はじめに
- 今回は自分で収集した画像を学習して分類するようなニューラルネットワークを自分で作成します。(バックボーンは選択できるようにしてあります。)
- 用いる深層学習フレームワークはKerasとPyTorchで、両者の違いも比較します。
- プログラムはこちら↓ (実行環境はページ下部に記載)
GitHub-moriitkys/MyOwnNN
問題設定
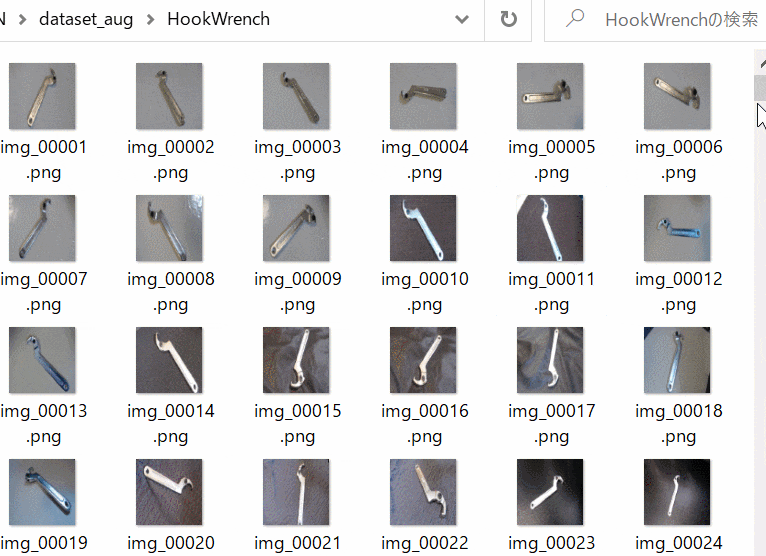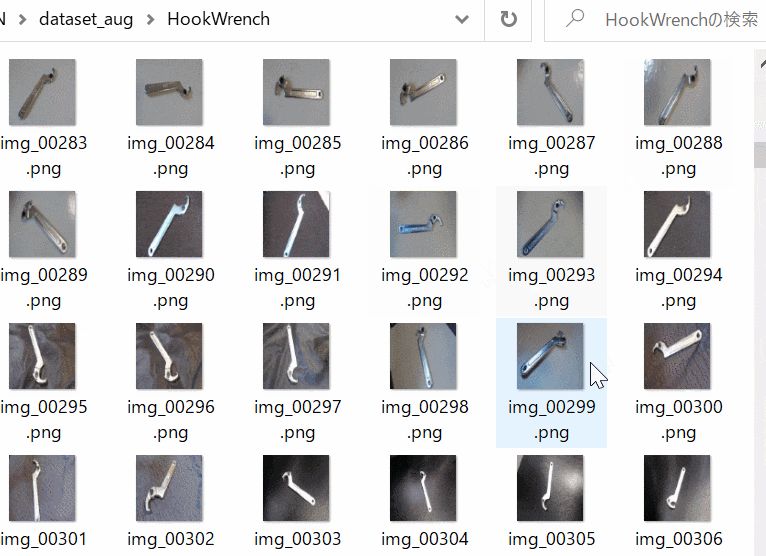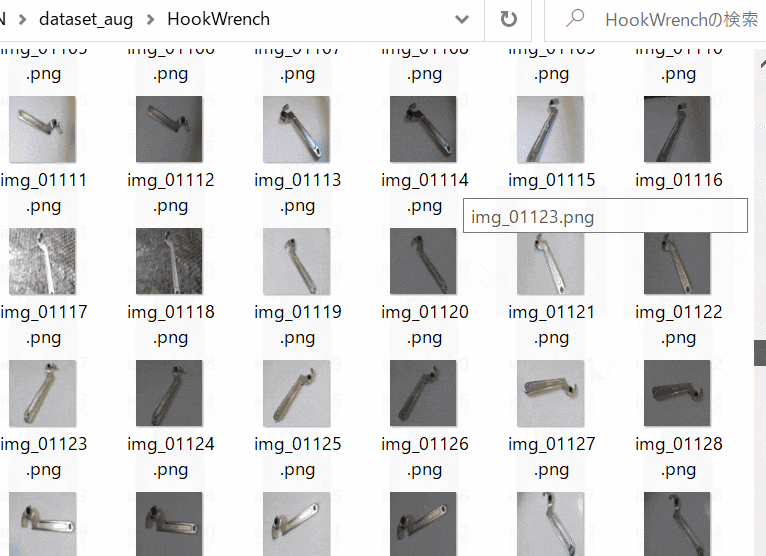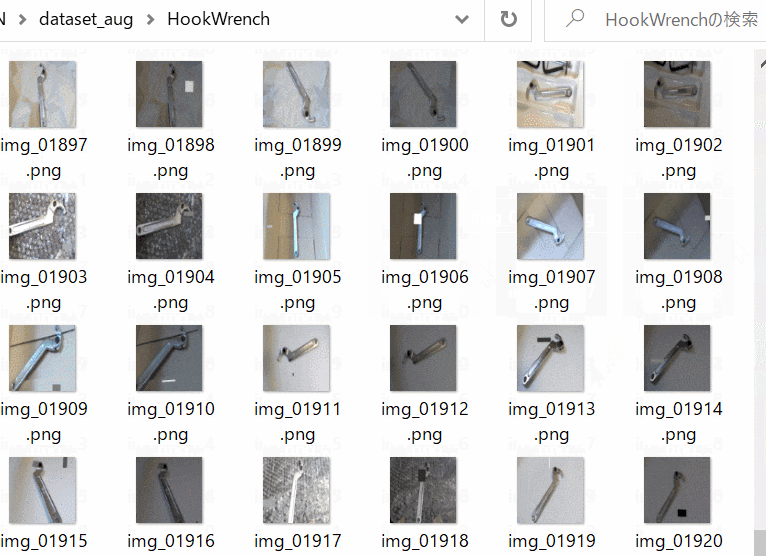
- データセットは試しにフックレンチ(62枚)とスパナレンチ(62枚)を収集・拡張して学習・評価(検証)用画像として用います(Figure 1-a,b)。工具分類です。
 |
 |
|---|---|
 |
 |
| Figure 1-a. Hook Wrench | Figure 1-b. Spanner Wrench |
- 自作NN(MyNet)の入力は28x28x3で出力は2で、分類問題です。ネットワーク構造は下で詳細を述べます。
- 学習回数はepoch、最適化関数はSGD、損失関数はcategorical crossentropy
- テスト画像(未知画像)は学習・評価に用いていないフックレンチ2枚、スパナレンチ2枚を用意
- UIは前回PyTorchのためのデータセット準備で使ったものを流用
- おまけで前回の続きの工作機械メーカー2社のロゴ分類もしてみました
ネットワーク構造
自作NNを本記事ではMyNetと呼びます。入力層(28283 nodes)、中間層(200 nodes)、出力層(2 outputs)で構成されるネットワークです。今回はRGBの3チャンネルも考慮できるようにしてあります。構造の概念図はFigure 2.です。
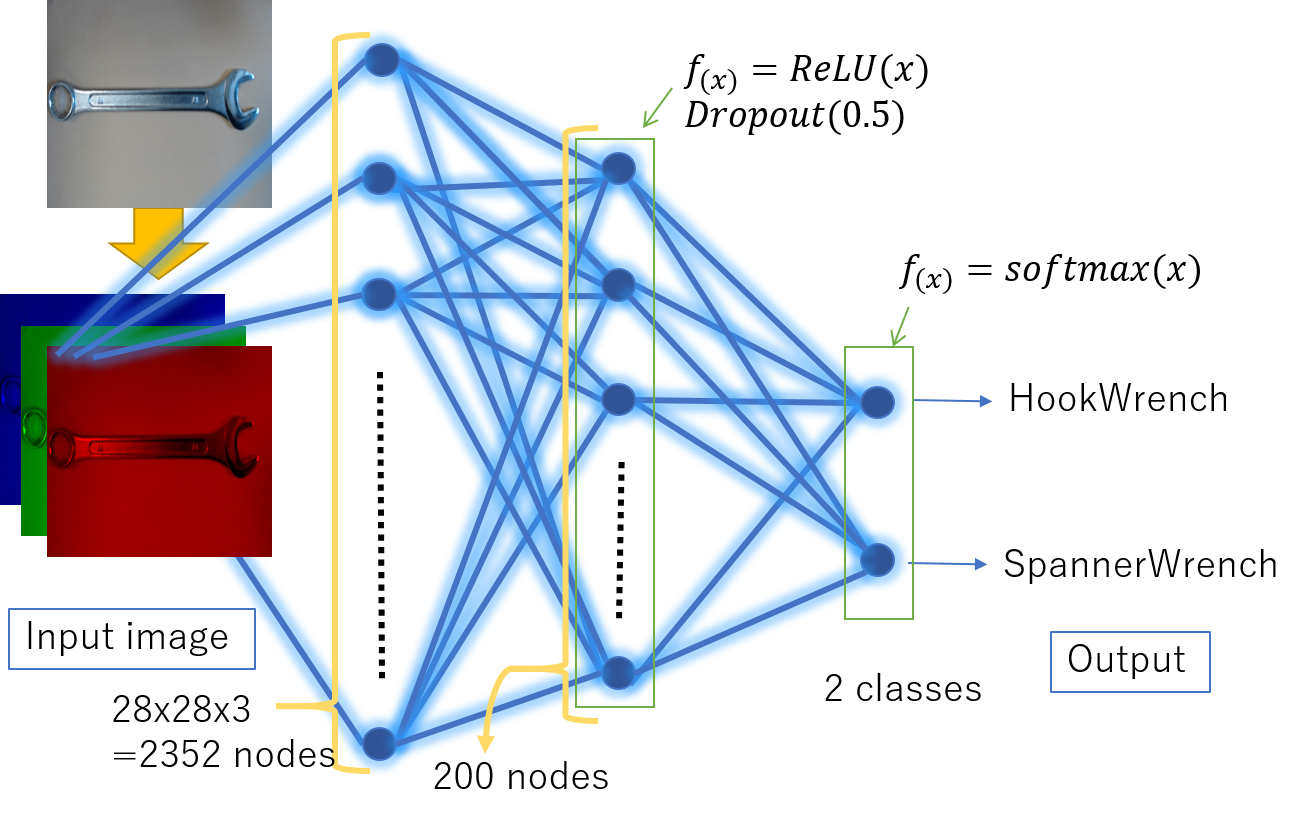 |
|---|
| Figure 2. MyNetの概念図 |
中間層では活性化関数としてReLUを適用し、Dropoutも適用します。
出力層で活性化関数としてsoftmax関数を適用し、クラスごとの出力(2つ)
を得ます。
ネットワークに関する簡単用語解説
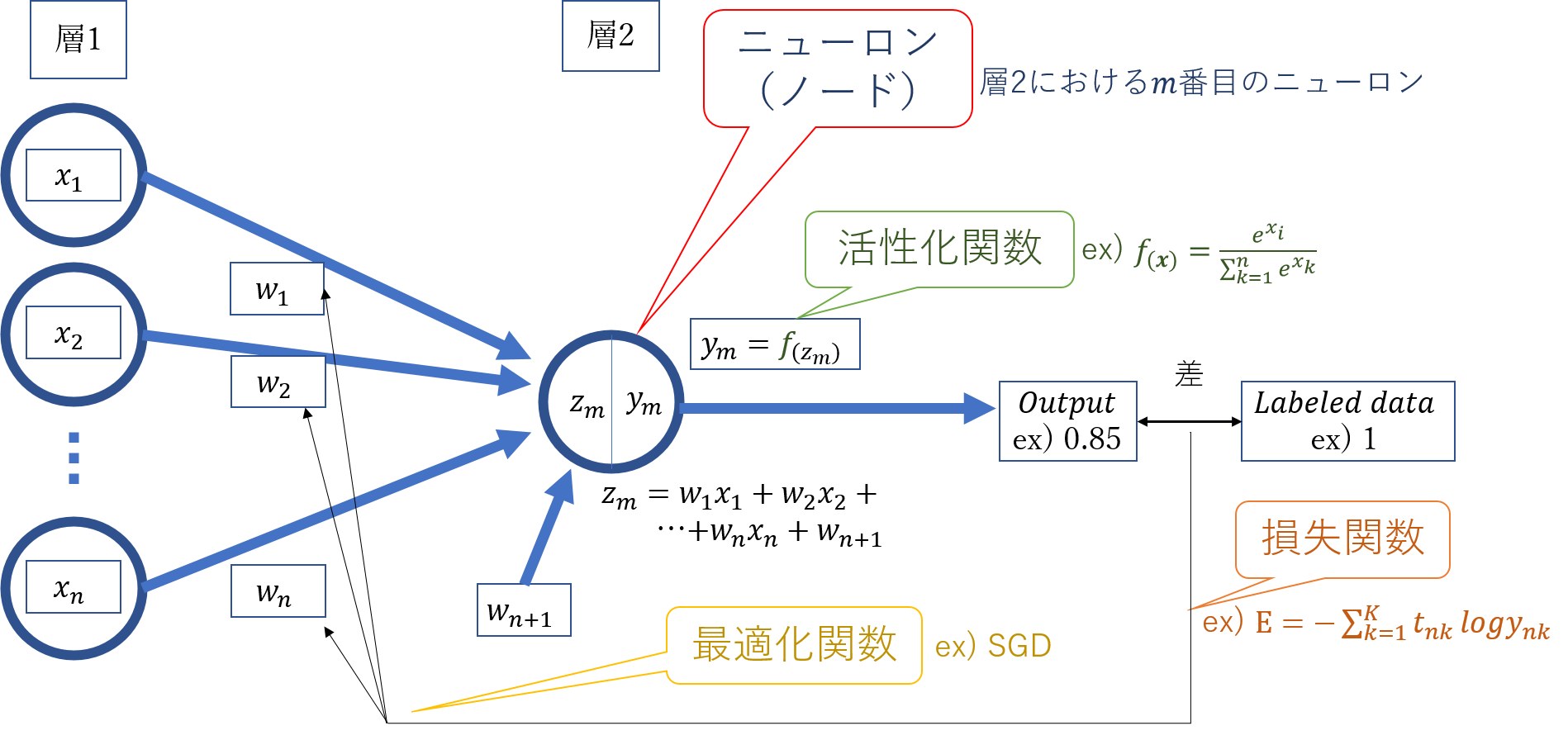 |
|---|
| Figure 3. 機械学習における用語と学習の概念図 |
・ニューロン、ノード
入力信号を受けて何か出力を出す部分の事。Figure 3.で示す通り丸い形状の部分をニューロン(ノード)と呼び、入力信号に何か関数変換して出力信号を出します。
・活性化関数 : ReLU、softmax
各ニューロン(ノード)において入力から出力を得る際の変換をする関数の事。図に示す$f_{( )}$のようなもの。
活性化関数の説明はここをクリック
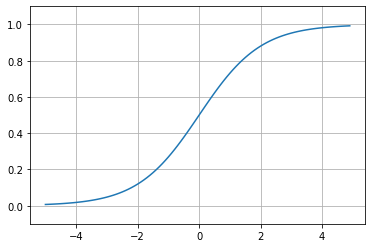
図では例としてソフトマックス関数を記載している。ソフトマックス関数は最終層で用いられ、各クラスに対応する出力の合計が1になる(クラス確率とみなせる)。活性化関数は脳のシナプスがある閾値を超えると発火するという現象を模倣するために使われるものである。活性化関数を非線形関数とすることで画像認識における認識精度は飛躍的に向上した。 ソフトマックス以外にReLU、シグモイドなどがあり、場面により使い分ける必要があるが、新しいものが続々出てきている。 ※非線形とは一本の直線で書けない事を言い、線形関数とは一本の直線で書けるような関数の事。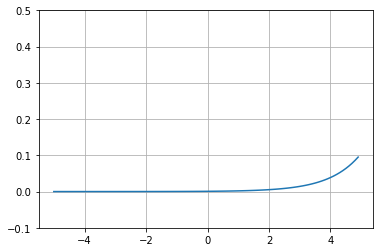 |
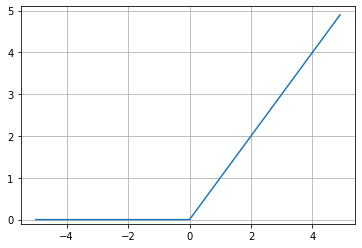 |
 |
|---|---|---|
| Figure 4-a. ソフトマックス関数 | Figure 4-b. ReLU | Figure 4-c. シグモイド関数 |
・損失関数 : categorical_crossentropy
損失値とはニューラルネットワークが予測した値と正解の誤差であり、その誤差を求める関数が損失関数です。図のようにモデルの出力と正解ラベルから誤差を計算する関数です。
損失関数の説明はここをクリック
図では例としてクロスエントロピーを記載している。クロスエントロピーはクラス分類のタスクで用いられる。クロスエントロピーの式は以下。 $$E=-\sum_{k=1}^{K} t_{n k} \log y_{n k}$$ $n$はサンプル番号、$K$はクラス数、$y_{nk}$は$n$サンプル目クラス$k$の出力、$t_{nk}$は$n$サンプル目クラス$k$の正解ラベル・最適化関数 : SGD
最適化関数は損失関数の値が減少するように重みを変化させる関数です。図のように誤差と重みから勾配を計算し、重み調整します。
最適化関数の説明はここをクリック
関数というより最適化アルゴリズムという方が適切であり、図では例としてSGDと記載してある。SGD(確率的勾配降下法)はミニバッチ学習において繰り返し少しずつ重み更新を行う。以下の図がSGDの重み更新の概念アニメーションであり、$w←w±εΔE$のように更新する。 その他、Adam、RMSpropなどの最適化関数がある。 ・Keras
Pythonで書かれた,TensorFlowまたはCNTK,Theano上で実行可能な高水準のニューラルネットワークライブラリの事。
・PyTorch
It’s a Python-based scientific computing package targeted at two sets of audiences:
・A replacement for NumPy to use the power of GPUs
・a deep learning research platform that provides maximum flexibility and speed
Kerasでの実装
完全なプログラム全体はGitHubを見てください。以下はMyNet部分の抽出です。
Kerasでの実装
# Build a model
from keras.applications.mobilenet import MobileNet
from keras.applications.resnet50 import ResNet50
from keras.layers.pooling import GlobalAveragePooling2D
from keras.layers.core import Dense, Dropout, Flatten
from keras.models import Model, load_model, Sequential
from keras.optimizers import Adam, RMSprop, SGD
base_model = Sequential()
top_model = Sequential()
INPUT_SHAPE = (img_size[0], img_size[1], 3)
neuron_total = 500
elif type_backbone == "MyNet":
INPUT_SHAPE = (img_size[0], img_size[1], 3)
base_model.add(Dense(neuron_total, activation='relu',
input_shape=(INPUT_SHAPE[0]*INPUT_SHAPE[1]*INPUT_SHAPE[2],)))
base_model.add(Dropout(0.5))
top_model.add(Dense(nb_classes, activation='softmax',
input_shape=base_model.output_shape[1:]))
# Concatenate base_model(backbone) with top model
model = Model(input=base_model.input, output=top_model(base_model.output))
print("{}層".format(len(model.layers)))
# Compile the model
model.compile(
optimizer = SGD(lr=0.001),
loss = 'categorical_crossentropy',
metrics = ["accuracy"]
)
model.summary()
PyTorchでの実装
完全なプログラム全体はGitHubを見てください。以下はMyNet部分の抽出です。
PyTorchでの実装
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torchvision.models
from torchsummary import summary
neuron_total = 200
INPUT_SHAPE = (img_size[0], img_size[1], 3)
print(INPUT_SHAPE)
print(nb_classes)
# Create my model
class MyNet(nn.Module):
def __init__(self):
super().__init__()
self.l1 = nn.Linear(INPUT_SHAPE[0]*INPUT_SHAPE[1]*INPUT_SHAPE[2], neuron_total)# Input Layer to Intermediate modules
self.dropout1 = torch.nn.Dropout2d(p=0.5)
self.l2 = nn.Linear(neuron_total, 2) #Intermediate modules to Output Layer
def forward(self, x):#順伝播 Forward propagation
x = x.view(-1, INPUT_SHAPE[0]*INPUT_SHAPE[1]*INPUT_SHAPE[2] ) # x.view : Transform a tensor shape. If the first argument is "-1", automatically adjust to the second argument.
x = self.l1(x)
x = self.dropout1(x)
x = self.l2(x)
return x
if type_backbone == "ResNet50":
model = Resnet()
elif type_backbone == "Mobilenet":
model = Mobilenet()
elif type_backbone == "MyNet":
model = MyNet()
model = model.to(device)
# Show the model
summary(model, ( 3, img_size[1], img_size[0]))#channel, w, h
#プログラミングにおける両者の比較
###データセット準備比較
まず、PyTorchのためのデータセット準備でも述べた通り、データセットの準備をKerasではnumpy形式、PyTorchではDataLoaderやtensor形式を用いるという点が違います。
モデル構築比較
次にモデルの作り方ですが、KerasではDenseなどで層を繋げるとき勝手に形状を合わせてくれますが、PyTorchでは明示しなければならないです。
例えばFigure 2.の中間層をいくつか増やしたとき、Kerasでは
base_model = Sequential()
top_model = Sequential()
INPUT_SHAPE = (img_size[0], img_size[1], 3)
base_model.add(Dense(neuron_total, activation='relu',
input_shape=(INPUT_SHAPE[0]*INPUT_SHAPE[1]*INPUT_SHAPE[2],)))
base_model.add(Dense(neuron_total, activation='relu'))
base_model.add(Dense(neuron_total, activation='relu'))
base_model.add(Dropout(0.5))
top_model.add(Dense(nb_classes, activation='softmax',
input_shape=base_model.output_shape[1:]))
# Concatenate base_model(backbone) with top model
model = Model(input=base_model.input, output=top_model(base_model.output))
PyTorchでは
class MyNet2(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(INPUT_SHAPE[0]*INPUT_SHAPE[1]*INPUT_SHAPE[2], neuron_total)# Input Layer to Intermediate modules
self.fc2 = nn.Linear(neuron_total, int(neuron_total/2)) #Intermediate modules to Output Layer
self.dropout1 = torch.nn.Dropout2d(p=0.5)
self.fc3 = nn.Linear(int(neuron_total/2), 2)
def forward(self, x):#順伝播 Forward propagation
x = x.view(-1, INPUT_SHAPE[0]*INPUT_SHAPE[1]*INPUT_SHAPE[2] ) # x.view : Transform a tensor shape. If the first argument is "-1", automatically adjust to the second argument.
x = self.fc1(x)
x = self.fc2(x)
x = F.relu(x)
x = self.dropout1(x)
x = self.fc3(x)
return x
となり、PyTorchでは入力も出力もノード数を明示しています。
ドロップアウトの比較
あまり詳しく把握しきれていないので不安がありますが、KerasではDropout適用を学習時と評価時で切り替える必要がないはずです。PyTorchではmodel.eval()でDropoutを無効化するので、テスト画像を読み込む際は学習モードではないということを明示するため、
param = torch.load(weights_folder_path + "/" + best_weights_path)
model.load_state_dict(param, strict=False)
model.eval()
# ~ Inference
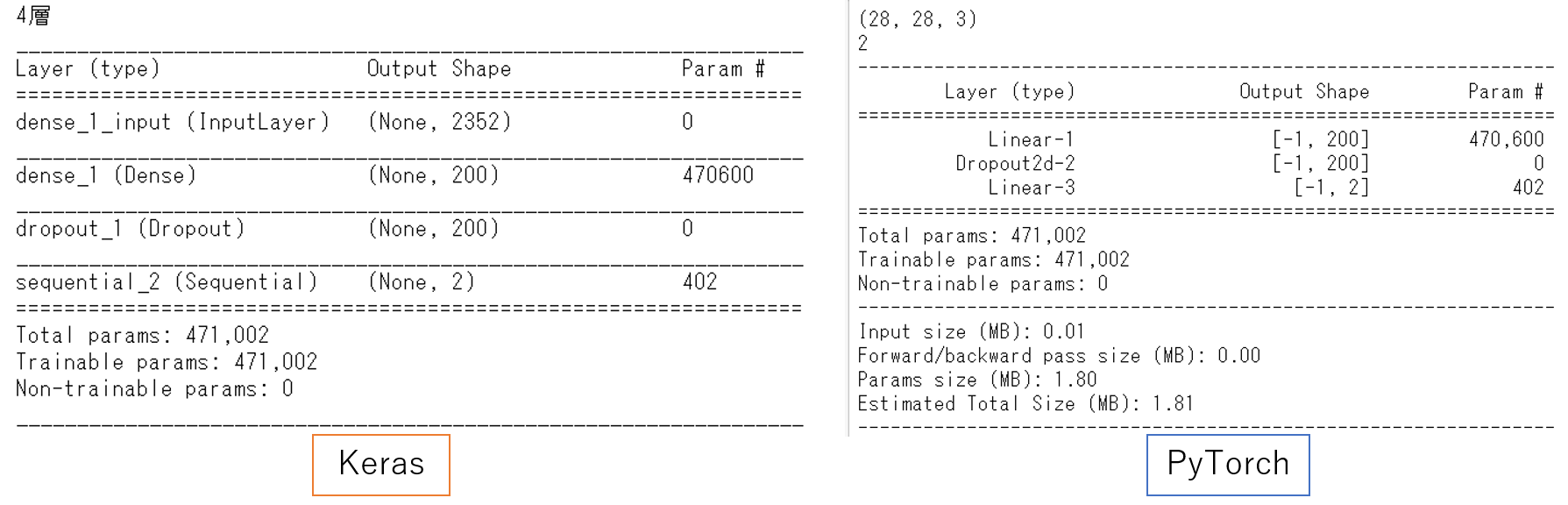
model_summaryの比較(パラメータ数)
パラメータ数はご覧の通り、完全一致しました。
 |
|---|
| Figure 5. model summaryによるKeras(左)とPyTorch(右)の比較 |
GPU利用比較
小ネタですが、KerasではGPUを使う際に記述の変更の必要はありませんが、PyTorchの場合は
#image, label = Variable(image), Variable(label)
image, label = Variable(image).cuda(), Variable(label).cuda()
のように書き換えする必要があります。
学習ループ比較
Kerasではmodel.fitのように記述することで勝手に学習評価のループをエポック数分繰り返します。PyTorchではforループなどで以下のようにエポック数分繰り返します。
def train(epoch):
#~略
def validation():
#~略
for epoch in range(1, total_epochs + 1):
train(epoch)
validation()
出力比較
また、PyTorchはデフォルトでlog_softmaxが使われているので、クラス確率の合計値は1にならないです(softmaxを指定するか、自分で換算する)。
#学習時の両者の比較
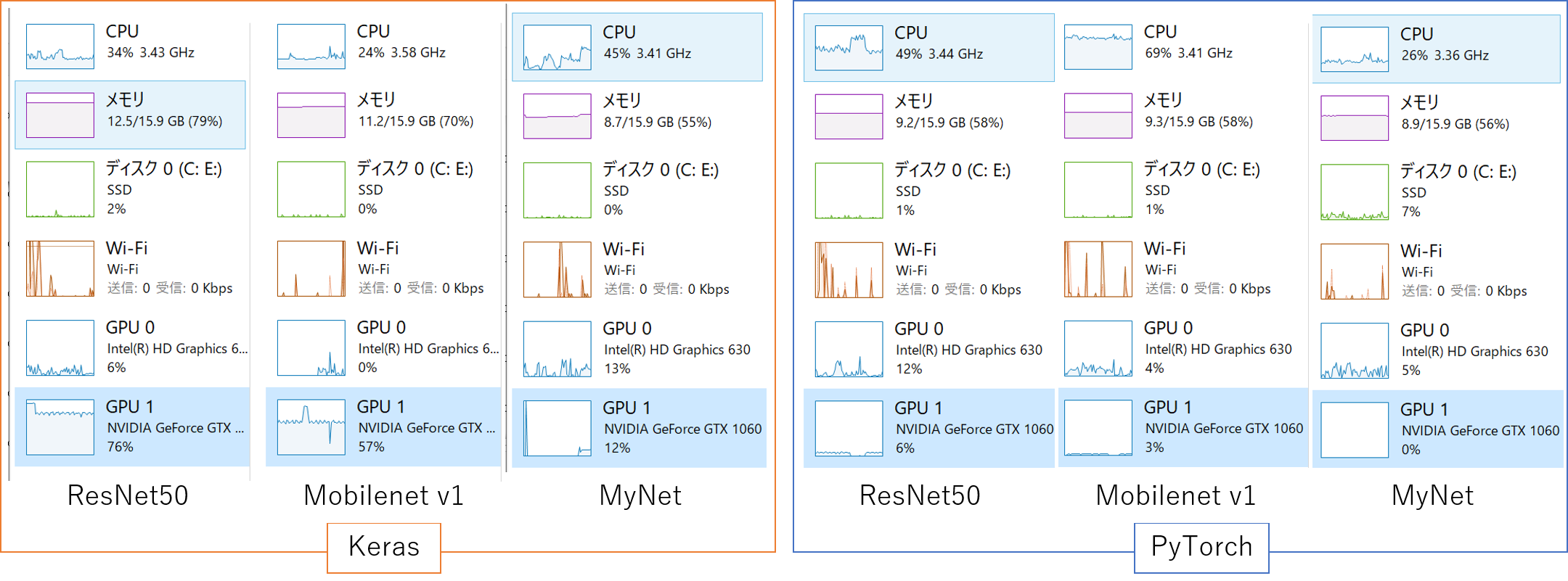
まず、タスクマネージャでPCの稼働状況を確認すると、以下のような違いがありました。
 |
|---|
| Figure 6. Kera(左)とPyTorch(右)それぞれの学習時(10epochあたり)のタスクマネージャパフォーマンス |
メモリ使用量はPyTorch側が小さかったです。Kerasではlistやnumpyの配列でデータセットを保持しているので(本プログラムでは)、どうしてもメモリを消費してしまいます。
GPU使用量もPyTorch側が小さかったです。
次に、KerasとPyTorchのそれぞれのネットワークの学習実行速度を比較します。ネットワークを用いて学習させたときの40エポックにかかる時間[s]を以下の表にまとめました。
| Keras | PyTorch | |
|---|---|---|
| ResNet | 3520 s | 3640 s |
| Mobilenet | 1600 s | 1760 s |
| MyNet | 40 s | 680 s |
Kerasはmodel.fitのverbose=1としているので勝手に出力してくれた値の秒のところを見ています。1ステップあたりの時間から計算すると正確ですが、めんどくさいのでだいたいの値とします。
上記の表からPyTorchの方が若干遅いです(1epochに3秒ほど遅い)。特にMyNetがかなり遅いです。ただしPyTorchの方が省エネ(?)です。PyTorchの方が速いつもりでしたが、コードが悪いような気がします。
ほぼ変わらないスピードで省エネならPyTorchの方が良い気がします。
結果の比較
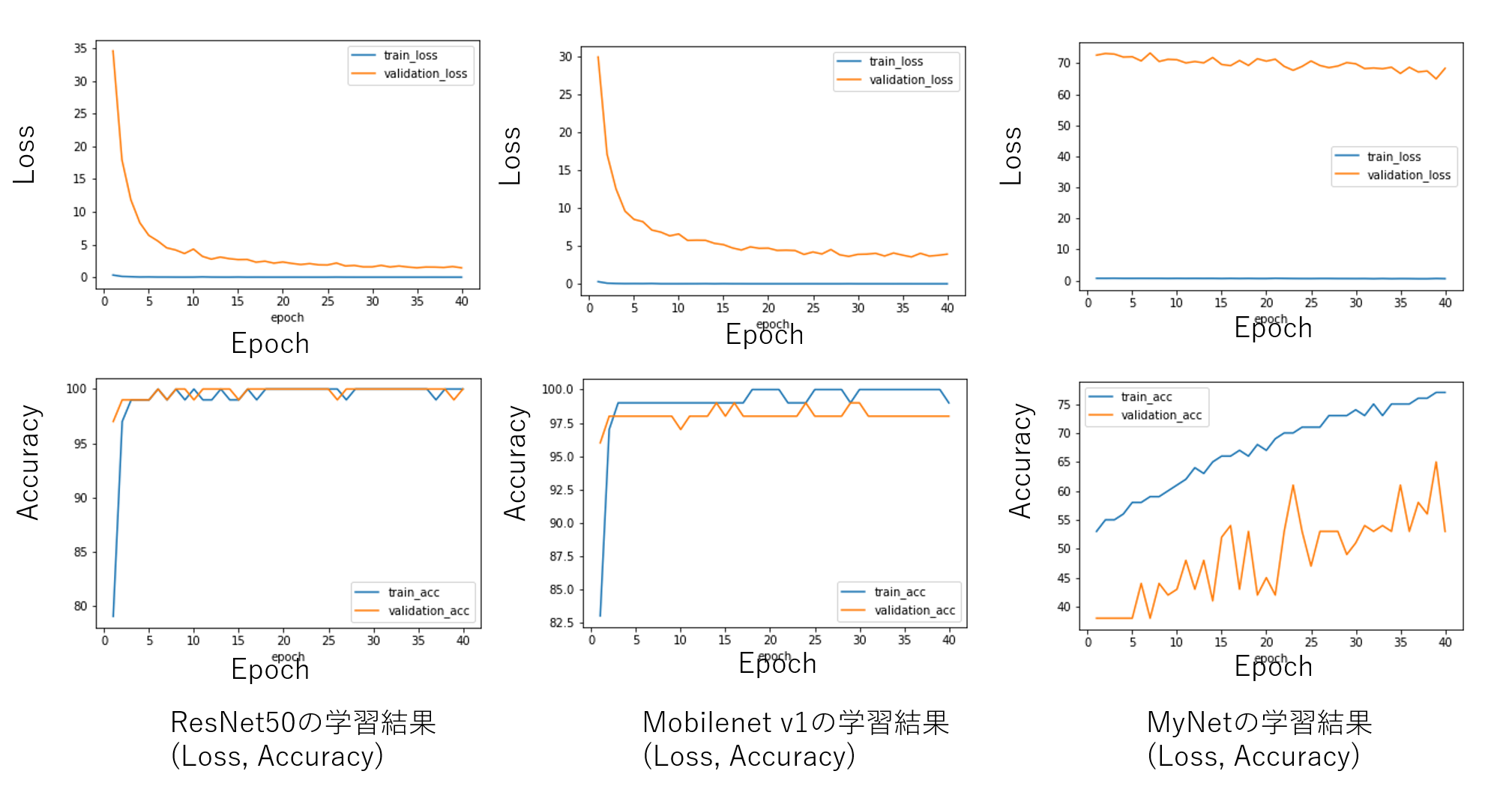
KerasでのResNet, Mobilenet, MyNetの推測結果
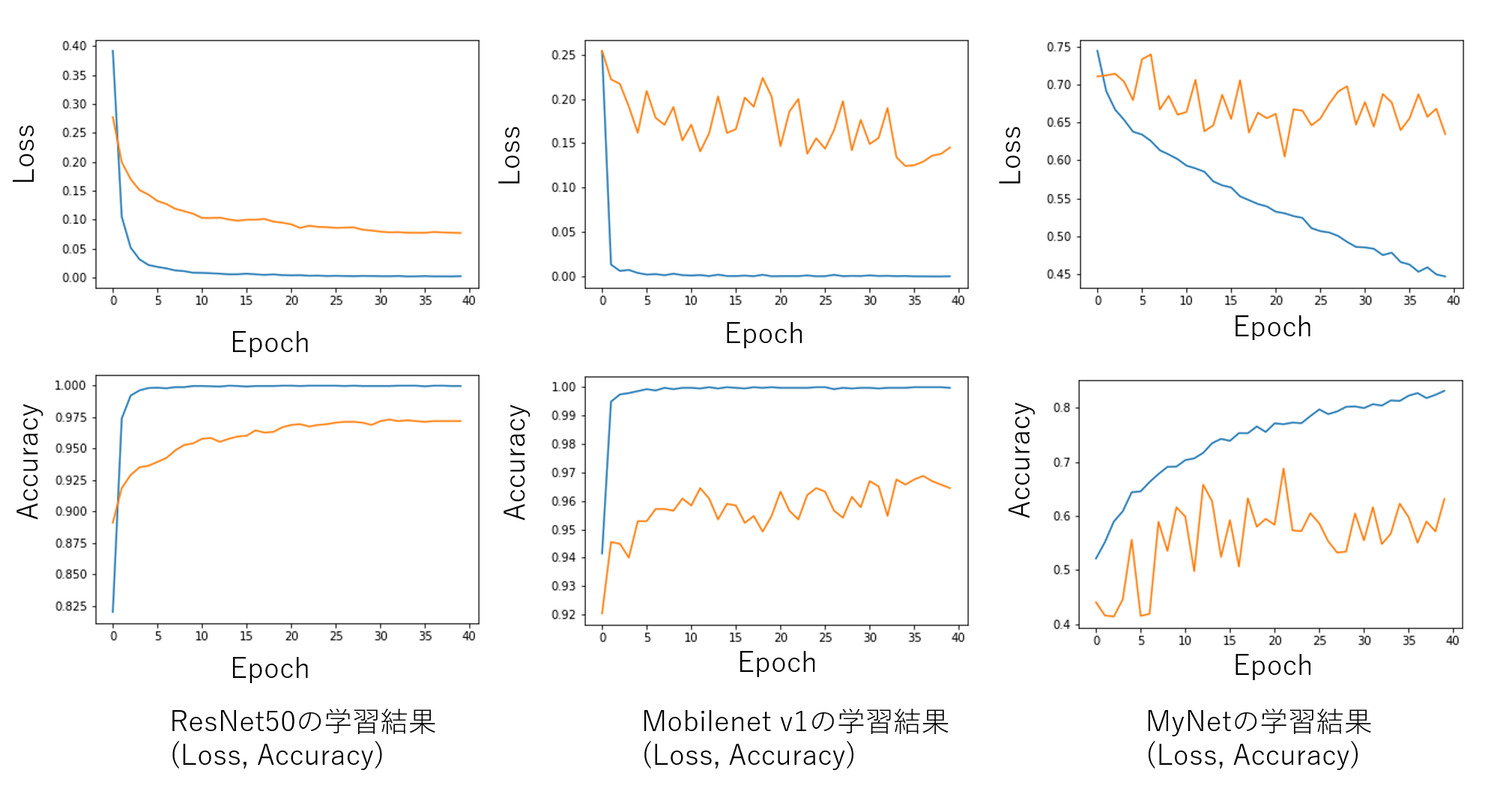
学習させた結果のLoss、Accuracy、テスト画像の推測結果を以下にまとめました。学習曲線はひどいですが、結果はまあ妥当なところではないでしょうか。
 |
|---|
| Figure 7. 学習でのエポックに対するLossとAccuracy(Keras) |
 |
|---|
| Figure 8-a. ResNet50による推測結果 (Keras) |
 |
|---|
| Figure 8-b. Mobilenet v1による推測結果 (Keras) |
 |
|---|
| Figure 8-c. MyNetによる推測結果 (Keras) |
PyTorchでのResNet, Mobilenet, MyNetの推測結果
学習させた結果のLoss、Accuracy、テスト画像の推測結果を以下にまとめました。Kerasと同様なので、折り畳みの中に結果を示します。
**PyTorchでの学習推測結果のまとめはここをクリック**
 |
|---|
| Figure 9. 学習でのエポックに対するLossとAccuracy(PyTorch) |
 |
|---|
| Figure 10-a. ResNet50による推測結果(PyTorch) |
 |
|---|
| Figure 10-b. Mobilenet v1による推測結果(PyTorch) |
 |
|---|
| Figure 10-c. MyNetによる推測結果(PyTorch) |
KerasとPyTorchの結果を踏まえて
両者とも傾向としては同じです(ほとんど同じ学習になるようにしたので)。
Keras、PyTorchとも、ResNet、Mobilenetでは分類ができていますが、MNISTレベルのMyNetでは分類できませんでした。ただし、Lossの下がり方を見るにResNetやMobilenetでも学習はうまくいっていないと思われます。今回はテスト画像も学習データに類似しているため、正解したのだと思います。フックレンチとスパナレンチほど類似した分類問題の場合、60枚程度ではデータ数が少ないようです。しかもデータそろえても分類できないような気もします・・・。
ちなみに、MyNetにおいて中間層のノードを500、学習回数を100epochで学習させた結果が以下です。
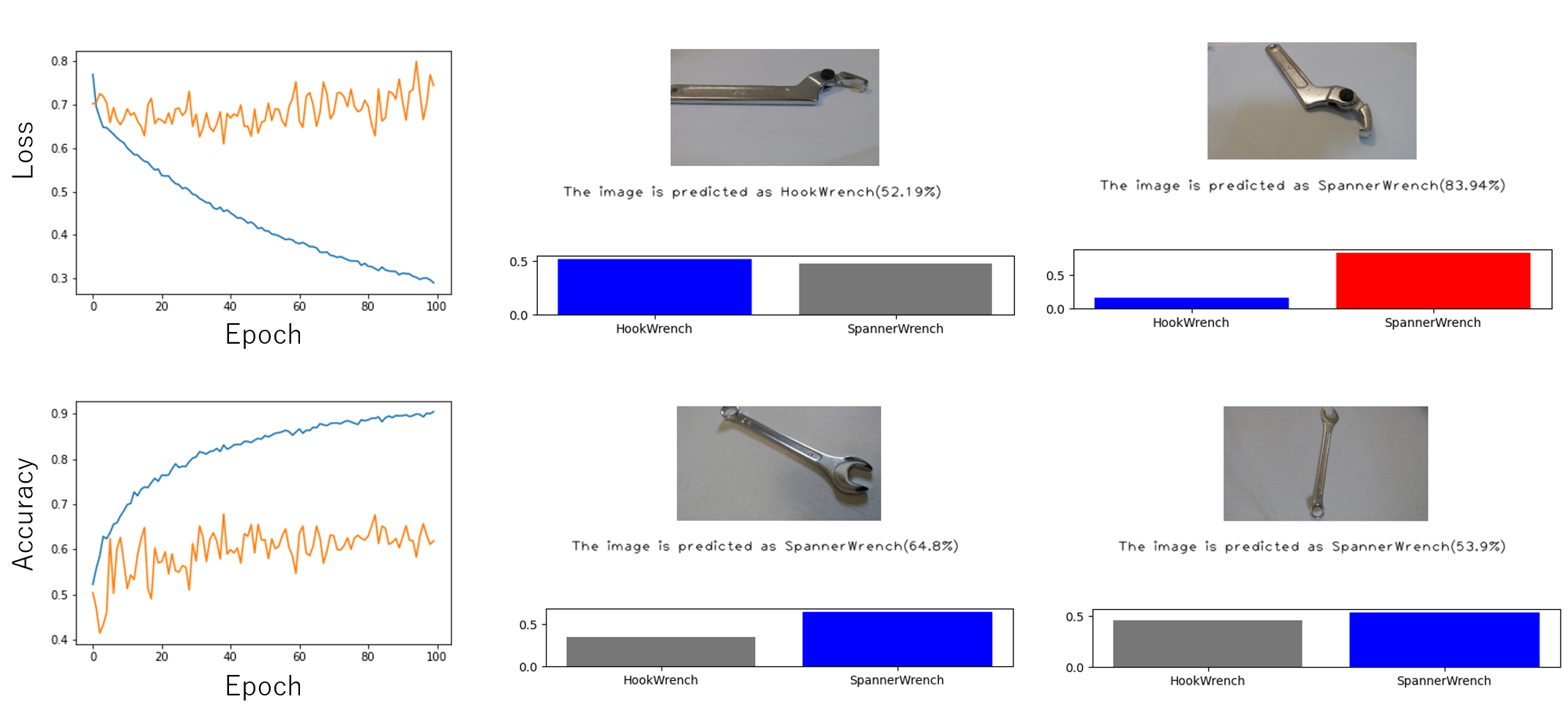 |
|---|
| Figure 11. MyNetで中間層のノードを500、学習回数を100epochで学習させた結果 |
Validationの損失値は下がらなくなります。おそらく、深層ではないただのニューラルネットでは分類できない問題なのでしょう。層を増やすか、CNN(畳み込みニューラルネットワーク)を用いるか、工夫が必要です。
まとめ
フックレンチとスパナレンチは単純なニューラルネットでは分類できない
実行環境 Environment
- Windows10
- CPU:Core i7-7700HQ
- Memory: 16GB
- Graphic board: GTX1060 6GB
- Strage: NVMe M.2 SSD 1TB
- CUDA 9.0.176
- cuDNN 7.0.5
※CUDA、cuDNNを導入していない方は環境構築が必要です。 - Keras==2.1.5
- tensorflow-gpu==1.11.0
- torch==1.1.0
- scikit-learn==0.19.1
- scipy==1.4.1
※GPU対応のPyTorch導入はこちらを参考にしてください
PyTorch==1.1.0をWindowsへ導入
参考
https://keras.io/ja/
https://pytorch.org/tutorials/beginner/blitz/tensor_tutorial.html
https://qiita.com/sheep96/items/0c2c8216d566f58882aa
https://rightcode.co.jp/blog/information-technology/pytorch-mnist-learning
https://water2litter.net/rum/post/pytorch_tutorial_classifier/
https://qiita.com/jyori112/items/aad5703c1537c0139edb
https://pystyle.info/pytorch-cnn-based-classification-model-with-fashion-mnist/
https://pytorch.org/docs/stable/torchvision/models.html
https://qiita.com/perrying/items/857df46bb6cdc3047bd8
https://qiita.com/sakaia/items/5e8375d82db197222669
https://discuss.pytorch.org/t/low-accuracy-when-loading-the-model-and-testing/44991/5