前書き
春からエンジニアとして働き始める予定の修士学生です.
本記事は「あれ,ニューラルネットワークの層の計算量計算できひん![]() 」ってなって,じゃあ実験しよってなった結果を共有するものです.
」ってなって,じゃあ実験しよってなった結果を共有するものです.
実験設定に根拠はなくて,これでいっか♪って感じでやってます.
ついでになんとなく計算できた気できたパラメータ数(空間計算量)も見てみます.
本記事には下記成分を含みます.
苦手な方はご自身に合った別の記事をお探しいただけると幸いです.
- 修士学生による稚拙な解説
- 浅学さからくる間違った知識
- \\\\ 唐突の自分語り //// (ポケモン出来てない)
- テンションとノリだけの文調
なお,本記事には下記の物は含まない予定です.
- 各層の詳細な解説(できない)
- Pythonコードの詳細な解説(できない)
- PyTorchの詳細な解説(できない)
基本層
本記事では,下記の層を基本層としています.
- 全結合層
- 畳み込み層
- 回帰層
- 複数ヘッド注意
実験
ここからは実験の設定や結果を見ていきます.
本実験に使用したコードや,出力はGitHubで公開してます.
本記事の実験結果はノートブックの内容を基に書いてるので,合わせてごらんいただくと僕のピンとこない文章を補完いただけるかもしれません.
比較方法
本記事では,Google Colaboratory上でPythonを動かします.
また,PyTorchパッケージでの各層の計算速度,パラメータ数を比較しています.
計算速度は,各設定で100回計測し平均値で比較します.
パラメータ数はtorchinfoパッケージを使用して取得してます.
設定,環境
本記事では,各層への入力$\boldsymbol x$を次にあらわす,ベクトル化した系列データを想定します.
\boldsymbol{x} \in \mathbb{R}^{B \times L \times F}
ここで,$B$はバッチサイズ,$L$は系列長,$F$はベクトル次元数です.
自然言語とか音信号の形式で,いわゆる一次元データです.
$B = [1], L = [16, 64, 256, 1024, 2048], F = [16, 64, 256, 1024, 2048]$ の組み合わせを試してます.
各層の設定はそれぞれの項目で触れます.
実験環境は次の通りです.
- OS:
Ubuntu 20.04.5 LTS - CPU:
Intel(R) Xeon(R) CPU @ 2.30GHz - GPU:
Tesla T4 16GB - Python:
3.9.16 - PyTorch;
1.13.1
全結合層
全結合層は次の数式で表される層です.
\boldsymbol y = \boldsymbol W \boldsymbol x + \boldsymbol b
ここで,出力$\boldsymbol y \in \mathbb R ^{B \times L \times Fout}$,重み$\boldsymbol W \in \mathbb R ^{Fout \times F}$, バイアス$\boldsymbol b \in \mathbb R ^{Fout}$です.
層に設定するハイパーパラメータは出力ベクトル次元数$Fout$です.
全結合層のパラメータは$\boldsymbol W$と$\boldsymbol b$なので,パラメータ数は$Fout \cdot F + Fout$になりそうです.
計算量はテンソル積を理解してれば計算できそうですが,理解してないのでできません ![]()
参考: Linear — PyTorch 1.13 documentation
設定
今回は$Fout = [16, 64, 256, 1024, 2048]$とします.
結果
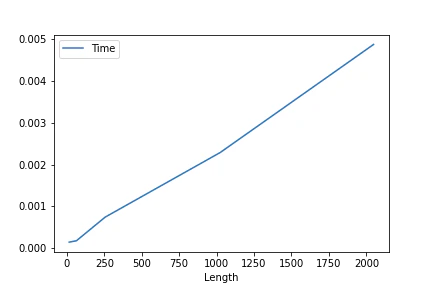
$L=[16, 64, 256, 1024, 2048], F=2048, Fout=2048$での平均処理時間のプロット
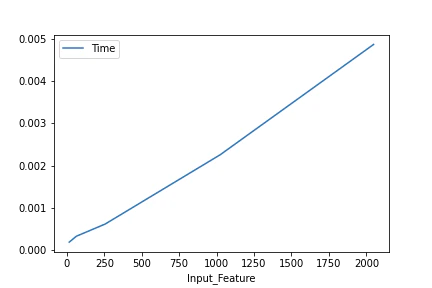
$L=2048, F=[16, 64, 256, 1024, 2048], Fout=2048$での平均処理時間のプロット
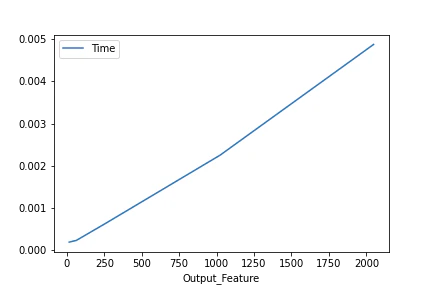
$L=2048, F=2048, Fout=[16, 64, 256, 1024, 2048]$での平均処理時間のプロット
上記の結果を見ると,時間計算量は$O(L \cdot F \cdot Fout)$っぽいです.
PyTorchの公式のドキュメントのどっかに,
「おかしいときはLinearの系列長を疑ってみ?」
みたいなことを書いてた気がしたので,ちょっと意外でした.
誤差逆伝播のメモリ消費とかの話やったんかな?
また,パラメータ数は系列長を変化させた時は変わらず,入/出力ベクトル次元数にのみ依存してました.
$F=2048, Fout=2048$のとき,$4196352=2048 \cdot 2048 + 2048$で,$Fout \cdot F + Fout$で間違ってなさそうです.
全結合層は,こっそりとっていた積和演算とパラメータ数が一致していたのが分かりやすくていいなって思いました.(小並感)
畳み込み層
本記事では,入力を一次元データとしているので,一次元畳み込み層を用います.
一次元畳み込み層は次の数式で表される層です.
\boldsymbol y_{(B_i, Fout_j)} = \sum_{F_k=1}^{F} \boldsymbol w_{(Fout_j, F_k)} \star \boldsymbol x_{(B_i, F_k)} + b_{Fout_j}
ここで,$\boldsymbol y \in \mathbb R ^{B \times L \times Fout}$,$\boldsymbol w \in \mathbb R ^{Fout \times F \times K}$, $\boldsymbol b \in \mathbb R^{Fout}$であり,$B_i = [1, \cdots,B]$, $Fout_j = [1, \cdots, Fout]$で,$a_n$や$a_{(n, m)}$は添え字に沿ってテンソルを抜き出してます.
$\star$は相互相関演算子です.
$K$はカーネルサイズで,ストライド$S$と$Fout$が層に設定するハイパーパラメータです.
畳み込み層のパラメータは$\boldsymbol w$と$\boldsymbol b$なので,パラメータ数は$Fout \cdot F \cdot K + Fout$だと思います.
計算量はよくわかりません ![]()
参考: Conv1d — PyTorch 1.13 documentation
設定
今回は $K = [1, 4, 8, 16, 64], S = [1, 4, 8, 16, 64], Fout = [16, 64, 256, 1024, 2048]$とします.
結果
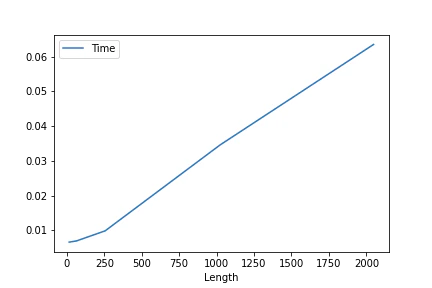
$L=[16, 64, 256, 1024, 2048], F=2048, Fout=2048, K=16, S=1$での平均処理時間のプロット
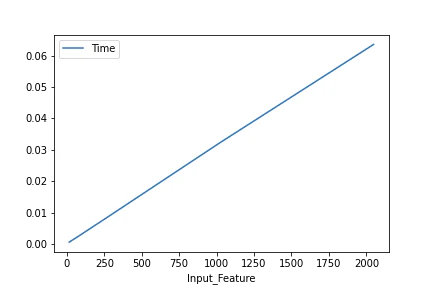
$L=2048, F=[16, 64, 256, 1024, 2048], Fout=2048, K=16, S=1$での平均処理時間のプロット
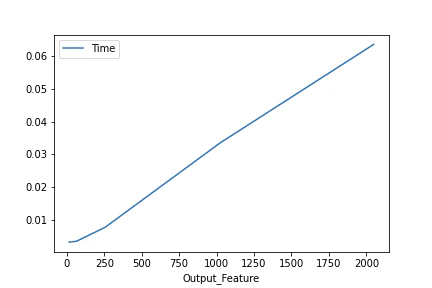
$L=2048, F=2048, Fout=[16, 64, 256, 1024, 2048], K=64, S=1$での平均処理時間のプロット
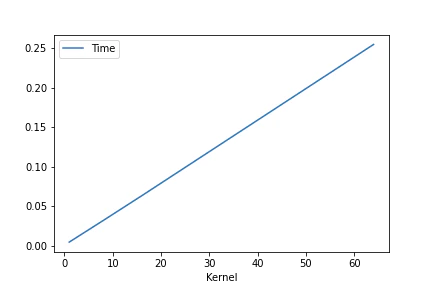
$L=2048, F=2048, Fout=2048, K=[1, 4, 8, 16, 64], S=1$での平均処理時間のプロット
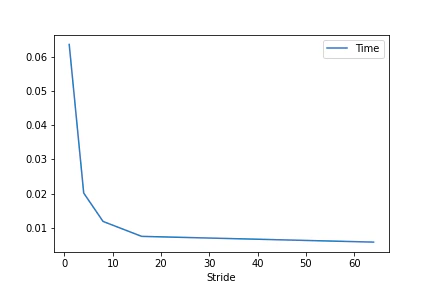
$L=2048, F=2048, Fout=2048, K=64, S=[1, 4, 8, 16, 64]$での平均処理時間のプロット
上記の結果を見ると,時間計算量は$O(L \cdot F \cdot Fout \cdot K / (S \cdot \text{log}S))$とかっぽいです(勘).
ストライドが小さめなうちは,大きくできるなら大きくしたい感じでしょうか.
その分入力の情報を落としているはずなので,ストライド大きくできたらラッキーくらいのスタンスでいようと思います.
パラメータ数は,入/出力ベクトル次元数とカーネルサイズを変化させたときのみ,変化してました.
$F=2048, Fout=2048, K=64$のとき,$268437504 = 2048 \cdot 2048 \cdot 64 + 2048$で,$Fout \cdot F \cdot K + Fout$のようです.
$K = L$のとき,パラメータ数と積和演算の値が一致していたので,
さては,$K = L$で全結合層と畳み込み層は同じ処理をしてるな?
って名探偵気分に浸ってました![]() <なぞはとけた!
<なぞはとけた!
回帰層
本記事では回帰層にLSTMを用います.
LSTMは次の数式で表されるそうです.
\begin{align}
i_t & = \sigma(W_{ii}x_t + b_{ii} + W_{hi}h_{t-1} + b_{hi}) \\
f_t & = \sigma(W_{if}x_t + b_{if} + W_{hf}h_{t-1} + b_{hf}) \\
g_t & = tanh(W_{ig}x_t + b_{ig} + W_{hg}h_{t-1} + b_{hg}) \\
o_t & = \sigma(W_{io}x_t + b_{io} + W_{ho}h_{t-1} + b_{ho}) \\
c_t & = f_t \odot c_{t-1} + i_t \odot g_t \\
h_t & = o_t \odot tanh(c_t)
\end{align}
(゜ロ゜)
参考: LSTM — PyTorch 1.13 documentation
設定
今回は$Fhid = [16, 64, 256, 1024], Nl = [2, 4], bidirectional = [True, False]$とします.
結果
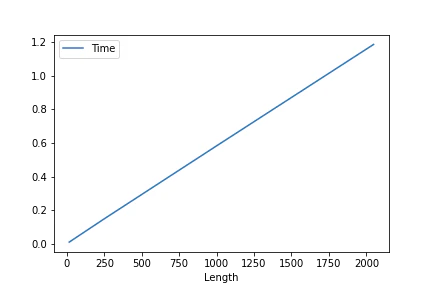
$L=[16, 64, 256, 1024, 2048], F=2048, Fhid=1024, Nl=4, bidirectional=True$での平均処理時間のプロット
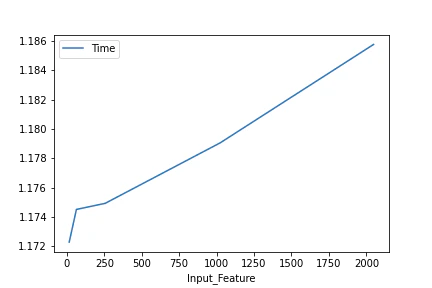
$L=2048, F=[16, 64, 256, 1024, 2048], Fhid=1024, Nl=4, bidirectional=True$での平均処理時間のプロット
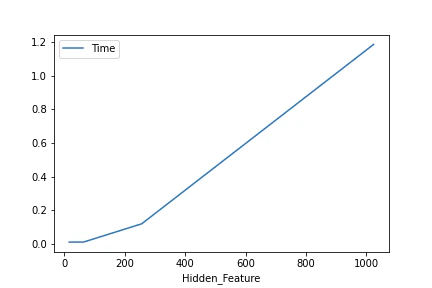
$L=2048, F=2048, Fhid=[16, 64, 256, 1024], Nl=4, bidirectional=True$での平均処理時間のプロット
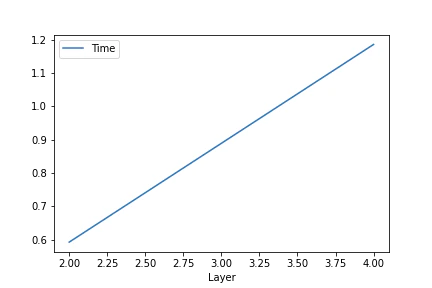
$L=2048, F=2048, Fhid=1024, Nl=[2, 4], bidirectional=True$での平均処理時間のプロット
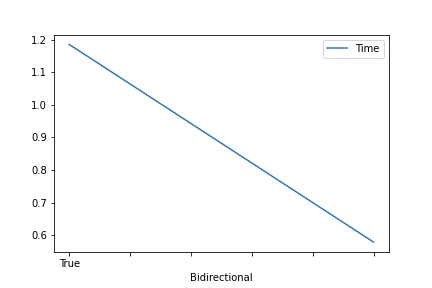
$L=2048, F=2048, Fhid=1024, Nl=4, bidirectional=False$での平均処理時間のプロット
入力のベクトル次元数が処理時間にあまり影響を及ぼしていなさそうですね.
パラメータ数も出力ベクトル次元数にほとんど依存してました.
つまり,僕にはよくわかりません ![]()
![]()
![]()
![]()
![]()
僕に分かることは,LSTMはGPUを使ってもクソ遅いってことぐらいです.
複数ヘッド注意
Multi-Head Attentionと呼ばれるやつです.
今回は複数ヘッド自己注意を用い,次の数式で表されます.
\boldsymbol y = \boldsymbol W^O \text{Concat}(head_1, \cdots, head_h) + \boldsymbol b^O \\
where \quad head_i = \text{Attention}(\boldsymbol W_i^Q \boldsymbol x + \boldsymbol b^Q_i, \boldsymbol W_i^K \boldsymbol x + \boldsymbol b^K_i, \boldsymbol W_i^V \boldsymbol x + \boldsymbol b^V_i)
ここで,$\boldsymbol y \in \mathbb R ^{B \times L \times F}$, $\boldsymbol W^O \in \mathbb R ^{F \times F}$, $\boldsymbol W^{(Q, K, V)} \in \mathbb R ^{h \times (F / h) \times F}$,$\boldsymbol W^{(Q, K, V)}_i$はi番目のヘッド軸の$\boldsymbol W^{(Q, K, V)}$, $\boldsymbol b ^O \in \mathbb R ^{F}$, $\boldsymbol b^{(Q, K, V)} \in \mathbb R ^{h \times F/h}$であり,$h$はヘッド数です.
ハイパーパラメータは$h$です.
複数ヘッド注意のパラメータは$\boldsymbol W^O, \boldsymbol W^{(Q, K, V)}, \boldsymbol b^O, \boldsymbol b^{(Q, K, V)}$なので,$F \cdot F + 3 \cdot F \cdot F + F + 3 \cdot F$つまり,$4F(F + 1)$です(バイアスがPyTorchで同実装されてるか自信ないです).
参考: MultiheadAttention — PyTorch 1.13 documentation
設定
今回は$h = [1, 2, 4, 8, 16]$とします.
結果
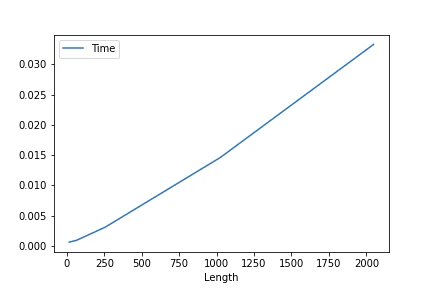
$L=[16, 64, 256, 1024, 2048], F=2048, h=16$での平均処理時間のプロット
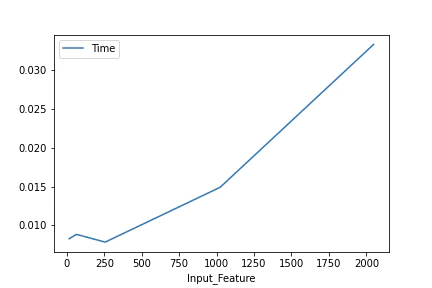
$L=2048, F=[16, 64, 256, 1024, 2048], h=16$での平均処理時間のプロット
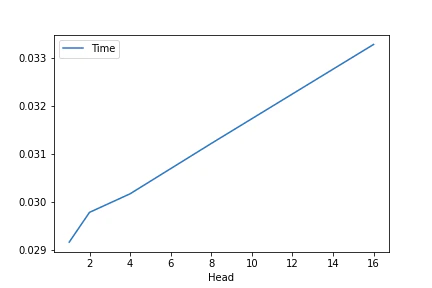
$L=2048, F=2048, h=[1, 2, 4, 8, 16]$での平均処理時間のプロット
上記によると,$O(L \cdot F)$っぽいです.
ヘッド数には大きく依存してなさげで,パラメータ数も変化ありませんでした.
ヘッド数によるモデルの性能への影響は実験的にしか示されていなさそうだと思ってて,計算の負担が大きいようならシングルヘッドでもいいかもねって思っていました.
結果的にはマルチヘッドによる計算の負担は少なく,性能に好影響を与える可能性があるならお得やんってなりました.
パラメータ数は入力ベクトル次元数を変化させて時のみ変わっていて,$F=2048$のとき,$16785408 = 4 \cdot 2048 \cdot 2049$で,$4 \cdot F (F + 1)$のようです.
torchinfoで積和演算を取っていたのですが,複数ヘッド注意では0になっていました.
途中まで実装を追ったのですが,まあいいかっておもってやめました.
積和演算を調べるって言ってないのはこのためです.
まとめ
本記事では,ニューラルネットワークの基本層を勝手に決めて,それらの計算速度やパラメータ数を雑に調べました.
文章自体は全力で書いてこの程度でした.
正直もうちょっと読みやすい文章を書けると思っていたので,不甲斐ナイナイです.
反省点は
- 実験設定が固まってからコーディングする
- コードをきれいに書く
- colab, GitHub, Qiitaのgoogleアカウントを統一する
あたりでしょうか.
実験設定を固める前にコーディングを始めたせいで,総当たりで各パラメータで時間計測することになってしまいました.
この総当たりを解消すれば時間削減ができて,5点程度でプロットするような事態になってなかったかもしれません.
あと,各層で記事分けたらこんなに長くならんかったやろって思います.
無駄に長い記事をここまで読んでいただき,ありがとうございます > ![]()
※本記事はChatGPTによる文章ではございません.
思ったより,自分語りとテンションとノリが少なくてロボットが書いたみたいな文章になった気がします.
それもまたよし![]()