja-jp/azure/search/cognitive-search-common-errors-warnings
登録されたデータを確認してみた。
-
インデックスメニューの、該当のインデックスをクリック
-
キーワードを入れずにとりあえず検索
ちなみに、登録したのはDX白書2023のPDFです。( https://www.ipa.go.jp/publish/wp-dx/dx-2023.html )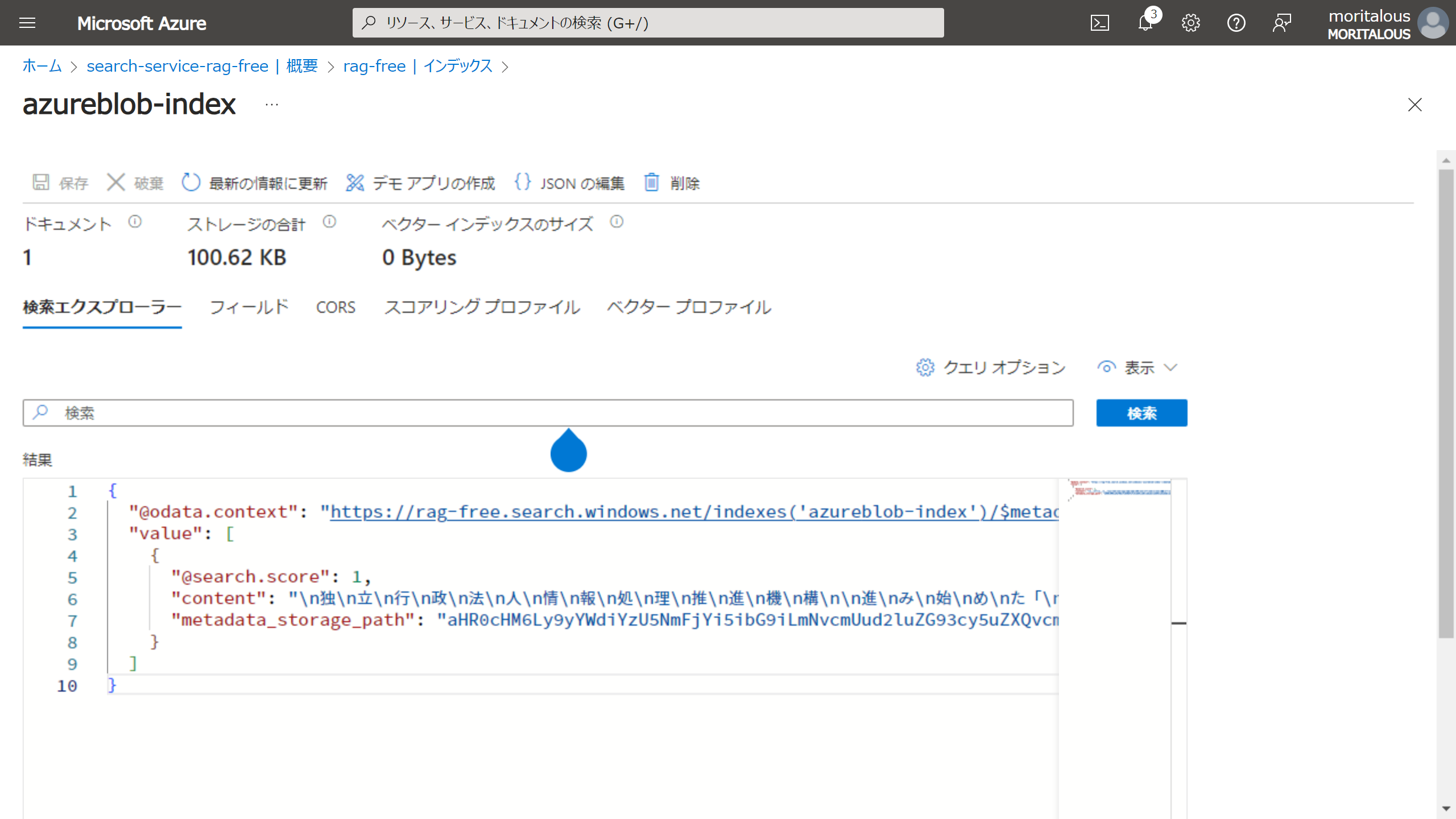
Kendra使いの皆さん、お気づきになりましたでしょうか?
そうです、 1ドキュメントが1件として登録される仕様 のようです。
設定漏れかもしれないのですが、分割して登録する方法がわかりませんでした(泣)
LangChainのRetrieverをやってみた。
こんな状況ではありますが、LangChainのRetrieverで使ってみます。
LangChainのドキュメントのとおりです。
まだAzure Cognitive Search表記ですね。ちなみにVector storesには、Azure AI Search表記のものがあります。これからはベクトルストアとして使うのがメインで、Retrieverとしての機能はあまりメインじゃないのでしょうか??
import os
from langchain_community.retrievers.azure_cognitive_search import (
AzureCognitiveSearchRetriever,
)
os.environ["AZURE_COGNITIVE_SEARCH_SERVICE_NAME"] = (
"https://*****.search.windows.net"
)
os.environ["AZURE_COGNITIVE_SEARCH_INDEX_NAME"] = "*****"
os.environ["AZURE_COGNITIVE_SEARCH_API_KEY"] = "*****"
retriever = AzureCognitiveSearchRetriever(content_key="content", top_k=10)
retriever.get_relevant_documents("DXとはなんですか?")
[Document(page_content='.........', metadata={'@search.score': 0.6293055, 'metadata_storage_path': 'aHR0cHM6Ly9yYWdiYzU5NmFjYi5ibG9iLmNvcmUud2luZG93cy5uZXQvcmFnLWNvbnRhaW5lci9EWCVFNyU5OSVCRCVFNiU5QiVCODIwMjMucGRm0'})]
取れたけど、、1件。。
次はGoogle CloudのVertex AI Search and Conversationに挑戦してみようと思います。