1. はじめに
(注意 著者はこの分野をがっつり専門にしているわけではないので、説明の不足や誤りもあるかもしれません。)
この記事は単回帰分析をKerasで実装する解説を雑にします。Jupyter NotebookをGitHubで公開するので、環境さえあればすぐ試せます。
また、単回帰分析についてはUdemyの【キカガク流】人工知能・機械学習 脱ブラックボックス講座-初級編- を参考にしています。詳しい解説を見たい方は受講をおすすめします。
【キカガク流】人工知能・機械学習 脱ブラックボックス講座-初級編-
https://www.udemy.com/course/kikagaku_blackbox_1/learn/lecture/8258758#overview
ノートブックはこちら
SimpleRegressionAnalysis_2.ipynbを実行してください。実行環境などはノートブックの頭に記載してあります。
https://github.com/moriitkys/SimpleRegressionAnalysis
2. 単回帰分析 雑解説
単回帰分析の説明でわかりやすく以下のようにまとめられています。
「1つの目的変数を1つの説明変数で予測するもので、その2変量の間の関係性をY=aX+bという一次方程式の形で表します。a(傾き)とb(Y切片)がわかれば、X(身長)からY(体重)を予測することができる」
https://www.albert2005.co.jp/knowledge/statistics_analysis/multivariate_analysis/single_regression
また、こちらのページでは詳しく説明してあります。
回帰分析(単回帰分析)をわかりやすく徹底解説!
https://udemy.benesse.co.jp/ai/regression-analysis.html
今回やることを図にしたら以下です。
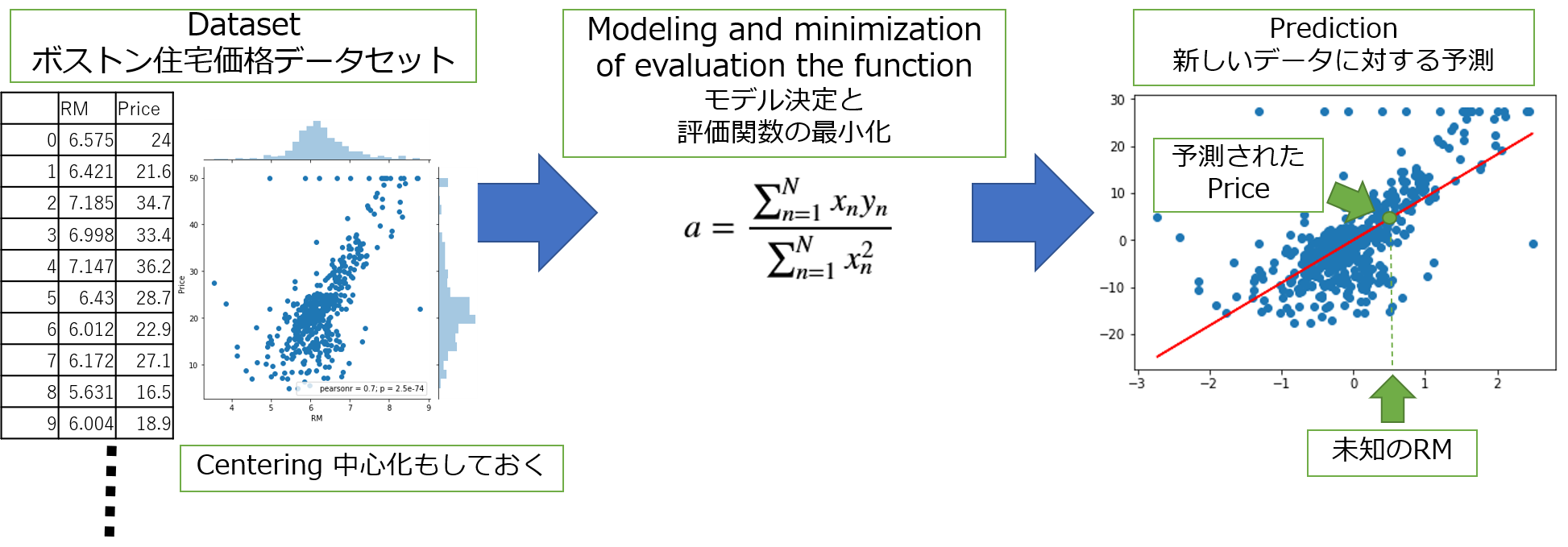
3. 単回帰分析 Keras
Kerasというニューラルネットワーク用ライブラリを用いて単回帰分析をします。Pythonで書かれていてTensorflow上などで実行可能です。
今回は単回帰分析なので、
モデルの作成:
model=Sequential()
model.add()
(注意 活性化はしない)
モデル初期化
model.init()
モデルの学習を開始
model.fit()
モデルの推測
model.prediction()
のような流れになります。コードはこの部分です。
# Build model
model = Sequential()
model.add(Dense(1, input_shape=(s, ), use_bias=False))
opt = keras.optimizers.Adam(lr=0.04, beta_1=0.9, beta_2=0.999, epsilon=1e-08, decay=0.0003)
model.compile(optimizer=opt,
loss='mean_squared_error',
metrics=['mae'])
# Start training
history = model.fit(x_normalized, y_normalized, epochs=50, batch_size=20, verbose=1)
以下のような単純な形です。
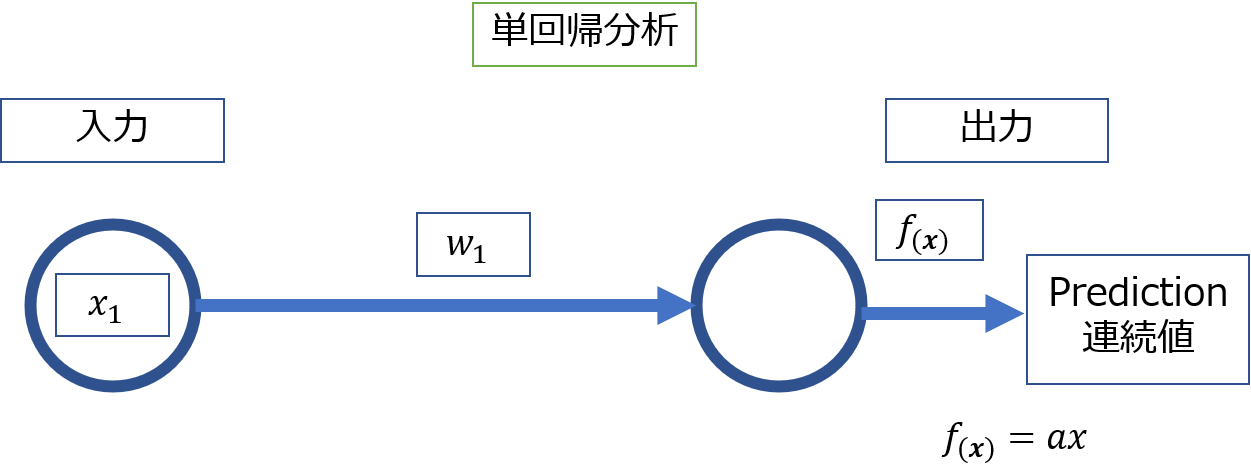
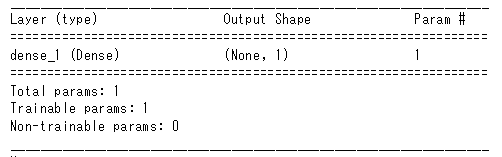
したがってmodel.summary()の結果もパラメータが一つです。
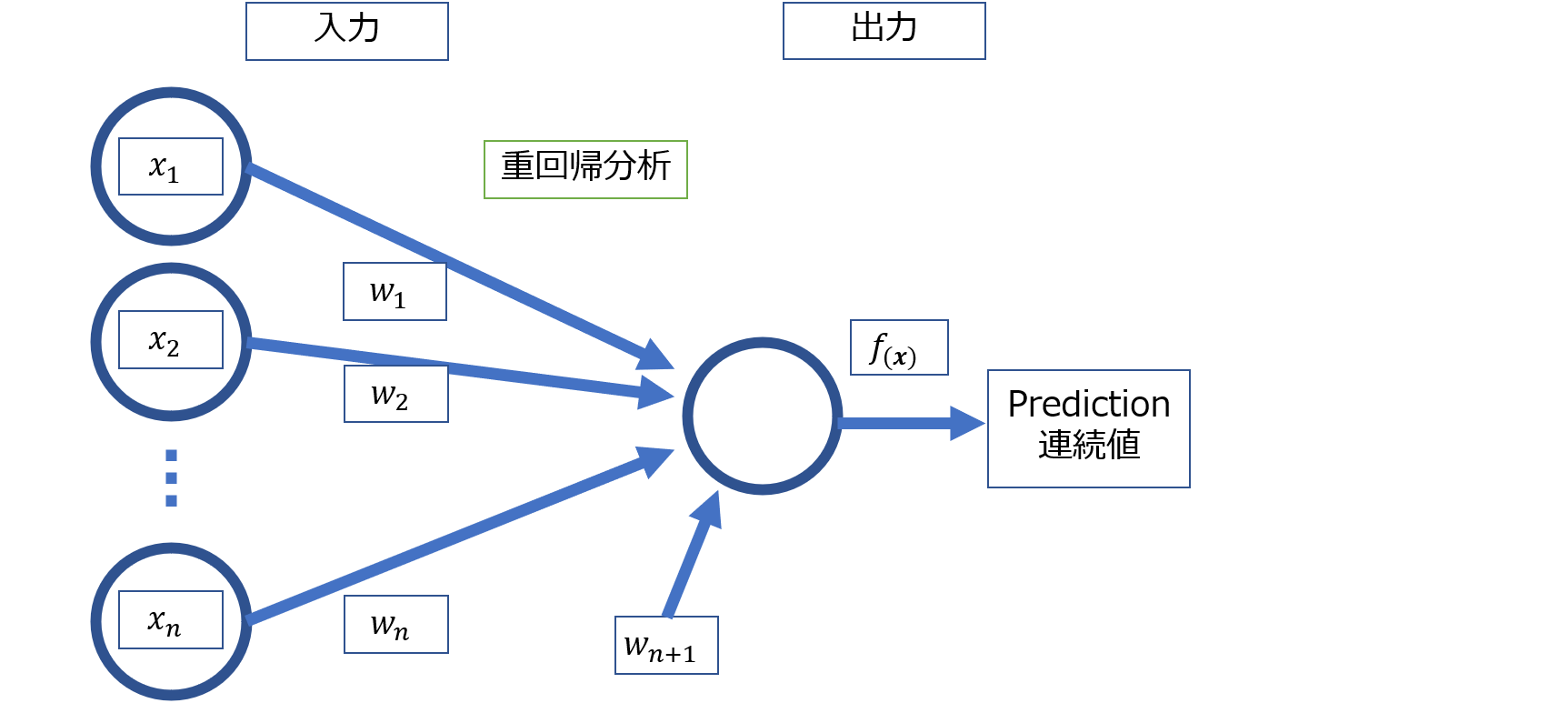
もし重回帰分析になったら以下のような感じになります。
学習の結果、損失値は以下のように推移し、すぐにフィッテングしたようです。
横軸にはエポック数がとってあります。

4. 実際にJupyter Notebookを実行
計算でモデル化、評価関数の設定と最小化によってaを求めた結果のモデルと、Kerasでモデルを求めた結果は以下です。
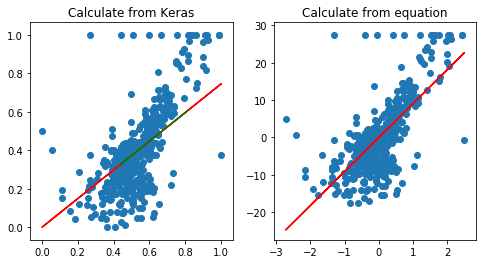
緑でプロットした点は住宅価格データセットのRMの98~108番目を今回作成した単回帰分析のモデルに入力して推測させた結果です。直線のモデルなので、直線上で推測されているのがわかります。 ちなみにKerasを使うときにデータを0から1のレンジにしていますが、普通に入力すると学習できないですので、注意(このノートブックのやり方では学習できないです)。よってaの値も見かけは式で計算したときと大きく異なりますが、データにはどちらも同様にフィッティングしているのではないでしょうか。
おまけ
初心を忘れないように、pandasでのデータ読み込みをforループで書き直したものをSimpleRegressionAnalysis_3.ipynbに載せました。機械学習を始めたばかりでここが何やってるかわからないという人は、参考までに。
with open('boston.csv') as f:
reader = csv.reader(f)
for row in reader:
x_orig.append(row[6])
y_orig.append(row[14])
こんな感じです。記事は更新するかもしれません。
参考
https://matplotlib.org/
https://matplotlib.org/3.2.1/api/_as_gen/matplotlib.pyplot.subplot.html
https://pandas.pydata.org/pandas-docs/stable/reference/frame.html
https://scikit-learn.org/stable/
https://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_boston.html#sklearn.datasets.load_boston
https://seaborn.pydata.org/
https://keras.rstudio.com/articles/tutorial_basic_regression.html
https://www.kaggle.com/xgdbigdata/keras-regression-tutorial
https://github.com/KatsuhiroMorishita/machine_leaning_samples
https://www.udemy.com/course/kikagaku_blackbox_1/learn/lecture/8258758#overview