Container Insights の強化されたオブザーバビリティは、NodeやDeploymentのCPU・メモリなどのリソース使用率を手軽に可視化できます。本ドキュメントでは、強化されたオブザーバビリティを使用して、リソース使用率に基づくメトリクス監視を設定する方法を説明します。
環境
本ドキュメントで説明する設定は、以下の環境で実施したものです。他のバージョンでも同様に設定が可能だと思いますが、細かい部分は異なるかもしれません。
- EKS: v1.31
- amazon-cloudwatch-observability: v3.6.0-eksbuild.2
Nodeのメトリクス監視
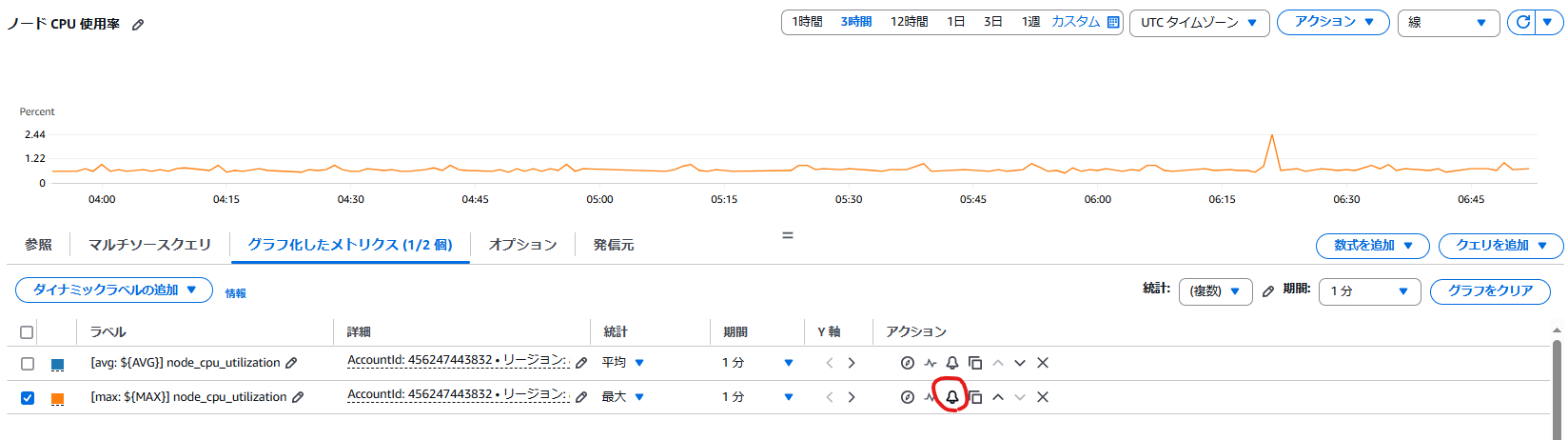
以下画面の様に Container Insights でノードを選択すると、ノード毎のCPU・メモリ使用率が可視化されます。しかし、このグラフにはInstanceIdやNodeNameの指定が含まれます。EKSではノードの入れ替えが発生するため、InstanceIdやNodeNameを指定したアラーム設定だとノードの入れ替えに対応できません。そのため別の方法を考えます。
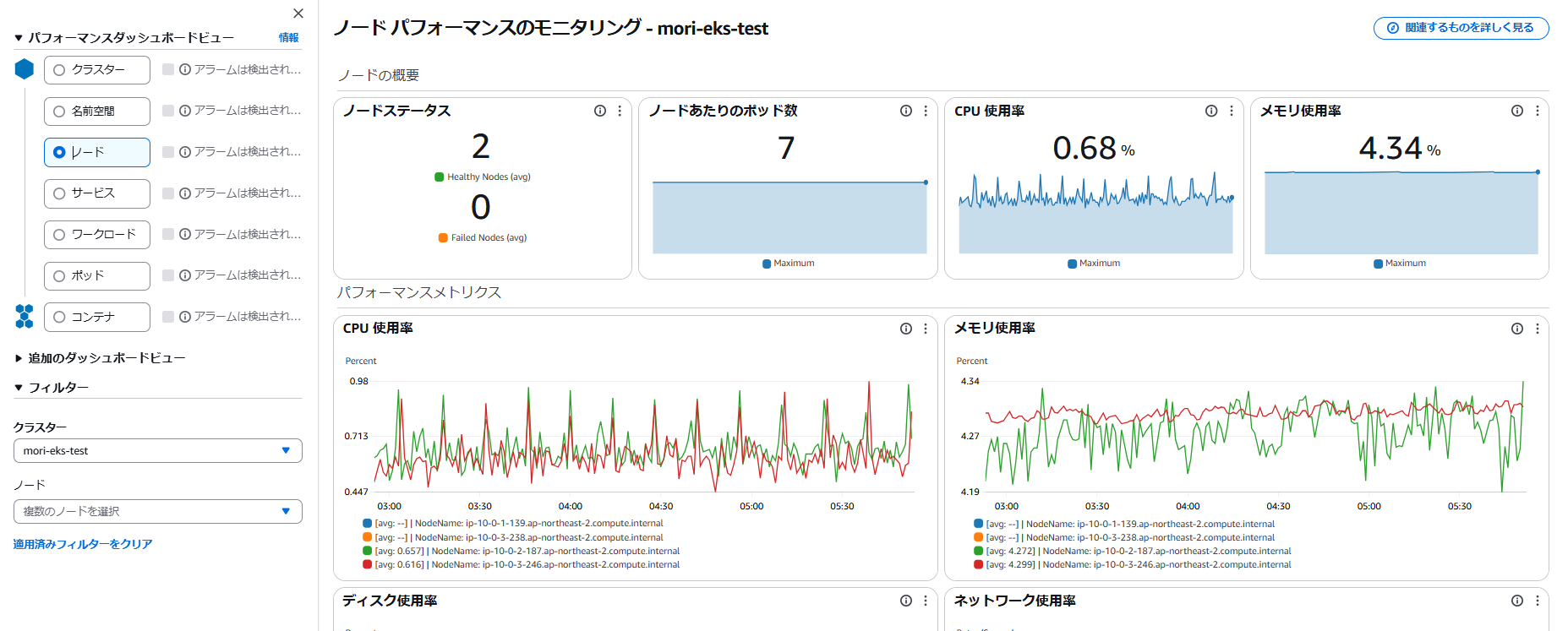
以下画面の様に Container Insights でクラスターを選択すると、クラスタ内全ノードのCPU・メモリ使用率が可視化され、平均使用率と最大使用率が表示されます。
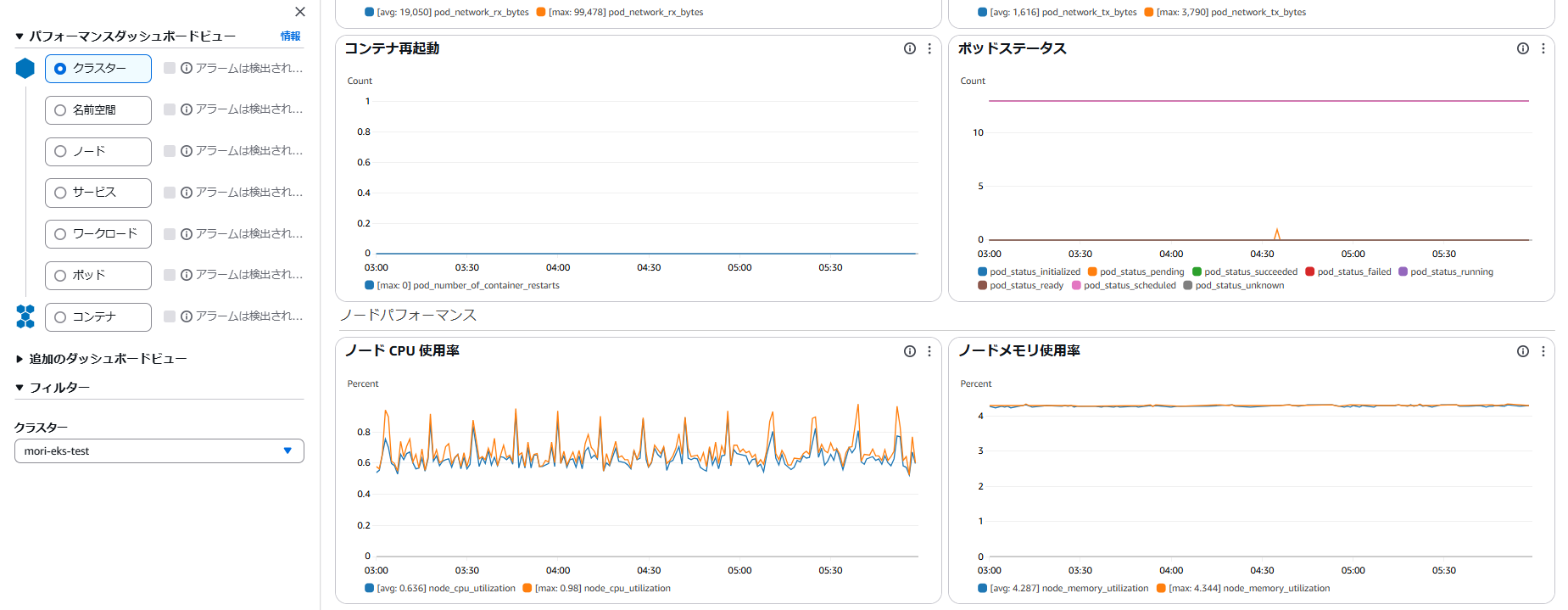
今回は異常を検知したいモチベーションを想定して、最大使用率が閾値を上回る場合を想定したアラームを設定します。
マネコンで設定
グラフにカーソルを移すと四方の矢印があります。
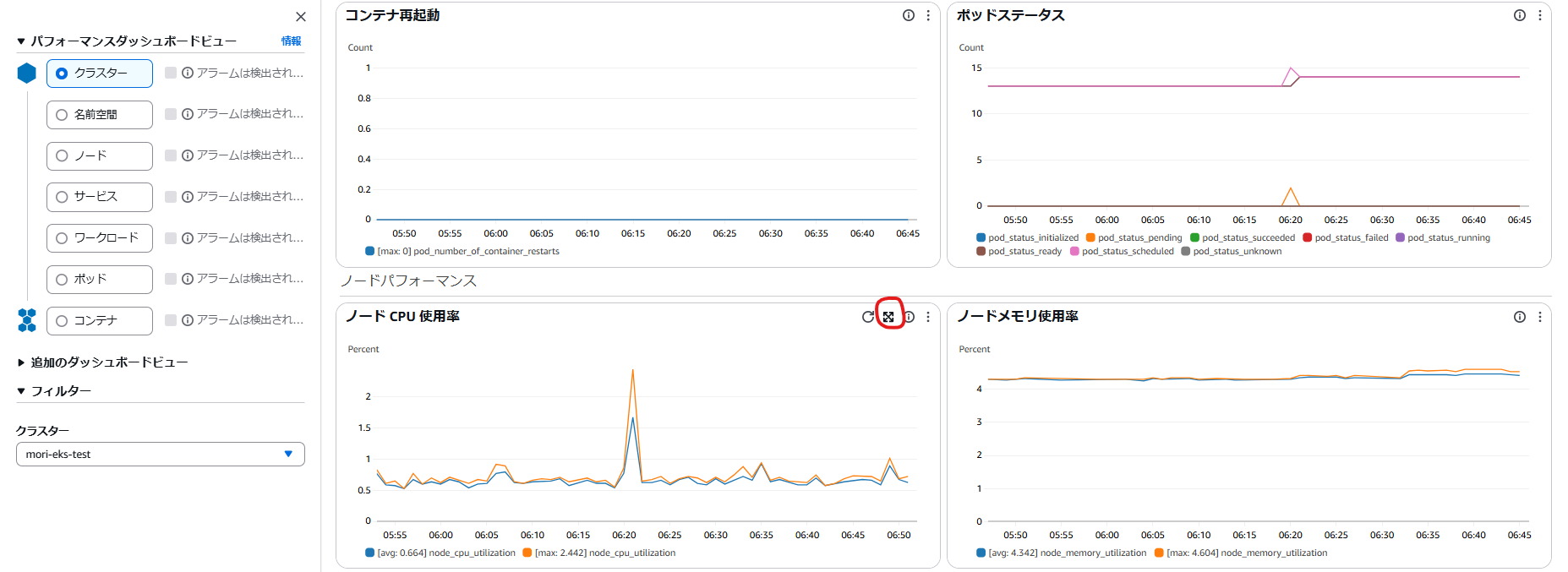
大きな画面でグラフが表示さるのでメトリクスで表示します。
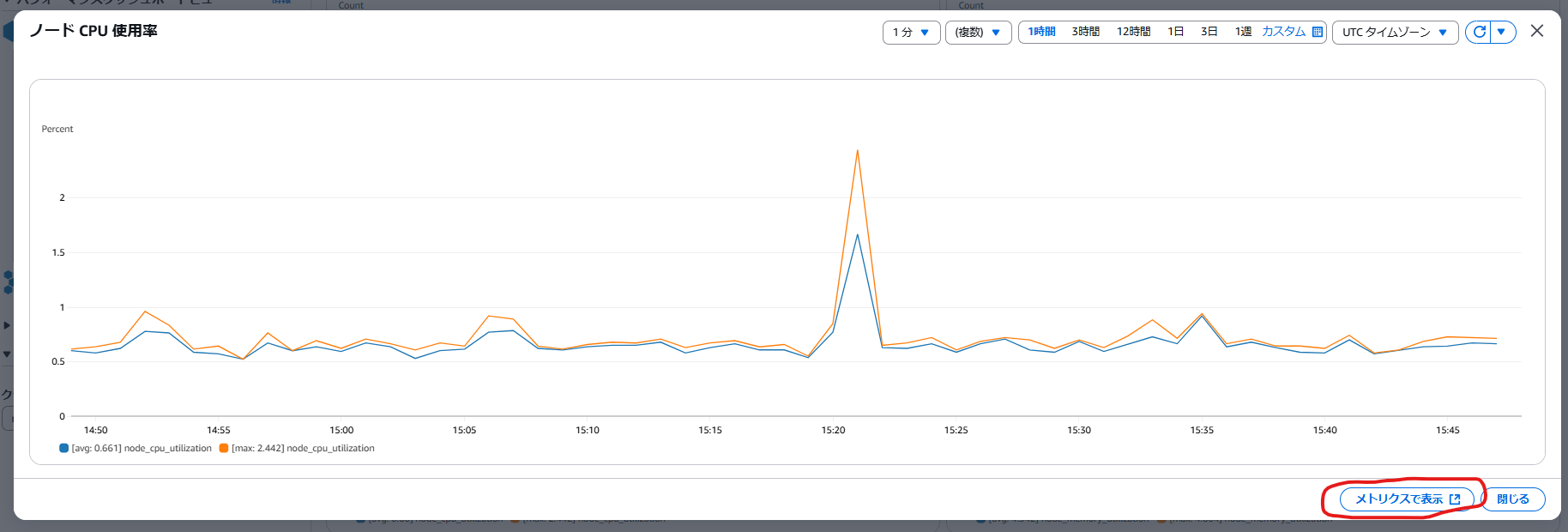
するとCloudWatchメトリクスの画面が表示されます。アラームを設定したいグラフのベルマークを押します。(今回は下の[max: ${MAX}]~のラベルが付いた方)
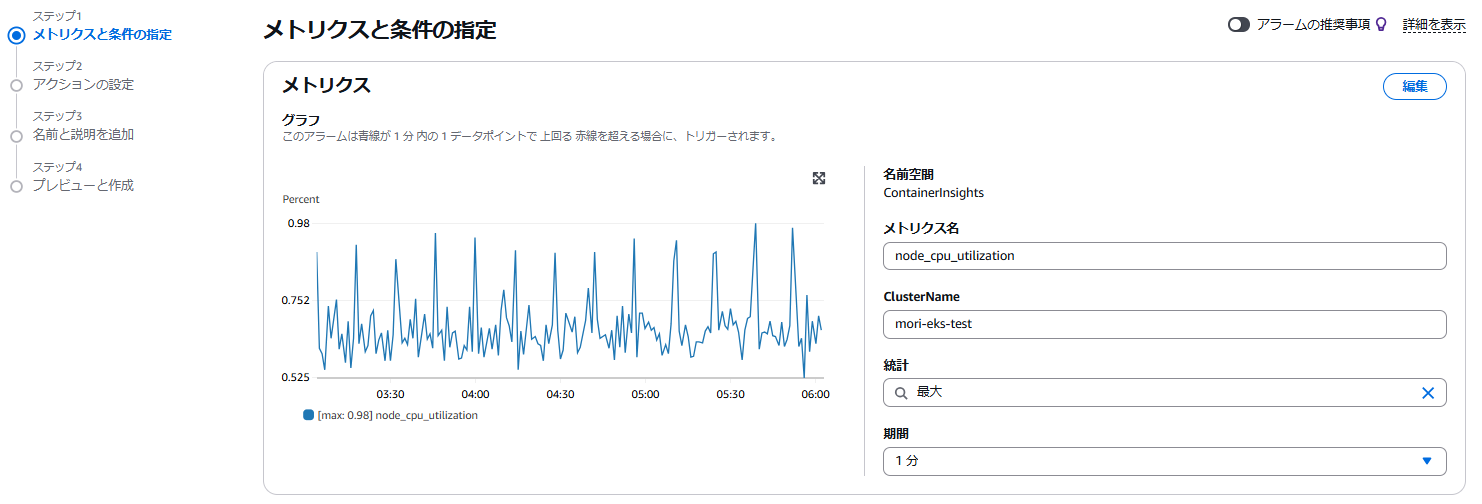
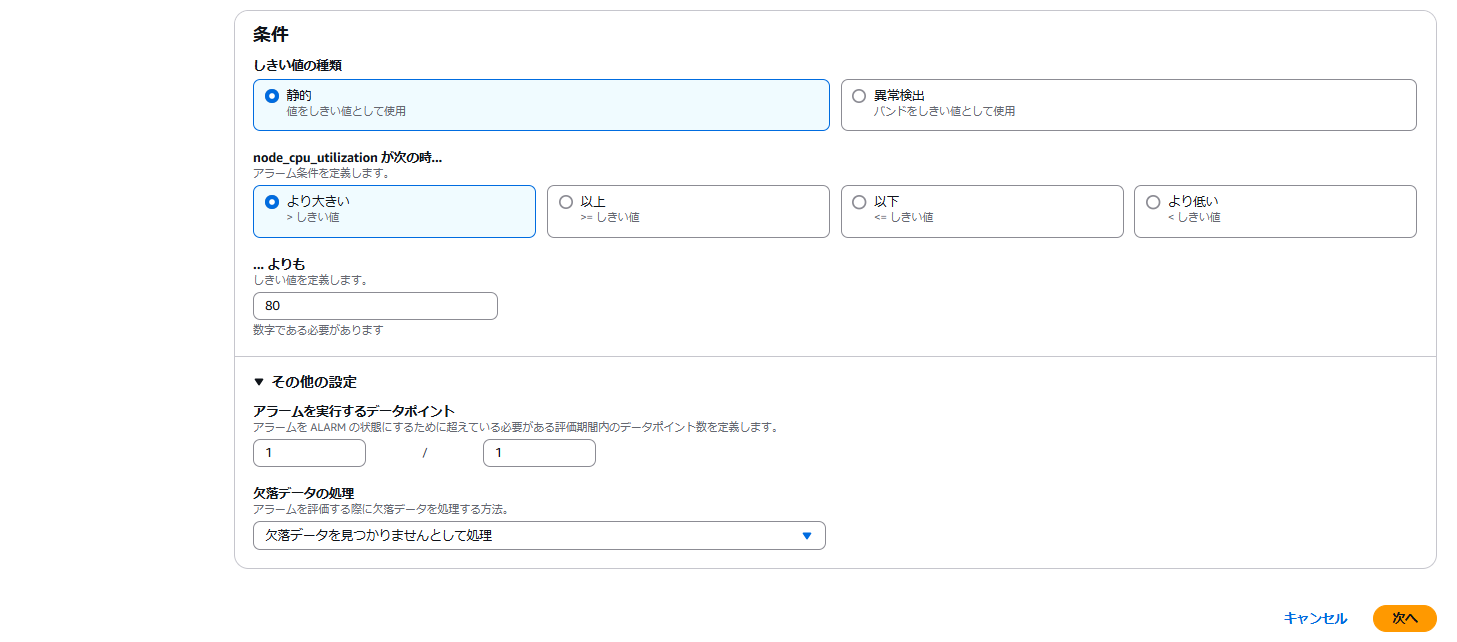
CloudWatchのアラーム作成で以下の様に設定します。以下の設定だと1分間隔でCPU使用率が80%より大きいNodeが一台でもあった場合にアラート状態となります。
Terraformで設定
同じ設定をTerraformで書くと以下の通りです。
resource "aws_cloudwatch_metric_alarm" "eks_node_cpu_utilization" {
alarm_name = "eks-node-high-cpu-utilization"
comparison_operator = "GreaterThanThreshold"
evaluation_periods = "1"
metric_name = "node_cpu_utilization"
namespace = "ContainerInsights"
period = "60" # 1分間隔で監視
statistic = "Maximum"
threshold = "80"
alarm_description = "EKSクラスタのノードCPU使用率がいずれかのノードで80%を超えました。"
alarm_actions = [aws_sns_topic.eks_alarm_topic.arn]
treat_missing_data = "ignore" # メトリクスの欠落を無視
dimensions = {
ClusterName = "mori-eks-test"
}
}
Deploymentのメトリクス監視
Container Insights でワークロードを選択すると、DeploymentなどのCPU・メモリ使用率が可視化されます。ややこしいですがポッド CPU 使用率とポッド CPU 使用率 (ポッド制限超過)の2つのグラフがあります。これらは以下の通り全くことなるグラフです。
-
ポッド CPU 使用率:
pod_cpu_usage_total / node_cpu_limit
Deploymentで展開したPodが平均どれくらいのノードCPUを消費しているかを表します。 -
ポッド CPU 使用率 (ポッド制限超過):
pod_cpu_usage_total / pod_cpu_limit
Podのresources.limitsに設定した値に対し、Deploymentで展開したPodが平均どれくらいのCPUを消費しているかを表します。
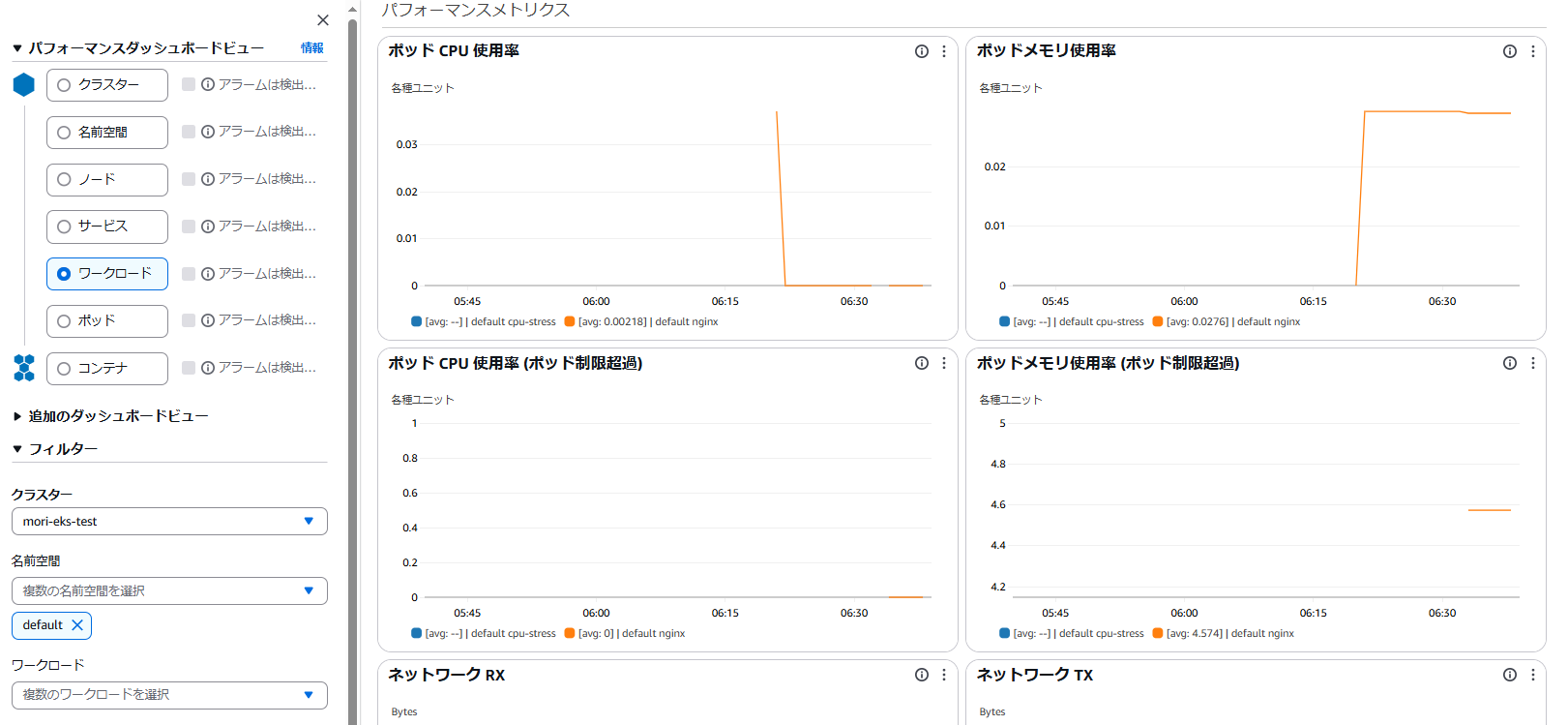
今回はDeploymentのリソース監視としてポッド CPU 使用率 (ポッド制限超過)に対するアラームを設定します。
マネコンで設定
Nodeの時と同じように Container Insights のグラフからCloudWatchメトリクスを表示し、監視したいグラフのベルマークを押します。
CloudWatchのアラーム作成で以下の様に設定します。以下の設定だと一分間隔でNamespace:defaultのDeployment:nginxで展開されたPod群の平均CPU使用率が80%より大きかった場合にアラート状態となります。
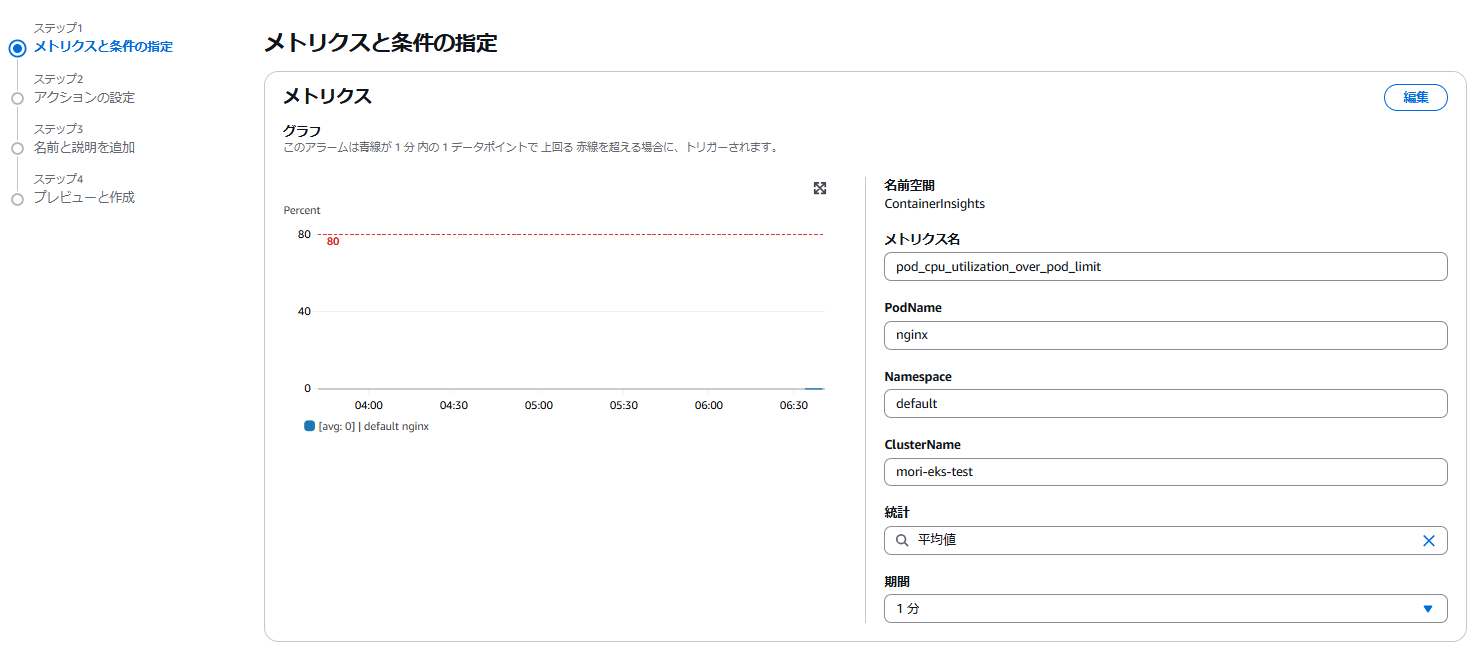
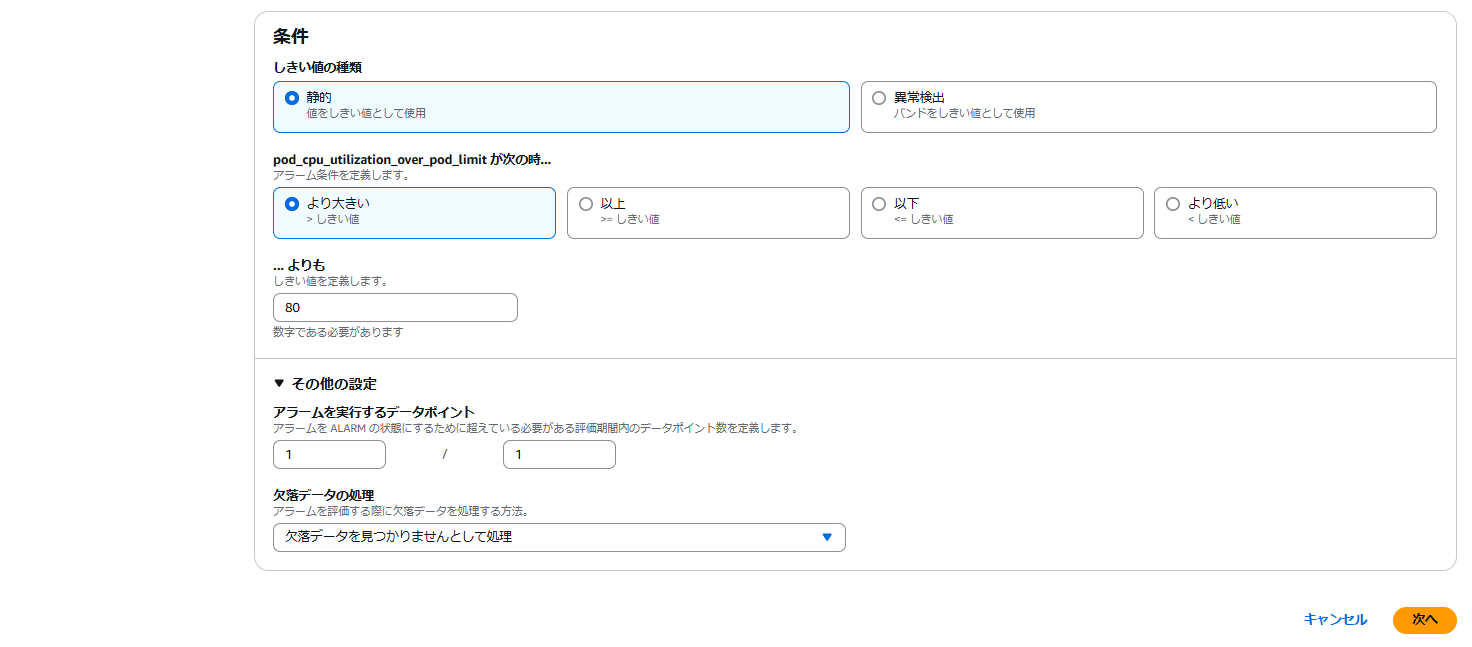
Terraformで設定
同じ設定をTerraformで書くと以下の通りです。
resource "aws_cloudwatch_metric_alarm" "eks_deployment_cpu_utilization" {
alarm_name = "eks-deployment-high-cpu-utilization"
comparison_operator = "GreaterThanThreshold"
evaluation_periods = "1"
metric_name = "pod_cpu_utilization_over_pod_limit"
namespace = "ContainerInsights"
period = "60"
statistic = "Average"
threshold = "80"
alarm_description = "EKSクラスタのDeploymentのCPU使用率(ポッド制限超過)が80%を超えました。"
alarm_actions = [aws_sns_topic.eks_alarm_topic.arn]
treat_missing_data = "ignore"
dimensions = {
ClusterName = "mori-eks-test"
Namespace = "default" # 監視対象のNamespaceを指定
Deployment = "your-deployment-name" # 監視対象のDeployment名を指定
}
}
その他の重要なメトリクス
上記ではCPU使用率を例に設定しました。他にも以下のメトリクスを監視してもいいと思います。
- Node
- メモリ使用率(
node_memory_utilization):メモリの枯渇を防ぎ、アプリケーションのパフォーマンス問題を特定します。 - ディスク使用率(
node_filesystem_utilization):ストレージの枯渇を防ぎ、データ損失のリスクを軽減します。 - ネットワークトラフィック(
node_network_total_bytes):通信の異常や過負荷を検出し、アプリケーションのパフォーマンス問題を特定します。 - 異常ノード数(
cluster_failed_node_count):リソース不足やスケジューリングの問題を早期に発見できます。
- メモリ使用率(
- Deployment
- メモリ使用率(
pod_memory_utilization_over_pod_limit):メモリの枯渇を防ぎ、アプリケーションのパフォーマンス問題を特定します。 - 異常Pod数(
pod_status_pending、pod_status_unknown、pod_status_failed):リソース不足やスケジューリングの問題を早期に発見できます。
- メモリ使用率(
その他にも多数のメトリクスがあります。詳細は公式のドキュメントを確認ください。