はじめに
前回のESP-ADFを使って、計算した音声信号を外部I2S-DACへ出力する方法(1)からの続きです。今回はプログラムの中身を説明します。
プログラム本体はESPADF_geneSig/main/geneSig_main.cです。
プログラムの説明
全体の流れ
- audio pipelineを作成する
- 2つのaudio elementを作成する(信号計算する要素と、I2S出力をする要素の2つ)
- 2つのaudio elementをaudio pipelineに登録し、接続する。
- event listenerを準備する
- audio pipelineを起動する
- 無限ループ(audio elementから停止・エラー等のメッセージを受け取ったら、無限ループを抜ける)
- ループを抜けたら、pipelineを停止し、各変数のメモリを解放する。
audio pipelineとaudio elementについて
プログラムの説明をする前に、まずESP-ADFにおける重要な概念であるaudio pipelineとaudio elementについて簡単に紹介しておきます。
audio pipelineとは、パイプラインという名前の通り、一つの管、線のようなものです。audio elementはこのパイプラインにの中にある要素で、audio pipelineは複数のaudio elementを接続する形で構成されます。公式説明の図を貼っておきます。

この図の例では、MP3ファイルを開く機能(Read MP3 file)、MP3ファイルから音声データを取り出す機能(MP3 decoder)、音声データをI2S出力する機能(I2S stream)の3つのaudio elementを接続して、1つのaudio pipelineを構成しています(一番右のCodec chipというのはプログラム上では存在しないものなので、今は無視してください)。
今回のプログラムでは、audio elementを2つ使用します。1つは信号波形を生成するelementです。もう1つは、上の図と同じようにI2S出力をするelement(I2S stream)です。これを、左から順に接続し、1つめのelementが生成した信号をI2S出力するelementに受け渡し、音声を再生します。
さて、ここからはプログラムを見ながら説明します。
pipelineの作成
まずはapp_main()の冒頭から、37~40行目のaudio pipelineの作成です。
//Create pipeline
audio_pipeline_cfg_t pipeline_cfg = DEFAULT_AUDIO_PIPELINE_CONFIG();
pipeline = audio_pipeline_init(&pipeline_cfg);
mem_assert(pipeline);
audio_pipeline_cfg_tというのは、audio_pipeline_cfgという構造体のポインタ型(typedefされたもの)です。ESP-ADFではこういった専用の型がたくさん出てきますが、中身を完全に把握する必要はありませんので、読み飛ばしてしまいましょう。
この3行の意味は要するに、
- 標準設定(config)を準備して、
- audio pipelineを初期化(init)して、
- 初期化の結果を確認(mem_assert)する
というだけです。これ以上の理解は今回は不要です。
audio elementの作成
次に、42~45行目は、I2S出力用のaudio elementを作成しています。
//Create audio-element for I2S output
i2s_stream_cfg_t i2s_cfg_write = I2S_STREAM_CFG_DEFAULT();
i2s_cfg_write.type = AUDIO_STREAM_WRITER;
i2s_stream_writer = i2s_stream_init(&i2s_cfg_write);
これも、先ほどのaudio pipelineの作成と似ています。この3行の意味は、
- 標準設定(config)を準備して、
- 設定の一項目(i2s_cfg_write.type)を微調整して、
- audio elementを初期化(init)する
というだけです。今回はなぜか初期化の結果の確認はしていませんが、気にする必要はありません。
ところで、このaudio elementは、いろんな種類のものがあります。上のi2s_streamというのはその1つで、これはi2sの入出力をする専用のaudio elementです(入力、つまり録音もできるelementです。今回は出力するため、i2s_cfg_write.type = AUDIO_STREAM_WRITER;としています)。この他にも、各種オーディオファイルの読み取り機能(mp3_decoder, wav_decoder等)やファイルの読み取り機能(fatfs_stream_reader, http_stream_reader等)のような専用elementがあります。
しかし、自分で信号を生成して次のelementに受け渡すような専用elementは残念ながらありません。そこで、汎用のaudio elementを使って、自分で実装する必要があります。それが48~76行目です。
//---- Create audio-element for generate signal(sine wave) ----
//prepare config structure
audio_element_cfg_t fg_cfg = DEFAULT_AUDIO_ELEMENT_CONFIG();
fg_cfg.open = _geneSig_open;
fg_cfg.close = _geneSig_close;
fg_cfg.process = _geneSig_process;
fg_cfg.destroy = _geneSig_destroy;
fg_cfg.read = _geneSig_read;
fg_cfg.write = NULL; //if NULL, execute "el->write_type = IO_TYPE_RB;"
fg_cfg.task_stack = (3072+512);
fg_cfg.task_prio = 5;
fg_cfg.task_core = 0;
fg_cfg.out_rb_size = (8*1024);
fg_cfg.multi_out_rb_num = 0;
fg_cfg.tag = "geneSig";
fg_cfg.buffer_len = 2048;
//create audio-element
generator = audio_element_init(&fg_cfg);
//prepare audio_element_info and set to audio-element
audio_element_info_t info = {0};
info.sample_rates = 44100;
info.channels = 2;
info.bits = 16;
audio_element_setinfo(generator, &info);
// --------
これも、簡単に言えば、以下の処理をしているだけです。
- fg_cfgという設定を準備して、
- audio_element_initでelementを初期化して、
- 少し設定を補足する(audio_element_setinfo)
初期化のあとに補足設定をしているのは、恐らくこの順序でなければ設定ができないからで、特に大きな意味はありません(i2s_stream_init関数の中身と同じ順序になっています)。
ここで、1つ重要な点があります。それは、fg_cfgの要素open, close, process, destroy, read, writeの部分です。これらは関数ポインタ型の変数で、それぞれ名前の通りの処理をする関数(コールバック関数)を指定する変数になっています。write以外はすべて_geneSig_***という関数名を代入していますが、これらは135行目以降の関数を指しています。今回は、これらのうち、read()(_geneSig_read())という関数で信号を生成して、process()(_geneSig_process())という関数で信号を次のaudio element(つまりi2s stream)へ渡します。この部分は後ほど詳しく説明します。
pipelineの実行
次に、78~91行目では、pipelineの準備・動作開始をしています。
//Register audio-elements to pipeline
audio_pipeline_register(pipeline, generator, "geneSig");
audio_pipeline_register(pipeline, i2s_stream_writer, "i2s_write");
//Link audio-elements (generator-->i2s_stream_writer)
audio_pipeline_link(pipeline, (const char *[]) {"geneSig", "i2s_write"}, 2);
//Set up event listener
audio_event_iface_cfg_t evt_cfg = AUDIO_EVENT_IFACE_DEFAULT_CFG();
audio_event_iface_handle_t evt = audio_event_iface_init(&evt_cfg);
audio_pipeline_set_listener(pipeline, evt);
//Run pipeline
audio_pipeline_run(pipeline);
これは、つまり以下の処理をしています。
- pipelineにelementを登録し、
- audio pipelineの中でelement同士を接続し、
- event listenerというのを設定して、
- audio pipelineを起動する
これらは、audio pipelineを使う時の定型文です。最後のaudio_pipeline_run()を実行すると、各audio elementが1つのタスクを生成します。ここでいうタスクとは、FreeRTOSのタスクのことで、具体的にはxTaskCreatePinnedToCore()の実行により生成します。FreeRTOSの説明については割愛しますが、ESP-IDFはFreeRTOSベースで設計されており、マルチタスクやメモリ管理など、一般的なFreeRTOSと同等の機能を有しているようです。ともあれ、タスクが生成されて、各audio elementが動作開始(read()やwrite()等の関数を実行)すると、element間で信号を受け渡しが始まります。
event処理
93~114行目は、無限ループになっています。
//inf-loop (can listen event messages from audio-elements)
while (1) {
audio_event_iface_msg_t msg;
esp_err_t ret = audio_event_iface_listen(evt, &msg, portMAX_DELAY);
if (ret != ESP_OK) { ... } //省略
if (msg.cmd == AEL_MSG_CMD_ERROR) { ... } //省略
if ( ... ) { ... } //省略
}
ここでは、各audio elementからのaudio eventと呼ばれるフィードバックを受け取って、それに応じて(if文で判定して)処理をしています。今回の場合、ずっと正弦波を出力し続けるため、回路が正常に動作していればこのループを抜けることはありません。audio elementとaudio pipelineの動作説明にはとりあえず関係が無いため、今回はこの部分の説明は割愛します。
後処理(メモリ解放)
118行目以降は、pipelineの停止やメモリの解放をしています。
//Terminate pipeline
audio_pipeline_terminate(pipeline);
//Unregister audio-elements
audio_pipeline_unregister(pipeline, generator);
audio_pipeline_unregister(pipeline, i2s_stream_writer);
//Remove listener
audio_pipeline_remove_listener(pipeline);
audio_event_iface_destroy(evt);
// Release all resources (audio-elements, pipeline)
audio_pipeline_deinit(pipeline);
audio_element_deinit(generator);
audio_element_deinit(i2s_stream_writer);
先ほど説明した通り、上の無限ループを抜けることは通常無いため、これらの処理が実行されることは通常ありません。よって、これらについても説明を割愛します。
audio elementのタスクについて(_geneSig_process関数)
app_main()の次はコールバック関数を説明します。まず_geneSig_process()について説明します。
static int _geneSig_process(audio_element_handle_t self, char *in_buffer, int in_len){
int r_size = 0;
int w_size = 0;
r_size = audio_element_input(self, in_buffer, in_len);
if (r_size == AEL_IO_TIMEOUT) { ... }
if ((r_size > 0)) {
w_size = audio_element_output(self, in_buffer, r_size);
}else{ ... }
return w_size;
}
この関数は、audio_pipeline_run()が実行されたときに生成されるタスクの中で繰り返し実行されます。主な処理は、audio_element_input()とaudio_element_ouotput()の実行です。そして実は、audio_element_input()はread()を、audio_element_ouotput()はwrite()を実行するのです。分かりにくいと思うので、図を用意しました。
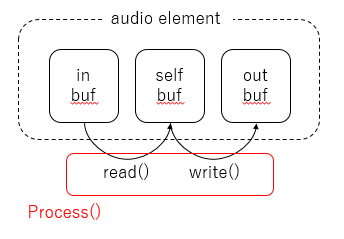
audio elementには3つのバッファがあるのですが、audio_element_input()(またはその中で呼ばれるread()というコールバック関数)はinバッファからselfバッファへ、audio_element_output()(またはその中で呼ばれるwrite()というコールバック関数)はselfバッファからoutバッファへ、それぞれデータを渡す処理をしています。そして、これの2つの関数は、process()というコールバック関数の中で実行されており、このprocess()は繰り返し実行されるようになっています。
なお、実は今回作成したgeneratorというelementは、上図のin-bufferを持っていません。というのは、audio pipelineの先頭のaudio elementはin-bufferを持たず、また末尾のaudio elementはout-bufferを持たないためです。そのため、先頭に位置するgeneratorはread()を実行する際、in-bufferから値を読み取るのではなく、自ら信号を生成してself-bufferへ渡すことになります。それが、次に説明する_geneSig_read()の動作です。
信号の生成(_geneSig_read関数)
さて最後に、信号の生成をしているコールバック関数_geneSig_read()の説明をします。
static int _geneSig_read(audio_element_handle_t self, char *buffer, int len, TickType_t ticks_to_wait, void *context){
//generate signals and put into (char *)buffer.
float f_signal = 0.0, f_time;
int i_fs, i_sample_per_wave;
uint16_t i_signal = 0;
uint16_t *sample;
size_t bytes_read = 0;
//get sample-rates from audio-element-info.
audio_element_info_t info;
audio_element_getinfo(self, &info);
i_fs = info.sample_rates;
i_sample_per_wave = i_fs / WAVE_FREQ_HZ;
//alloc signal sample buffer.
sample = calloc(len/2, sizeof(uint16_t));
for(int i=0;i<len/2;i+=2){
//Increment global time-step. (Unit:step, 1step = 1/44100 seconds)
i_time_global++;
//calc real-time. (Unit:seconds)
f_time = (float)(i_time_global) / (float)(i_sample_per_wave);
//calc signal amplitude
f_signal = 1 + sin(2 * PI * f_time); //float:[0, 2]
i_signal = (uint16_t)(MAXVOL * f_signal); //uint16_t:[0, 65535]
//copy to sample-buffer(on memory).
//Left channel(2bytes) and Right channel(2bytes)
sample[i] = i_signal;
sample[i+1] = i_signal;
//For return value
bytes_read += 4;
//For prevent from overflow global-time steps, decrease time.
if(i_time_global > i_sample_per_wave) i_time_global -= i_sample_per_wave;
}
//memory copy to buffer from sample
memcpy(buffer, sample, len);
//release sample buffer
free(sample);
return bytes_read;
}
この関数は、引数の(char *)bufferに、lenで指定された長さの音声データを渡す関数です。この(char *)bufferが、上の説明のself-bufferです。この関数では、以下の処理をしています。
-
(char *)bufferに入れる音声データを保管するためのメモリ領域を確保(calloc) - 1ステップずつ、音声波形を計算し、確保したメモリへ代入(forループ)
-
(char *)bufferに音声波形をコピーし、確保したメモリを解放(memcpy, free)
以下、それぞれ詳しく説明します。
音声データを保管するためのメモリ領域を確保
今回、音声データは、サンプリング周波数44.1kHzの16bitとしています。つまり音声信号はunsigned int 16bitで表現され、1サンプルにつき2byte(16bit)必要になります。*bufferへ入れるデータ量は引数のlenで指定されていますが、*bufferはchar型なので、(len)byteを*bufferへ入れる必要があります。たとえばlenが10なら10byteです。下のプログラムのsizeof(uint16_t)は2byteなので、サイズはlen/2としています。つまりlenが10なら、2byteをlen/2つまり5個分、となります。
//alloc signal sample buffer.
sample = calloc(len/2, sizeof(uint16_t));
1ステップずつ、音声波形を計算し、確保したメモリへ代入
i_time_globalはグローバル変数です。forループの中身が1回実行されると1増えます。これは時間(ステップ数)を表しており、この変数が1ステップ増える=1/44100秒進む、という意味です。f_timeは秒単位の実時間で、i_time_globalをサンプリング周波数i_fsで割って、正弦波の周波数WAVE_FREQ_HZを掛けた値になっています。
f_signalとi_signalは正弦波です。uint16_t型の範囲内になるよう調整をしています。正弦波の計算ロジックについては割愛します。あとは、sampleにi_signalを代入するだけです。今回は2ch分のデータが必要になるため、sample[i]とsample[i+1]の両方に同じ値を代入しています。
(char *)bufferに音声波形をコピーし、確保したメモリを解放
forで計算が終わったら、*bufferの示すメモリ番地へsampleの値をコピーします。そしてsampleのメモリを解放します。
バッファについて補足
プログラムの説明は以上ですが、ADFのaudio element及びaudio pipelineにおけるバッファについて、補足説明をします。
上の方でaudio elementには3つのバッファがあると書きましたが、実際には下図のような構造になっています。
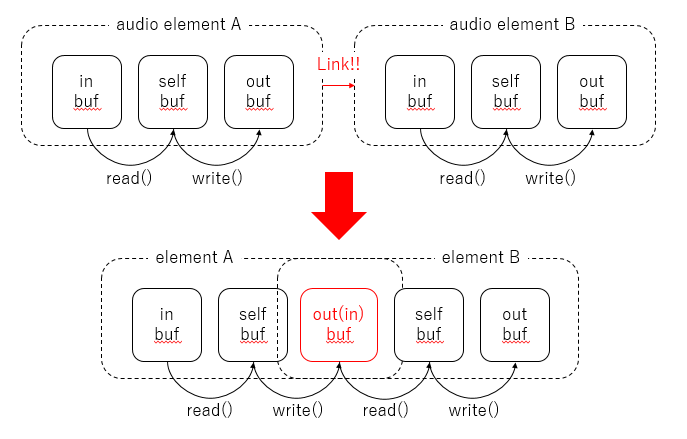
in-bufferとout-bufferは、audio pipelineにelementを登録し、element同士を接続した時点で生成されます。そして、手前のelementのout-bufferと次のelementのin-bufferは、実は同じもの(同じメモリアドレス)を指しています。このin-bufferとout-bufferはリングバッファ(メモリ操作不要のFILO)です(ringbuf.cに実装されています)。
上の方で、audio elementの初期化の所で、各コールバック関数を指定しましたが、writeにはNULLを指定しました。
fg_cfg.write = NULL; //if NULL, execute "el->write_type = IO_TYPE_RB;"
これは、つまりself-bufferの値をそのままout-buffer(リングバッファ)へ書き込む、という意味です。他の特別なことは何もしないので、自分で作成した関数を指定する必要がないため、関数ポインタ変数のwriteにはNULLを代入します。もしもwriteもreadもNULLにした場合、in-bufferの値をself-bufferを経由してout-bufferへ流す(パススルー)動作になります。 逆に、readまたはwriteに自作した関数を指定すれば、その自作関数の中で信号の加工(フィルタ・アンプ)や観測(FFTなど)といった処理を実装できます。
さいごに
長くなりましたが、いかがでしょうか。ESP-ADFについては日本語の情報が全く無さそうだったため、ESP32を使って音声信号処理をしたいと考えている方々への一助になればと思い、投稿しました。私は、もう随分昔の話ですが、AppleのCoreAudioやVSTプラグイン開発ライブラリを使ってリアルタイム音声処理プログラムを少し書いていたことがあるため、コールバック関数や信号の受け渡しの概念・お作法には多少慣れています。そのため、不慣れな方にとっては分かりにくい説明になっているかもしれません。疑問がありましたら、コメント等頂ければ補足したいと思います。
しばらくは、引き続きこのESP-ADFライブラリを活用して、知見を投稿したいと思います。