はじめてのAthena
webサイトの訪問ログがs3に溜まっていくことになったので、Athenaを使ってみることに。
はじめてのAthenaを使う色々を自分用にメモ。
テーブルを作る
最初なので、GUIで作る(2回目以降はSQLで作った方が楽ちん)
step0
create table > from S3 bucket data

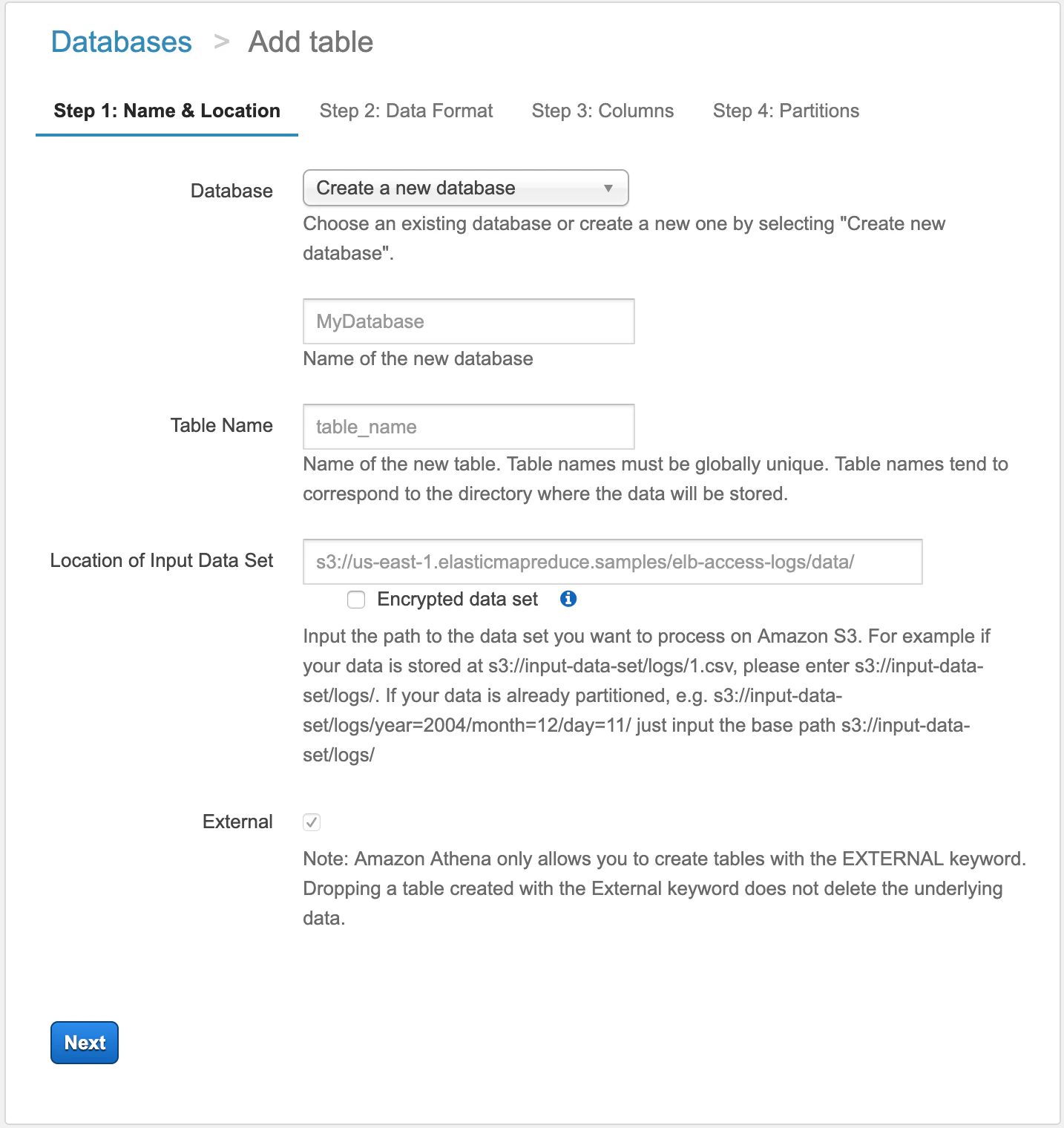
step1
DB名、Table名、データの取得場所を入力
※ フォルダを指定すると、中にある該当ファイルが取り込まれる
step2
ファイルフォーマットを指定

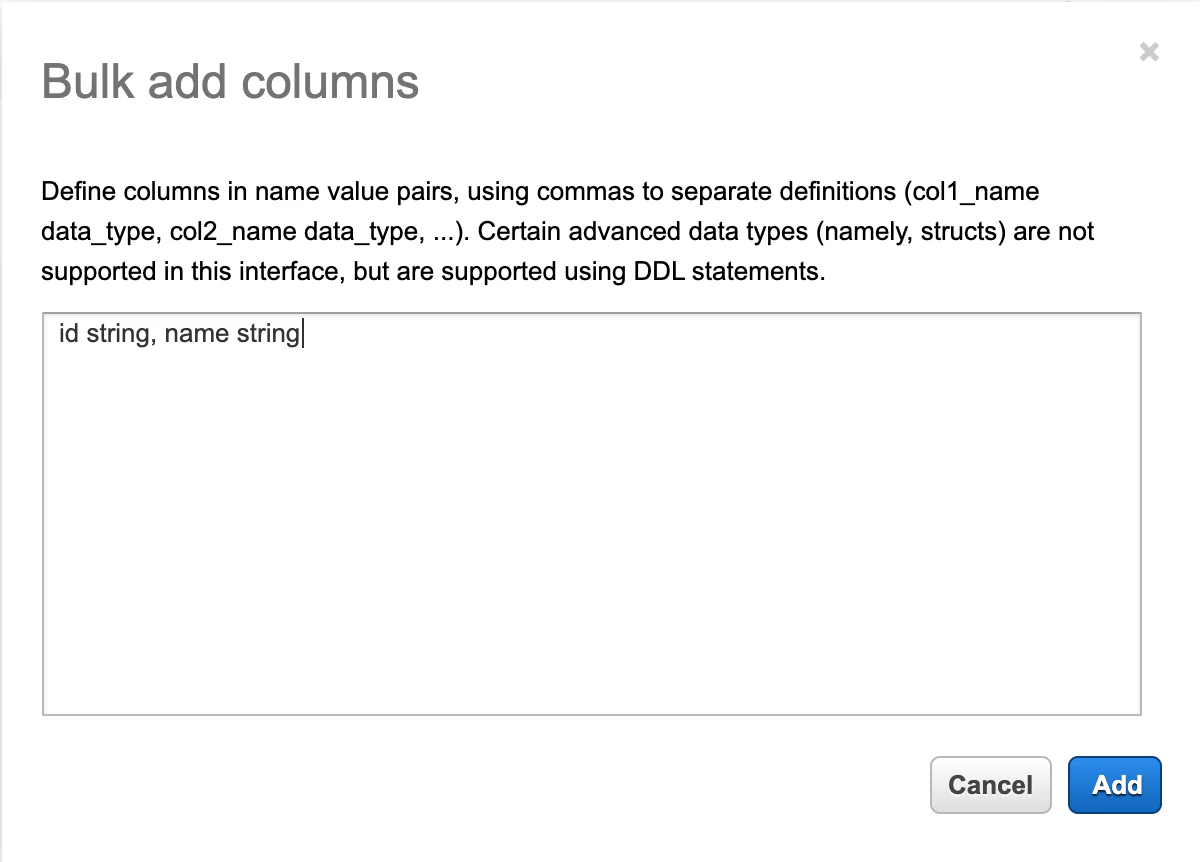
step3
Columnを設定。ひとつずつプルダウンで選べるけど、多いと大変なので一気に入力
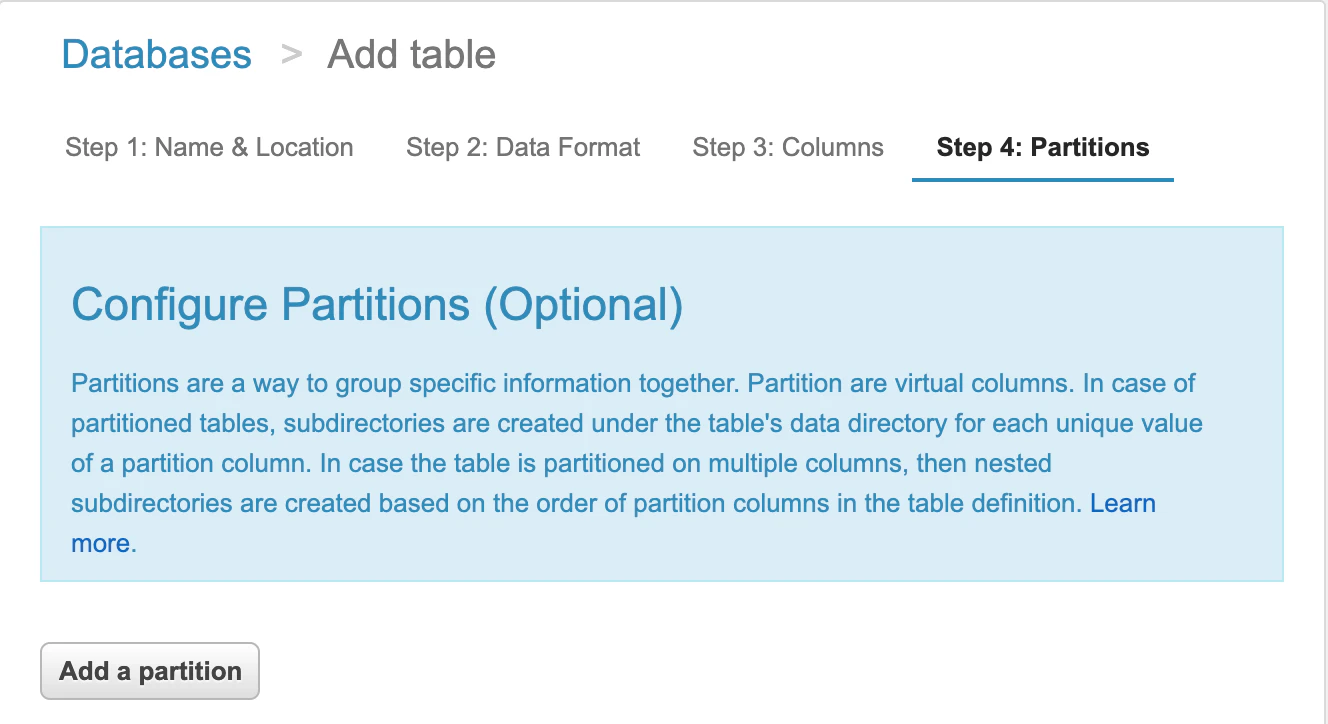
step4
Partitionに使うColumnを決める。最初なので、いったんそのままで。
step5
createでテーブル作成
作成と同時に作成に使われたSQLが表示されるので、次回以降はこれを修正しながら作るのが早い
GUIでヘッダーをスキップする方法が見つからないので、結局SQLでつくり直し![]()
CREATE EXTERNAL TABLE IF NOT EXISTS <Database名>.<Table名> (
`id` string
...
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = ',',
'field.delim' = ','
) LOCATION 's3://XXXXXXXX'
TBLPROPERTIES (
'has_encrypted_data'='false', # 暗号化するか否か
'skip.header.line.count'='1' # ヘッダーをスキップ
);
Database, Tableを削除
DROP DATABASE `DB_name`; # DBを削除
DROP TABLE `table_name`; # Tableを削除
TIMESTAMP分割
useragentわける
https://qiita.com/nightyknite/items/b2590a69f2e0135756dc
https://docs.aws.amazon.com/ja_jp/redshift/latest/dg/r_CASE_function.html
そのうち使いそう
サブクエリからの配列の作成
https://docs.aws.amazon.com/ja_jp/athena/latest/ug/creating-arrays-from-subqueries.html